我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
在亚马逊 SageMaker Studio 上托管 Spark 用户界面
最后,您可以通过将 Studio 笔记本电脑与
所有这些选项允许您生成和存储 Spark 事件日志,以便通过基于 Web 的用户界面(通常称为
解决方案概述
该解决方案将 Spark 历史服务器集成到 SageMaker Studio 中的 Jupyter Server 应用程序中。这允许用户直接从 SageMaker Studio IDE 中访问 Spark 日志。集成的 Spark 历史服务器支持以下内容:
- 访问 SageMaker Processing Spark 作业生成的日志
- 访问 亚马逊云科技 Glue Spark 应用程序生成的日志
- 访问由自行管理的 Spark 集群和亚马逊 EMR 生成的日志
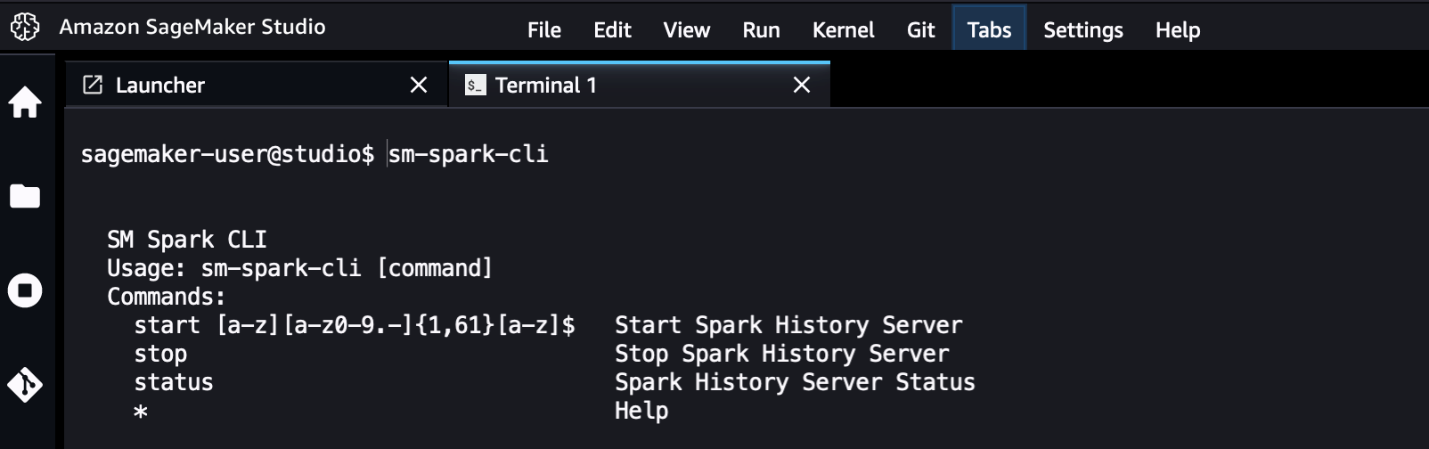
还提供了一个名为 sm-sp
ark-cli 的实用命令行界面 (CLI),用于从 S ageMak
er Studio 系统终端与 Spark 用户界面进行交互。
sm-spark-cli 无需离开 SageMak
er Studio 即可管理 Spark 历史服务器。
该解决方案由执行以下操作的 shell 脚本组成:
- 在 Jupyter 服务器上安装 Spark 以获取 SageMaker Studio 用户配置文件或 SageMaker Studio 共享空间
-
为用户配置文件或共享空间安装
sm-spark-cli
在 SageMaker Studio 域中手动安装 Spark 用户界面
要在 SageMaker Studio 上托管 Spark 用户界面,请完成以下步骤:
- 从 SageMaker Studio 启动器中选择 “ 系统终端 ”。
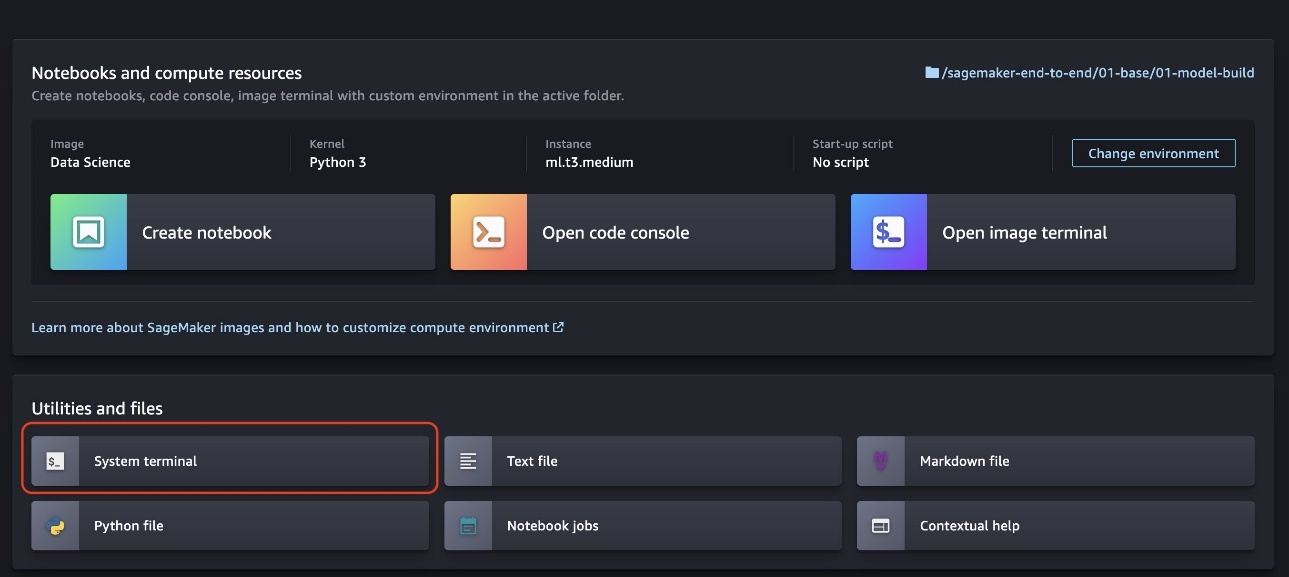
- 在系统终端中运行以下命令:
命令需要几秒钟才能完成。
-
安装完成后,你可以使用提供的
sm-spark-cli 启动 Spark 用户界面, 并通过运行以下代码从 Web 浏览器访问它:
sm-spark-cli 开始 s3://DOC-EXAMPLE-BUCKET/
运行 Spark 应用程序时,可以配置存储 SageMaker Processing、亚马逊云科技 Glue 或 Amazon EMR 生成的事件日志的 S3 位置。
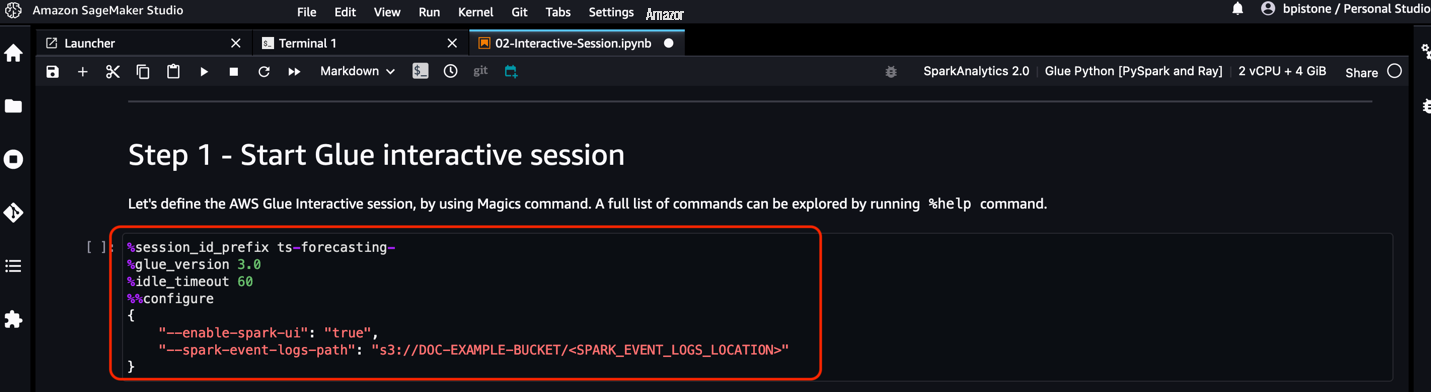
对于 SageMaker Studio 笔记本电脑和 亚马逊云科技 Glue Interactive Sessions,你可以使用 sparkmagic 内核直接从笔记本上设置
Spar
k 事件日志位置。
sparkmagic
内核包含一组用于通过笔记本与远程 Spark 集群进行交互的工具。它提供了神奇的(
%spark
、
%sql
)命令来运行 Spark 代码、执行 SQL 查询以及配置 Spark 设置,例如执行器内存和内核。
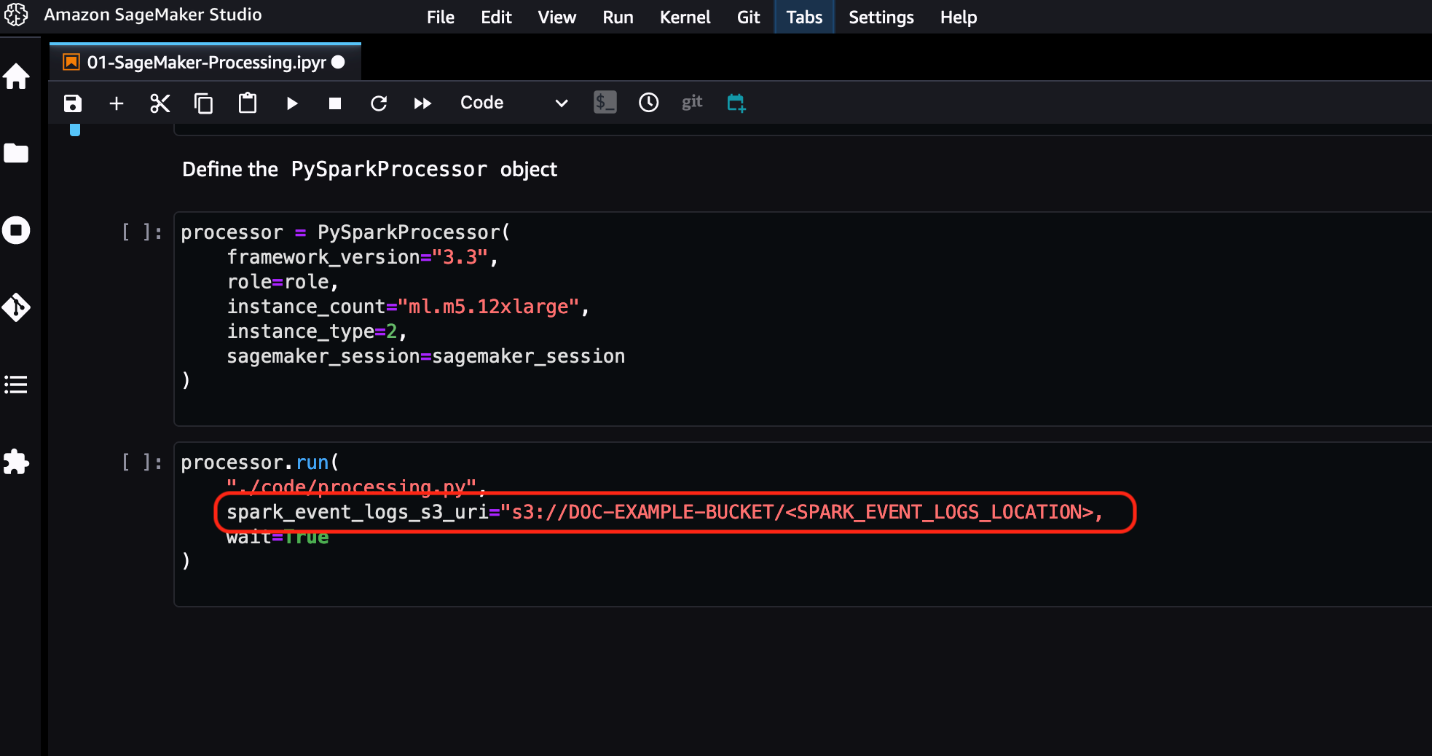
对于 SageMaker Processing 作业,你可以直接从 SageMaker Python SDK 中配置 Spark 事件日志的位置。
有关其他信息,请参阅 亚马逊云科技 文档:
-
有关 SageMaker 处理的信息,请参阅 PysparkProcessor -
有关 亚马逊云科技 Glue 互动会话的信息,请参阅
配置 Spark 用户界面(控制台) -
有关 Amazon EMR,请参阅
配置输出位置

你可以选择生成的网址来访问 Spark 用户界面。
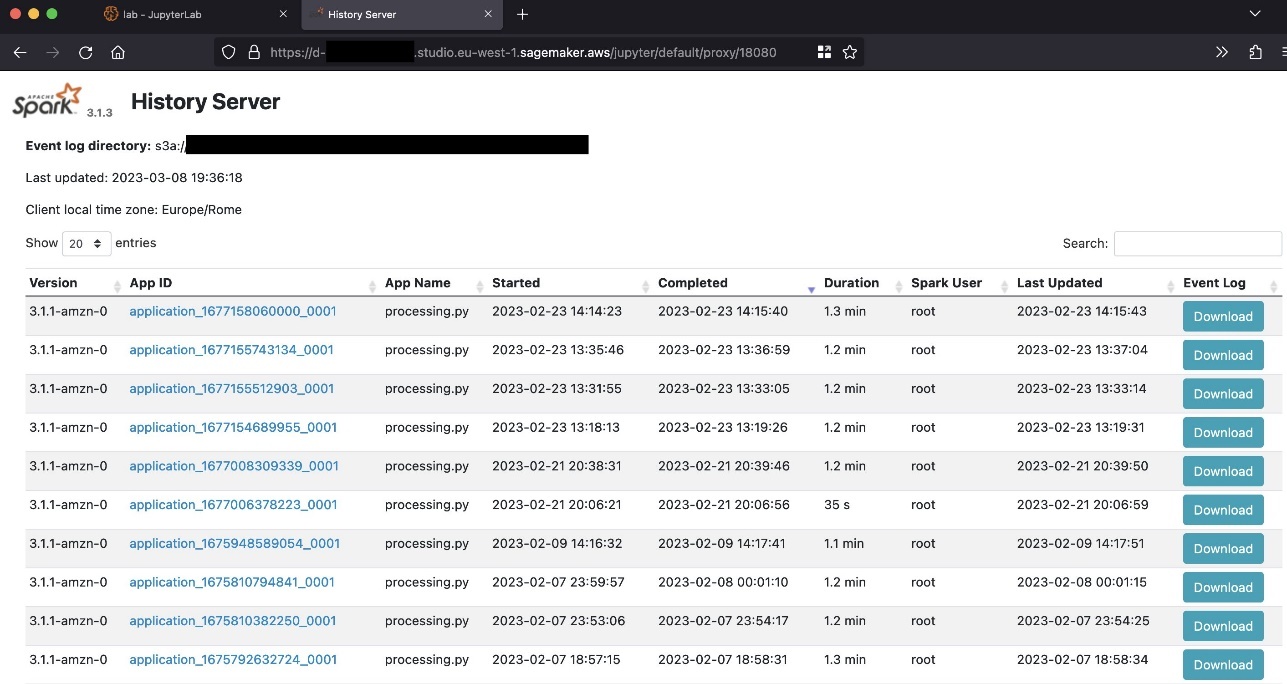
以下屏幕截图显示了 Spark 用户界面的示例。
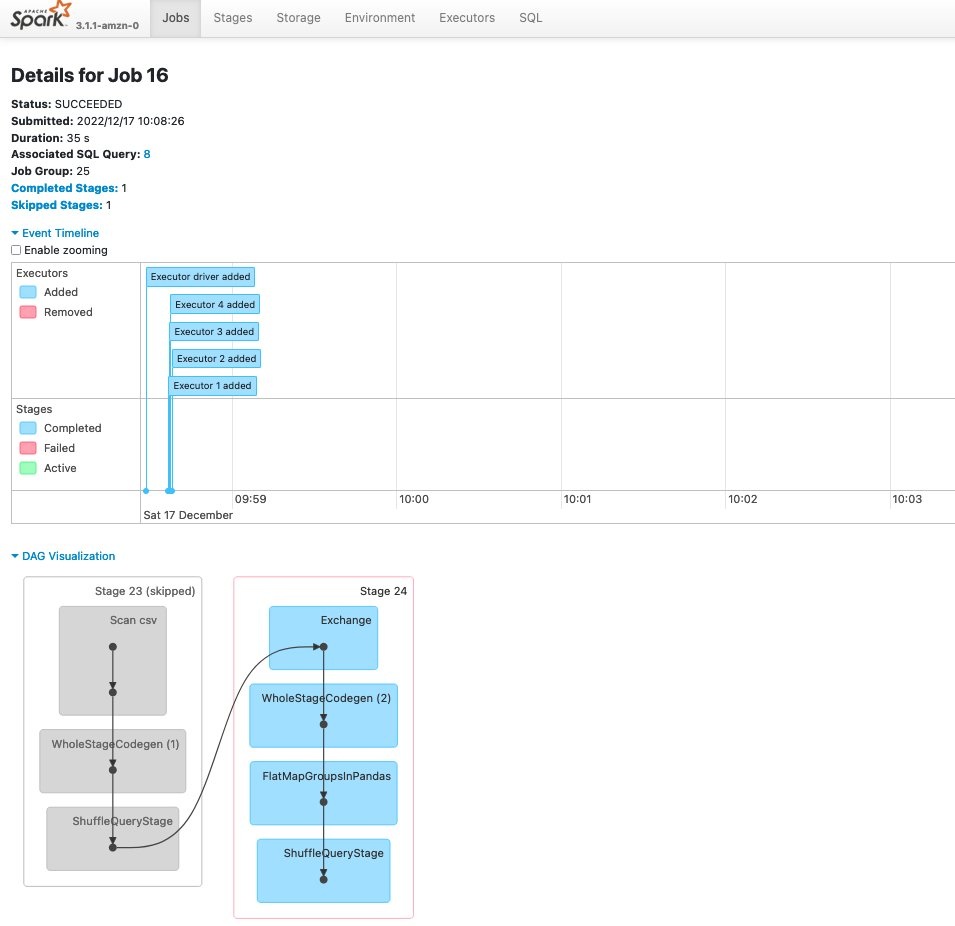
你可以在 Studio 系统终端中使用
sm-spark-cli 状态 命令来检查 Spark 历史服务器的状态
。

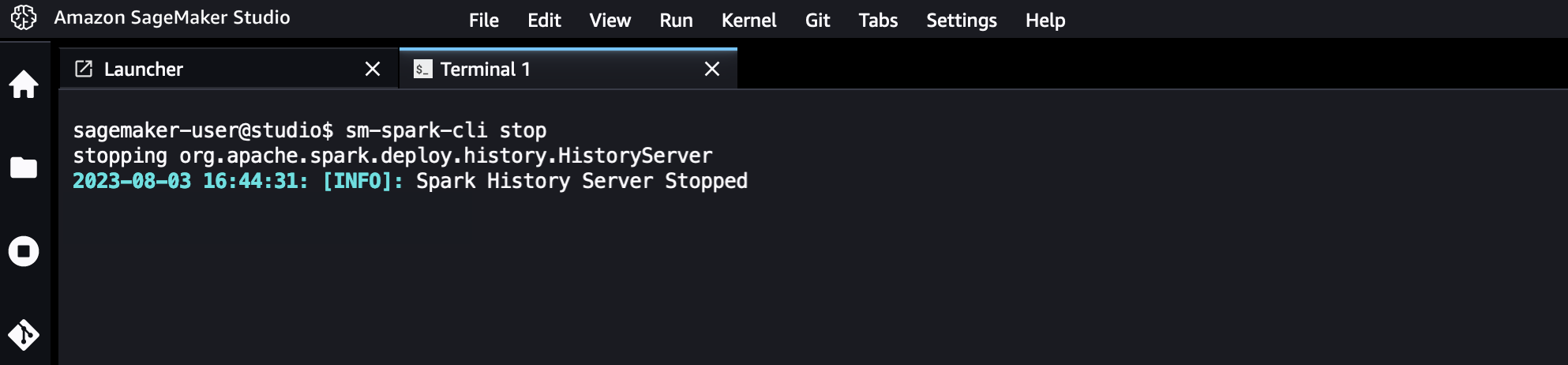
你也可以在需要时停止 Spark 历史服务器。
为 SageMaker Studio 域中的用户自动安装 Spark 用户界面
作为 IT 管理员,您可以使用
您可以通过
在配置了
Jupyter Server 重启后,Spark 用户界面和 sm-spark
-cli 将在你的 SageMak
er Studio 环境中可用。
清理
在本节中,我们将向您展示如何手动或自动清理 SageMaker Studio 域中的 Spark 用户界面。
手动卸载 Spark 用户界面
要在 SageMaker Studio 中手动卸载 Spark 用户界面,请完成以下步骤:
- 在 SageMaker Studio 启动器 中选择 “ 系统终端 ”。
- 在系统终端中运行以下命令:
自动卸载所有 SageMaker Studio 用户个人资料的 Spark 用户界面
要自动卸载 SageMaker Studio 中所有用户个人资料的 Spark 用户界面,请完成以下步骤:
- 在 SageMaker 控制台上, 在导航窗格中选择 域名 ,然后选择 SageMaker Studio 域名。
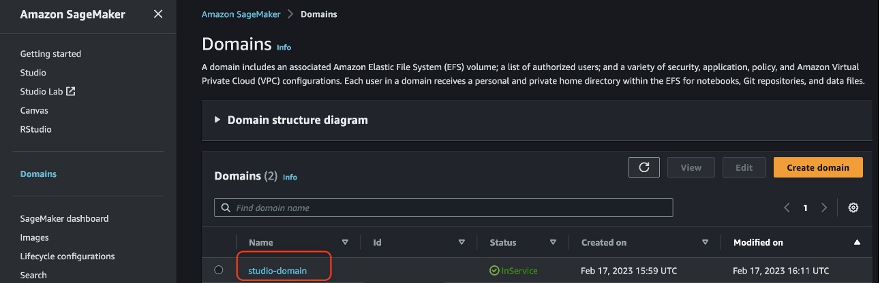
- 在域详细信息页面上,导航到 环境 选项卡。
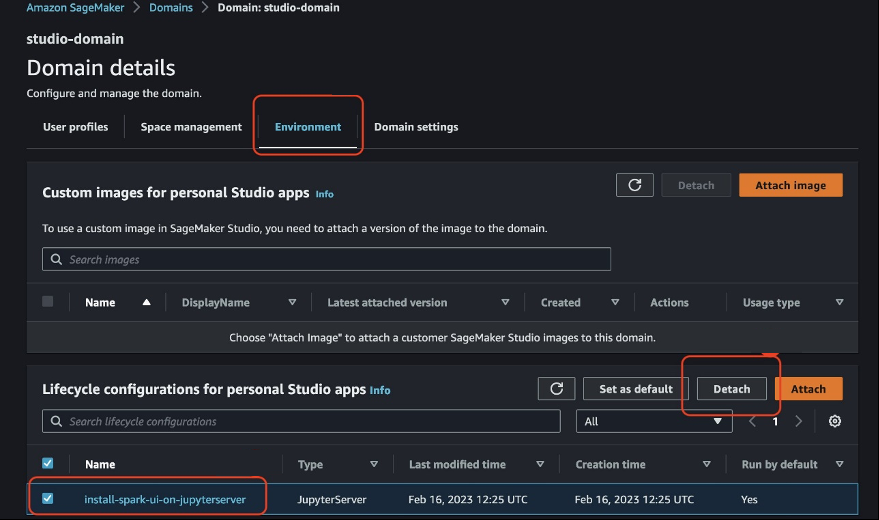
- 在 SageMaker Studio 上选择 Spark 用户界面的生命周期配置。
- 选择 “ 分离 ”。
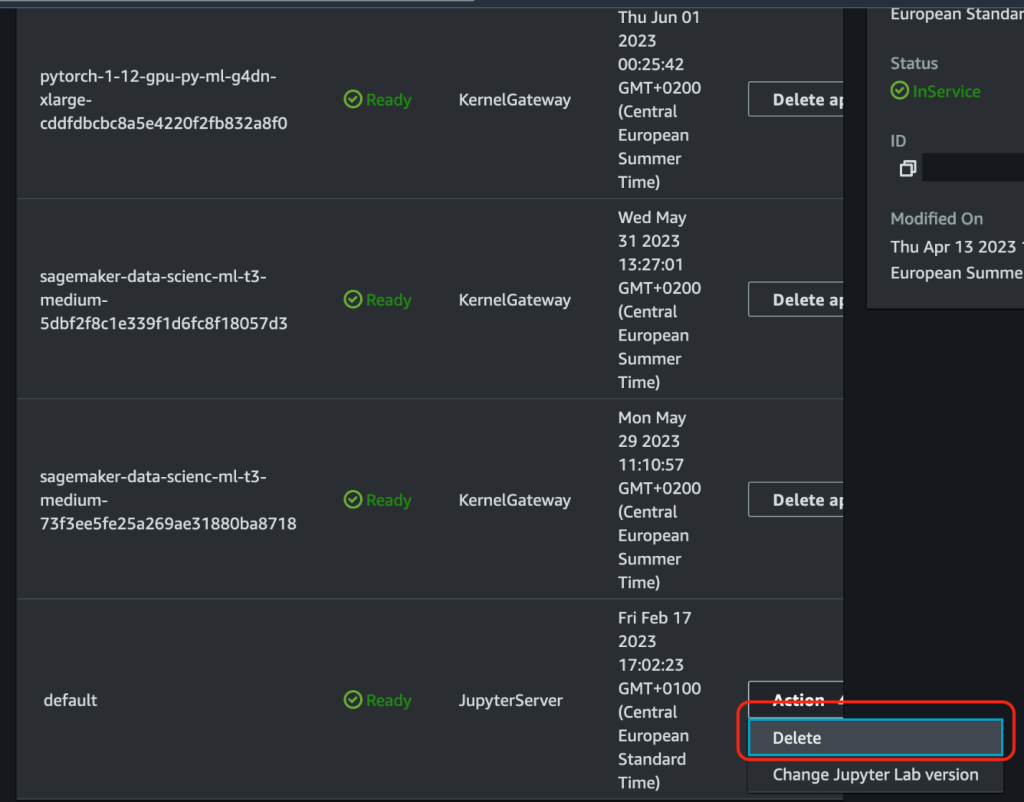
- 删除并重新启动 SageMaker Studio 用户配置文件的 Jupyter 服务器应用程序。
结论
在这篇文章中,我们分享了一个解决方案,你可以用它在 SageMaker Studio 上快速安装 Spark 用户界面。借助 SageMaker 上托管的 Spark UI,机器学习 (ML) 和数据工程团队可以使用可扩展的云计算从任何地方访问和分析 Spark 日志,并加快项目交付。IT 管理员可以标准化并加快云端解决方案的配置,并避免机器学习项目的自定义开发环境激增。
本文中显示的所有代码都可以在
作者简介
 Giuseppe Angelo Porcel li
是亚马逊网络服务的首席机器学习专家解决方案架构师。凭借多年的软件工程和机器学习背景,他与任何规模的客户合作,了解他们的业务和技术需求,设计能够充分利用 亚马逊云科技 云和亚马逊机器学习堆栈的 AI 和 ML 解决方案。他曾参与过不同领域的项目,包括 mLOP、计算机视觉和 NLP,涉及大量 亚马逊云科技 服务。在空闲时间,朱塞佩喜欢踢足球。
Giuseppe Angelo Porcel li
是亚马逊网络服务的首席机器学习专家解决方案架构师。凭借多年的软件工程和机器学习背景,他与任何规模的客户合作,了解他们的业务和技术需求,设计能够充分利用 亚马逊云科技 云和亚马逊机器学习堆栈的 AI 和 ML 解决方案。他曾参与过不同领域的项目,包括 mLOP、计算机视觉和 NLP,涉及大量 亚马逊云科技 服务。在空闲时间,朱塞佩喜欢踢足球。
 Bruno Pistone
是 亚马逊云科技 的人工智能/机器学习专业解决方案架构师,总部位于米兰。他与任何规模的客户合作,帮助他们了解他们的技术需求,设计能够充分利用 亚马逊云科技 云和亚马逊机器学习堆栈的 AI 和 ML 解决方案。他的专业领域包括端到端机器学习、机器学习终端化和生成式人工智能。他喜欢与朋友共度时光,探索新地方,也喜欢去新的目的地旅行。
Bruno Pistone
是 亚马逊云科技 的人工智能/机器学习专业解决方案架构师,总部位于米兰。他与任何规模的客户合作,帮助他们了解他们的技术需求,设计能够充分利用 亚马逊云科技 云和亚马逊机器学习堆栈的 AI 和 ML 解决方案。他的专业领域包括端到端机器学习、机器学习终端化和生成式人工智能。他喜欢与朋友共度时光,探索新地方,也喜欢去新的目的地旅行。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。