我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 Amazon DynamoDB 预置容量应对流量高峰
如果您使用预置容量的
流量峰值越突然越长,牌桌出现节流的可能性就越大。但是,即使流量激增,节流也不是不可避免的。在这里,我们将向您介绍八种应对流量峰值的设计,并介绍它们的优缺点:
- 利用自动扩展和突发容量
- 调整您的自动扩展目标利用率
- 切换到按需模式
- 让任何后台工作自动节流
- 有后台工作慢起步
- 如果可以预测峰值时机,请使用自动扩展计划
- 如果您无法预测峰值时机,请主动申请自动缩放调整
- 战略上允许一定程度的油门
DynamoDB 节流阀的背景信息
使用 DynamoDB,有两种情况可能会限制读取和写入请求。首先,当对表的请求速率超过表的预置容量时。其次,当分区的请求速率超过所有分区上存在的硬限制时。在这篇文章中,我们将重点介绍牌桌级别的油门。这些是与突然的流量高峰最相关的限制。
要了解有关表和分区限制的更多信息,请参阅
使用 DynamoDB 预置表,您可以通过分配预置吞吐容量来明确控制表上的读取和写入能力。您可以分配读取吞吐量(以
1。利用自动扩展和突发容量
流量通常全天都在波动,使用预置容量表处理此问题的经典方法是开启 自动扩展功能 。Auto Scaling 会观察表上消耗的容量,并根据需要上下调整预配置容量。您可以配置最小值(不要低于此值)、最大值(不要超过此值)和目标利用率(尽量将消耗量保持为预配置总量的百分比)。Auto Scaling 会进行调整,以应对终端用户全天常见的流量差异和峰值。
如果 Auto Scaling 连续观察到消耗的容量超过目标利用率 2 分钟,则会向上调整预配置容量。如果连续观察到 15 分钟的利用率超过目标利用率线的 20%(如 2,000 个基点,不是相对的),它就会向下调整预置容量。可以随时扩大规模。缩减有更严格的规则,如
“您每天可以在 DynamoDB 表上减少的预置容量数量有默认配额。一天是根据协调世界时 (UTC) 定义的。在给定的一天,只要你在一小时内还没有进行任何其他减法操作,你就可以从一小时内最多减小四次开始。随后,只要前一小时没有减少,您就可以每小时再减少一次。这实际上使一天内的最大减少次数达到 27 次(第一个小时减少 4 次,之后的 1 小时窗口每减少一次)。表和全局二级索引减少限制是分开的,因此特定表的任何全局二级索引都有自己的减少限制。”
自动扩展使用
Auto Scaling 的目标利用率功能提供填充,旨在适应该时间段内的流量高峰。如果您的表格消耗了 70,000 个 WCU,则目标利用率为 70% 的自动扩展将预置 100,000 个 WCU。在自动扩展可以提供更高的配置之前,额外的 30,000 个 WCU 将用于应对流量高峰。这可以防止除最极端的流量峰值之外的所有流量都受到限制。
当峰值超过填充值时,DynamoDB 会提供突发容量,允许表暂时超出其预配置级别,但数量有限。有关更多信息,请参阅
图 1 显示了典型的自动扩展行为。锯齿状的橙色线条是指消耗的写入流量,全天从 300,000 个 WCU 波动到 650,000 个 WCU。水平蓝线是由 Auto Scaling 控制的预置写入容量。它根据需要上下移动。
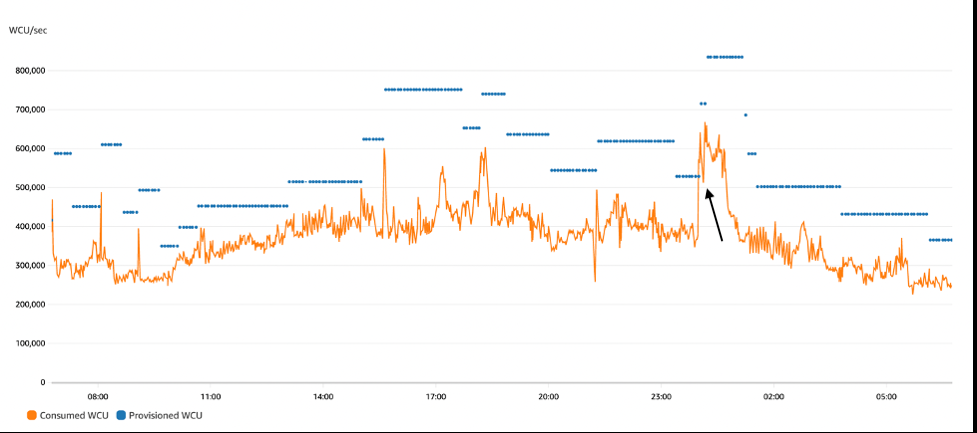
图 1:自动扩展行为:锯齿状的橙线表示写入消耗,水平蓝线表示预置容量
午夜过后(进入图表的四分之三),如果我们仔细观察,我们就能看到节流的影响。橙色消费线从37.5万个WCU急剧跃升至640,000个WCU,远远超过了设定的52万个WCU的蓝色预置容量线。由于突发容量,这种暂时的过剩是允许的。峰值持续存在,几分钟后突发容量耗尽,导致橙色消耗线恢复到预配置线路约一分钟,Auto Scaling 才能够向上提高蓝色的预配置线,从而让消耗量反弹。(黑色箭头指向此事件。)
图 2 显示了长达一小时的综合测试,该测试旨在生成节流阀,将用户负载从 4,000 个 WCU 增加到 18,000 个 WCU。该综合测试包括随机抖动,例如真实的用户负载,但都是人为生成的,因此我们可以调整各种行为并测试结果。
第一次测试的表启用了自动扩展,目标利用率为70%。图表顶部显示了由此产生的消耗容量(波动的蓝线)以及预配置的容量(红线平方)。图表底部显示了同一时间段内表上的油门数量。尖峰很陡而且足够长,足以引起油门。
披露:红线是手工绘制的,用于显示每分钟的扩展活动,与自动扩展事件日志中描述的完全一致。CloudWatch 不会以最小的粒度接收预置容量信息。
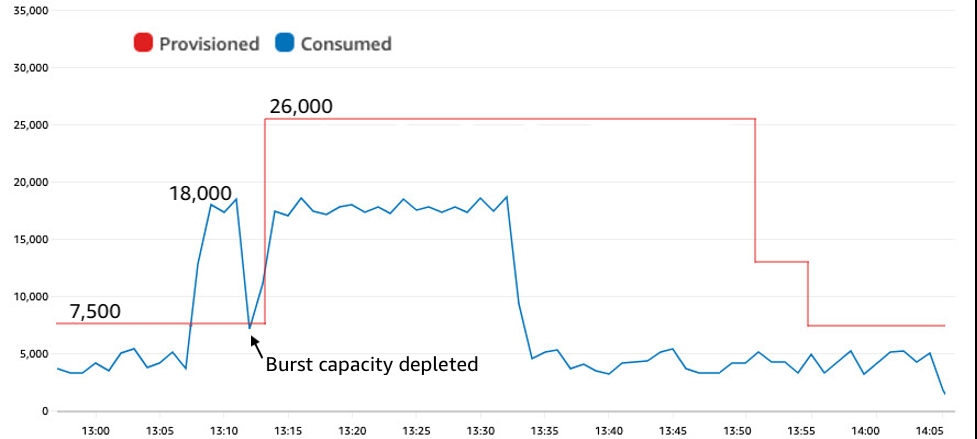
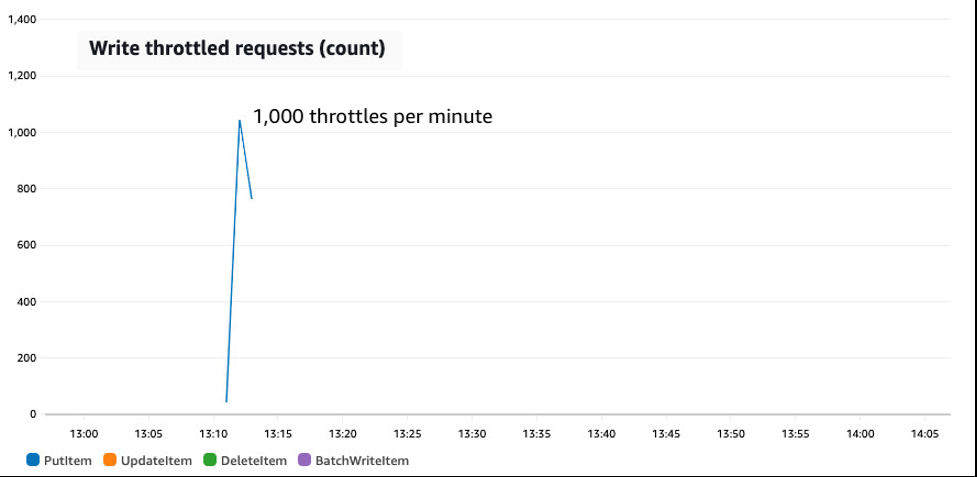
图 2:综合测试显示,在配置了自动扩展且目标利用率为 70% 的表格上,流量从 4,000 个 WCU 突然跃升至 18,000 个
测试开始时,流量相当平坦,消耗4,000至5,000个WCU。自动扩展使预置容量保持在 7,500 个 WCU 左右。简单的流量波动由填充处理。然后,在 13:07,写入流量立即跃升至 18,000 个 WCU。最初没有油门。突发容量允许过量使用。但是,在 13:11,突发容量耗尽,写入速率降至预置量,所有其他请求都受到限制。限制将持续到 13:13,那时 Auto Scaling 将预配置容量增加到 26,000 个 WCU,足以应对峰值,还会有填充,以防出现另一个峰值。最后,在峰值消退大约 15 分钟后,Auto Scaling 会降低预配置金额。
本文的其余部分将探讨当你的表具有访问模式时的设计,包括像这样的超出默认自动扩展所能处理的极其敏锐和持续的读取或写入流量增长场景。
2。调整您的自动扩展目标利用率
需要考虑的一项调整是将自动扩展目标利用率设置得更低。如果你在无法预料的情况下遇到终端用户流量峰值,并希望通过避开限制来保持低延迟,那么这种方法效果很好。
自动扩展目标利用率控制您的表格在处理峰值时保留的边距量。其范围可以从20%到90%不等。值越低意味着填充量越大。40% 的目标将为填充分配当前流量水平的 1.5 倍,因此,积极消耗 10,000 个 WCU 的表格将提供 25,000 个 WCU 来实现该 40% 的目标。较低的目标利用率有三个好处:
- 它提供了更多的填充物来处理尖峰。
- 如果峰值超过预置水平,它将增加突发容量限额,因为突发容量配额与预置容量成正比。
- 它允许更快地提高自动缩放速度。Auto Scaling 会查看消耗的容量超过了目标利用率,以决定要增加多少。它不考虑油门次数。如果你有更多的填充,那么可以看到更多的意外峰值,并用它来计算大幅跳跃。如果你的填充物很少,则峰值会显得更加平静(它不会消耗容量,反而会产生节流),而自动扩展将以较小的步伐加强。
缺点是成本增加。根据预配置金额向您收费,因此填充越多意味着成本越高。此外,每次Auto Scaling向上调整预配置容量以应对流量激增时,可能需要等待一段时间才能再次向下调整。在此期间,更多的填充物也会增加额外的成本。选择正确的目标利用率是在限制和成本之间取得平衡。
如果您选择调整自动扩展目标利用率,请不要忘记考虑 GSI 和基表。
图 3 重新创建了与之前相同的流量模式,但现在使用的目标利用率为 60%。它没有油门。
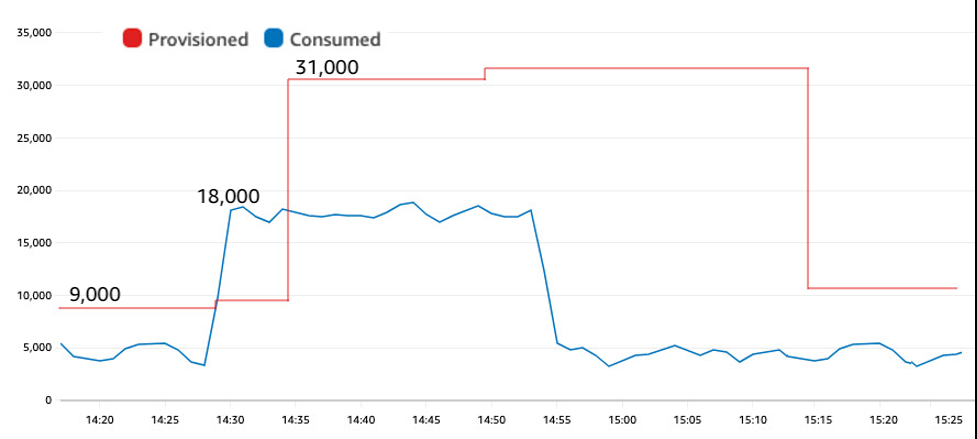
图 3:综合测试显示,在配置为目标利用率为 60% 且现在没有限制的自动扩展表上,流量从 4,000 个 WCU 突然跃升至 18,000 个 WCU
较低的目标利用率提供了更多的填充。在测试的前 10 分钟内,自动扩展配置了接近 9,000 个 WCU,而不是之前测试中的 7,500 个 WCU。WCU 跃升至 18,000 个 WCU 发生在 14:28,自动扩展在 14:35 向上调整了预配置金额。尽管出现了与图 2 相同的大幅上升,但目标利用率较低的表却没有受到任何限制。
较低的目标利用率在这方面提供了两个好处:首先,额外的填充意味着在峰值期间所需的突发容量更少。其次,在峰值之前拥有更高的预配置量意味着有更多的突发容量可供消费。这种组合消除了这种情况的任何限制。
3。切换到按需模式
如果避开油门至关重要,需要考虑的一个有用设计是将表格更改为
对于按需定价,定价完全基于消费。每个请求都会产生少量费用。与其每秒分配一定数量的 RCU 和 WCU 并按小时付费,您只需在每次提出请求时消耗读取请求单元 (RRU) 或写入请求单元 (WRU) 即可。使用按需扩展,无需预配,也无需向上或向下自动扩展。它非常适合高峰工作负载和不可预测的工作负载。
按需表格大大降低了因突然的流量激增而出现节流的可能性。按需牌桌的限制仅有两个原因。首先,如果超过分区的限制(与配置相同)。其次,如果表的流量超过账户的表级读取或写入吞吐量限制,这两个限制的默认软防护都是 40,000,但可以设置得更高,设置得更高不会产生额外费用。
图 4 重新创建了相同的流量模式,但现在显示在按需模式下。没有预置值(没有红线),也没有表级限制。
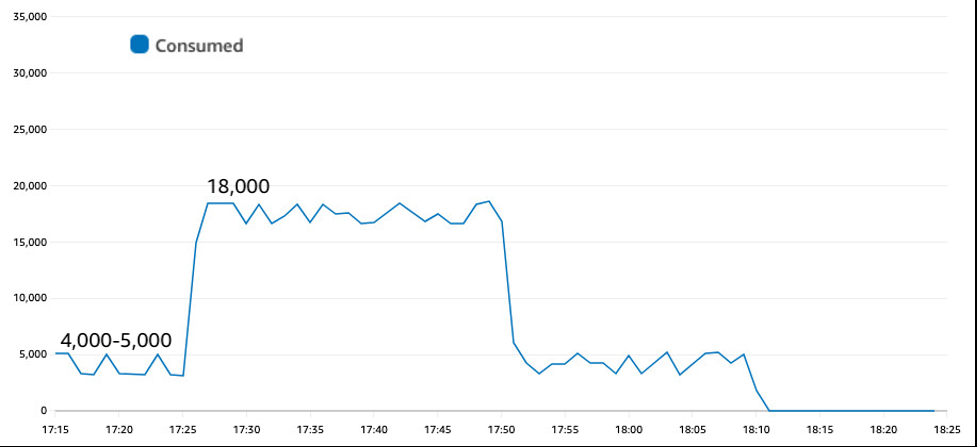
图 4:按需可立即对流量峰值做出反应,而不会受到限制
将您的表格转换为按需表是 “设置就算了” 的选择。无需考虑配置、目标利用率、扩大规模或缩小规模。您可以在预置表和按需之间来回转换表。表格可以每 24 小时切换到按需模式一次。表可以随时恢复到预置容量模式。您可能会发现,将每天预计流量峰值的表格转换为按需表格,然后将其转换为针对其他较平稳时段的预配置表会很有用。
人们普遍误以为按需表格比预配置表格更昂贵。有时候是,有时候不是。对于相对平坦的流量,就成本而言,预配置会更胜一筹。工作负载的流量峰值越多(急剧上升和下降),按需的成本优势就越大。只要有足够的峰值,它就可以成为成本较低的选择。那是因为按需可以避免与填充有关的所有额外成本,而且在激增之后不用等到裁员。
从数学上讲,如果预配置表上实现的利用率低于 15%,则按需将是一个成本较低的选项。实现利用率的计算方法是当月消耗的容量总和除以预置容量总和。由于缩小规模的延迟,它低于目标利用率。
4。让任何后台工作自动节流
如果您的流量高峰是由您可以控制的后台操作引起的,则可以考虑另一种选择,那就是让后台活动自动节流。基本上,让后台操作限制其消耗率,这样它就不会与最终用户流量过度竞争,从而抑制必要的自动扩展增长。
显著的峰值通常是由于某些后台活动造成的:加载新数据集、每日项目刷新、有选择地删除历史数据或扫描表格进行分析。在这些情况下,你可以在一定程度上控制后台工作的行为。
你可以让后台任务以一定的自限速率运行。选择旨在轻松适应通常的自动缩放填充的速率。这样,它在启动时就不会造成节流(假设没有热分区),并且自动扩展可以向上调整以恢复表上必要的填充。如果是外部方推动了高峰流量,请考虑是否可以对每个外部方的应用程序接入点进行速率限制。
批量工作可以通过要求每个请求提供 R
eturnConsumedConsumedConsumedCapacity 并跟踪每秒消耗
的容量来进行自我限制。如果太高,它可能会减速。如果您使用多个单独的客户端进程,则可以允许每个客户端一定的最大容量消耗率。
下图显示了自动节流批量工作如何限制峰值的大小并避免节流。该表的目标利用率再次达到70%,如图 2 所示,但现在请求率仅跃升至 14,000 个 WCU,因为批量处理任务已重做,运行速度稍慢一些。
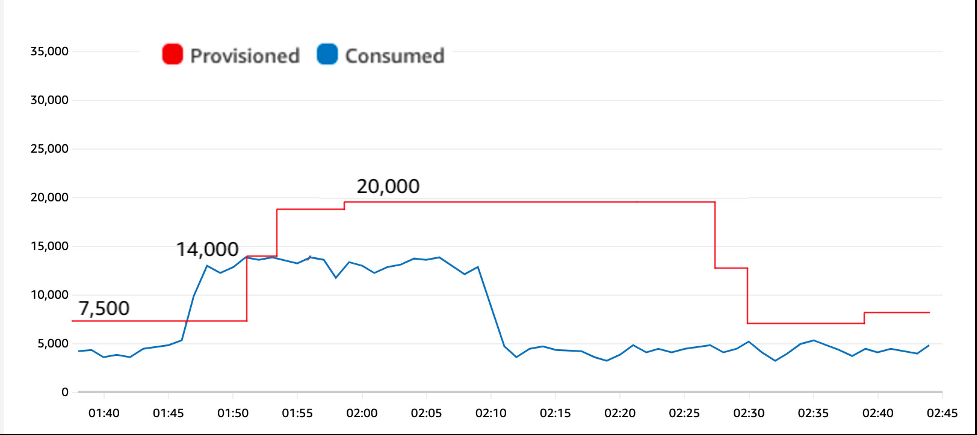
图 5:跳到 14,000 个 WCU 而不是 18,000 个 WCU 可以消除油门
较小的峰值为 14,000 个 WCU 可减少峰值期间消耗的突发容量,并允许自动缩放时间在牌桌出现节流之前向上调整
如果后台工作以适度的速度进行是可以接受的,那么自节奏的方法就会奏效。如果是这样,它还有一个额外的优势,那就是它限制了自动缩放向上调整的程度。假设您的后台工作可以在 10 分钟内持续消耗 4,000 个 WCU,或者在 5 分钟内消耗 8,000 个 WCU。使用按需订阅表,这两个选项的价格相同。如果预置表使用自动扩展,则审核得越多,自动扩展的增加幅度越小。如果自动扩展减少必须等待一个小时,则预置容量要低得多,则等于一个小时。对于此处的测试结果,您可以看到配置的峰值为 20,000 个 WCU,低于最初测试中的 26,000 个 WCU。
这种方法将峰值转化为停滞点,任何具有自动扩展功能的高位往往成本都较低。
5。有后台工作慢起步
如果你想尽快完成后台工作,又不想冒着限制最终用户流量的风险,那么可以让后台工作缓慢启动。
如前所述,慢速启动需要工作自动节流,但只有缓慢启动,然后每隔几分钟就会增加请求速率。这种缓入行为使自动扩展有时间进行调整,以适应容量需求的增加。和运动一样,你要先热身,以免破坏任何东西。
与之前的选项相比,这并未提供潜在的成本节约,但它确实限制了表级限制和与最终用户流量竞争的风险,同时允许(预热后)任意快速的请求速率(仅受您配置的 Auto Scaling 最大值以及账户级和表级限制的限制)。
下图显示了缓慢启动如何能够适应自动扩展填充以避免节流,同时还向自动扩展发送有关需要增加容量的信号。
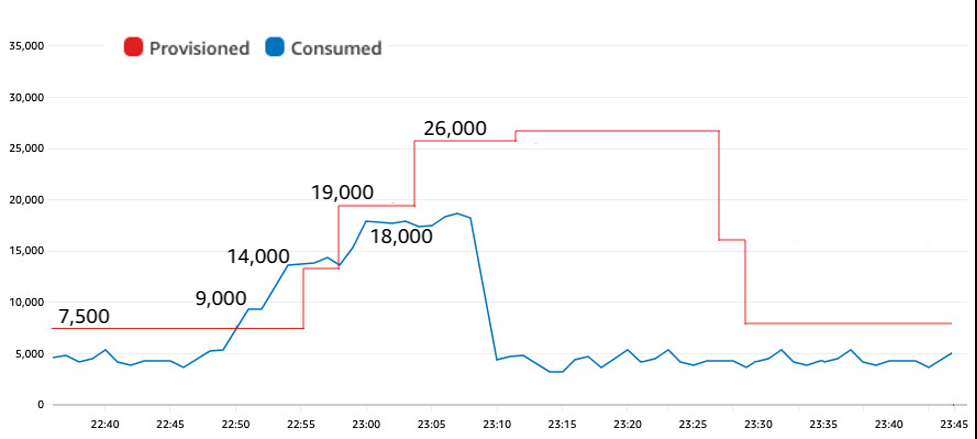
图 6:后台处理启动缓慢会允许自动缩放时间进行调整
流量逐步增长:从 4,000 人增加到 9,000 人增加到 14,000 人,然后在 22:49 至 23:00 之间增加到 18,000 人。这种缓慢的启动为自动扩展提供了足够的时间来在突发容量耗尽之前对其自身的一系列增加做出反应。该测试达到了与原始测试相同的18,000 WCU速率,目标利用率为70%,但是通过缓慢启动,它避免了所有限制。
6。如果可以预测峰值时机,请使用自动扩展计划
通过计划扩展,您可以根据日期和时间为表格的最小值和最大值设置不同的值。在控制
例如,如果您知道峰值即将来临及其规模,则可以将自动扩展的最低设置更改为足以应对峰值,这将提高表的预配置容量。峰值开始后,你可以下拉最小值。降低最低限额不会降低预配置金额,它只允许自动扩展在实际看到消耗量减少时将其删除。
下图显示了一项计划操作,该操作在流量激增至该速率前两分钟将自动扩展最小值调整为 18,000 个 WCU。
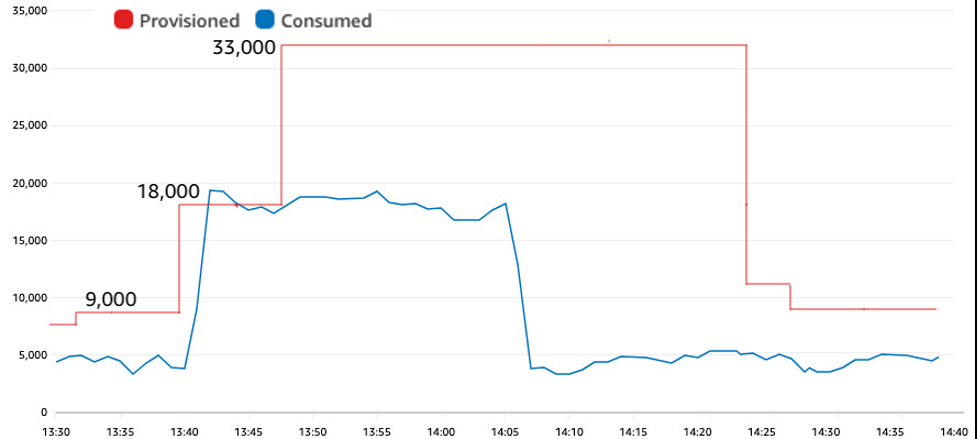
图 7:在出现可预测的峰值之前主动扩大规模
这种对自动缩放最低限度的主动调整避免了任何限制。第一次加薪至18,000美元是预定行动。第二次提高到33,000是自动扩展以响应实际流量并添加必要的填充。
7。如果您无法预测峰值时机,请主动申请自动缩放调整
相反,如果您的峰值无法预测确切的时机,但可以检测到峰值何时开始,则可以直接主动强制进行自动缩放调整。
例如,也许你知道早上会有大量货物,但你不知道确切的时间。您可以让批量负载在开始时主动请求增加特定的容量。想象一下,它发出 “准备好,我来了” 的呼叫,要求一定容量,然后桌子可以毫不拖延地进行调整。
实际上,一旦有人调用表格的预置容量,就可以很快地调整表格的预置容量。通常不到一分钟。需要注意的是,如果您将表格的预配置限制提高到比以前设定的更高。如果你像这样设定一个新的高水位线,那么表格可能需要提高其容量,而这种增长可能需要时间。最佳做法是,在再次缩小规模之前,通过一次性地将表和索引配置到生产中所需的最大读写级别,预先设定最高水位线。这确保了以后可以快速实现产能提升。如果你能在创建表时这样做,那是最快的。
现在,让我们讨论如何主动增加自动扩展表的预置容量。如果你直接更新表,Auto Scaling 将不知道所做的更改,并且可以通过自己的自动缩放操作撤消你的更改。更可靠的方法是将自动扩展的最小值调整为您想要的新预配置容量。通过这种方式,自动缩放可以为你加薪,并且知道发生了这种情况。
每个容量请求者都应去协调员那里,请求向表或 GSI 中添加一定数量的额外容量,等待容量满足,然后毫不拖延地启动,且不会造成表级限制。
协调器接收每个请求,检查当前流量,添加请求的金额,并分配新的自动扩展最低值。几分钟后,它可以将最低值调整回原始值,因为他们相信批量工作结束之前,批量工作人员的活动会将预配置级别保持在更高的请求金额上。无需仔细安排缩小规模。只需要快速放大桌子即可。
最终结果的外观和行为与图 7 相同,唯一的变化是您无需事先知道时间。
8。从战略上讲,允许一定程度的油门
需要考虑的最后一项设计是在应用程序设计中战略性地允许节流。如果可靠的低延迟不是硬性要求,可以考虑这个问题。接受一些油门可能是一个具有成本效益的选择。
油门不是灾难性的。它们不会造成任何数据库损坏。它们只会增加延迟。
例如,如果您在没有并发最终用户流量的表上执行批量加载,则批量加载的运行速度可能刚好等于或高于表的最大容量,在此过程中会出现一些限制。这意味着与提高容量以消除节流相比,负载所花费的时间要长一点,但成本将保持不变,每一点容量都将得到利用,无需填充物或其他注意事项。
但是,如果该表有并发的最终用户流量,那么运行这样的批量加载也会导致最终用户的写入受到限制,从而增加他们的感知延迟,这可能是一个问题。当没有客户端需要低延迟时,策略性地允许节流的选择效果最好。
请注意,默认情况下,如果 SDK 调用看到节流响应,则再次重试请求。你通常不会意识到会发生这种情况,因为它是在SDK本身中完成的。一个请求可能会被重试几次然后成功,在客户端看来,它看起来像是成功的请求(但延迟时间比平时长)。只有当 SDK 失败的次数足以超过 SDK 的可配置重试次数时,您才会看到超出预配置吞吐量的异常。如果你看到这个异常,你应该捕捉到异常,然后(假设你还需要完成工作)重试请求。最终,请求将成功。如果您的表配置为 10,000 个 RCU,则每毫秒就会有 10 个 RCU 可供请求处理。
当少数受限制的客户端在成功之前执行一系列快速自动重试时,这些客户端可能会生成大量的限制事件。出于这个原因,你应该关注油门事件的总体相对规模,而不是精确的数量。另外,请记住,限制可能发生在表级别,但如果你有热分区,它们也可能发生在分区级别。尽管 CloudWatch
限制事件在
readThrottleEvent、WriteThrottleEvents 和 Throttle
结论
自动扩展和突发容量可以应对显著的流量峰值,但是峰值越突然和延长,餐桌受到限制的可能性就越大。
您可以向下调整自动扩展目标利用率,从而为流量增长留出更多余地,也可以将表格更改为按需模式,即设置后就算了。
如果激增是由后台工作引起的(通常是大规模持续的激增),你可以让后台工作自动节流以保持较低的消耗,或者让它在增长到全速之前缓慢启动,让自动缩放时间进行适应。
如果您事先知道激增的时间,则可以安排自动扩展更改,将吞吐量提高到足以应对激增的最低水平。如果你事先不知道激增时间但能确定起始时刻,那么你可以主动请求增加自动扩展。
最后,如果不需要低延迟,你可以决定战略性地允许一定程度的限制。
进行更改时,也不要忘记调整任何 GSI 设置。
如果您有任何意见或疑问,请在评论部分发表评论。你可以在
作者简介
 杰森·亨特
是加州的首席解决方案架构师,专门研究亚马逊 DynamoDB。自 2003 年以来,他一直在使用 NoSQL 数据库。他以对 Java、开源和 XML 的贡献而闻名。
杰森·亨特
是加州的首席解决方案架构师,专门研究亚马逊 DynamoDB。自 2003 年以来,他一直在使用 NoSQL 数据库。他以对 Java、开源和 XML 的贡献而闻名。
 Puneet Rawal
是一位驻芝加哥的高级解决方案架构师,专门研究 亚马逊云科技 数据库。他在架构和管理大型数据库系统方面拥有 20 多年的经验。
Puneet Rawal
是一位驻芝加哥的高级解决方案架构师,专门研究 亚马逊云科技 数据库。他在架构和管理大型数据库系统方面拥有 20 多年的经验。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。