我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 Triton 在亚马逊 SageMaker 上托管机器学习模型:xgBoost、LightGBM 和 Treelite Models
当今最受欢迎的型号之一是XgBoost。凭借解决分类和回归等各种问题的能力,XgBoost 已成为一种流行的选择,也属于基于树的模型类别。在这篇文章中,我们将深入了解
SageMaker 提供
Triton 支持将各种后端作为引擎,以支持运行和提供各种 ML 模型以进行推理。对于任何 Triton 部署,了解后端行为如何影响您的工作负载以及预期结果至关重要,这样您才能取得成功。在这篇文章中,我们将帮助您了解
深入研究 FIL 后端
FIL 后端使用 cuML 的库来使用 CPU 或 GPU 内核来加速学习。
为了使用这些处理器,需要从主机内存(例如 NumPy 数组)或 GPU 数组(uDF、Numba、CuPy 或任何支持 __cuda_array_interface__)API 的库中引用数据。
将数据暂存到内存中后,FIL 后端可以在所有可用的 CPU 或 GPU 内核上运行处理。
FIL 后端线程可以在不使用主机的共享内存的情况下相互通信,但在集合工作负载中,应考虑主机内存。下图显示了一个集成调度器运行时架构,在该架构中,您可以微调内存区域,包括用于 Triton (C++) 和 Python 进程(Python 后端)之间用于与 FIL 后端交换张量(输入/输出)的 Python 进程(Python 后端)之间进程间通信的 CPU 可寻址共享内存。
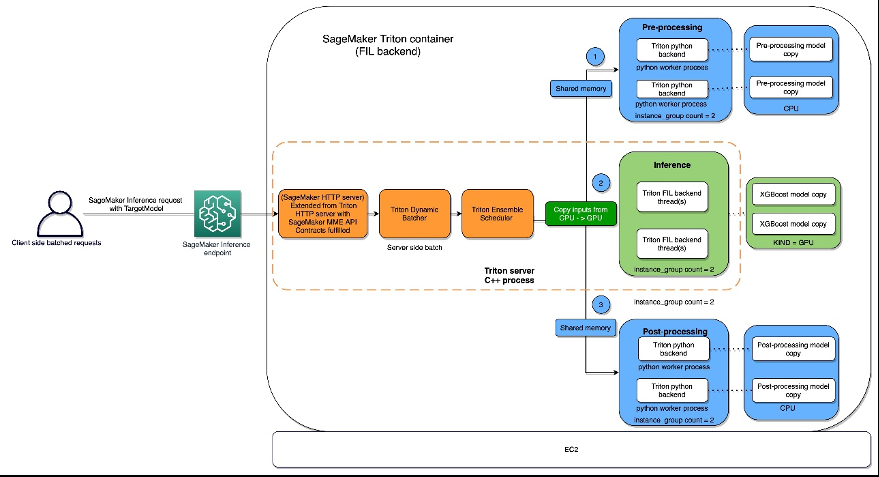
Triton Inference Server 为开发人员提供了可配置的选项,以调整工作负载和优化模型性能。配置 d
ynamic_batching
允许 Triton 保存客户端请求并在服务器端对其进行批处理,以便有效地使用 FIL 的并行计算来推断整个批次。
max_queue_delay_microsec
onds 选项可以安全地控制 Triton 等待形成批次的时间。
还有许多其他特定于 FIL 的
storage
_type 开始。在 GPU 上运行后端时,FIL 会创建一个新的内存/数据结构,该结构表示 FIL 可能影响性能和占用空间的树。这可以通过环境参数
storage_ty
pe 进行配置 ,该参数具有密集、稀疏和自动选项。选择密集选项会消耗更多的 GPU 内存,并且并不总是能带来更好的性能,因此最好检查一下。相比之下,稀疏选项将消耗更少的 GPU 内存,并且性能可能与密集选项一样好或更好。选择 auto 会导致模型默认为密集,除非这样做会消耗的 GPU 内存明显多于稀疏内存。
在模型性能方面,你可以考虑强调
threads_per_tre
e 选项。在现实场景中,你可能会过度使用的一件事是,
threads_per_tree
对吞吐量的影响比任何其他参数都大。将其设置为 1—32 之间的任意 2 次方是合法的。该参数的最佳值很难预测,但是当服务器需要处理更高的负载或处理更大的批量时,它往往会从比一次处理几行时更大的值中受益。
另一个需要注意的参数是
algo
,如果你在 GPU 上运行,它也可用。此参数确定用于处理推理请求的算法。
为此支持的选项有
这些选项决定了树中节点的组织方式,还可以提高性能。
ALGO_AUTO 、
REORG 和 BATCH_TREE_
NAIVE
、TREE_
RE ORG
。
对于稀疏存储,
ALGO_AUTO
选项默认为
NAIVE,对于密集
存储,默认为 BATCH_TREE_REORG 。
最后,FIL 附带了 Shapley 解释器,可以使用 treeshap_output 参数将其激活。
但是,你应该记住,Shapley 输出由于其输出大小而损害了性能。
模型格式
目前没有用于存储基于森林的模型的标准文件格式;每个框架都倾向于定义自己的格式。为了支持多种输入文件格式,FIL 使用开源
c
onfig.pbtxt 文件中指定的
model_type
配置值中进行设置。
config.pbtxt
模型
config.pbtxt
文件中提供的。
- max_batch_siz e — 这决定了可以传递给此模型的最大批量大小。通常,对传递到 FIL 后端的批处理大小的唯一限制是可用于处理批次的内存。对于 GPU 运行,可用内存由 Triton 的 CUDA 内存池的大小决定,启动服务器时可以通过命令行参数进行设置。
- 输入 — 本节中的选项告诉 Triton 每个输入样本的预期特征数量。
-
输出
— 本节中的选项告诉 Triton 每个样本将有多少输出值。如果
predict_proba选项设置为 true,则将返回每个类的概率值。否则,将返回单个值,表示给定样本的预测类别。 - instance_ group — 它决定将创建该模型的实例数量以及它们将使用 GPU 还是 CPU。
-
model_type
— 此字符串表示模型采用的格式(本示例中为 xgboost_json,但是 xgboost、 lightgbm和 tl_checkpoint 也是有效的格式)。 - predict_proba — 如果设置为 true,则将返回每个类别的概率值,而不仅仅是类别预测 。
- output_class — 对于分类模型,此值设置为真,对于回归模型,设置为假。
-
阈值
-这是确定分类的分数阈值。当
output_class设置 为 true 时,必须提供该值,但如果 predict_proba也设置为 true,则不会使用它。 - storage_type — 通常,在此设置中使用 AUTO 应该可以满足大多数用例。如果选择自动存储,FIL 将根据模型的大致大小使用稀疏或密集表示加载模型。在某些情况下,您可能需要将其明确设置为 SPARSE 以减少大型模型的内存占用。
SageMaker 上的 Triton 推理服务器
SageMaker
在为 SageMaker 端点配置自动扩展组时,您可能需要将 SageMa
kerVariantInvocationsPerInstan
ce 作为确定自动扩展组扩展特性的主要标准。此外,根据您的模型是在 GPU 还是 CPU 上运行,您也可以考虑使用 CPU 利用率或 GPU 利用率作为附加标准。请注意,对于单一模型端点,由于部署的模型完全相同,因此设置适当的策略以满足 SLA 非常简单。对于多模型端点,我们建议在给定端点后面部署类似的模型,以获得更稳定的可预测性能。在使用不同大小和要求的模型的用例中,您可能需要将这些工作负载分隔到多个多模型终端节点,或者花一些时间微调您的 Auto Scaling 组策略以获得最佳的成本和性能平衡。
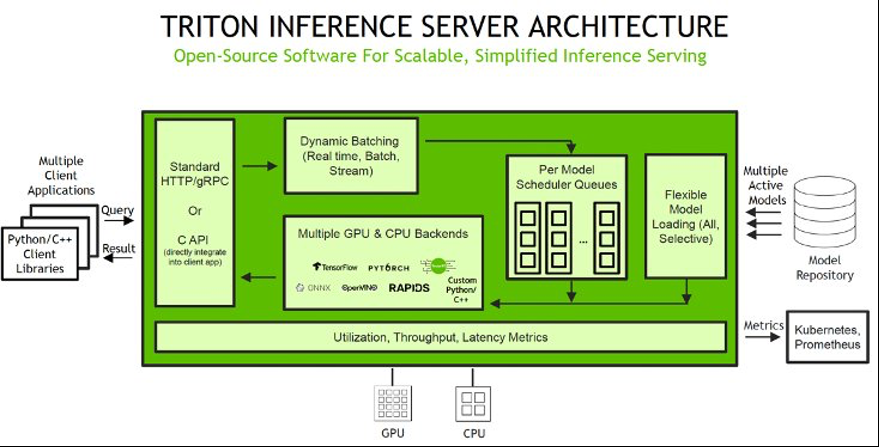
有关 SageMaker 推理支持的 NVIDIA Triton 深度学习容器 (DLC) 列表,请参阅
SageMaker 笔记本电脑攻略
机器学习应用程序很复杂,通常需要数据预处理。在本笔记本中,我们将深入探讨如何在 SageMaker 多模型端点上使用 Triton 中的 FIL 后端部署基于树的机器学习模型,例如 XgBoost。我们还将介绍如何使用 Triton 中的集成功能为模型实现基于 Python 的数据预处理推理管道。这将允许我们从客户端发送原始数据,并在 Triton SageMaker 端点中同时进行数据预处理和模型推断,以实现最佳推理性能。
Triton 模型集合功能
Triton 推理服务器极大地简化了在生产环境中大规模部署 AI 模型。Triton Inference Server 附带一个便捷的解决方案,可简化预处理和后处理管道的构建。Triton Inference Server 平台提供了集成调度器,该调度器负责对参与推理过程的模型进行流水线,同时确保效率和优化吞吐量。使用集成模型可以避免传输中间张量的开销,并最大限度地减少必须发送给 Triton 的请求数量。
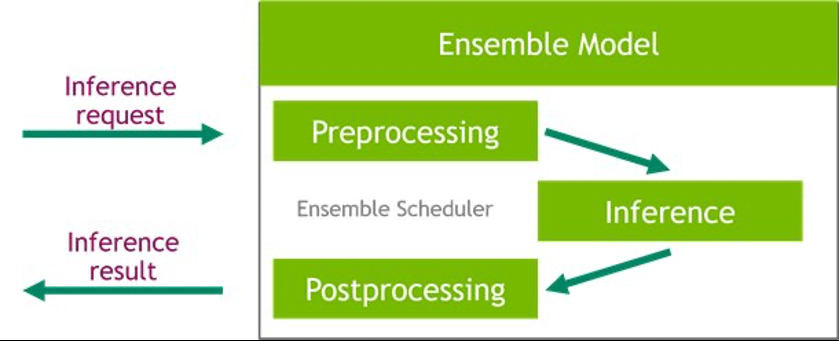
在本笔记本中,我们展示了如何使用集成功能通过 XgBoost 模型推断来构建数据预处理管道,您可以从中推断出来为流水线添加自定义后处理。
设置环境
我们首先设置所需的环境。我们安装了打包模型管道所需的依赖关系,并使用 Triton 推理服务器进行推断。我们还定义了
为预处理依赖关系创建 Conda 环境
Triton 中的 Python 后端要求我们使用
-
我们将介绍如何为你的依赖关系创建 Conda 环境,以及如何以 Triton 的 Python 后
端预期 的 格式 打包它。 - 通过显示在 CPU 上运行 Python 后端而 XGBoost 在 FIL 后端的 GPU 上运行的预处理模型,我们说明了 Triton 集成流水线中的每个模型如何在不同的框架后端以及不同的硬件配置上运行。
-
它重点介绍了 RAPIDS 库(cuDF、cumL)如何与 CPU 同类库(Pandas、scikit-learn)兼容。例如,我们可以展示如何在 cumL 中 创建的
标签编码器在 scikit-learn 中使用,反之亦然。
我们按照
在我们运行前面的脚本后,它会生成
preprocessing_env.tar.gz
,我们将其复制到预处理目录中:
使用 Triton Python 后端设置预处理
为了进行预处理,我们使用 Triton 的
Python 后端支持在 Python 中实现预处理、后处理和任何其他自定义逻辑,并与 Triton 一起使用。在 SageMaker 上使用 Triton 需要我们首先设置一个包含我们要服务的模型的模型存储库文件夹。
我们已经在
cpu
_model_repository 和 gpu_model_repository 中建立了一个名为预处理的 Python 数据预处理模型。

Triton 对模型存储库布局有特定的要求。在顶级模型存储库目录中,每个模型都有自己的子目录,其中包含相应模型的信息。Triton 中的每个模型目录必须至少有一个代表模型版本的数字子目录。值 1 代表我们的 Python 预处理模型的版本 1。每个模型都由特定的后端运行,因此在每个版本的子目录中,必须有该后端所需的模型工件。在此示例中,我们使用 Python 后端,它要求将您提供的 Python 文件命名为 model.py,并且该文件需要实现
我们在此处使用
每个 Triton 模型还必须提供描述模型配置的
config.pbtxt
文件。要了解有关配置设置的更多信息,请参阅
为 FIL 后端设置基于树的 ML 模型
接下来,我们为基于树的 ML 模型(如 XgBoost)设置模型目录,该模型将使用 FIL 后端。
cpu_memory_repository 和 gpu_memory_
repository 的预期布局与我们之前展示
的布局类似。
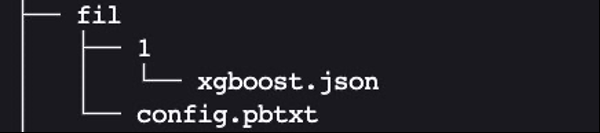
这里,
FIL
是模型的名称。 如果我们愿意,我们可以给它起一个不同的名字,比如
xgboost
。
1
是版本子目录,其中包含模型工件。在本例中,是我们保存的
xgboost.json 模型。
让我们创建这个预期的布局:
我们需要配置文件
config.pbtxt
来 描述基于树的机器学习模型的模型配置,这样 Triton 中的 FIL 后端才能理解如何为其提供服务。有关更多信息,请参阅最新的通用
为 model_cpu_repository 创建
config.pbt
xt:
同样,为 m
odel_gpu_repository 设置
True):
config.pbtxt
(注意区别在 于 USE_GPU =
使用集合设置数据预处理 Python 后端和 FIL 后端的推理管道
集
合
模型目录的预期布局与我们之前展示的布局类似:
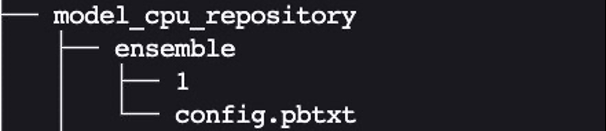

config.pbtxt
中设置集合调度器 ,它指定集合内模型之间的数据流。集合调度器收集每个步骤中的输出张量,并根据规范将其作为输入张量提供给其他步骤。
打包模型存储库并上传到 Amazon S3
最后,我们得到了以下模型存储库目录结构,其中包含 Python 预处理模型及其依赖关系以及 XgBoost FIL 模型和模型集合。
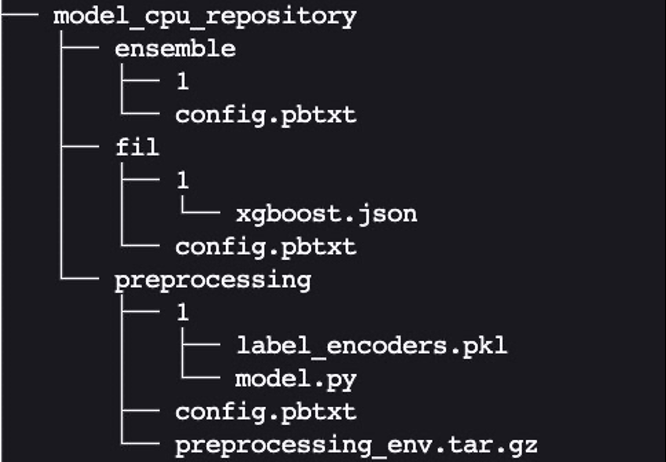
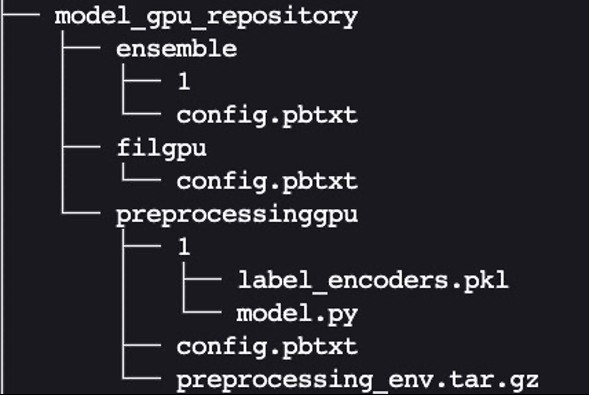
我们将目录及其内容打包为
model.tar.gz
,然后上传到
使用以下代码为基于 CPU 的实例(针对 CPU 进行了优化)创建和上传模型包:
使用以下代码为基于 GPU 的实例(针对 GPU 进行了优化)创建和上传模型包:
创建 SageMaker 端点
现在,我们将模型工件存储在 S3 存储桶中。在此步骤中,我们还可以提供额外的环境变量
SAGEMAKER_TRITON_DEFAULT_MODEL_NAME,它指定 Triton 要加载的模型的名称
。此密钥的值应与上传到 Amazon S3 的模型包中的文件夹名称相匹配。对于单一模型,此变量是可选的。就集成模型而言,必须指定此密钥才能在 SageMaker 中启动 Triton。
此外,你可以设置
SAGEMAKER_TRITON_BUFFER_MANAGER_THREAD_COUNT 和 SAGEMAKER_TRITON_TRITON_THREAD_
COUNT 来优化线程数。
我们使用前面的模型来创建端点配置,在其中我们可以指定我们想要在端点中使用的实例类型和数量。
我们使用此端点配置来创建 SageMaker 端点并等待部署完成。使用 SageMaker MME,我们可以通过重复此过程来选择托管多个集成模型,但对于此示例,我们坚持使用一个部署:
成功部署 后,状态将更改为
InServic
e。
调用 SageMaker 端点上托管的模型
端点运行后,我们可以使用一些示例原始数据,使用 JSON 作为负载格式进行推断。
KfServing 社区标准推理协议
。
博客中提到的笔记本可以在
最佳实践
除了我们前面提到的微调 FIL 后端设置的选项外,数据科学家还可以确保对后端的输入数据进行优化,以供引擎处理。尽可能将行优先格式的数据输入到 GPU 数组中。其他格式将需要内部转换并占用周期,从而降低性能。
由于 FIL 数据结构在 GPU 内存中维护的方式,请注意树的深度。树深度越深,您的 GPU 内存占用量就越大。
使用
instance_group_count
参数添加工作进程并提高 FIL 后端的吞吐量,这将导致 CPU 和 GPU 内存消耗量增加。此外,请考虑可用于提高吞吐量的 Sagemaker 特定变量,例如 HTTP 线程、HTTP 缓冲区大小、批量大小和最大延迟。
结论
在这篇文章中,我们将深入探讨Triton Inference Server在SageMaker上支持的 FIL 后端。此后端为基于树的模型(例如流行的 XgBoost 算法)提供 CPU 和 GPU 加速。要获得最佳的推理性能,有许多选项可供考虑,例如批量大小、数据输入格式和其他可以调整以满足需求的因素。SageMaker 允许您将此功能与单模型和多模型端点结合使用,以平衡性能和成本节约。
我们鼓励您参考这篇文章中的信息,看看SageMaker能否满足您的托管需求,提供基于树的模型,满足您对降低成本和提高工作负载性能的要求。
这篇文章中引用的笔记本可以在 SageMaker 示例
作者简介
 Raghu Ramesha
是亚马逊 SageMaker 服务团队的高级机器学习解决方案架构师。他专注于帮助客户构建、部署机器学习生产工作负载并将其大规模迁移到 SageMaker。他专攻机器学习、人工智能和计算机视觉领域,并拥有德克萨斯大学达拉斯分校的计算机科学硕士学位。在业余时间,他喜欢旅行和摄影。
Raghu Ramesha
是亚马逊 SageMaker 服务团队的高级机器学习解决方案架构师。他专注于帮助客户构建、部署机器学习生产工作负载并将其大规模迁移到 SageMaker。他专攻机器学习、人工智能和计算机视觉领域,并拥有德克萨斯大学达拉斯分校的计算机科学硕士学位。在业余时间,他喜欢旅行和摄影。
 詹姆斯·帕克
是亚马逊网络服务的解决方案架构师。他与 Amazon.com 合作,在 亚马逊云科技 上设计、构建和部署技术解决方案,并对人工智能和机器学习特别感兴趣。在业余时间,他喜欢寻找新的文化、新的体验,并及时了解最新的技术趋势。
詹姆斯·帕克
是亚马逊网络服务的解决方案架构师。他与 Amazon.com 合作,在 亚马逊云科技 上设计、构建和部署技术解决方案,并对人工智能和机器学习特别感兴趣。在业余时间,他喜欢寻找新的文化、新的体验,并及时了解最新的技术趋势。
 达瓦尔·帕特尔
是 亚马逊云科技 的首席机器学习架构师。他曾与从大型企业到中型初创企业等组织合作,研究与分布式计算和人工智能有关的问题。他专注于深度学习,包括自然语言处理和计算机视觉领域。他帮助客户在亚马逊 SageMaker 上实现高性能模型推断。
达瓦尔·帕特尔
是 亚马逊云科技 的首席机器学习架构师。他曾与从大型企业到中型初创企业等组织合作,研究与分布式计算和人工智能有关的问题。他专注于深度学习,包括自然语言处理和计算机视觉领域。他帮助客户在亚马逊 SageMaker 上实现高性能模型推断。
 刘佳虹
是 NVIDIA 云服务提供商团队的解决方案架构师。他帮助客户采用机器学习和人工智能解决方案,这些解决方案利用 NVIDIA 加速计算来应对他们的训练和推理挑战。闲暇时,他喜欢折纸、DIY 项目和打篮球。
刘佳虹
是 NVIDIA 云服务提供商团队的解决方案架构师。他帮助客户采用机器学习和人工智能解决方案,这些解决方案利用 NVIDIA 加速计算来应对他们的训练和推理挑战。闲暇时,他喜欢折纸、DIY 项目和打篮球。
 Kshitiz Gupta 是 NVIDIA
的解决方案架构师。他喜欢向云客户介绍 NVIDIA 提供的 GPU AI 技术,并帮助他们加速机器学习和深度学习应用程序。工作之余,他喜欢跑步、远足和观赏野生动物。
Kshitiz Gupta 是 NVIDIA
的解决方案架构师。他喜欢向云客户介绍 NVIDIA 提供的 GPU AI 技术,并帮助他们加速机器学习和深度学习应用程序。工作之余,他喜欢跑步、远足和观赏野生动物。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。