我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
Earnin 如何使用亚马逊 QLDB 建立账本服务
这是来自 EarnIn 后端工程师 Nehme Bilal 的客座文章。
作为工资准入方面的创新技术组织,
在美国,每两周或每月向员工支付工资。这意味着在完成工作和支付补偿的时间之间存在延迟。由于这种流动性缺口,美国人每年积累超过500亿美元的滞纳金和透支费,并且经常转向其他金融产品,例如高息发薪日或典当贷款和现金透支。我们提供一款消费者友好型应用程序,以帮助美国人完全避免使用这些产品。
我们为社区成员(我们的用户称为社区成员)提供现代且功能齐全的移动应用程序,以帮助他们完成财务之旅。我们的用户利用我们的应用程序来快速访问他们的工资,关注他们的账户余额并管理他们的交易。在这篇文章中,我们将分享我们如何使用
微服务挑战赛
我们的移动应用程序由托管在 亚马逊云科技 上的微服务提供支持。这些微服务各自拥有一个私有数据库(或者根本没有用于无状态微服务的数据库)。微服务实现带来了高度弹性、松散耦合、容错的主干,为我们面向用户的应用程序提供支持。尽管微服务架构有很多好处,但由于数据库的分布式性质,它使我们很难创建用户财务交易的汇总视图。实际上,为了汇总社区成员的金融交易,我们需要对许多不同的微服务进行 API 调用,并合并返回的数据。这最终是一项昂贵而复杂的操作。
由于数据分布在许多不同的数据库中,每个数据库都使用不同的技术和设计方法,因此我们机器学习团队的数据科学家在运行系统范围的查询时面临挑战。此外,我们希望构建数据仓库,而不必构建繁琐的提取、转换和加载 (ETL) 流程或管理数据库实例存储。
收益账本系统
为了克服这些困难,我们决定创建社区成员财务状况的汇总视图,我们称之为账本。每个运行影响用户财务状况的业务逻辑的微服务还负责以最终一致的方式更新账本。除了可用于数据分析外,该账本还用于提供面向用户的API和生成财务报表。
下图说明了我们使用
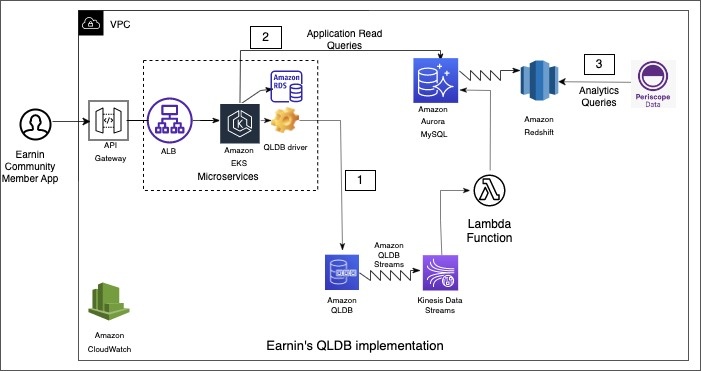
Earnin 的 QLDB 实施方案
通过该应用程序生成的社区成员请求由写入其本地数据库以及 Amazon QLDB 的微服务提供服务。利用 QLDB 中对变更流的内置支持,对 QLDB 账本的每一项更改都通过
根据经典的会计惯例,我们在复式记账会计账本的基础上建立了分类账。每笔账本交易都是一系列平衡的借记和贷项,存储在单个 QLDB 实体中。换句话说,给定交易中的贷方总和必须等于同一笔交易中的借方总和。给定交易中的借记和贷记适用于不同的账户。我们已经按资产、负债、支出和收入等类别创建了分类账账户。除了作为交易日志外,我们还使用账本服务来存储余额。实际上,给定社区成员的所有账户余额存储在单个QLDB实体中,每次在账本上为社区成员执行新交易时,该实体都会更新。
账本要求和能力
为了实现Earnin账本服务,我们需要具有以下功能的数据管理服务:
- 不可变且可验证的交易日志 — 鉴于账本用于提供面向用户的 API 和生成月度报表,因此保留一份不可变且可验证的日记账以反映账本的每一次更新非常重要。更新记录为已执行的操作,通常被称为日记条目。记录后,不应修改日记账条目;账户的任何进一步更改都应是新的日记账分录。日记账条目充当所执行操作的线索,并生成账本的当前视图。理想情况下,我们不希望在没有特殊权限的情况下访问日记条目。更重要的是,在任何情况下都不应有人能够篡改/修改这些日记文章。
- 自动扩展数据存储 — 由于每笔金融交易都写入账本,因此我们希望数据存储库自动扩展。我们不想担心配置数据库服务器、配置容量或配置读/写容量单位。
- 在单个 ACID 交易中修改多个实体的能力 ——当我们在账本中添加新交易时,它会影响多个账户的余额。因此,每笔交易都会导致存储在账本数据库中的余额发生变化。为了确保日记账交易和余额高度一致,我们希望更新单笔ACID交易中的所有相关实体。
- 能够根据时间范围检索实体以前的余额 — 要生成月度报表(以及用于其他会计目的),我们需要能够提取给定社区成员在特定时间点的余额。鉴于这些余额存储在QLDB(余额实体)中,我们可以简单地检索以前的余额实体以获取给定时间点的余额。
- 乐观并发和序列化操作 — 我们经常在做出业务决策之前查询账本余额,这会产生新的账本交易。例如,如果用户想要将一些资金从他们的Earnin账户转移到外部账户,我们首先检查他们的余额以确保他们有足够的资金,然后创建一个反映资金转移的新分类账交易。如果在我们读取账户余额之后但在记录新交易之前发生另一笔交易,这可能会导致竞争状态。为了避免这个问题,我们需要乐观的并发控制,即数据库不会获取账户余额的锁,而是以完全可序列化的操作运行。
-
能够订阅账本变动
— 我们有几种微服务会对账户余额变化做出反应。确保在账户余额公布 后向发布/订阅系统(如
亚马逊简单通知服务 (Amazon SNS) 或 A mazon Kinesis )发布通知容易出错。理想情况下,我们希望存储系统能够可靠地处理开箱即用的问题。此外,订阅变更源的功能使我们能够在需要时将主数据库复制到辅助存储。
在现有的众多托管数据库中,我们主要考虑了 MySQL、
| Feature | RDS/Aurora MySQL | Amazon DynamoDB | Amazon QLDB |
| Immutable and verifiable transaction log | No | No | Yes |
| Serverless Database with automatic scaling | No | Yes | Yes |
| Modify multiple entities in an ACID transaction | Yes | Yes | Yes |
| Retrieving an older revision of an entity based on a time range | No | Yes* | Yes |
| Ability to subscribe to a change feed | No** | Yes | Yes |
| Support for optimistic concurrency | No | Yes | Yes |
*是 — 通过
**不是 —
基于这种比较,Amazon QLDB是显而易见的选择,因为它支持账本服务所需的功能。我们确实使用QLDB实现了账本服务,并得以实现上面讨论的目标。
结论
在这篇文章中,我们分享了Earnin如何使用Amazon QLDB更新我们的账本系统,以满足我们的移动应用程序、数据科学和会计团队的需求。使用 QLDB,我们能够为社区成员的金融交易创建汇总、全面、不可变和可加密验证的视图。这意味着我们社区成员财务交易的任何变化都将得到可靠地跟踪,并可通过 QLDB 的变更历史记录进行访问。
将所有交易存储在一个地方可以更有效地为我们的移动应用程序 API 提供服务。此外,我们的数据科学家很高兴依赖一个数据库而不是多个数据库。我们还利用了QLDB检索实体的旧版本的能力来生成月度报表和用于会计目的。
此外,QLDB 的无服务器特性及其自动扩展能力意味着我们不必担心在保持应用程序快速响应的同时,可以支持的用户数量达到限制。
在查询数据方面,QLDB 不如关系数据库强大,仅支持 SQL 查询的子集。也就是说,由于它内置了对
总体而言,采用QLDB使Earnin的移动应用程序更加可靠、安全和快速。它还简化了我们的后端,使我们的数据科学家提高了效率。截至2022年9月,Earnin已经进行了超过1.25亿笔交易,并为其会员提供了100亿美元的收入。
作者简介
 Nehme Bilal
是EarnIn(之前在亚马逊和微软工作)的员工后端工程师,拥有近15年的经验。Nehme 领导了 EarnIn 多项后端服务的开发。他还热衷于建立流程和指导方针,以提高团队构建高质量软件的效率。
Nehme Bilal
是EarnIn(之前在亚马逊和微软工作)的员工后端工程师,拥有近15年的经验。Nehme 领导了 EarnIn 多项后端服务的开发。他还热衷于建立流程和指导方针,以提高团队构建高质量软件的效率。
 Shilpa Bondale
是一位经验丰富的技术专业人士,在硅谷拥有 20 年的经验,目前在亚马逊网络服务担任解决方案架构师。除了专业成就外,她还是《Women Who Code》的活跃成员和顾问,这进一步表明了她对促进科技行业多元化和包容性的承诺。
Shilpa Bondale
是一位经验丰富的技术专业人士,在硅谷拥有 20 年的经验,目前在亚马逊网络服务担任解决方案架构师。除了专业成就外,她还是《Women Who Code》的活跃成员和顾问,这进一步表明了她对促进科技行业多元化和包容性的承诺。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。