我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 亚马逊云科技 Glue 和 亚马逊云科技 Lake Formation Formatch ML 协调数据,构建全方位的客户视图
在当今的数字世界中,数据由大量不同的来源生成,并以指数级的速度增长。各公司面临着一项艰巨的任务,那就是摄取所有这些数据,清理这些数据,并使用这些数据来提供出色的客户体验。
通常,公司会将来自多个来源的数据提取到他们的数据湖中,以便从数据中获得有价值的见解。这些来源通常相互关联,但使用不同的命名惯例,这将延长清理时间,减缓数据处理和分析周期。这个问题尤其影响到试图建立准确、统一的客户360度档案的公司。此数据中有语义重复的客户记录,也就是说,它们代表相同的用户实体,但具有不同的标签或值。它通常被称为数据协调或重复数据删除问题。底层架构是独立实现的,不遵循可用于使用确定性技术删除重复记录的连接的常用密钥。这导致了所谓的模糊重复数据删除技术来解决这个问题。这些技术利用各种基于机器学习 (ML) 的方法。
在这篇文章中,我们将探讨如何使用
解决方案概述
在这篇文章中,我们将介绍各种步骤,应用基于机器学习的模糊匹配来协调汽车和财产保险两个不同数据集中的客户数据。这些数据集是合成生成的,是存储在多个不同的数据源中的实体记录的常见问题,这些数据源具有自己的谱系,这些数据源看起来相似,在语义上代表同一个实体,但没有用于确定性、基于规则的匹配的匹配密钥(或一致起作用的密钥)。下图显示了我们的解决方案架构。
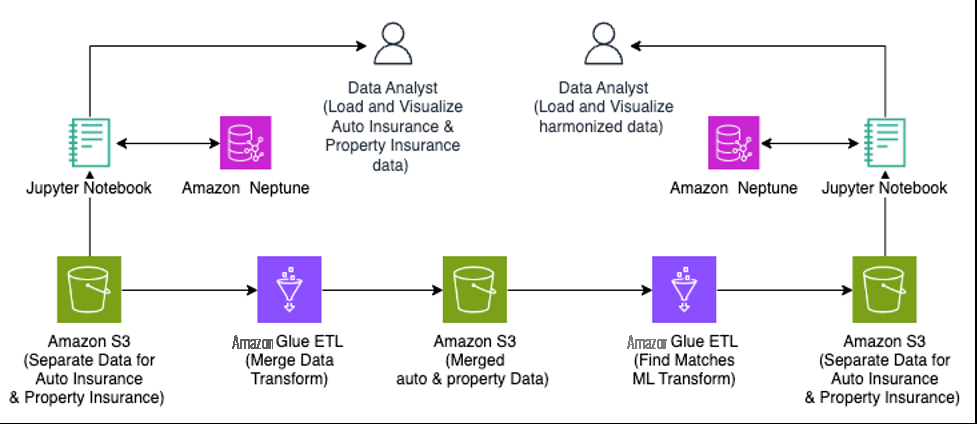
我们使用 亚马逊云科技 Glue 任务来转换汽车保险和财产保险客户源数据,以创建一个合并的数据集,其中包含两个数据集共有的字段(标识符),人类专家(数据管家)将使用这些字段来确定语义匹配。然后,使用合并后的数据集使用 亚马逊云科技 Glue ML 转换来消除重复的客户记录,从而创建统一的数据集。我们使用海王星对合并和协调之前和之后的客户数据进行可视化,以了解转型
为了演示解决方案,我们使用两个独立的数据源:一个用于财产保险客户,另一个用于汽车保险客户,如下图所示。
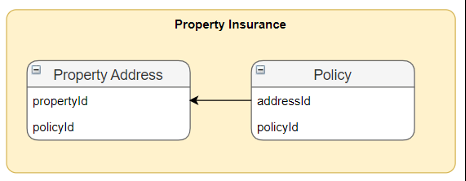
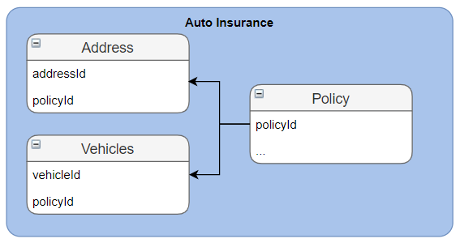
数据存储在
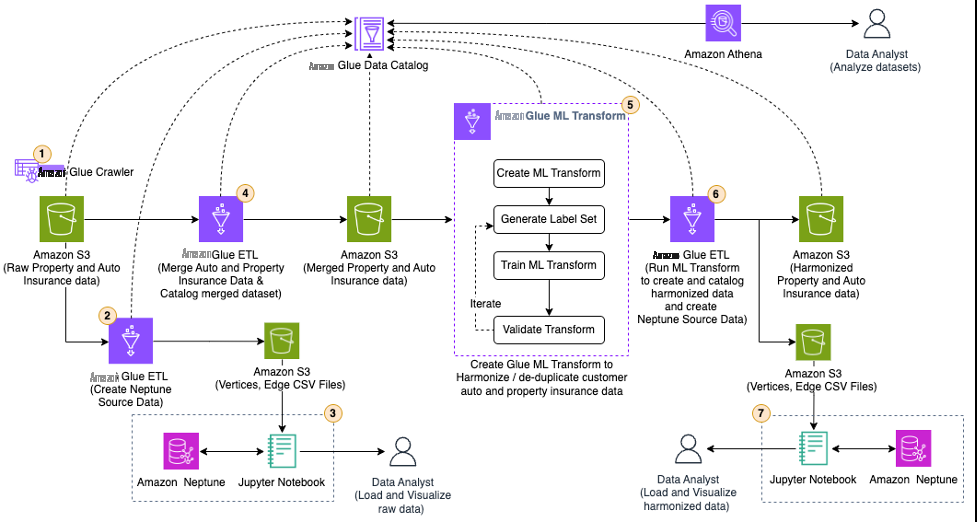
工作流程包括以下步骤:
-
使用 亚马逊云科技 Glue 爬虫将原始财产和汽车保险数据作为 亚马逊云科技 Gl
ue 数据目录 中的 表格进行编目。 -
使用 亚马逊云科技 Glue 提取、转换和加载 (ETL) 任务 ,将原始保险数据转换为
Neptune 批量加载器 可接受的 CSV 格式。 -
当数据采用 CSV 格式时,使用
亚马逊 S ageMaker Jupyter 笔记本运行 PySpark 脚本将原始数据加载到海王星并在木星笔记本中进行可视化。 - 运行 亚马逊云科技 Glue ETL 任务,将原始财产和汽车保险数据合并为一个数据集并对合并后的数据集进行分类。该数据集将有重复项,并且汽车和财产保险数据之间不建立任何关系。
- 创建并训练 亚马逊云科技 Glue ML 转换以协调合并后的数据,删除重复数据并在相关数据之间建立关系。
- 运行 亚马逊云科技 Glue ML 转换作业。该工作还对数据目录中的统一数据进行编目,并将统一的保险数据转换为海王星批量装载机可以接受的CSV格式。
- 当数据采用 CSV 格式时,使用 Jupyter 笔记本运行 PySpark 脚本,将协调后的数据加载到海王星中,然后在 Jupyter 笔记本中进行可视化。
先决条件
要继续进行本演练,您必须拥有 亚马逊云科技 账户。您的账户应有权预置和运行
使用 亚马逊云科技 CloudFormation 预置所需的资源:
要在您的 亚马逊云科技 账户中启动配置此解决方案所需资源的 CloudFormation 堆栈,请完成以下步骤:
- 登录您的 亚马逊云科技 账户并选择 Launch Stack:
![]()
- 按照 亚马逊云科技 CloudFormation 控制台上的提示创建堆栈。
- 启动完成后,导航到已启动堆栈的 Outputs 选项卡,并记下堆栈配置的资源的所有键值对。
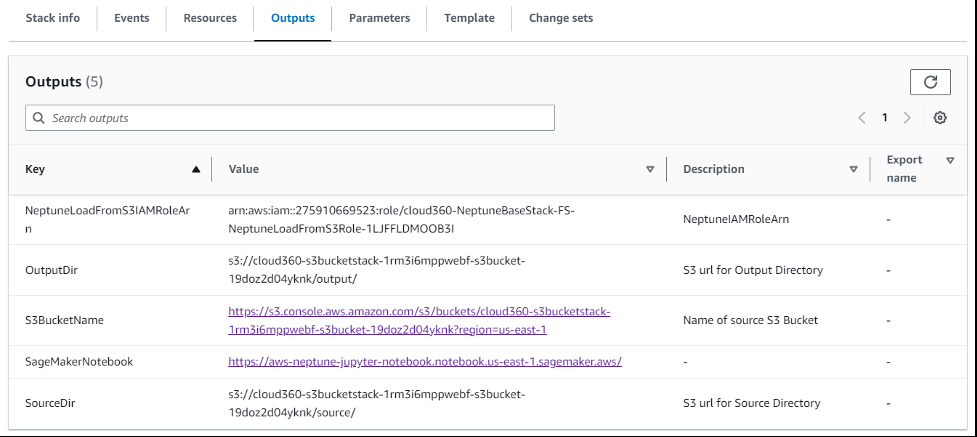
验证原始数据和脚本文件 S3 存储桶
在 CloudFormation 堆栈的输出选项卡上,选择 s3BucketName 的值。S3 存储桶名称应为 c
loud360-s3bucketstack-xxxxxxxxxxxxxxxxxxxxxxxx
,并且应包含与以下屏幕截图类似的文件夹。
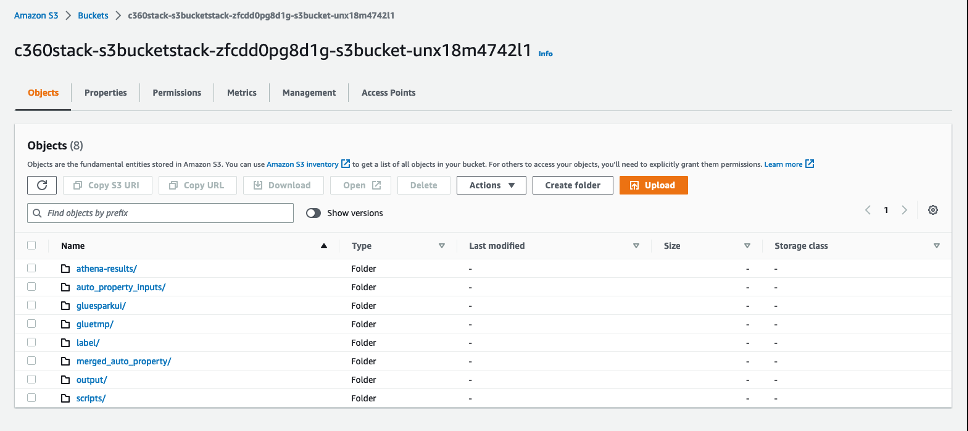
以下是一些重要的文件夹:
- auto_property_inputs — 包含原始的汽车和属性数据
- merged_auto_property — 包含汽车和财产 保险的合并数据
- 输出 -包含分隔的文件(单独的子目录)
对原始数据进行编目
为了帮助了解解决方案,CloudFormation堆栈创建并运行了一个亚马逊云科技 Glue爬虫来对财产和汽车保险数据进行分类。要了解有关创建和运行 亚马逊云科技 Glue 爬虫的更多信息,请参阅在 AW
- source_auto_addres s — 包含购买汽车保险的客户的地址数据
- source_auto_customer — 包含客户的 汽车保险详情
- source_auto_vehicles — 包含客户的车辆 详细信息
- source_property_add ress — 包含购买财产保险的客户的地址数据
- source_property_customers — 包含客户的 财产保险详细信息
你可以使用
将原始数据转换为海王星的 CSV 文件
CloudFormation 堆栈创建并运行了 亚马逊云科技 Glue ETL 任务 p
rep_neptune_data,将原始数据 转换为海王星批量加载器接受的 CS
V 格式。要了解有关使用 亚马逊云科技 Glue Studio 构建 亚马逊云科技 Glue ETL 任务的更多信息以及查看为此解决方案创建的任务,请参阅使用
导航到 “运行” 选项卡并检查最近运行的状态,以验证作业运行的完成。
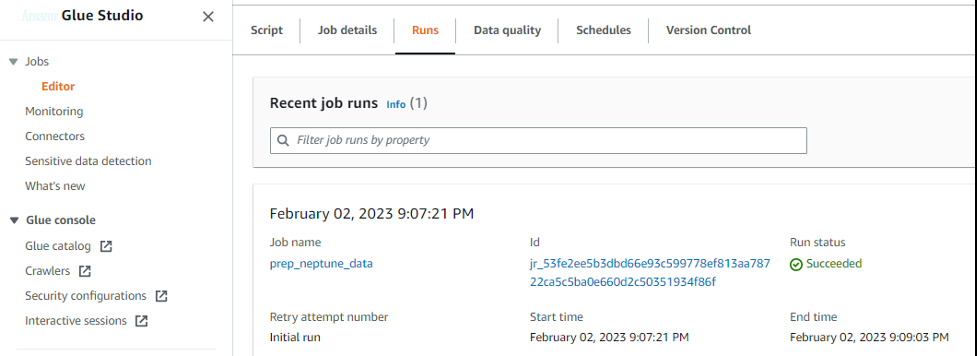
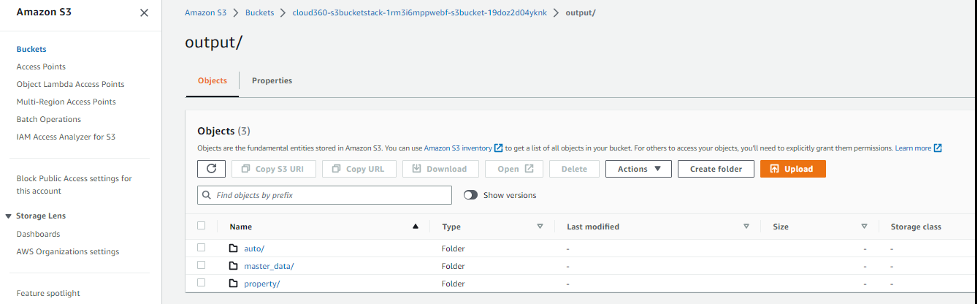
验证 亚马逊云科技 Glue 任务在输出文件夹下的 S3 存储桶中创建的 CSV 文件。
在海王星中加载和可视化原始数据
本节使用 SageMaker Jupyter 笔记本来加载、查询、浏览和可视化海王星中的原始财产和汽车保险数据。Jupyter 笔记本是基于 Web 的交互式平台。我们使用 Python 脚本来分析 Jupyter 笔记本中的数据。CloudFormation 堆栈已经配置了装有必要 Python 脚本的 Jupyter 笔记本。
-
启动 Jupy ter 笔记本。 -
在 “文件” 选项卡上选择
Neptune文件 夹。
-
在
Customer360文件夹下,打开笔记本 explore_raw_insurance_data.ipynb。
- 在笔记本中运行步骤 1—5,分析和可视化原始保险数据。
其余说明位于笔记本本身。以下是笔记本中每个步骤的任务摘要:
- 步骤 1:检索配置 -运行此单元运行命令以连接到 Neptune for Bulk Loader。
- 步骤 2:加载源自动数据 -将汽车 保险数据作为顶点和边缘加载到海王星中。
- 步骤3:加载源财产数据 -将财产保险数据作为顶点和边缘加载到海王星中。
- 第 4 步:用户界面配置 — 此块用于设置 UI 配置并提供 UI 提示。
-
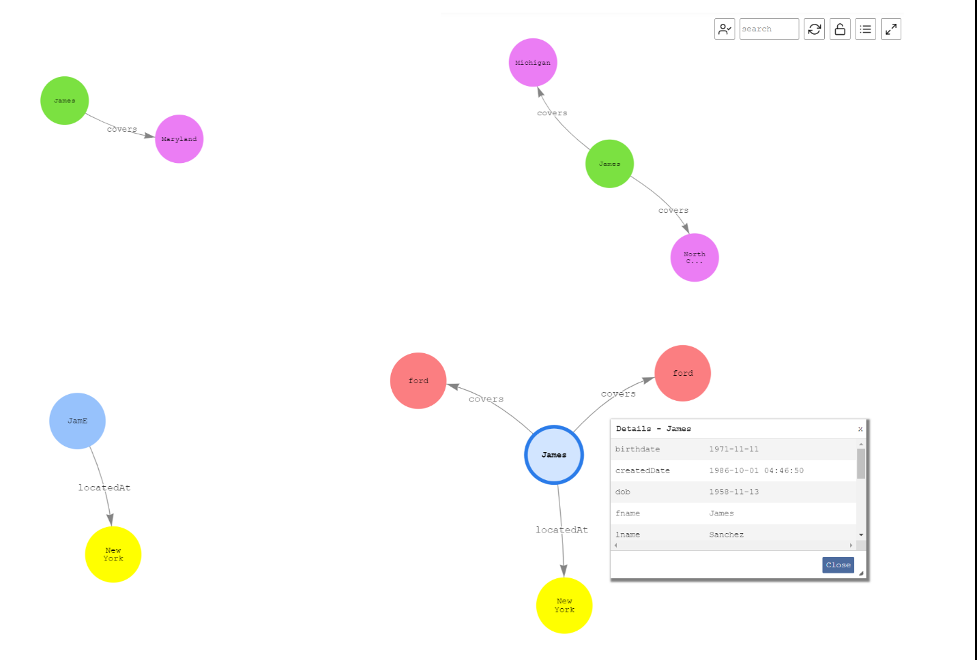
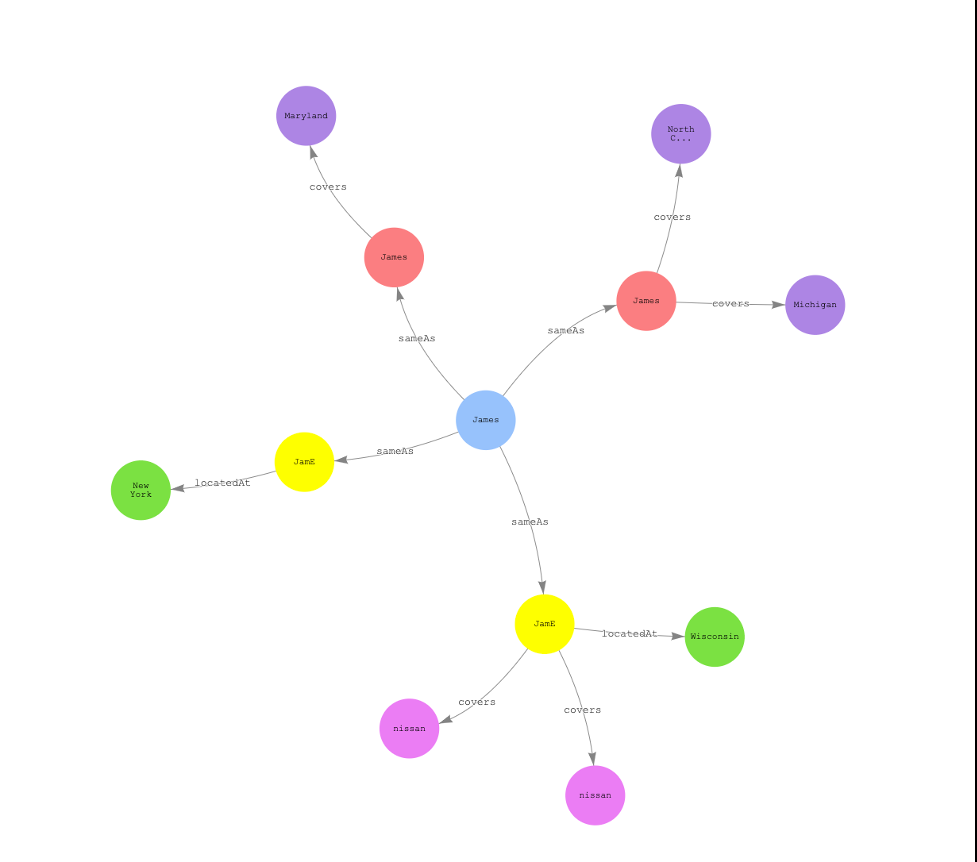
第 5 步:浏览整个图表
— 第一个区块为拥有四份以上的汽车或财产保险单的所有客户构建并显示一张图表。第二个区块显示名为
James的客户的四条不同记录的图表 。
这些记录都是同一个客户的记录,但是由于它们没有以任何方式关联,因此它们显示为不同的客户记录。亚马逊云科技 Glue FindMatches 机器学习转换任务会将这些记录识别为客户
James
,这些记录可以全面查看
James
拥有的所有政策。海王星图看起来像下面的例子。顶点
保险
代表所有者(在本例 中为
詹姆斯
)对汽车或财产保险的承保范围,顶点
Located
At 代表车主保险所承保的财产或车辆的地址。
合并原始数据并抓取合并的数据集
CloudFormation 堆栈创建并运行了 亚马逊云科技 Glue ETL 任务
merge_auto_p
roperty,将原始财产和汽车保险数据合并为一个数据集,并将生成的数据集编入数据目录。亚马逊云科技 Glue ETL 任务对原始数据进行以下转换,并将转换后的数据合并为一个数据集:
-
更改源表 s
ource_auto_customer 上的以下字段:
-
-
将
策略 ID更改为 id 并将数据类型更改为字符串将 f name 更改为 -
first_name 将 lname -
更改 为姓氏更改适用于公司 -
更改 -
dob todate_of_birth 将电话改 为 h ome_phone 删除出生 -
将
-
日期、优先级 -
、政策起始日期和创建日期字段
-
更改 s
ource_property_customers 上的以下字段:
-
将 -
customer_id 更改为 id并将数据类型 更改为字符串 将社交更改为 -
ssn
删除
职务
、
电子邮件
、
行业
、
城市
、
州
、邮政编码等字段,
netnew
、sales_corned、
sales_
d
ecimal 、priorit
y 和 indu
-
将每个表中的唯一 ID 字段转换为字符串类型并将其重命名为 ID 后,AWS Glue 任务会将后缀-auto_customer 表中的所有property 附加 到ID字段追加后缀-源_propert y_customer 表中的所有ID字段,然后将两个表中的所有数据复制 到 m erged_auto_property 表中。
使用以下 Athena SQL 查询验证作业在数据目录中创建的新表,并使用 Athena 查看合并的数据集:
有关如何查看
merged_auto_property 表中数据的更多信息,请参阅使用 Amazon Athena 运行 S
QL 查询。
创建、教授和调整 Lake Formation ML 变换
合并后的 亚马逊云科技 Glue 任务创建了一个名为
merged_auto_property
的数据目录。在 Athena 查询编辑器中预览表格,并从 Athena 控制台以 CSV 格式下载数据集。您可以打开 CSV 文件以快速比较重复项。
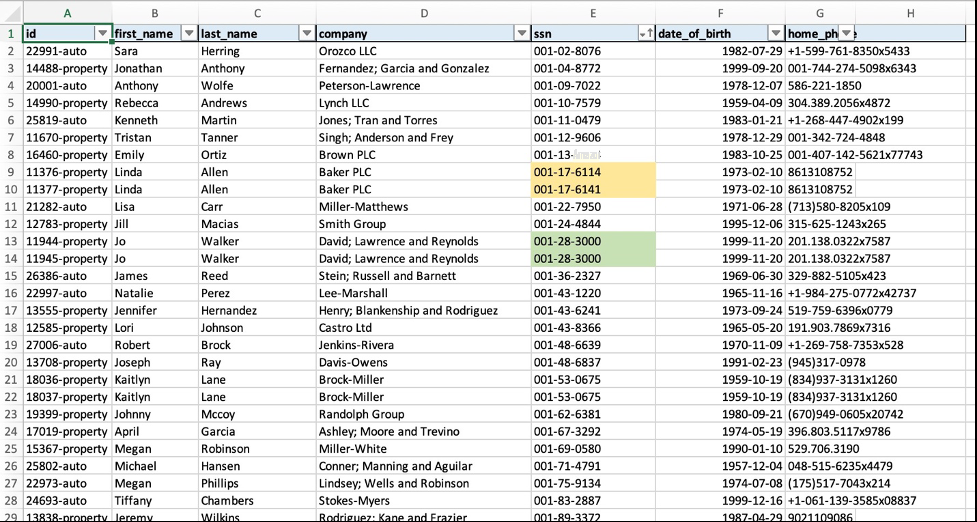
ID为11
37
的最后两位数字之外基本相同,但 这些主要是人为错误。如果人类专家或数据管理员了解这些数据在各种源系统中是如何生成、清理和处理的,则很容易发现模糊匹配项。尽管人类专家可以在小型数据集中识别出这些重复项,但在处理成千上万条记录时却变得乏味。亚马逊云科技 Glue ML 转换建立在这一直觉的基础上,提供了一种易于使用的基于 ML 的算法,可以自动将这种方法高效地应用于大型数据集。
6属 性和113777属性的
行除了 SSN
创建 findMatches 机器学习变换
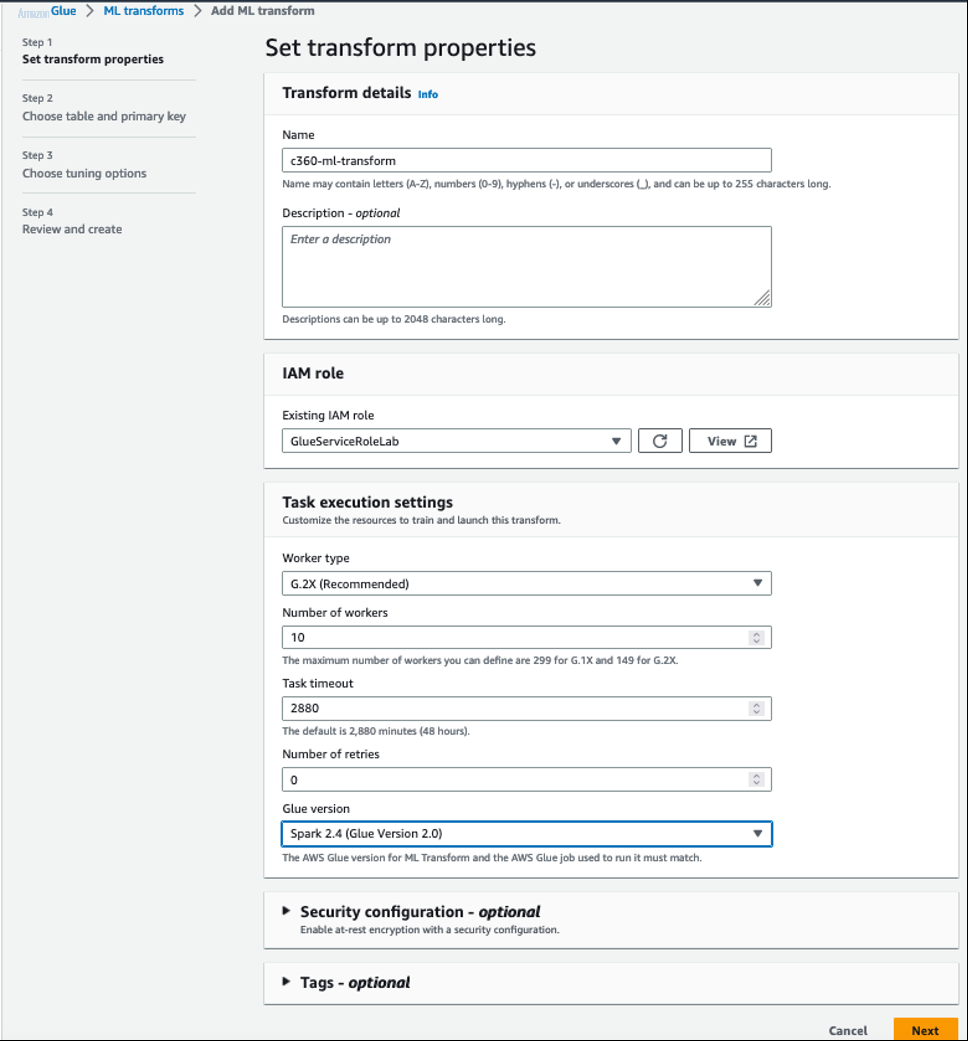
- 在 亚马逊云科技 Glue 控制台上,展开导航窗格 中的 数据集成 和 ETL 。
- 在 数据分类 工具下,选择 记录匹配 。
这将打开 M L 转换 页面。
- 选择 “ 创建转换 ” 。
-
对于
名称
,输入
c360-ml-transform。 -
对于
现有 IAM 角色
,请选择
GlueServiceRoleLab。 - 对于 工作人员类型 ,选择 G.2X(推荐) 。
-
对于
工作人员人 数
,输入
10。 - 对于 Glue 版本 ,请选择 Spark 2.4(Glue 版本 2.0) 。
- 将其他值保留为默认值,然后选择 “ 下一步 ” 。
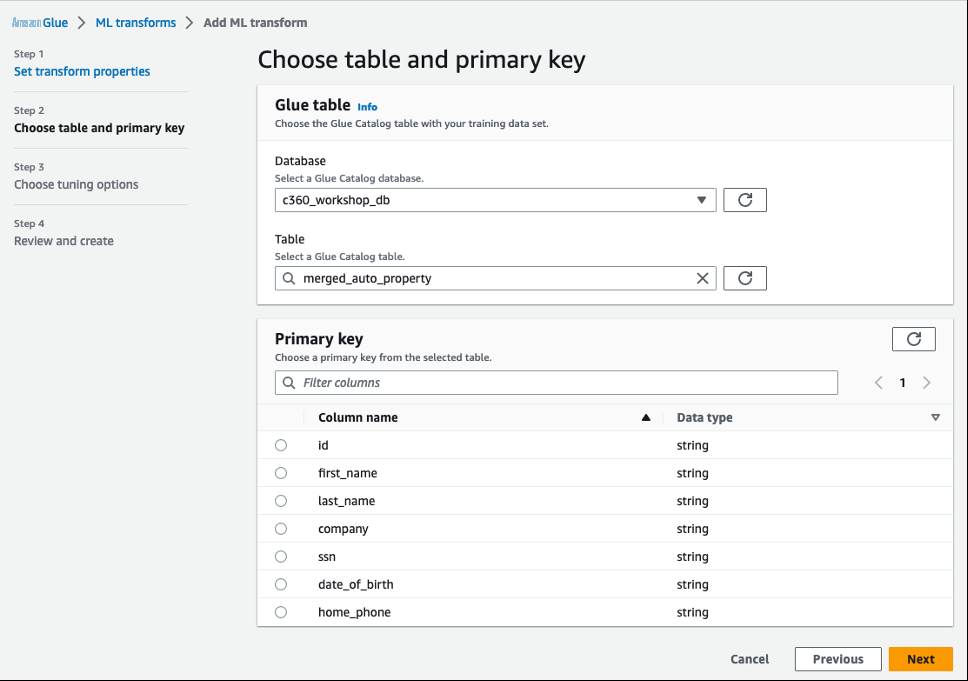
-
对于
数据库
,选择
c360_workshop_db。 -
对于
表格
,选择
merged_auto_property。 -
对于
主键
,选择
id。 - 选择 “ 下一步 ” 。
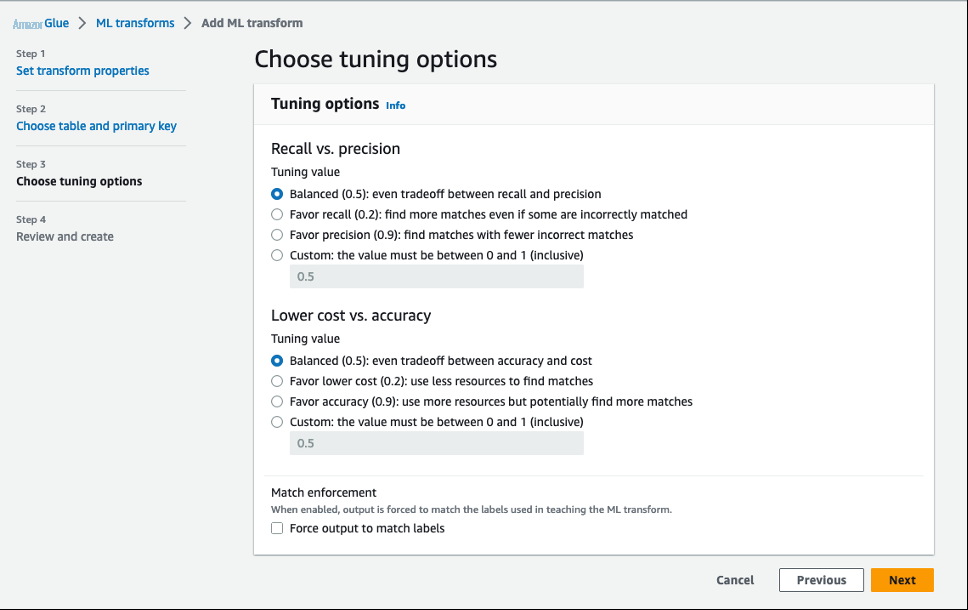
- 在 选择调整选项 部分中,您可以调整可用于 ML 转换的性能和成本指标。我们采用默认的权衡取舍,以实现平衡的方法。
我们指定了这些值以实现平衡的结果。如果需要,您可以稍后通过选择变换并使用
Tune 菜单来调整
这些值。
- 查看值并选择 创建 ML 转换 。
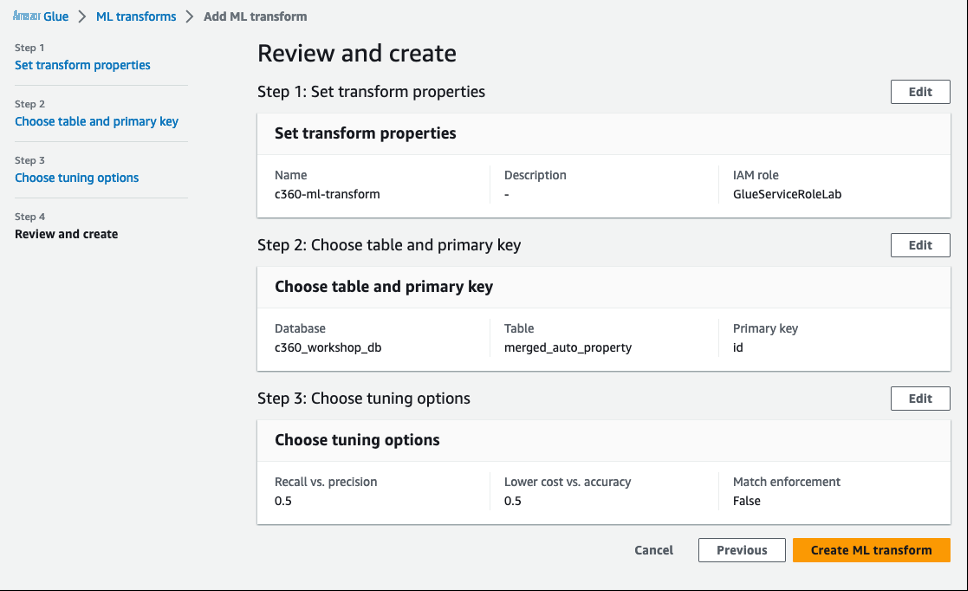
现在,ML 转换的创建状态为 “
需要训练
” 。
教导变换识别重复项
在此步骤中,我们通过提供带有标签的匹配和非匹配记录示例来教授转换。您可以自己创建标签集,也可以让 亚马逊云科技 Glue 根据启发式方法生成标签集。亚马逊云科技 Glue 从您的源数据中提取记录并建议潜在的匹配记录。该文件将包含大约 100 个数据样本供您使用。
- 在 亚马逊云科技 Glue 控制台上,导航到 机器学习转换 页面。
-
选择变换
c360-ml-transform并选择 Train 模型。

- 选择 “ 我有标签 ”, 然后选择 “ 浏览 S3 ” 以从 Amazon S3 上传标签。
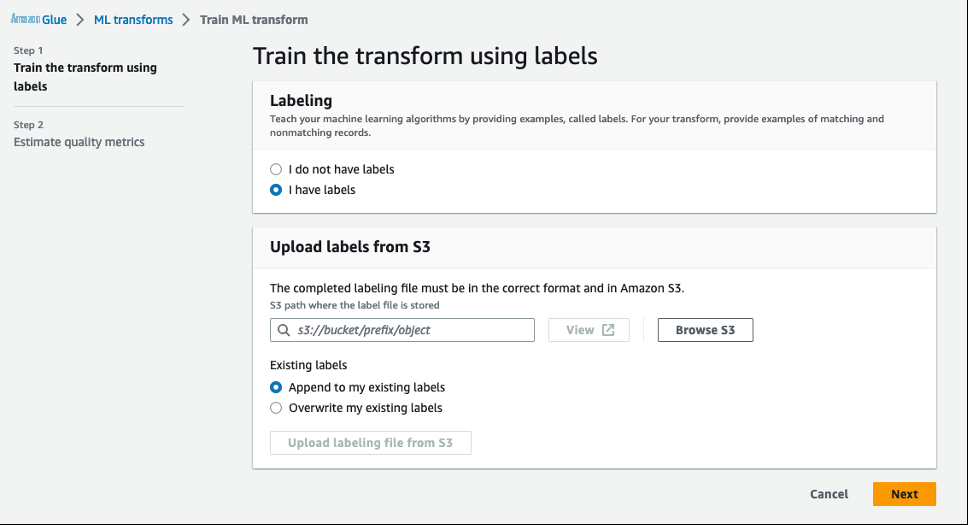
已为此示例创建了两个带标签的文件。我们上传这些文件来教学 ML 转换。
-
导航到 S3 存储桶 中的文件夹
标签,选择带有标签的文件 (Label-1-iteration.csv),然后选择 “ 选择” 。然后单击 “ 从 S3 上传标签文件 ”。

-
成功上传时会出现绿色横幅。

-
上传另一个标签文件 (
Label-2-iteration.csv),然后选择 “ 追加到我的现有标签 ”。 - 等待成功上传,然后选择 下一步 。

- 查看 “ 估算质量指标 ” 部分中的详细信息,然后选择 “ 关闭 ” 。
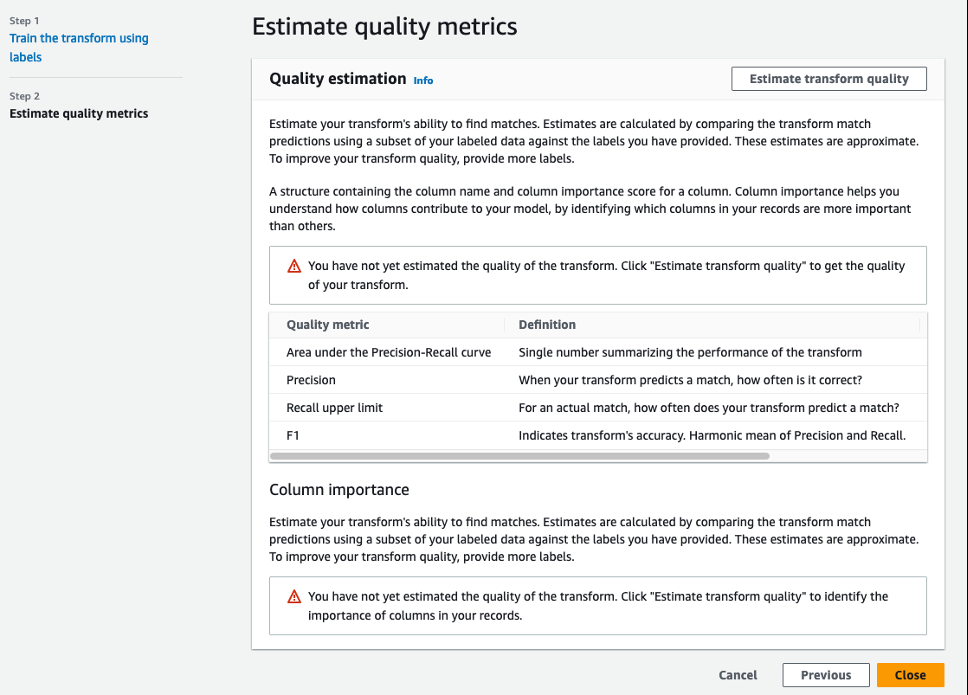
验证 ML 转换状态是否为 “
准备就绪
” 。请注意,标签数为 200,因为我们成功上传了两个带标签的文件来教导转换。现在我们可以在 亚马逊云科技 Glue ETL 任务中使用它来模糊匹配完整数据集。

在继续执行后续步骤之前,请记下创建的 ML 转换的转换 ID (
tfm-xxxxxxx
)。
协调数据,对统一的数据进行编目,并将数据转换为海王星的 CSV 文件
在此步骤中,我们运行 亚马逊云科技 Glue ML 转换作业,在合并的数据中查找匹配项。该作业还对数据目录中的统一数据集进行编目,并将合并后的 [A1] 数据集转换为 CSV 文件,以供海王星显示匹配记录中的关系。
- 在 亚马逊云科技 Glue 控制台上,选择导航窗格 中的 任务 。
-
选择作业
perform_ml_dedup。
- 在作业详细信息页面上,展开 其他属性 。
- 在 “ 作业参数 ” 下 ,输入您之前保存的转换 ID 并保存设置。
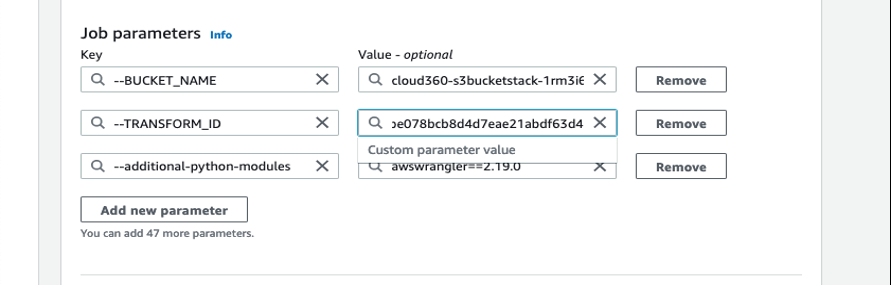
-
- 选择 “ 运行 ” 并监视作业状态是否已完成。
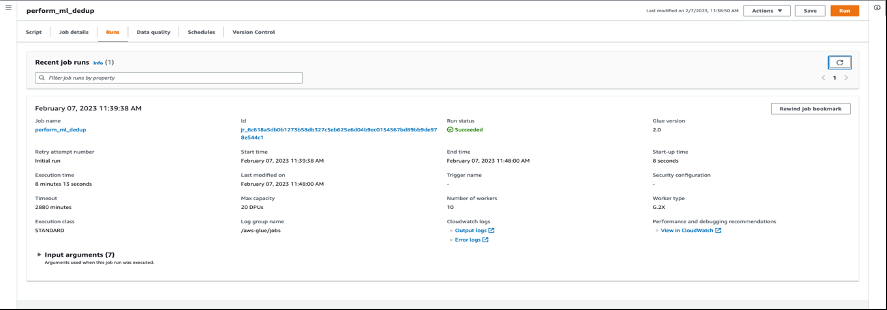
-
在 Athena 中运行以下查询,查看由 亚马逊云科技 Glue 任务创建 和编目的新表
ml_matched_auto_property 中的数据,并观察结果:
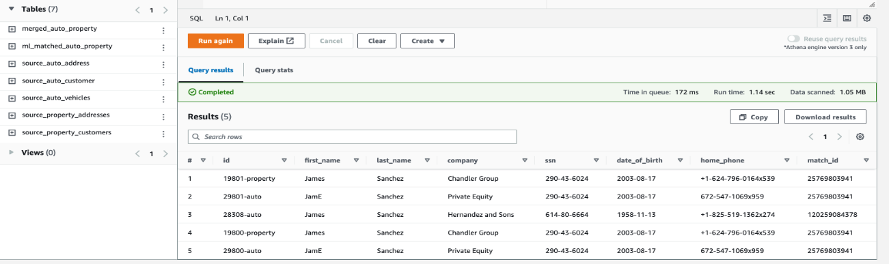
 Nishchai JM
是亚马逊网络服务的分析专家解决方案架构师。他擅长构建大数据应用程序,并帮助客户在云端实现应用程序的现代化。他认为数据是新石油,并将大部分时间都花在从数据中获得见解上。
Nishchai JM
是亚马逊网络服务的分析专家解决方案架构师。他擅长构建大数据应用程序,并帮助客户在云端实现应用程序的现代化。他认为数据是新石油,并将大部分时间都花在从数据中获得见解上。
 Varad Ram
是亚马逊网络服务的高级解决方案架构师。他喜欢帮助客户采用云技术,对人工智能特别感兴趣。他相信深度学习将推动未来的技术增长。在业余时间,他喜欢和女儿和儿子一起在户外。
Varad Ram
是亚马逊网络服务的高级解决方案架构师。他喜欢帮助客户采用云技术,对人工智能特别感兴趣。他相信深度学习将推动未来的技术增长。在业余时间,他喜欢和女儿和儿子一起在户外。
 纳伦德拉·古普塔
是亚马逊云科技的专业解决方案架构师,专注于亚马逊云科技分析服务,帮助客户踏上云之旅。工作之余,纳伦德拉喜欢学习新技术、看电影和参观新地方
纳伦德拉·古普塔
是亚马逊云科技的专业解决方案架构师,专注于亚马逊云科技分析服务,帮助客户踏上云之旅。工作之余,纳伦德拉喜欢学习新技术、看电影和参观新地方
 Arun A K
是 亚马逊云科技 的大数据解决方案架构师。他与客户合作,为在云端运行分析解决方案提供架构指导。在空闲时间,Arun 喜欢与家人共度美好时光
Arun A K
是 亚马逊云科技 的大数据解决方案架构师。他与客户合作,为在云端运行分析解决方案提供架构指导。在空闲时间,Arun 喜欢与家人共度美好时光
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。