我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 NVIDIA 时间切片和加速 EC2 实例在亚马逊 EKS 上共享 GPU
在当今快节奏的技术格局中,对加速计算的需求猛增,尤其是在人工智能 (AI) 和机器学习 (ML) 等领域。企业面临的主要挑战之一是计算资源的高效利用,尤其是在GPU加速方面,这对于机器学习任务和一般人工智能工作负载至关重要。
NVIDIA GPU 在机器学习工作负载方面占有领先的市场份额,使其成为高性能和加速计算领域的首选。他们的架构专为处理计算任务的并行性质而设计,使其成为机器学习和人工智能工作负载不可或缺的一部分。这些 GPU 擅长矩阵乘法和其他数学运算,显著加快了计算,为更快、更精确的人工智能驱动见解铺平了道路。
尽管NVIDIA GPU提供了令人印象深刻的性能,但它们也很昂贵。对于组织而言,挑战在于最大限度地利用这些 GPU 实例,以获得最佳投资价值。这不仅仅是要充分利用 GPU 的全部功能;还要以最具成本效益的方式做到这一点。有效共享和分配 GPU 资源可以节省大量成本,使企业能够在其他关键领域进行再投资。
什么是 GPU?
图形处理单元 (GPU) 是一种专门的电子电路,旨在加速图像和视频的处理以供显示。中央处理器 (CPU) 处理计算机的一般任务,而 GPU 则负责图形和视觉方面。但是,他们的作用已大大扩展到不仅仅是画面。多年来,GPU 的巨大处理能力已被用于更广泛的应用,尤其是在需要同时处理大量数学运算的领域。这包括人工智能、深度学习、科学模拟,当然还有机器学习等领域。GPU 之所以能如此高效地完成这些任务,是因为它们的架构。与具有几个针对顺序串行处理进行了优化的内核的 CPU 不同,GPU 具有数千个专为多任务处理和处理并行操作而设计的小内核。这使他们非常擅长同时执行多项任务。
GPU 并发性选择
GPU 并发 性 是指 GPU 同时处理多个任务或进程的能力。用户可以使用不同的并发选项,每种选择都有自己的优势和理想的用例。让我们深入研究这些方法:
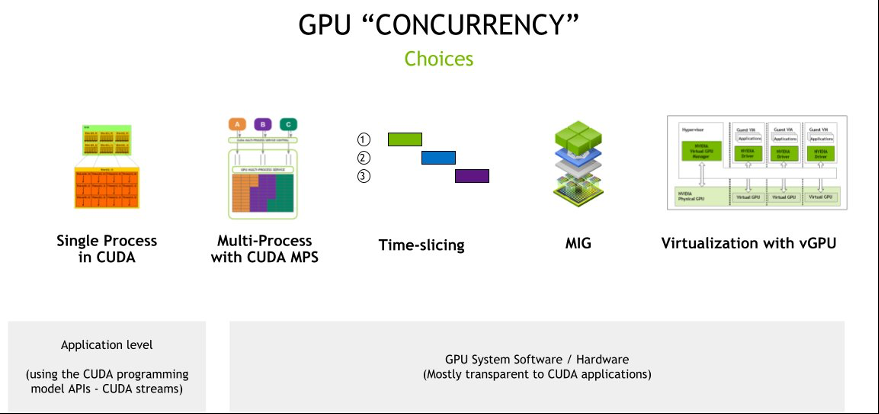
CUDA 中的单一进程
-
这是 GPU 利用率的最基本形式,即单个进程使用 CUDA
(计算统一设备架构)访问 GPU 以满足 其计算需求。 - 非常适合独立应用程序或需要 GPU 全部功能的任务。
- 当 GPU 专为特定的高计算任务分配时,无需共享。
使用 CUDA 多进程
- CUDA MPS 是 CUDA 的一项功能,它允许多个进程共享一个 GPU 上下文。这意味着多个任务可以同时访问 GPU,而无需大量的上下文切换开销。
- 当多个应用程序或任务需要并行访问 GPU 时。
- 非常适合任务具有不同的 GPU 需求并且您希望在不增加大量开销的情况下最大限度地提高 GPU 利用率的场景。
时间切片
- 时间切片涉及将 GPU 访问划分为较小的时间间隔,允许不同的任务在这些预定义的切片中使用 GPU。这类似于 CPU 在不同进程之间进行时间切换。
- 适用于具有多项任务且需要间歇性 GPU 访问的环境。
- 当任务的 GPU 需求不可预测时,需要确保所有任务都能公平访问 GPU。
多实例 GPU
- MIG 特定于 NVIDIA 的 A100 Tensor Core GPU,它允许将单个 GPU 分成多个实例,每个实例都有自己的内存、缓存和计算内核。这可确保每个实例的性能得到保证。
- 当你的目标是保证特定任务的特定性能水平时。
- 在多租户环境中,目标是确保严格隔离。
- 最大限度地提高云环境或数据中心的 GPU 利用率。
使用 虚拟 GPU 进行虚拟化
- NVIDIA vGPU 技术允许多个虚拟机 (VM) 共享单个物理 GPU 的功能。它虚拟化 GPU 资源,允许每个 VM 拥有自己的专用 GPU 切片。
- 在虚拟化环境中,目标是将 GPU 功能扩展到多个虚拟机。
- 对于云服务提供商或企业而言,目标是将GPU功能作为服务提供给客户。
- 当目标是确保不同任务或用户之间的数据隔离时。
对于 GPU 密集型工作负载进行时间切片的重要性
在
以下是最适合进行时间切片的场景和工作负载:
多个小规模工作负载:
- 对于同时运行多个中小型工作负载的组织,时间切片可确保每个工作负载获得公平的 GPU 份额,从而在无需多个专用 GPU 的情况下最大限度地提高吞吐量。
开发和测试环境:
- 在开发人员和数据科学家正在对模型进行原型设计、测试或调试的情况下,他们可能不需要持续的 GPU 访问权限。在这些间歇性使用模式下,时间切片允许多个用户高效地共享 GPU 资源。
批处理:
- 对于涉及批量处理大型数据集的工作负载,时间切片可以确保每个批次获得专用 GPU 时间,从而实现一致和高效的处理。
实时分析:
- 在实时数据分析至关重要且数据以流形式到达的环境中,时间切片可确保 GPU 可以同时处理多个数据流,从而提供实时见解。
模拟:
- 对于金融或医疗保健等定期但不连续运行仿真的行业,时间切片可以在需要时为这些任务分配 GPU 资源,从而确保在不浪费资源的情况下及时完成。
混合工作负载:
- 在组织混合运行 AI、ML 和传统计算任务的情况下,时间切片可以根据每项任务的即时需求动态分配 GPU 资源。
成本效率:
- 对于预算有限的初创企业或中小型企业来说,投资大量 GPU 可能是不可行的。时间切片使他们能够最大限度地利用有限的 GPU 资源,在不影响性能的情况下满足多个用户或任务的需求。
从本质上讲,在 GPU 需求是动态的、多个任务或用户需要并行访问或优先考虑最大化 GPU 资源效率的情况下,时间切片变得非常宝贵。当严格隔离不是主要考虑因素时,尤其如此。通过在这些场景中识别和实施时间分割,组织可以确保最佳的 GPU 利用率,从而提高性能和成本效率。
解决方案概述:在亚马逊 EKS 上实现 GPU 共享
亚马逊 EKS 用户可以通过集成 NVIDIA Kubernetes 设备插件来启用 GPU 共享。该插件将 GPU 设备资源暴露给 Kubernetes 系统。这样,Kubernetes 调度器现在可以在做出调度决策时考虑这些 GPU 资源,从而确保适当分配需要 GPU 资源的工作负载,而无需系统自己直接管理 GPU 设备。
先决条件:
-
安装
eksdemo ,这是学习、测试和演示亚马逊 EKS 的简单选项。 -
安装
头盔 。 -
安装
亚马逊云科技 CLI 。 -
安装
kubec tl。 -
安装
jq 。
解决方案演练
使用 NVIDIA GPU 支持的 EC2 实例创建 EKS 集群
注意: 所有由 NVIDIA GPU 提供支持的 EC2 实例都支持时间切片。但是,在实现时间切片时,必须验证设备和驱动程序版本以及任何特定的 GPU 类型限制。
以下命令将为我们的测试创建所需的资源:
注意: 使用所需的选项 替换实例类型和区域
此命令创建了一个名为 gpusharing-demo 的新 EKS 集群。该集群将具有类型为 t3.large 的实例,并将由两个节点组成。该集群将在美国西部(俄勒冈)的 亚马逊云科技 区域创建。
此命令在 gpusharing-demo 集群 中创建一个名为 gp u 的新节点组。节点组将包含类型 为 p3.8xlarge 的实例 ,它们是 GPU 优化的 实例。此节点组中将有一个节点。

如果你有兴趣了解有关
eksdemo
的更多信息 ,可以参阅
在亚马逊 EKS 上部署英伟达 GPU 设备插件
NVIDIA GPU 设备插件增强了 kubernetes 管理 GPU 资源的能力,类似于它处理 CPU 和内存的方式。这是通过暴露每个节点上的 GPU 容量来实现的,然后 Kubernetes 调度器使用这些容量来分配请求 GPU 资源的 Pod。此设备插件作为守护程序在集群中的每个节点上运行,并与 Kubernetes API 服务器通信以通告该节点的 GPU 容量。这可确保当 Pod 需要 GPU 资源时,它会被放置在可以满足该要求的节点上。
注意: 设备插件将 GPU 视为扩展资源。这种方法虽然与 Kubernetes API 无缝集成,但确实存在某些限制,尤其是在使用像 Karpenter 这样的工具时。通过了解此分配是通过 Kubernetes API 完成的,而不是对节点进行任何物理更改,用户可以更好地导航并可能解决任何相关挑战。
在此步骤中,我将手动为具有 GPU 的节点添加标签,以便我们可以将 GPU 工作负载调度到该节点。此外,NVIDIA 设备插件守护程序只能在具有 GPU 向 kubelet 通告的节点上运行。
注意:
替换
使用标 有 eks-node=gpu 标签的 GPU 节点上的 Helm 图表安装 NVIDIA Kubernetes 设备插件 。
部署设备插件后,您可以通过运行以下命令对其进行验证:
![]()
我们有一个 GPU 节点,因此我们将 NVIDIA 设备插件作为守护程序在该节点上运行。
要
请求 GPU 资源
,可以在部署规范中包含一个
资源
字段,其中包含
“ nvidia.com/gpu”
例如,看一看 Pod 请求整个 GPU 的示例部署清单:
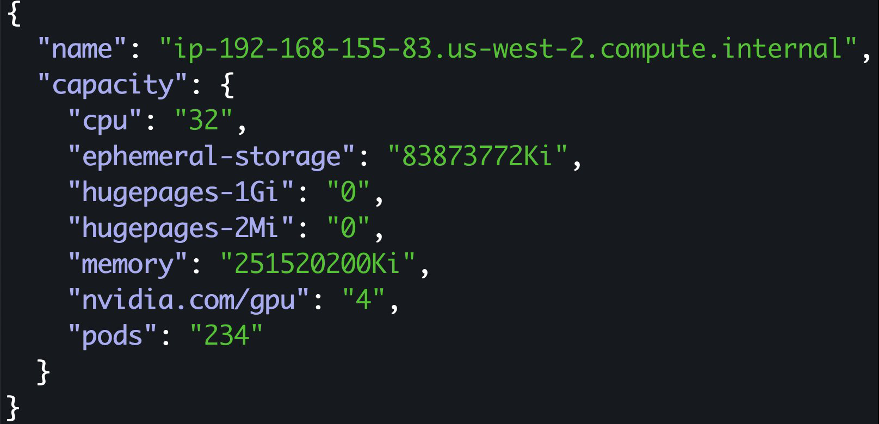
运行此命令以查看其中一个节点上可用的 GPU。我们目前在 p3.8xlarge 上有四个 GPU 可用,这些 GPU 由 kubernetes NVIDIA 设备插件进行宣传。
注意: 我们尚未启用分时配置
部署示例工作负载以演示时间切片功能
我们将部署一个示例工作负载来演示时间切片功能,其中 Python 脚本使用 Tensorflow 和 Keras 在 CIFAR-10 数据集上训练 CNN。该数据集包含 10 个类别的 60,000 张图像,将自动下载到容器中。该脚本还具有实时数据增强功能,以提高模型性能。
Python 代码在
创建 kubernetes 命名空间:
创建部署
此次部署将运行五个吊舱,在 CIFAR-10 数据集上训练 CNN 模型。
该代码在这个

我们使用的是具有四个 G PU 的 p3.8xLarg e 实例,每个 Pod 都请求一个 GPU。观察这些容器后,由于缺少可用的 GPU,其中一个 pod 处于待处理状态。

在 EKS 中对显卡进行时间切片
Kubernetes 中的 GPU 时间切片允许任务轮流共享 GPU。当 GPU 被超额订阅时,这尤其有用。系统管理员可以为 GPU 创建 “副本”,并将每个副本指定给特定的任务或 Pod。但是,这些副本不提供单独的内存或故障保护。当 EC2 实例上的应用程序无法充分利用 GPU 时,可以使用时间切片调度器来优化资源使用。默认情况下,Kubernetes 将整个 GPU 分配给一个 pod,这通常会导致未得到充分利用。时间切片可确保多个 Pod 可以高效共享一个 GPU,使其成为处理各种 Kubernetes 工作负载的宝贵策略。
启用分时配置
创建一个 ConfigMap 并运行引用它的 Helm 升级命令。
在前面的清单中,我们为每个物理 GPU 设置 10 个虚拟 GPU,因此 Pod 可以请求一个虚拟 GPU 单元,相当于物理 GPU 资源的 10%。
使用具有时间切片配置的新 ConfigMap 更新你的 NVIDIA Kubernetes 设备插件:
现在我们已经使用 新的时间切片配置修补了守护程序集 ,让我们验证可用 GPU 的数量:
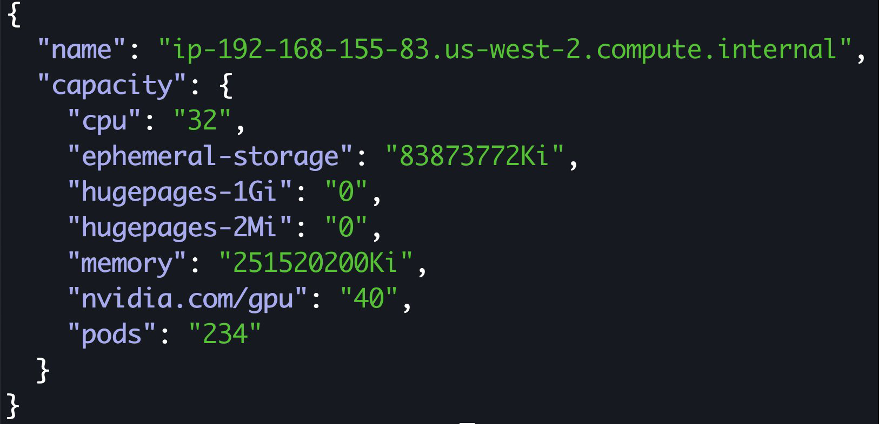
现在有 40 个 GPU 可用于训练模型。

由于 GPU 不足而处于待处理状态的 pod 现在正在运行。
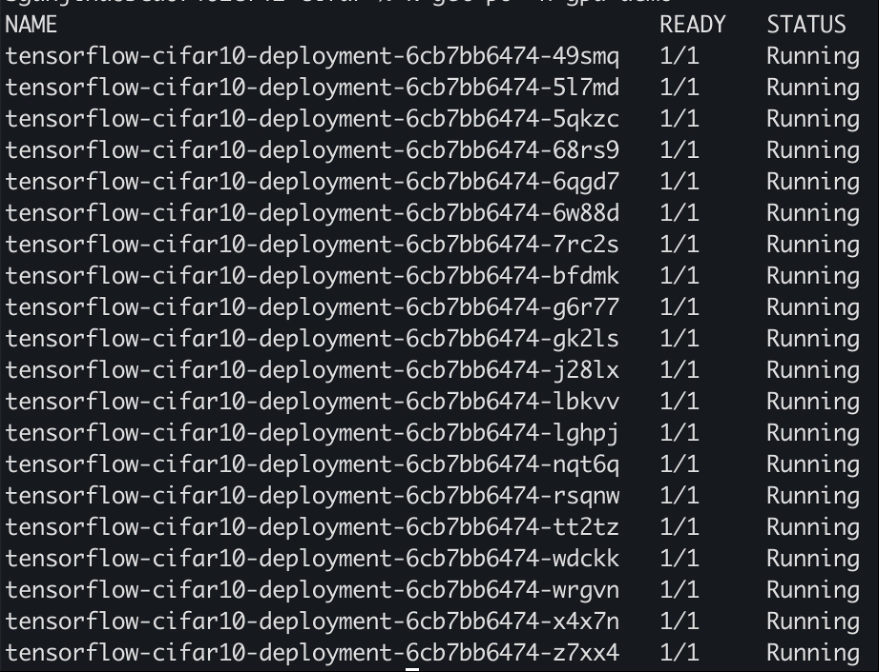
扩大部署规模
将部署扩展到 20 个副本,我们应该看到每个 Pod 都有足够的 GPU 来训练 ML 模型。
通过
A
在输出中,特别寻找共享 GPU 的多个进程,这表明 GPU 的有效利用率和资源共享。
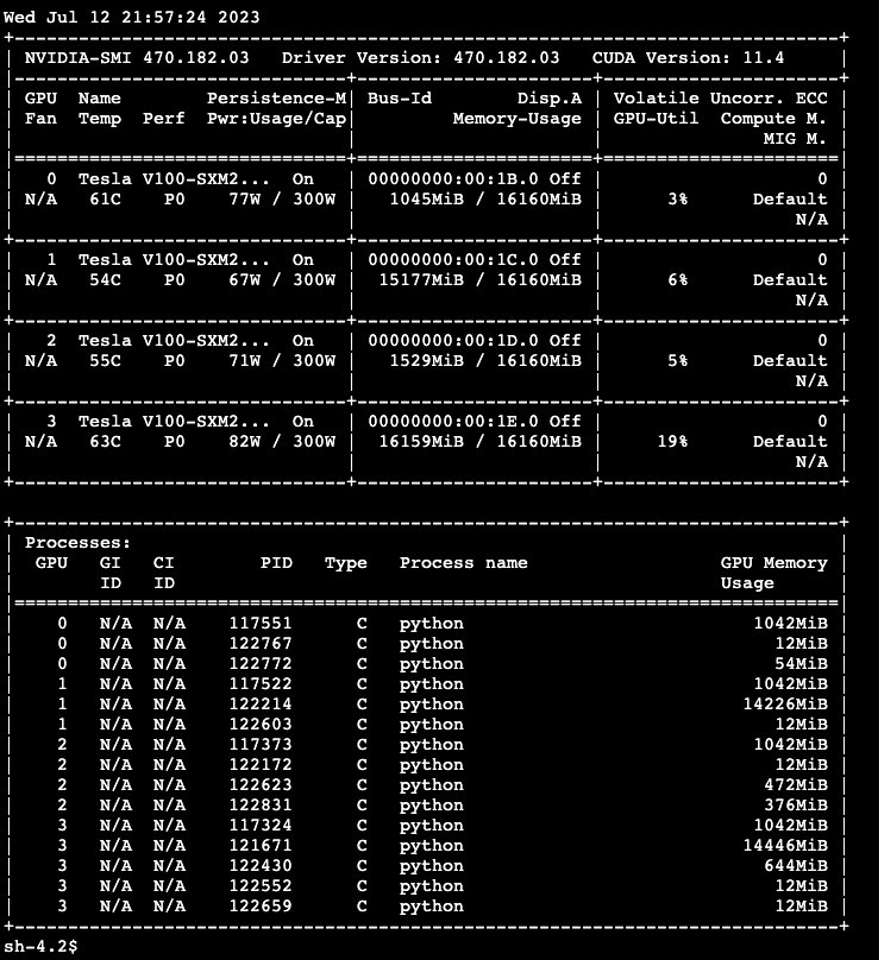
分时的好处
-
提高资源利用率:
- GPU 共享允许多个 Pod 使用相同的 GPU,从而更好地利用 GPU 资源。这意味着,即使不需要 GPU 全部功能的较小工作负载仍然可以从 GPU 加速中受益,而不会浪费资源。
-
成本优化:
- GPU 共享可以通过提高资源利用率来帮助降低成本。通过 GPU 共享,您可以在相同数量的 GPU 上运行更多工作负载,从而有效地将这些 GPU 的成本分散到更多的工作负载上。
-
提高吞吐量:
- GPU 共享允许同时运行多个工作负载,从而提高系统的整体吞吐量。这在需求激烈或高负载的情况下尤其有利,在这些时期,同时请求的数量激增。通过在相同的时间范围内处理更多请求,该系统可以提高资源利用率,从而优化性能。
-
灵活性:
- 时间切片可以适应从机器学习任务到图形渲染的各种工作负载,从而允许不同的应用程序共享相同的 GPU。
-
兼容性:
- 时间切片可能有利于不支持 MIG 等其他共享机制的老一代 GPU。
分时缺点
-
没有内存或故障隔离:
- 与 MIG 等机制不同,时间分片不能在任务之间提供内存或故障隔离。如果一项任务崩溃或行为不端,它可能会影响共享 GPU 的其他任务。
-
潜在延迟:
- 当任务轮流使用 GPU 时,可能会有轻微的延迟,这可能会影响实时或延迟敏感型应用程序。
-
复杂的资源管理:
-
确保 GPU 资源在多个任务之间公平高效地分配可能是一项挑战。
有关更多信息,请参阅提高 Kubernetes 中的 GPU 利用率。
-
确保 GPU 资源在多个任务之间公平高效地分配可能是一项挑战。
-
开销:
- 在任务之间切换的过程可能会带来计算时间和资源方面的开销,尤其是在切换频率较高的情况下。这可能会导致正在执行的任务的整体性能降低。
-
可能出现饥饿:
- 如果管理不当,某些任务可能会比其他任务获得更多的 GPU 时间,从而导致优先级较低的任务的资源匮乏。
清理
为避免收费,请删除您的 亚马逊云科技 资源。
结论
在亚马逊 EKS 上使用 GPU 共享,借助 NVIDIA 的时间切片和加速 EC2 实例,可以改变公司在云中使用 GPU 资源的方式。这种方法可以节省资金并提高系统速度,从而帮助完成许多不同的任务。GPU 共享存在一些挑战,例如确保每项任务都在 GPU 中获得应有的份额。但是最大的好处说明了为什么它是现代 Kubernetes 设置的关键部分。无论是用于机器学习还是详细图形,Amazon EKS 上的 GPU 共享都能帮助用户从 GPU 中获得最大收益。请继续关注我们的下一篇博客文章,该文章将深入探讨多实例 GPU (MIG),以了解更多共享 GPU 资源的方法。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。