我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
Encored Technologies 如何使用 亚马逊云科技 构建无服务器事件驱动的数据管道
这篇文章是与 Encored Technologies 的李宣正、严载润和杨贤锡共同撰写的客座文章。
在这篇文章中,我们分享了 Encored 如何在 亚马逊云科技 上为容器化机器学习应用程序运行数据工程管道,以及他们如何使用 A
业务和技术挑战
Encored正在将其业务扩展到多个国家,为最终客户提供电力交易服务。随着时间的推移,数据量和收集数据所需的发电厂数量正在迅速增加。例如,训练其中一个 ML 模型所需的数据量超过 200 TB。为了满足不断增长的业务需求,数据科学和平台团队需要加快交付模型输出的过程。作为解决方案,Encored旨在迁移现有数据并在亚马逊云科技云环境中运行机器学习应用程序,以高效处理可扩展且强大的端到端数据和机器学习管道。
解决方案概述
该解决方案的主要目标是开发优化的数据采集管道,以解决与数据摄取相关的扩展挑战。在之前在本地环境中部署期间,处理从摄取到准备训练数据集的数据所花费的时间超过了所需的服务级别协议 (SLA)。机器学习模型所需的输入数据集之一是韩国气象局 (KMA) 提供的天气数据。为了将 GRIB 数据集用于机器学习模型,Encored 需要准备原始数据,使其适合构建和训练 ML 模型。第一步是将 GRIB 转换为 Parquet 文件格式。
Encored 使用 Lambda 运行在基于 Linux 的容器映像中构建的现有数据提取管道。Lambda 是一项计算服务,允许您在不预置或管理服务器的情况下运行代码。Lambda 在高可用性计算基础设施上运行您的代码,并执行计算资源的所有管理,包括服务器和操作系统维护、容量预置和自动扩展以及日志记录。当 GRIB 数据文件上传到亚马逊 S
下图说明了解决方案架构。
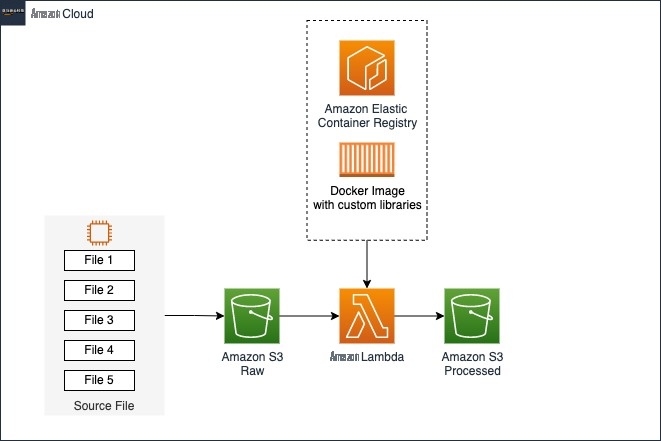
对于数据密集型任务,例如提取、转换和加载 (ETL) 任务和机器学习推理,Lambda 是理想的解决方案,因为它具有多项关键优势,包括快速扩展以满足需求、不使用时自动扩展到零,以及可以启动操作以响应对象创建事件的 S3 事件触发器。所有这些都有助于建立可扩展且具有成本效益的数据事件驱动管道。除了这些好处外,Lambda 还允许您配置 512—10,240 MB 之间的临时存储 (/tmp)。Encored 在读取或写入数据时将此存储用于其数据应用程序,使他们能够优化性能和成本效益。此外,Lambda 的按使用量付费定价模式意味着用户只需为使用的计算时间付费,这使其成为适用于各种用例的经济高效的解决方案。
先决条件
在本演练中,您应该具备以下内容:
- 一个 亚马逊云科技 账户
-
安装 了亚马逊云科技 命令行接口 (亚马逊云科技 CLI) -
Docker 命令 行界面 - 你的函数码
构建 Docker 映像所需的应用程序
第一步是开发一个可以采集和处理文件的应用程序。此应用程序读取从 添加到 Lambd
/tmp
)、解析 GRIB 格式的数据以及将解析后的数据保存为 Parquet 格式。
客户有一个 Python 脚本(例如,
app.py
),可以按如下方式执行这些任务:
准备一个 Docker 文件
第二步是使用 亚马逊云科技 基础映像创建 Docker 镜像。为此,你可以在本地计算机上使用文本编辑器创建新的 Dockerfile。这个 Dockerfile 应该包含两个环境变量:
-
lambda_task_root=/var/Task -
lambda_runtime_dir=/var/runtime
务必将所有依赖项安装在函数处理程序旁边的
$ {LAMBDA_TASK_ROOT}
目录下,以确保 Lambda 运行时可以在调用函数时找到它们。有关更多信息,请参阅
构建 Docker 镜像
第三步是使用 docker 编译命令来构建
Dock
er 镜像。 运行此命令时,请务必输入图像的名称。例如:
docker build-t process-grib。
在此示例中,图像的名称为 proc
ess-grib
。你可以为你的 Docker 镜像选择任何你喜欢的名称。
将图片上传到亚马逊 ECR 存储库
您的容器映像需要存放在
第一步是将 Docker CLI 验证到您的 ECR 注册表,如下所示:
第二步是标记您的映像以匹配您的存储库名称,然后使用
docker pus
h 命令将映像部署到 Amazon ECR:
将 Lambda 函数部署为容器镜像
要创建您的 Lambda 函数,请完成以下步骤:
- 在 Lambda 控制台上, 在导航 窗格中选择函数 。
- 选择 创建函数 。
- 选择 容器镜像 选项。
- 在 函数名称 中 ,输入一个名称。
- 对于 容器镜像 URI ,请提供容器镜像。您可以输入 ECR 图像 URI 或浏览 ECR 图像。
- 在 容器映像覆盖 下 ,您可以替换 Dockerfile 中包含的入口点或工作目录等配置设置。
- 在 “ 权限” 下 ,展开 “ 更改默认执行角色 ” 。
- 选择创建新角色或使用现有角色。
- 选择 创建函数 。
关键注意事项
为了同时快速地处理大量数据,Encored 需要将 GRIB 格式的文件存储在 Lambda 附带的临时存储 (
/
tmp) 中。为了满足这一要求,Encored 使用了
tempfile.namedTemporaryFile
,它允许用户轻松创建临时文件,在不再需要时将其删除。使用 Lambda,您可以配置 512 MB—10,240 MB 之间的临时存储空间用于读取或写入数据,从而允许您运行 ETL 作业、机器学习推理或其他数据密集型工作负载。
业务成果
Hyoseop Lee(Encored Technologies首席技术官)说:“自迁移到亚马逊云科技云以来,Encored取得了积极的成果。最初,人们认为在 亚马逊云科技 上运行工作负载比使用本地环境更昂贵。但是,当我们开始在 亚马逊云科技 上运行应用程序后,我们发现情况并非如此。亚马逊云科技 服务最引人入胜的方面之一是它为处理、存储和访问不经常需要的大量数据提供了灵活的架构选项。”
结论
在这篇文章中,我们介绍了 Encored 如何使用 Lambda 和 Amazon ECR 构建无服务器数据管道,以实现性能改进、成本降低和运营效率。
Encored 成功构建了一个架构,该架构将通过 亚马逊云科技 服务和 亚马逊云科技 数据实验室计划支持其全球扩张并增强技术能力。基于Encored整合和整理的架构和各种内部数据集,Encored计划提供可再生能源预测和能源交易服务。
感谢您阅读这篇文章,希望您发现它有用。为了利用机器学习加速您的数字化转型,亚马逊云科技 可以通过提供针对特定用例的规范性架构指导、分享最佳实践和消除技术障碍来为您提供支持。您将使用根据您的需求量身定制的架构或工作原型、生产路径以及对 亚马逊云科技 服务的更深入了解。请联系您的 亚马逊云科技 客户经理或解决方案架构师开始使用。如果您没有 亚马逊云科技 账户经理,请联系
要了解有关 Lambda 机器学习推理用例的更多信息,请查看以下博客文章:
-
使用 亚马逊云科技 无服务器进行大规模机器学习推断 -
在 亚马逊云科技 Lambda 上部署机器学习推理数据捕获解决方案
这些资源将为您提供有关如何使用 Lambda 进行机器学习推理的宝贵见解和实际示例。
作者简介




*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。