我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
Blueshift 如何将其客户数据环境与亚马逊 Redshift 整合在一起,以统一和激活用于营销的客户数据
这篇文章由联合创始人兼首席执行官维杰·奇图尔和Blueshift团队的联合创始人兼首席技术官Mehul Shah共同撰写。
业务需求
在当今的全渠道世界中,现代企业的营销团队的任务是通过多种渠道吸引客户。为了成功实现智能客户互动,营销人员需要以全方位的客户视角进行运营,将各种类型的数据考虑在内,包括客户行为、人口统计、同意和偏好、交易、来自人工辅助和数字互动的数据等。但是,统一这些数据并使其可供营销人员采取行动通常是一项艰巨的任务。现在,随着Blueshift与Amazon Redshift的整合,各公司首次可以使用比以往更多的数据进行智能的跨渠道互动。
Amazon Redshift 是一个快速、完全托管的云数据仓库。成千上万的客户使用亚马逊 Redshift 作为他们的分析基础设施。数据分析师、数据库开发人员和数据科学家等用户使用 SQL 在 Amazon Redshift 数据仓库中分析数据。除了支持通过 ODBC/JDBC 或 Redshift 数据 API 进行连接外,Amazon Redshift 还提供基于 Web 的查询编辑器。
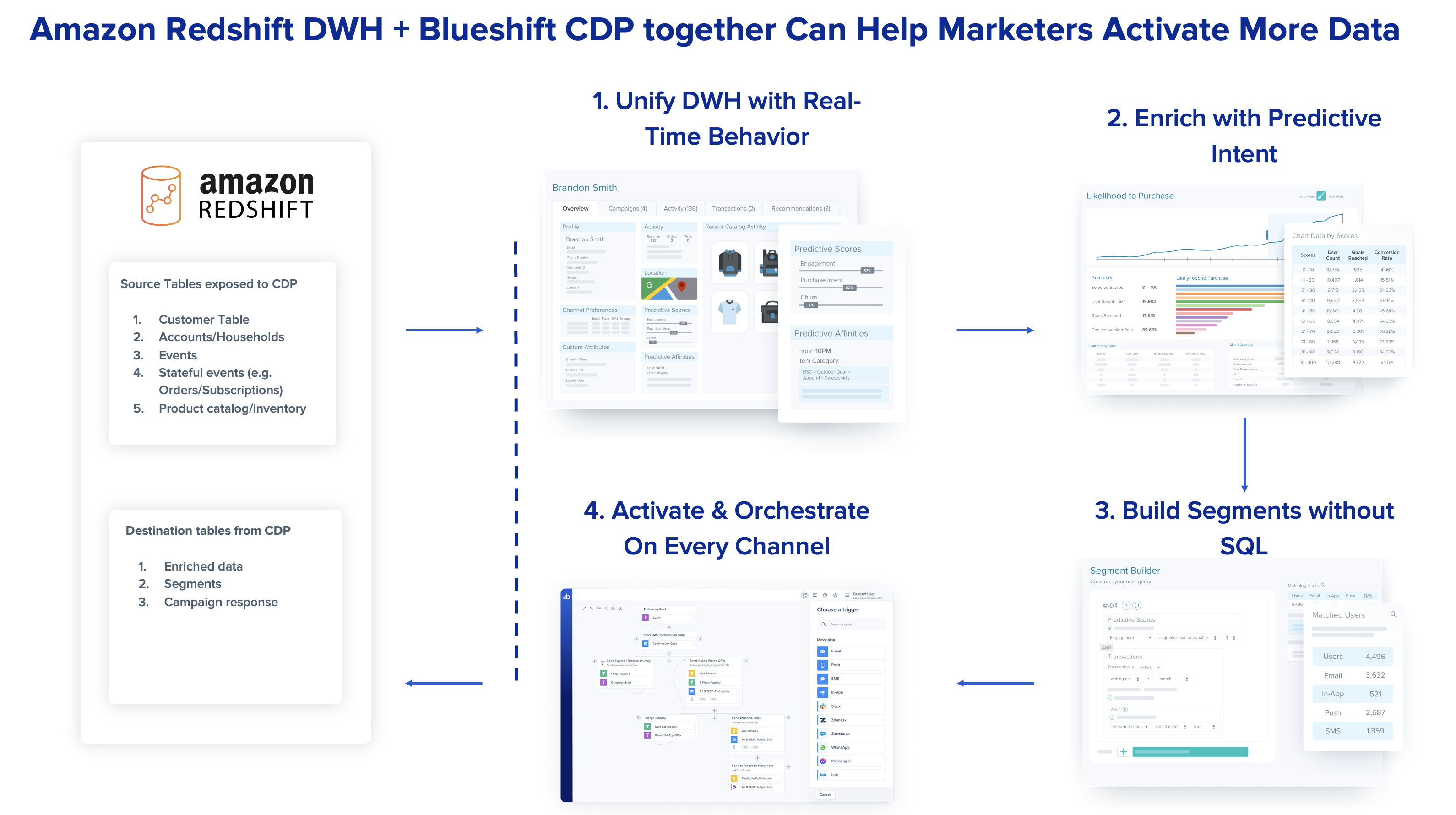
Blueshift 旨在让企业用户能够解锁此类数据仓库中的数据,并通过个性化的细分旅程、1:1 消息、网站、移动和付费媒体用例激活受众。此外,Blueshift可以帮助将Amazon Redshift数据仓库中的这些数据与实时网站和移动数据相结合,以进行实时配置和激活,从而使这些业务的营销人员能够使用这些数据。
尽管Amazon Redshift中的数据非常强大,但由于各种原因,营销人员无法以原始形式将其用于客户互动。首先,查询数据需要了解像 SQL 这样的查询语言,而营销人员不一定擅长这些语言。此外,营销人员需要将仓库中的数据与对客户互动至关重要的其他数据源相结合,包括实时事件(例如,客户查看的网站页面)以及渠道级权限和身份。
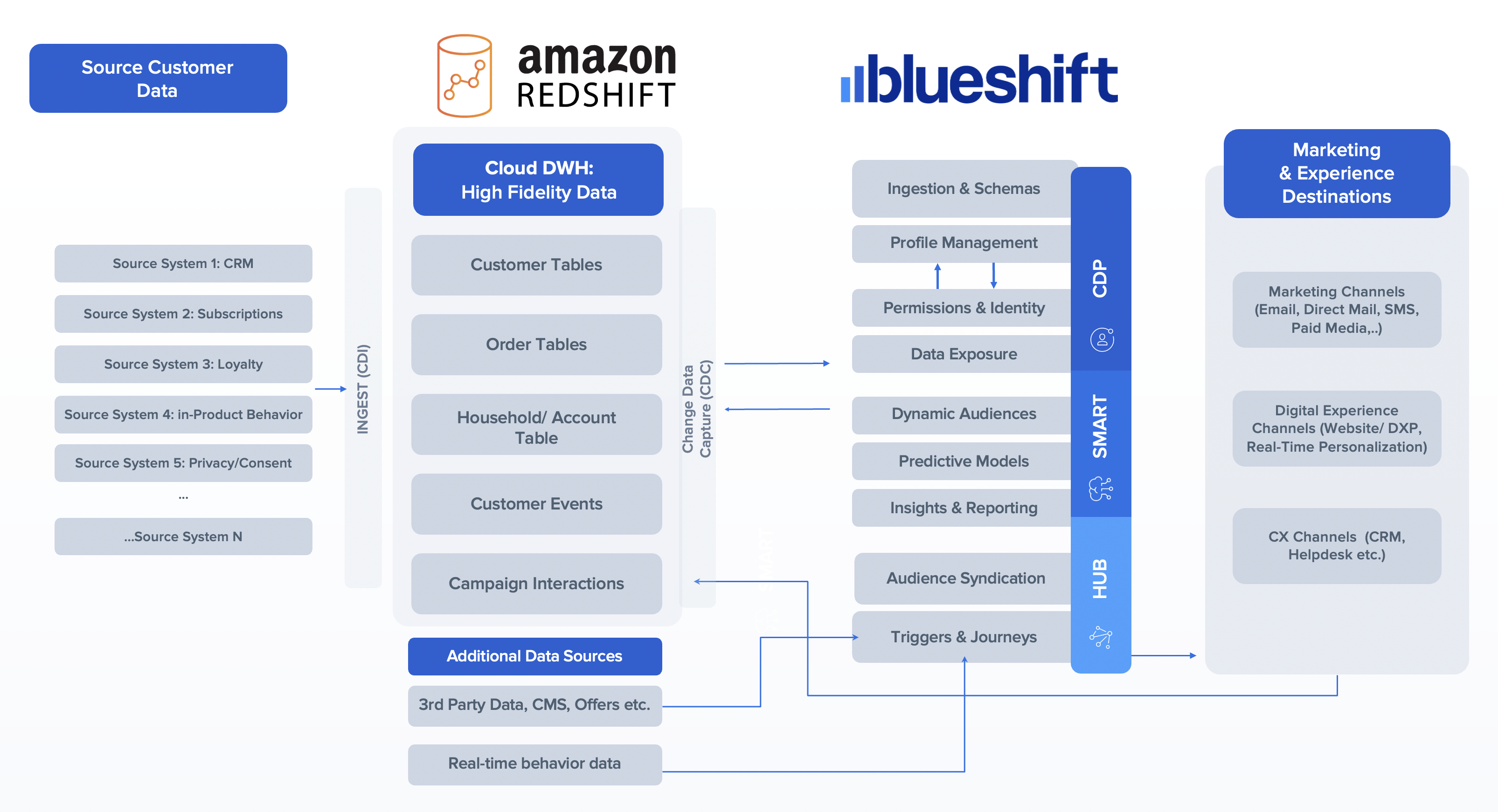
通过新的集成,Blueshift客户可以将来自Amazon Redshift的多维数据表(例如,客户表、交易表和产品目录表)提取到Blueshift中,以构建营销人员可以访问的单一客户视图。双向集成还确保将Blueshift中计算的预测数据属性以及Blueshift的活动参与度数据写回Amazon Redshift表中,从而使技术和分析团队能够全面了解数据。
在这篇文章中,我们描述了Blueshift如何与亚马逊Redshift整合。我们重点介绍与从客户的 Amazon Redshift 数据仓库流向 Blueshift 的 CDP 环境以及反之亦然的数据的双向集成。这些机制是通过使用 Redshift 数据 API 来实现的。
解决方案概述
两个环境之间的集成是通过连接器实现的。我们将在本节中讨论连接器的核心组件。Blueshift使用混合方法,使用
Blueshift 使用容器技术来摄取和处理数据。数据摄取容器和出口容器会根据正在处理的数据量向上和向下扩展。关键设计原则之一是通过不必管理连接或活动连接池来简化设计。Redshift 数据 API 支持基于 HTTP 的 SQL 接口,无需主动管理连接。如流程中所述,
在Blueshift的应用程序中集成了Redshift数据API之后,来自Blueshift客户的IT用户可以设置和验证数据连接,随后,Blueshift的业务用户(营销人员)可以通过为存储在亚马逊云科技 Redshift中的客户数据开发见解并将这些见解无缝付诸实践,从而无缝地从数据中提取价值。因此,Blueshift使用Redshift数据API开发的流程显著降低了新用户的进入门槛,而无需数据仓库经验或业务用户持续的IT依赖关系。
下图中描述的解决方案架构显示了 CDP 环境和 Amazon Redshift 的各个组件如何集成以提供端到端解决方案。
先决条件
在本节中,我们描述了两个基础架构之间集成解决方案的要求。向客户实施的典型数据包括将来自亚马逊 Redshift 的数据提取到 Blueshift CDP 环境中。这种摄取机制必须适应不同的数据类型,例如:
- 客户 CRM 数据(用户标识符和各种 CRM 字段)。此数据类型支持的数据量范围通常为最初采集后的 50—500 GB。
- 实时行为或事件数据(例如,播放或暂停电影)。
- 交易数据,例如订阅购买。每天为活动和交易摄入的数据量通常在 500 GB — 1 TB 之间。
- 目录内容(例如,供发现的节目或电影列表),通常每天摄入的大小约为 1 GB。
集成还需要支持Blueshift的CDP平台环境才能将数据导出到Amazon Redshift。这包括诸如营销活动(例如正在查看的电子邮件)之类的数据,这些数据可能高达数十 TB,以及区段或用户导出以支持属于区段定义的用户列表,通常每天导出 50-500 GB。
将 Amazon Redshift 与数据应用程序集成
Amazon Redshift 提供了多种快速集成数据应用程序的方法。
对于初始数据加载,Blueshift 使用 Redshift S3 UNLOAD 将亚马逊 Redshift 数据转储到亚马逊简单存储服务(
对于增量数据摄取,Blueshift 数据导入任务会跟踪上次运行导入的时间,并导入自上次导入运行以来添加或更新的新数据行。Blueshift 使用 Redshift 数据 API 与亚马逊 Redshift 数据仓库的更改(更新或插入)保持同步。Blueshift 使用亚马逊 Redshift 表中的
last_updated_a
t 列来确定新的行或更新的行,然后使用 Redshift 数据 API 提取这些行。Blueshift 的数据集成 cron 任务使用 Redshift 数据 API,通过定期轮询更新(例如,每 10 分钟、每小时或每天)来近乎实时地同步数据。节奏可以根据数据新鲜度要求进行调整。
下表汇总了集成类型。
| Integration type | Integration mechanism | Advantage |
| Initial data ingestion from Amazon Redshift to Blueshift |
|
Initial data is exported from Amazon Redshift via Amazon S3 to allow faster parallel loads into Blueshift using the Amazon Redshift UNLOAD command. |
| Incremental data ingestion from Amazon Redshift to Blueshift |
|
Incremental data changes are synchronized using the Redshift Data API in near-real time. |
| Data export from Blueshift to Amazon Redshift |
|
Blueshift natively stores campaign activity and segment data in Amazon S3, which is loaded into Amazon Redshift using the Redshift S3 COPY command. |
Redshift 支持多种开箱即用的机制来提供数据访问权限。Blueshift 采用混合方法,将亚马逊 Redshift 与 Redshift S3 UNLOAD、Redshift Data API 和 Redshift S3 COPY 集成,从而缩短了客户的数据上传时间。Blueshift能够缩短初始数据加载时间,并且可以根据Amazon Redshift的变化进行近乎实时的更新,反之亦然。
结论
在这篇文章中,我们展示了Blueshift如何与Redshift数据API集成以提取客户数据。这种集成是无缝的,展示了Redshift数据API可以轻松地与外部应用程序(例如Blueshift的CDP营销环境以及Amazon Redshift进行集成)。这篇文章中概述的用例只是如何使用 Redshift 数据 API 来简化用户与 Amazon Redshift 集群之间的交互的几个示例。
现在开始构建亚马逊 Redshift 并将其与 Blueshift 集成。
作者简介




*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。