我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
Chime Financial 如何使用 亚马逊云科技 来构建无服务器流分析平台并击败欺诈者
这是Chime Financial参谋软件工程师坎杜·辛德和高级软件工程师爱德华·佩吉特的客座文章。
Chime 有责任保护我们的会员免受其账户中未经授权的交易。Chime的风险分析团队不断监控我们数据的趋势,以发现表明欺诈交易的模式。
这篇文章讨论了 Chime 如何利用
问题陈述
为了跟上欺诈者的快速流动,我们的决策平台必须持续监控用户事件并实时做出响应。但是,我们基于数据仓库的传统解决方案无法应对这一挑战。它旨在大规模管理复杂的查询和商业智能 (BI) 用例。但是,这种架构的最低数据新鲜度为 10 分钟,本质上与近乎实时的欺诈检测用例不一致。
为了做出高质量的决策,我们需要从各种来源收集用户事件数据并实时更新风险概况。当我们的团队发现新的攻击时,我们还需要能够在风险概况中添加新的字段和指标,而无需工程干预或复杂的部署。
我们决定探索流分析解决方案,在这些解决方案中,我们可以大规模捕获、转换和存储事件流,并提供基于规则的欺诈检测模型和具有毫秒延迟的机器学习 (ML) 模型。
解决方案概述
下图说明了 Chime Streaming 2.0 系统的设计。
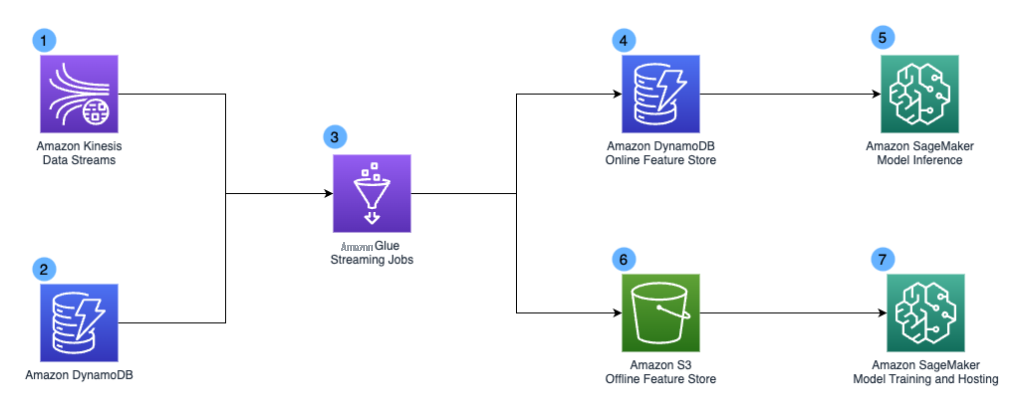
该设计包括以下关键组件:
-
我们将
Amazon Kinesis Data Streams 作为 流数据 服务,用于大规模捕获和存储事件流。我们的直播管道捕获各种事件类型,包括用户注册事件、用户登录事件、刷卡事件、点对点支付和应用程序屏幕操作。 - 亚马逊 DynamoDB 是我们流媒体 2.0 系统的另一个数据源。它充当应用程序后端,存储诸如阻止的设备列表和设备用户映射之类的数据。我们主要将其用作管道中的查找表。
-
亚马逊云科技 Glue 任务构成了我们流媒体 2.0 系统的支柱。图中简单的 亚马逊云科技 Glue 图标代表数千个执行不同转换的 亚马逊云科技 Glue 任务。为了实现 Steaming 2.0 管道的 5-15 秒端到端数据新鲜度服务等级协议 (SLA),我们在
亚马逊云科技 Glue 中使用 流式处理 ETL 任务来使用 来自 Kinesis Data Streams 的数据并进行近乎实时的转换。我们之所以选择 亚马逊云科技 Glue,主要是因为它具有无服务器特性,它通过自动配置和工作人员管理简化了基础设施管理,并且能够大规模执行复杂的数据转换。 - 亚马逊云科技 Glue 流媒体任务会生成派生字段和风险概况,这些字段和风险概况存储在亚马逊 DynamoDB 中。由于其毫秒级性能和可扩展性,我们使用亚马逊 DynamoDB 作为在线功能商店。
- 我们的应用程序调用 Amazon SageMaker 推理端点进行欺诈检测。亚马逊 DynamoDB 在线功能商店支持实时推断,查询延迟为个位数毫秒。
-
我们使用
亚马逊 Simple Storage Servic e (Amazon S3) 作为我们的离线功能商店。它包含历史用户活动和其他衍生的 ML 功能。 - 我们的数据科学家团队可以访问数据集并使用 Amazon SageMaker 进行机器学习模型训练和批量推断。
亚马逊云科技 Glue 管道实施深入探讨
我们的 亚马逊云科技 Glue Pipeline 和 Streaming 2.0 项目有几项关键设计原则。
- 我们希望实现数据平台的民主化,让所有 Chime 开发人员都能访问数据管道。
- 我们希望实施云金融后端服务并实现成本效益。
为了实现数据民主化,我们需要让组织中的不同角色能够使用该平台并快速定义转型任务,而不必担心管道的实际实施细节。数据基础设施团队在 Spark 和集成服务的基础上构建了一个抽象层。该层包含集成服务、作业标签、调度配置和调试工具上的 API 封装,向最终用户隐藏 Spark 和其他较低级别的复杂性。因此,最终用户能够使用声明式 YAML 配置定义作业,并使用 SQL 定义转换逻辑。这简化了入职流程,加快了实施阶段。
为了提高成本效率,我们的团队基于
结论
在这篇文章中,我们向您展示了 Chime 的 Streaming 2.0 系统如何允许我们采集事件,并在事件从其他服务发出几秒钟后将其提供给决策平台。这使我们能够制定更好的风险政策,为我们的机器学习模型提供更新的数据,并保护我们的会员免受其账户中未经授权的交易。
Chime 中有 500 多名开发者正在使用这个流媒体管道,我们每秒采集超过 100 万个事件。我们遵循
我们希望这篇文章能激励您的组织使用无服务器技术构建实时分析平台,以加速实现业务目标。
作者简介
 Khandu Shinde
是一名职员工程师,专注于Chime的大数据平台和解决方案。他通过架构方向和愿景帮助平台扩展以满足Chime的业务需求。他住在旧金山,在那里他打板球和看电影。
Khandu Shinde
是一名职员工程师,专注于Chime的大数据平台和解决方案。他通过架构方向和愿景帮助平台扩展以满足Chime的业务需求。他住在旧金山,在那里他打板球和看电影。
 爱德华·佩吉特
是一名软件工程师,致力于提高Chime的能力以降低风险,确保我们的会员在财务上高枕无忧。他喜欢站在大数据和编程语言理论的交汇处。他住在芝加哥,在那里他花时间在湖边跑步。
爱德华·佩吉特
是一名软件工程师,致力于提高Chime的能力以降低风险,确保我们的会员在财务上高枕无忧。他喜欢站在大数据和编程语言理论的交汇处。他住在芝加哥,在那里他花时间在湖边跑步。
 Dylan Qu
是一名专业解决方案架构师,专注于亚马逊网络服务的大数据和分析。他帮助客户在 亚马逊云科技 上架构和构建高度可扩展、高性能和安全的基于云的解决方案。
Dylan Qu
是一名专业解决方案架构师,专注于亚马逊网络服务的大数据和分析。他帮助客户在 亚马逊云科技 上架构和构建高度可扩展、高性能和安全的基于云的解决方案。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。