我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
亚马逊金融科技如何使用 Amazon DynamoDB 构建事件驱动且可扩展的汇款服务
亚马逊金融科技(FinTech)支付传输团队为应付账款(AP)团队管理从发票到付款流程的产品。他们的服务套件处理从发票生成到付款创建的付款流程,以确保付款受益人收到付款。Amazon Business 向各种各样的收款人付款,包括数字作者、应用程序开发人员、零售供应商、公用事业公司和税务公司。2022年,金融科技支付传输团队通过ACH和电汇等各种支付方式,为来自150个国家和60多种货币的超过4200万笔汇款提供了支持。
在这篇文章中,我们将向您展示我们如何使用
要求
亚马逊汇款的支付生命周期包括几个步骤。首先生成发票,其中包含收款人姓名和金额等详细信息,然后确定银行合作伙伴以知道将款项发送到哪里,最后根据金额、国家和业务类型选择最佳的付款方式。收集到必要信息后,汇款指令将发送给银行合作伙伴。银行合作伙伴确认付款成功后,亚马逊会通知客户汇款已完成。成功付款后及时通知客户有助于他们了解付款状态并最大限度地减少客户服务查询。每天的付款量因地区而异,因此,为了保持汇款交付通知的准确性,该服务必须根据需要进行扩展。
我们确定了以下关键要求:
- 无缝可扩展性
- 保证处理和汇款通知
- 高效的错误处理
- 维护简单
我们对缩放问题的解决方案
为了构建强大的汇款服务,我们需要使用两种 亚马逊云科技 计算和数据库技术。为了满足计算需求,我们选择了
为了决定使用哪种数据库服务,我们确定了两个主要标准。首先,数据库应无缝扩展,以处理我们的大量汇款并及时通知客户。其次,必须保持架构灵活性,以考虑可能影响汇款细节的各种因素,例如收款人类型、交易类型和国家。我们不想构建一个必须预先定义所有数据元素的僵化架构的系统。在瞬息万变的金融格局中,这种情况很难维持。出于这些考虑,我们选择了 DynamoDB。
DynamoDB 是一个完全托管的无服务器键值 NoSQL 数据库,旨在大规模运行高性能应用程序。DynamoDB 提供内置安全性、持续备份、自动多区域复制、内存缓存以及数据导入和导出工具。这些功能有助于消除我们团队管理和扩展数据库所需的无差别繁重工作,因此我们可以专注于为客户构建汇款应用程序。我们利用了 DynamoDB 的
为了使我们的客户能够付款,将必要的信息发送给银行合作伙伴进行处理。银行合作伙伴成功处理付款后,将发送一条确认消息。这些消息包括其他详细信息,例如发票和付款说明。这两个操作适用于不同的系统,这促使我们将它们分成两个不同的服务,允许每个服务执行自己的任务,同时遵循相同的可重用模式(我们稍后将对此进行讨论)。职责分工有助于金融科技保持解决方案的简单性,并使每项服务能够独立扩展。
我们在应用程序中使用了以下两项服务:
- 充实服务 -此服务负责在成功付款后接收银行合作伙伴的通知,并向他们提供更多详细信息
- 通知服务 -此服务接收丰富的消息,并负责向客户发送通知
充实服务
下图显示了丰富服务流程。
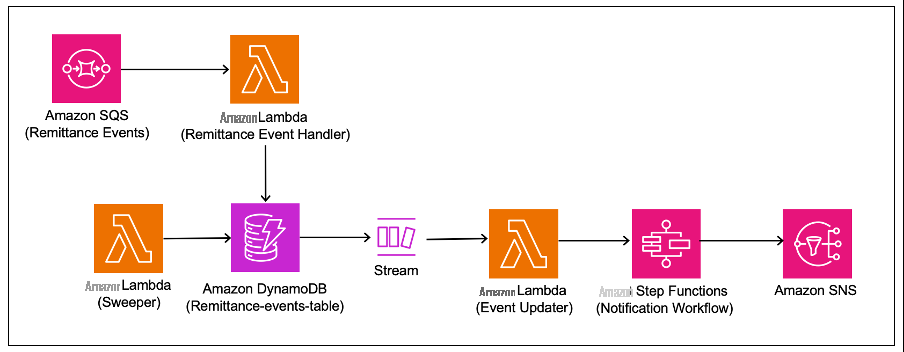
外部合作伙伴通知在
下图显示了我们的表格设计。
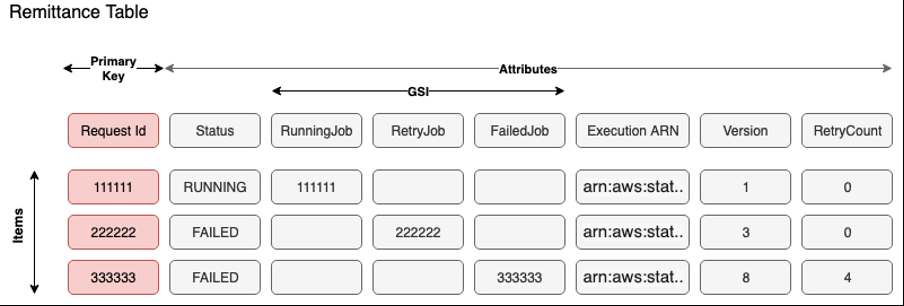
使用
请求 ID
作为主键将新记录插入到 DynamoDB 中,由于事件的原子性质和高基数,因此无需排序键。我们还为每条消息生成并存储一个步骤函数唯一的运行 ARN 名称。事先生成 ARN 有两个主要优点:首先,我们使用 ARN 作为查询来识别 DynamoDB 中的正确记录,以便在监听 Step Functions 事件更新时更新状态。其次,我们将意外重跑和重复处理降至最低,因为 Step Functions 不允许使用相同的 ARN 运行。
“arn: aws: states::: execution:
为了为每条消息生成这个唯一的运行名称,我们使用请求 ID 和其他大部分是静态的值。扫描器和通知工作流程等多个进程可能会访问同一条记录来更新状态。为了启用
versionID
属性,我们使用了适用于 Java 的 DynamoD
由于金融科技的要求之一是提高错误处理能力,因此我们的目标是处理由依赖服务(由工作流程触发)中断等多种原因导致的 Step Functions 工作流程故障。为了实现这一目标,我们在金融科技中引入了被称为 “清理模式” 的内部设计模式,该模式依赖于表格上的全球二级索引(GSI)。
对于汇款表,我们创建了三个 GSI 密钥来识别处于相应状态的作业:重试作业 GSI、失败的作业 GSI 和正在运行的作业 GSI。每当工作流程失败时,丰富服务都会更新相应的表项目,并使用与请求 ID 相同的值修改 “
重试作业
” 属性。要重新运行失败的消息,需要调用名为清理器的 Lambda 函数并扫描 GSI 密钥属性 Retry
Job 以查找未达到 重试
阈值的失败项目。由于 GSI 是
通知服务
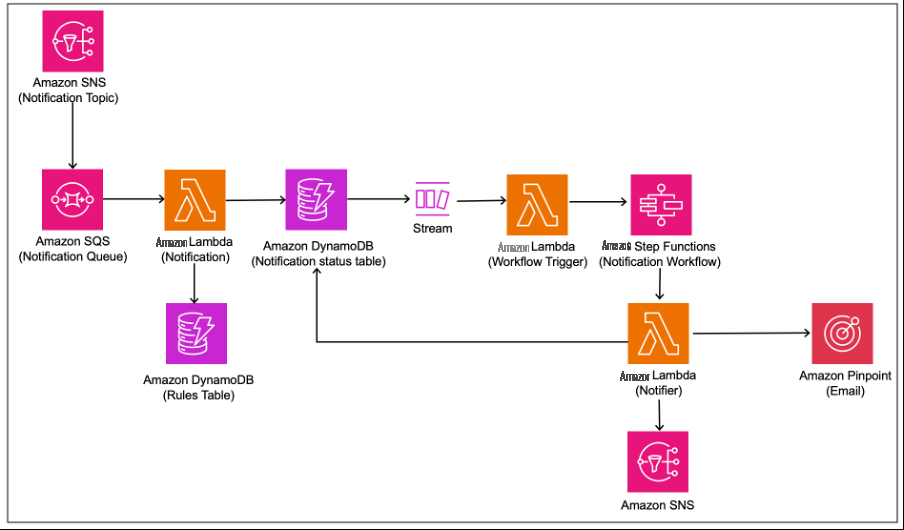
通知服务使用与丰富服务相似的设计和表格架构,在该服务中,输出消息按照类似的模式进行消费和处理,以向客户发送汇款通知。此服务还有其他规则,可根据用户特征、目的或地区验证是否使用了正确的通知模板。
下图显示了通知服务流程。
摘要
亚马逊金融科技团队利用 DynamoDB 数据库来构建可扩展、可靠和事件驱动的汇款服务。他们使用 DynamoDB 流和稀疏的 GSI 简化了解决方案,以实现扫频模式设计。此外,借助 DynamoDB Streams、GSI 和架构灵活性等开箱即用的特性和功能,金融科技团队与其他考虑的选项相比,开发工作减少了 40%,从而得以更快地推出汇款和通知服务。
作者简介


*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。