我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
亚马逊金融科技如何使用亚马逊 DocumentDB 创建支付存储库来简化全球支付
亚马逊金融科技(FinTech)支付系统向亚马逊的供应商和服务提供商支付应付账款(AP)。2021年,金融科技AP系统通过各种支付方式在150多个国家以50多种货币支付了数百万笔款项。
在这篇文章中,我们将向您展示我们如何构建可扩展的支付元数据存储库解决方案,该解决方案为所有亚马逊业务提供标准支付选项和工具包,从而利用亚马逊网络服务 (亚马逊云科技) 专门构建的数据库 Amazon
挑战和要求
在任何金融交易中,都有两方:付款人(债务人)和收款人(债权人)。FinTech AP付款的付款人是进行付款的亚马逊企业,收款人多种多样,包括但不限于数字作者、应用程序开发人员、零售供应商、公用事业公司和税务机关,他们是付款的接收者。
在入职过程中,每家企业都会收集收款人信息,包括付款偏好和银行账户信息。收款人的付款详细信息决定付款方式。这可以是以当地货币进行的国内支付(ACH:自动清算所),用于大额付款的国内电汇,以及用于跨国或跨币种支付的跨境电汇。例如,来自美国的数字作者可能会以美元向美国企业收取ACH的特许权使用费,并从欧盟企业收取跨境电汇。
他们在哪里、谁向他们付款以及他们想要如何获得付款会影响付款方式,这决定了我们需要从收款人那里获得的信息类型才能成功完成付款。例如,拉丁美洲的应用程序开发者在接收本地付款而不是国际付款时需要一组不同的付款明细。
下图说明了付款工作流程的示例。
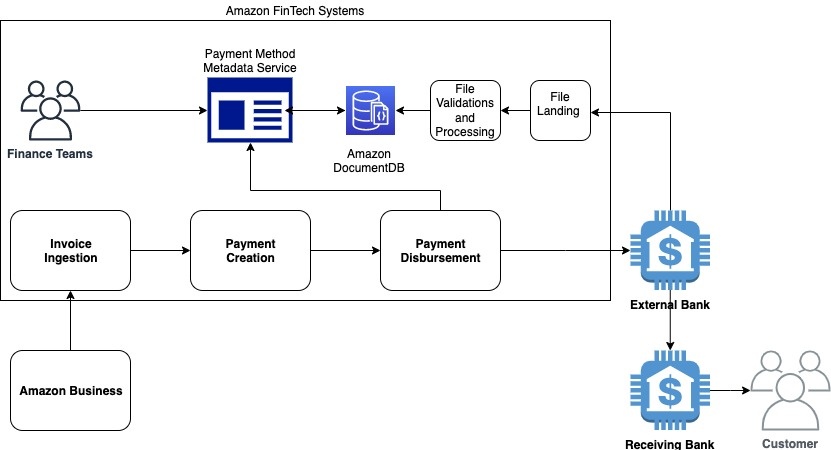
在发票提取、处理和生成付款过程中,我们会验证我们是否拥有成功付款所需的所有信息,并通过考虑其可用性、截止时间和处理时间来优化银行支付。
这种支付格局正在发展和变化,从收款人入职到支付,许多系统都参与协调付款。我们需要一种能够存储来自全球银行合作伙伴的规则和付款选项的支付方式元数据服务,这些规则和支付选项随后可由AP系统中的微服务进行访问。这项元数据服务之所以重要,是因为我们有来自银行合作伙伴的广泛全球要求以及支付选项的集中验证规则,它通过减少代码重复,使我们能够快速扩展到其他地区。
在检查了外部银行的付款元数据后,我们得以确定元数据服务的以下数据特征:
- 它需要灵活的查询功能
- 属性因银行而异
- 它具有大量读取的访问模式
为什么是亚马逊 DocumentDB?
为了确保我们能够使用我们的应付账款系统在全球范围内付款,拥有快速、高度可用、可扩展和专门构建的数据存储以支持我们的支付元数据服务需求非常重要。
金融科技团队开始使用
我们的第一个决策标准是使用 SQL(关系)还是 NoSQL(非关系)数据库。对于我们的用例,我们需要架构灵活性和简化的数据模型,因为来自银行的数据是分层的,有多个嵌套级别。
使用关系数据库将意味着失去架构灵活性。对于关系存储,表需要定义结构,任何新字段都会影响该表中的每条记录。这本来很难维护,并且会导致我们在存储库中加入的每个新银行实体或新属性都会发生表级别的变化。如果我们必须根据共同特征为每个国家维护不同的表格,并避免使用包含许多包含完整属性的空值的宽表,情况就会更加复杂。
支付数据本质上是分层的,具有深层嵌套性。对于关系数据库,需要第三种正态形式的复杂数据模型来对数据中的各种一对一和一对多关系进行建模。这不仅会使存储模式变得复杂,还会影响消耗和吞吐量延迟。对于我们的大多数业务需求,我们需要跨多个实体连接数据,这增加了查询和数据库性能的开销。扩展以解决存储和性能开销将导致更高的成本,并预计会出现性能延迟。
对于 NoSQL(非关系)数据库,我们同时研究了键值对和文档结构。使用键值数据库,我们可以获得所需的架构灵活性,但它在表设计中仍然存在复杂性。由于分层数据元素,我们需要高级行设计来优化我们的解决方案,并且很可能必须分解为多行。
与关系数据库方法类似,第二个挑战是查询灵活性。当我们知道访问模式,并且我们不想将数据分成不同的行并以编程方式将其组合在一起时,键值选项效果最好。我们可以为灵活的查询模式定义索引存在限制,我们不想为此维护两个单独的数据存储,因为这样的成本太高了,而且不符合应用程序的一致性要求。
当我们查看 Amazon DocumentDB 时,我们发现我们的数据可以很容易地以自然 JSON 格式表示为文档。每个文档都可以有可变字段,不需要遵循常见的静态架构。这提供了我们所寻求的灵活性,因为我们可以将来自多个国家/地区的具有不同属性的数据纳入到我们的应用程序的通用集合中。我们不需要为每个国家维护单独的实例,这对我们来说是一个胜利。文档结构还简化了我们的应用程序,因为我们使用 JSON 数据结构与 Amazon DocumentDB 进行交互,我们可以轻松地对其进行格式化、塑造并与应用程序中所需的其他 API 共享。
对于架构设计,我们创建了一个嵌入层次结构的去规范化模型,以减少数据消耗期间的开销。我们可以获得特定的属性,而无需在数据库或应用程序中加入或查找。这为我们提供了额外的优势,可以在不存在任何一致性挑战的情况下简化整个系统,因为可以在单个事务中插入和更新数据。正如我们前面提到的,对于各种用例,我们需要不同的属性组合。
以下是具有有限属性的示例文档结构:
Amazon DocumentDB 还提供了我们需要的查询灵活性,因为我们可以创建包括嵌套字段在内的索引。我们坚持
以下是我们为应用程序识别和定义的一些索引:
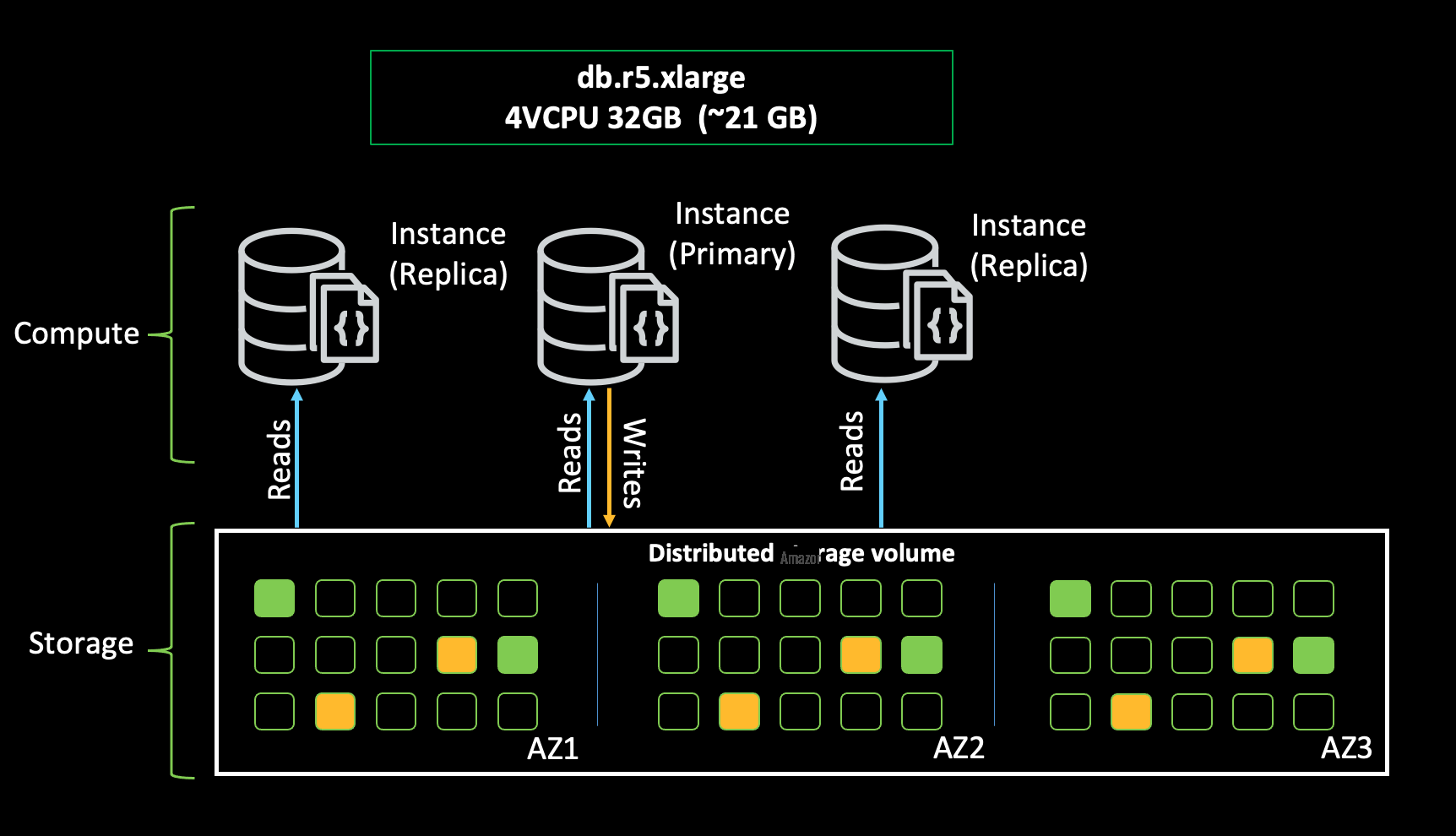
及时付款对我们很重要,因此我们希望我们的存储库具有高可用性。为了扩大集群规模,我们启动了至少三个实例,以达到 99.99% 的可用性目标,并将这些实例放在三个不同的可用区中。如果主实例出现故障,故障转移将在 30 秒内完成。
我们遵循的另一个最佳做法是选择正确的实例以确保索引和工作集适合缓存。由于一个实例中只有大约 2/3 的可用内存会用于缓存,因此我们努力确定正确的实例大小,并选择了 db.r5.xlarge 实例来满足我们的目的。
我们的应用程序将由不同国家的团队使用。Amazon DocumentDB 全球集群使我们能够以低延迟执行全球读取,并提高我们的应用程序抵御区域性中断的能力。我们的应用程序是读取密集型的,更新量很低。全球数据库的复制不到一秒钟,可以满足我们的需求。如果出现任何区域范围的中断,我们可以将其中一个辅助集群升级为主集群,以确保应用程序的正常运行时间和可用性。我们以 100 TPS 进行了性能测试,如果需要,可以选择进一步扩展。
下图显示了获得高可用性以满足我们性能需求的实例。
最后,我们可以用高安全标准实现所有这些。默认情况下,亚马逊 DocumentDB 具有许多安全功能。由于它是一项仅限 VPC 的服务,因此我们可以保护边界以供访问,并利用安全组来允许流量。默认情况下,对数据和传输中的数据启用加密。通过基于角色的访问控制,我们实现了最低权限强制执行以及集群审计和监控。它还与
基于这些评估,我们认为 Amazon DocumentDB 最适合我们的解决方案。我们可以创建简单而灵活的数据模型,获得所需的查询灵活性,支持大量读取请求,通过安全控制实现应用程序所需的可用性和灵活性目标,并采用按使用量付费的定价。此外,由于它是完全托管的,因此我们没有任何管理数据库的运营开销,因为这是由 Amazon DocumentDB 完成的。
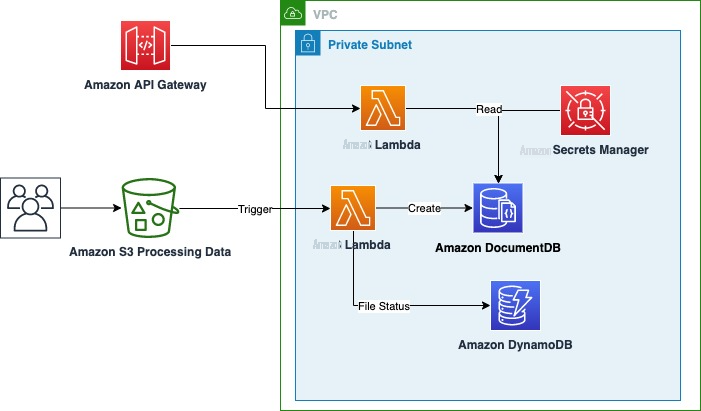
下图显示了整个应用程序架构。
摘要
借助亚马逊DocumentDB数据库,亚马逊金融科技团队得以通过推出全球支付存储库来创新其支付系统。该团队能够通过文档结构简化解决方案,从而缩短了全球 AP 团队发布产品的总体时间。我们还能够通过
有关亚马逊 DocumentDB 的更多信息,请访问
作者简介


*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。