我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
开始管理由 亚马逊云科技 Glue 数据目录支持的 Amazon S3 表的分区
处理大量数据的大型组织通常将其存储在
分区是一种常用技术,可以为分布式分析引擎以最佳方式布局数据。通过对数据进行分区,您可以限制下游分析引擎扫描的数据量,从而提高性能并降低查询成本。
在这篇文章中,我们涵盖了以下与 Amazon S3 数据分区相关的主题:
-
了解
亚马逊云科技 Glue 数据目录 和 S3 分区中的表元数据以提高性能 - 如何使用 Athena 在数据目录中创建表和加载分区
- 分区如何存储在表中
- 在数据目录的表中添加分区的不同方法
- 在采集和编目时对存储在 Amazon S3 中的数据进行分区
了解数据目录和 S3 分区中的表元数据以提高性能
亚马逊云科技 Glue 数据目录中的表是组织数据位置、数据类型和列架构(代表数据存储中的数据)的元数据定义。分区是按层次结构组织的数据,定义了特定分区的数据所在的位置。对数据进行分区可以限制 S3 SELECT 扫描的数据量,从而提高性能并降低成本。
在决定要分区的列时,需要考虑几个因素。例如,如果您使用列作为筛选器,则不要使用分区过于精细的列,也不要选择数据严重偏向于一个分区值的列。您可以按任何列对数据进行分区。在您的用例中,分区列通常是由常见的查询模式设计的。例如,一种常见的做法是根据年/月/日对数据进行分区,因为许多查询倾向于在典型用例中运行时间序列分析。这通常会导致多级分区方案。数据根据一列或多列的不同值以分层目录结构进行组织。
让我们来看一个分区工作原理的例子。
与一天的数据相对应的文件放在诸如
s3://my_bucket/logs/year=2023/month=06/day=01/
之类的前缀下 。
如果每天对数据进行分区,则每天您只有一个文件,例如:
-
s3://my_bucket/logs/year=2023/month=06/day=01/file1_example.json -
s3://my_bucket/logs/year=2023/month=06/day=02/file2_example.json -
s3://my_bucket/logs/year=2023/month=06/day=03/file3_example.json
我们可以使用 WHERE 子句来查询数据,如下所示:
前面的查询仅读取分区文件夹 year
=2023/month=06/day=01
内的数据,而不是扫描所有分区下的文件。因此,它只扫描文件
file1
_example.json。
雅典娜、
如何使用 Athena 在数据目录中创建表和加载分区
让我们首先了解如何在 Athena 中使用 DDL(数据定义语言)查询创建表和加载分区。请注意,为了演示将分区加载到表中的各种方法,我们需要在以下步骤中多次删除并重新创建表。
首先,我们为这个演示创建一个数据库。
- 在 Athena 控制台上,选择 查询编辑器 。
如果这是您第一次使用 Athena 查询编辑器,则需要
- 使用以下命令创建数据库:
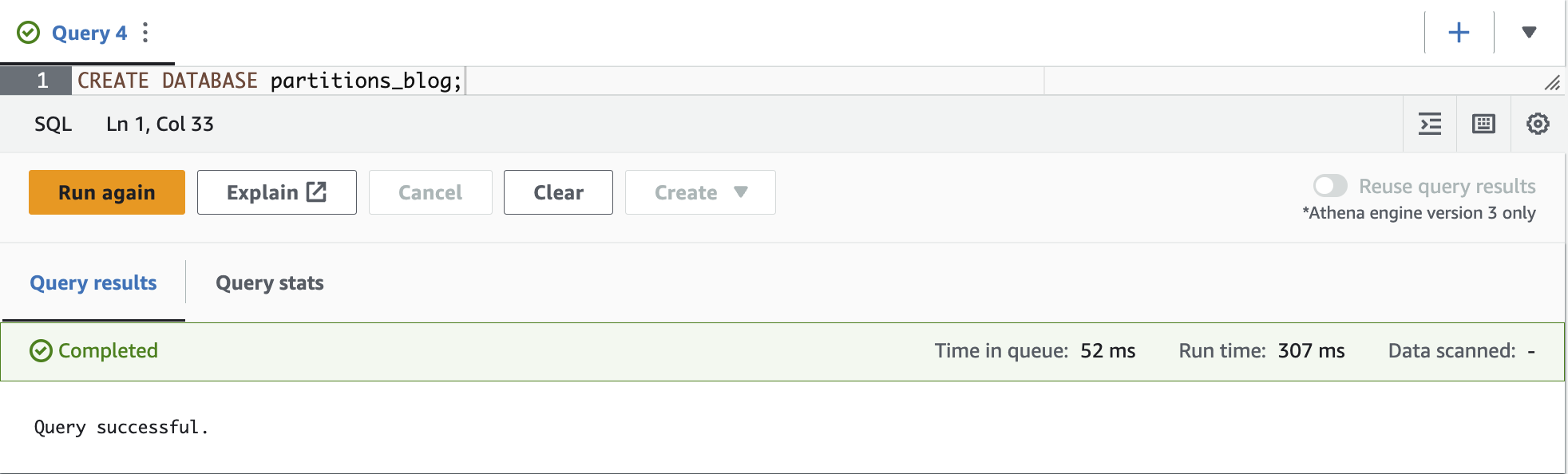
-
在 “
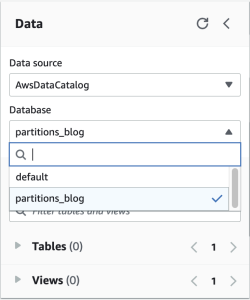
数据
” 窗格中,为 “
数据库
” 选择 “数据库
分区_博客”。
-
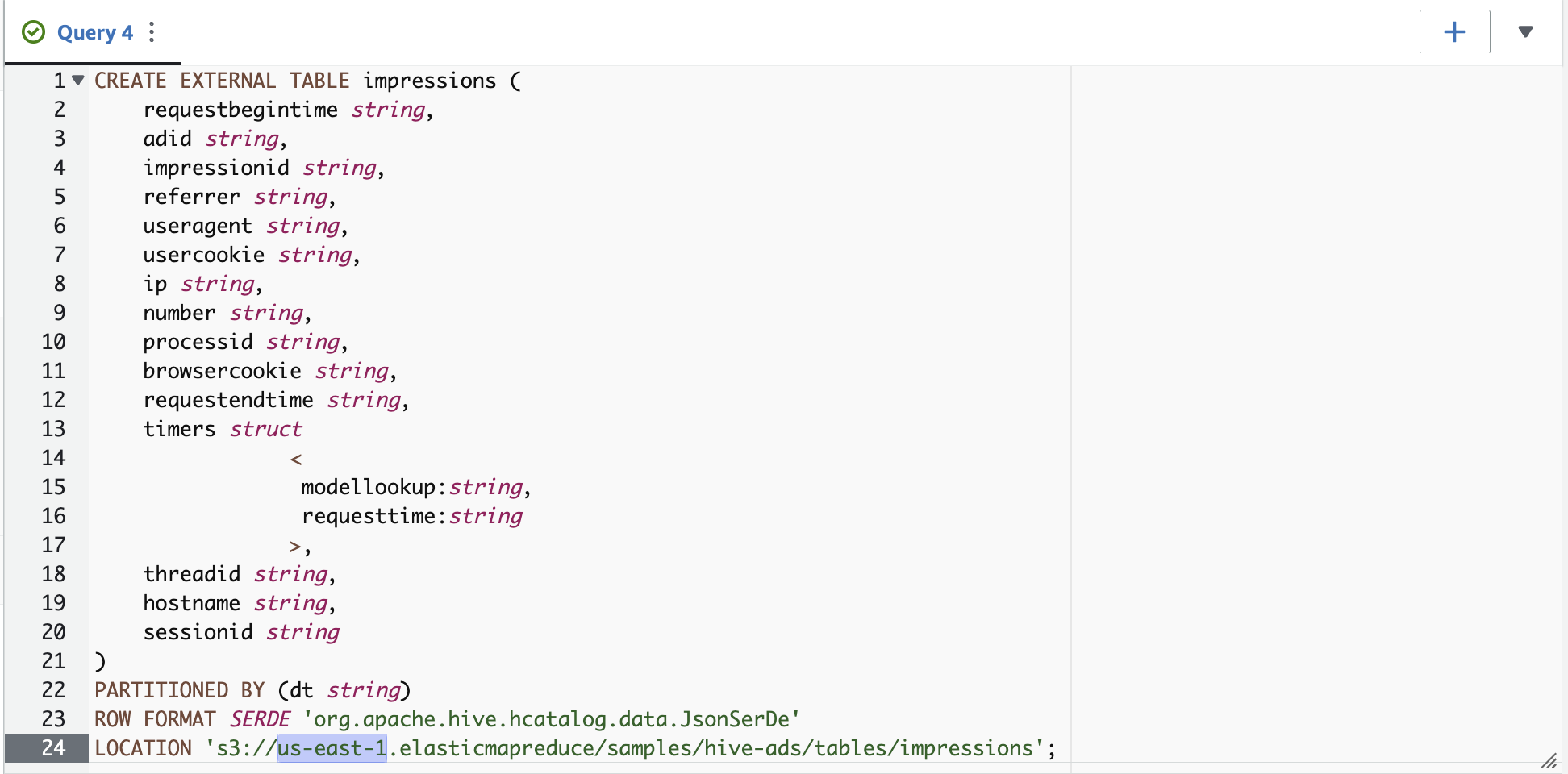
按照
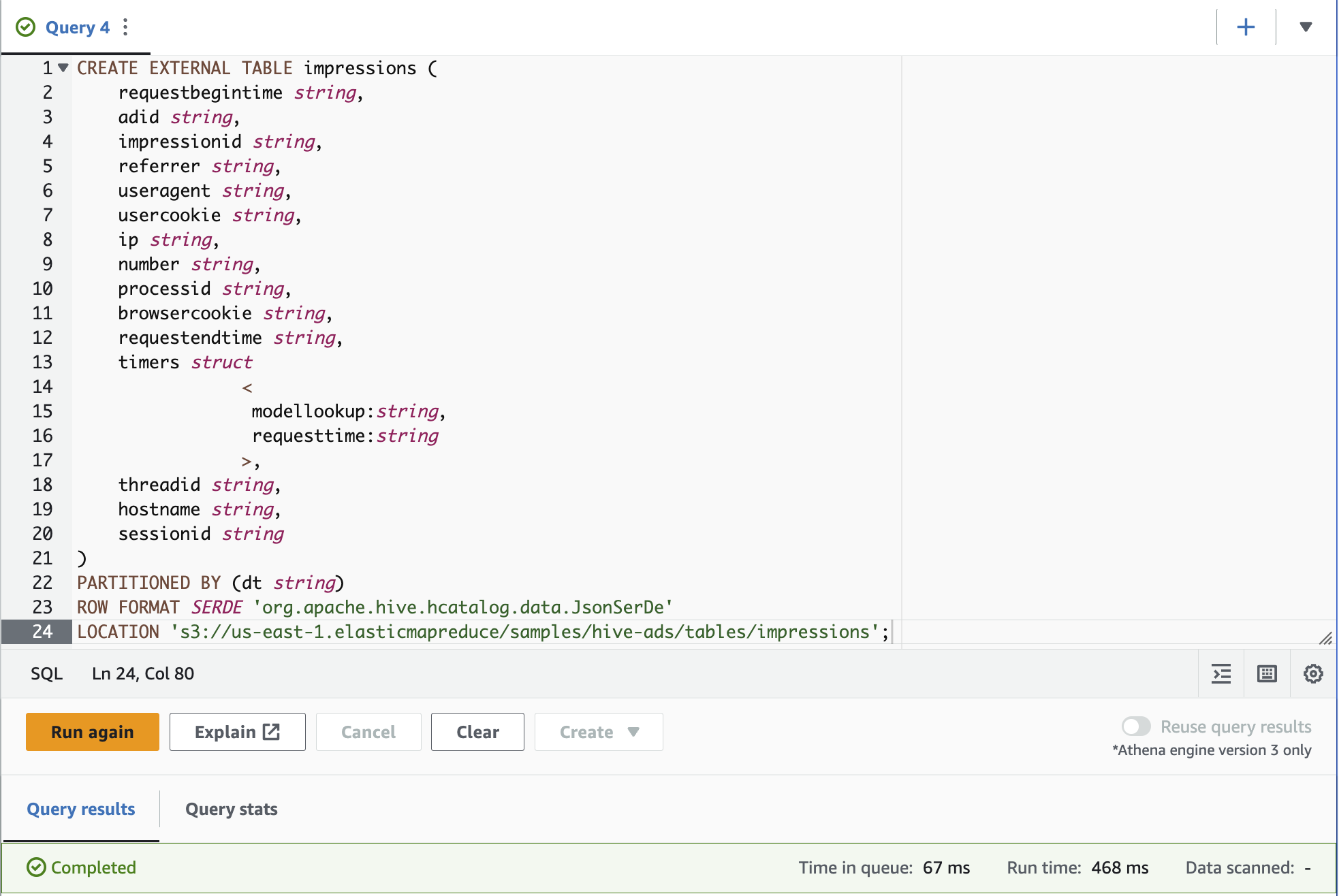
Hive JSON Ser De 中的示例创建表格展示次数。将3://.elasticmapreduce/samples/hive-ads/tables/impressions 中替换为运行雅典娜的区域标识符(例如,s3://us-east-1.elasticmapreduce/samples/hive-ads/tables/impressions)。 - 运行以下查询来创建表:
以下屏幕截图显示了查询编辑器中的查询。
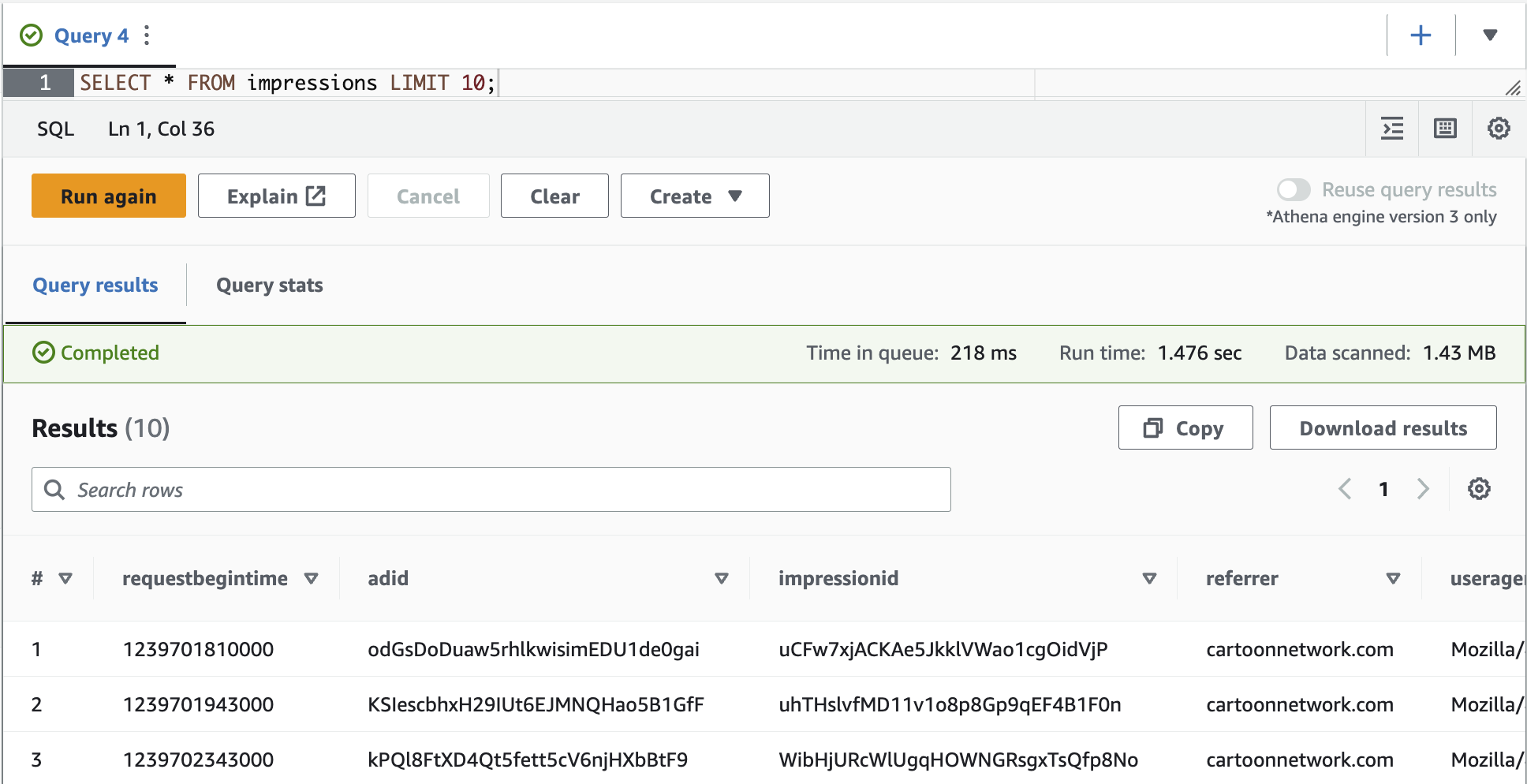
- 运行以下查询来查看数据:
你看不到任何结果,因为分区尚未加载。
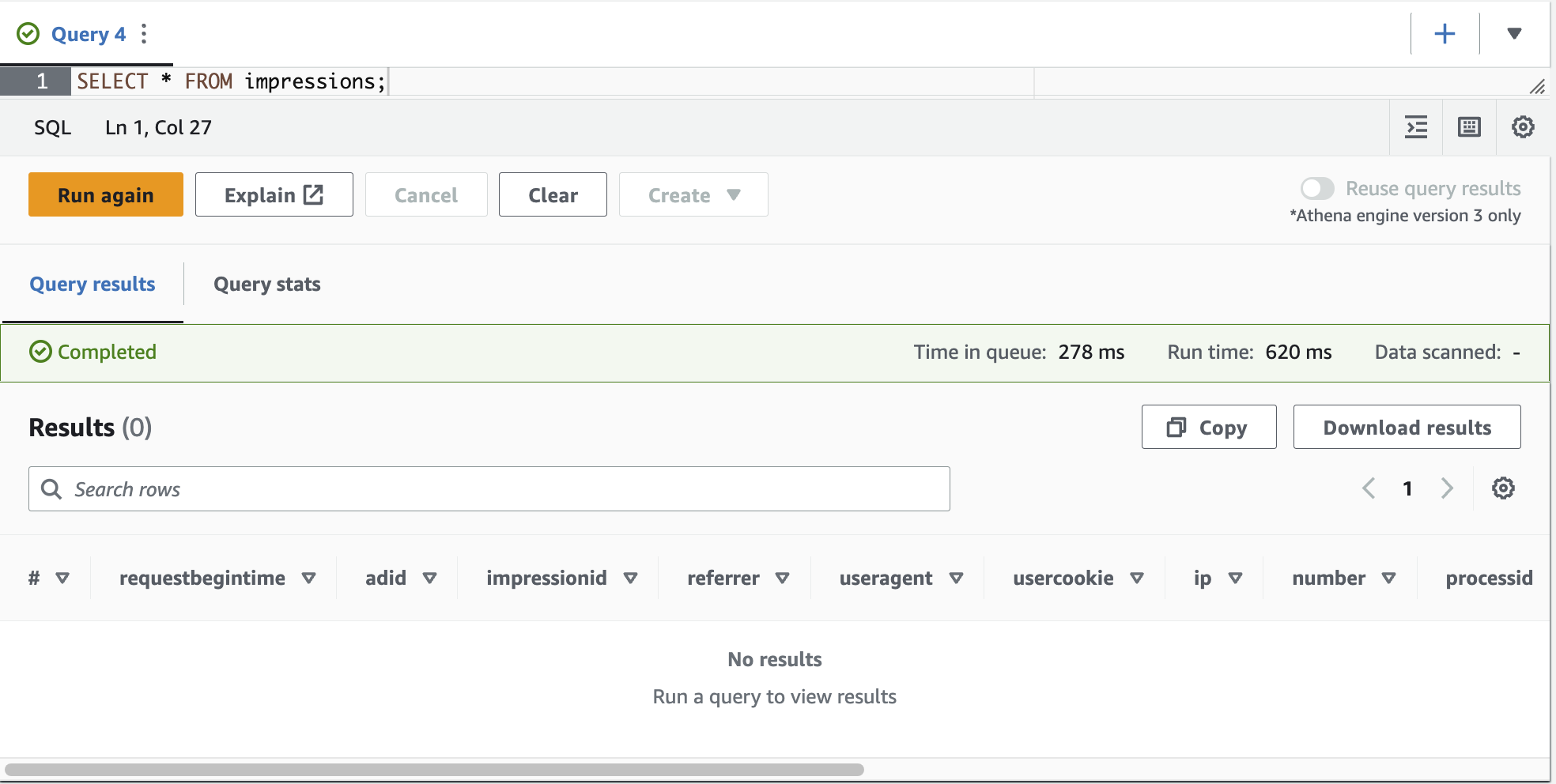
如果分区未加载到分区表中,则当应用程序下载分区元数据时,应用程序将不知道需要查询的 S3 路径。有关更多信息,请参阅
-
使用
MSCK 修复表命令加载分区。
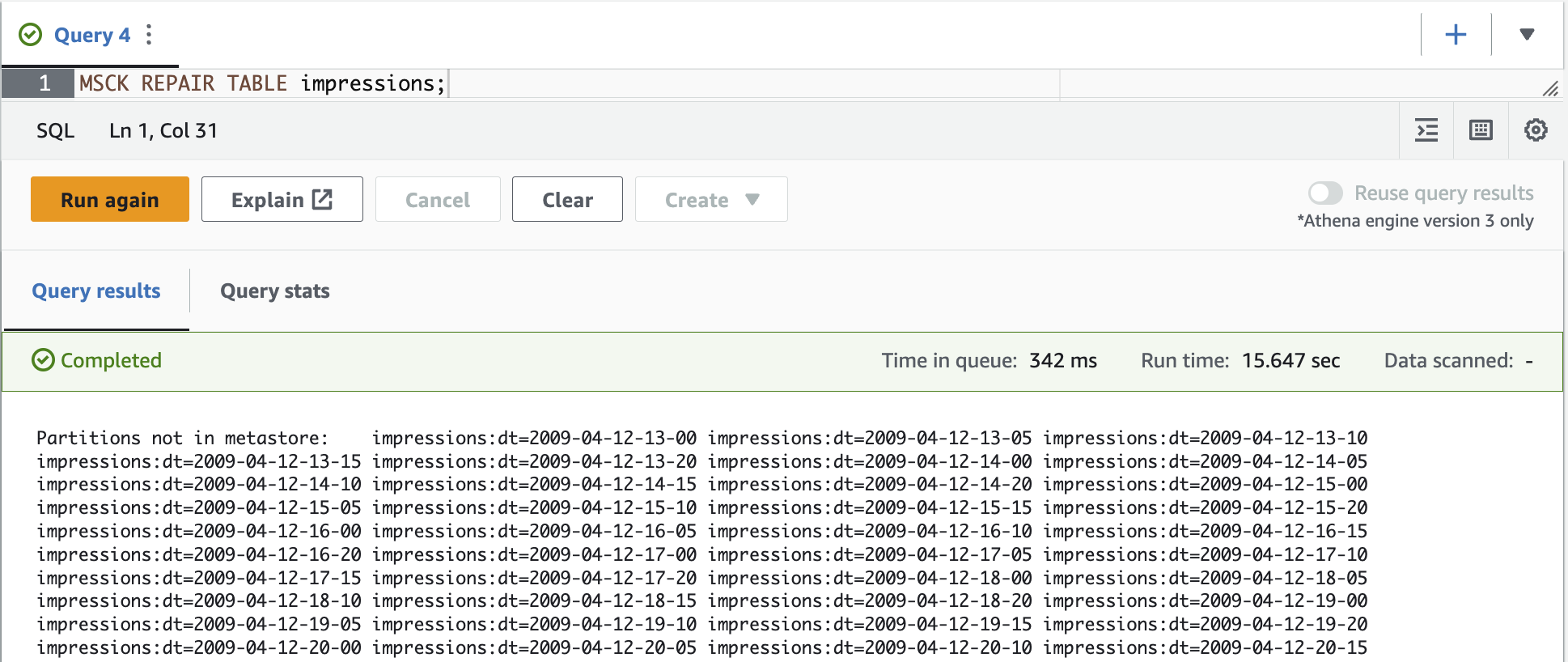
MSCK REPAIR TA
BLE 命令旨在手动添加已添加到文件系统或从文件系统中删除的分区,例如 HDFS 或 Amazon S3,但不存在于元存储中。
- 再次查询表以查看结果。
在
MSCK REPAIR TABLE
命令扫描 Amazon S3 并向 亚马逊云科技 Glue 中添加与 Hive 兼容的分区后,现在会返回注册分区下的记录。
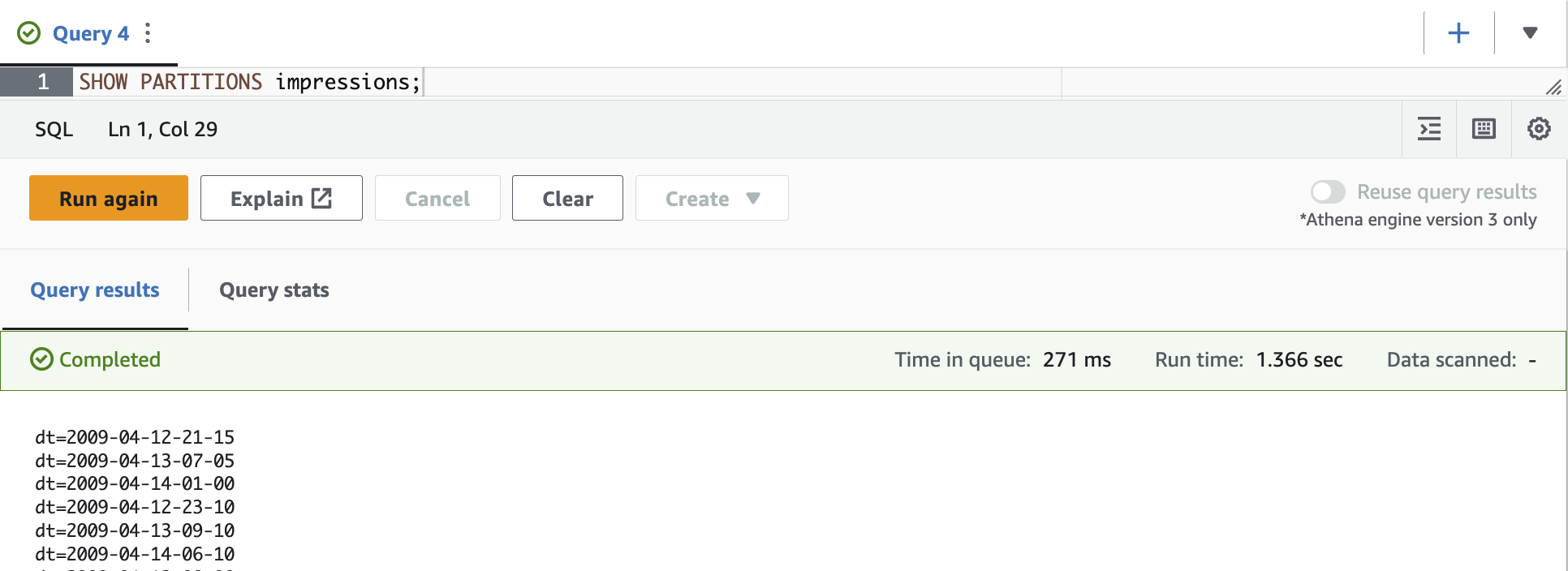
分区如何存储在表元数据中
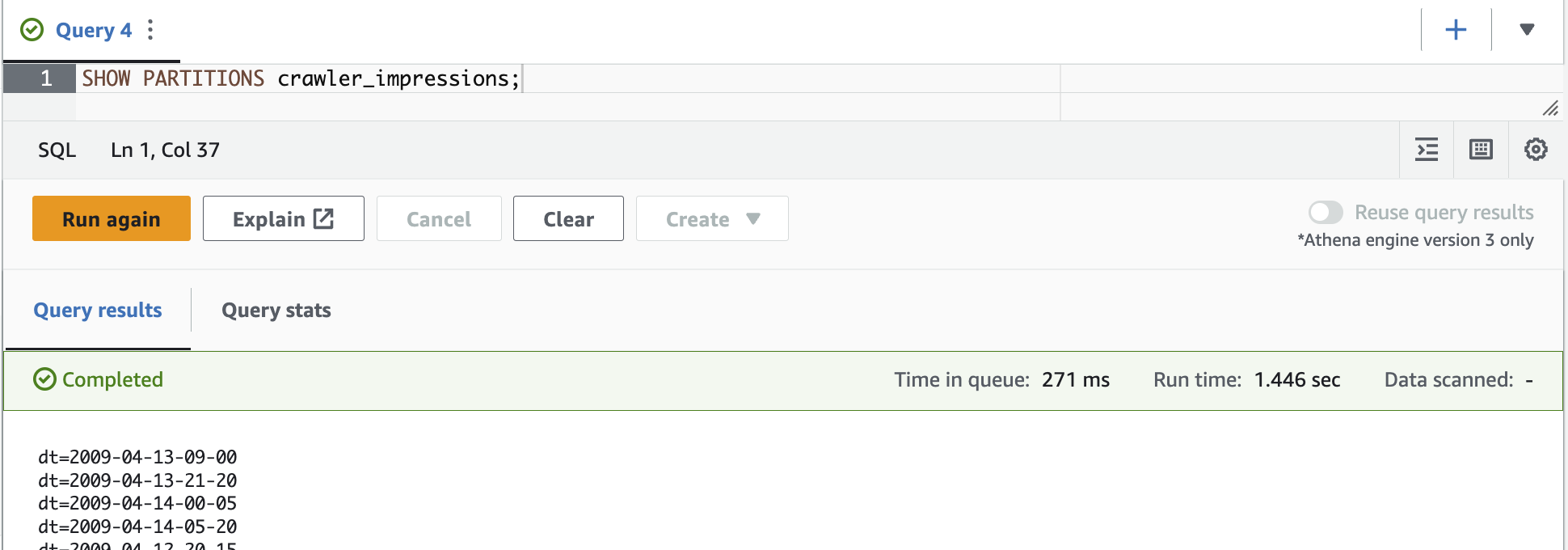
我们可以通过运行
SHOW PARTITIONS 命令列出 Athena 中的表分区
,如以下屏幕截图所示。
我们还可以在 亚马逊云科技 Glue 控制台上查看分区元数据。完成以下步骤:
- 在 亚马逊云科技 Glue 控制台上, 在导航窗格的 “ 数据目录 ” 下选择 “ 表 ” 。
-
在 p
artitions_blog 数据库中选择展示次数 表。
-
在
分区
选项卡上,选择分区 旁边的
查看属性
以查看其详细信息。
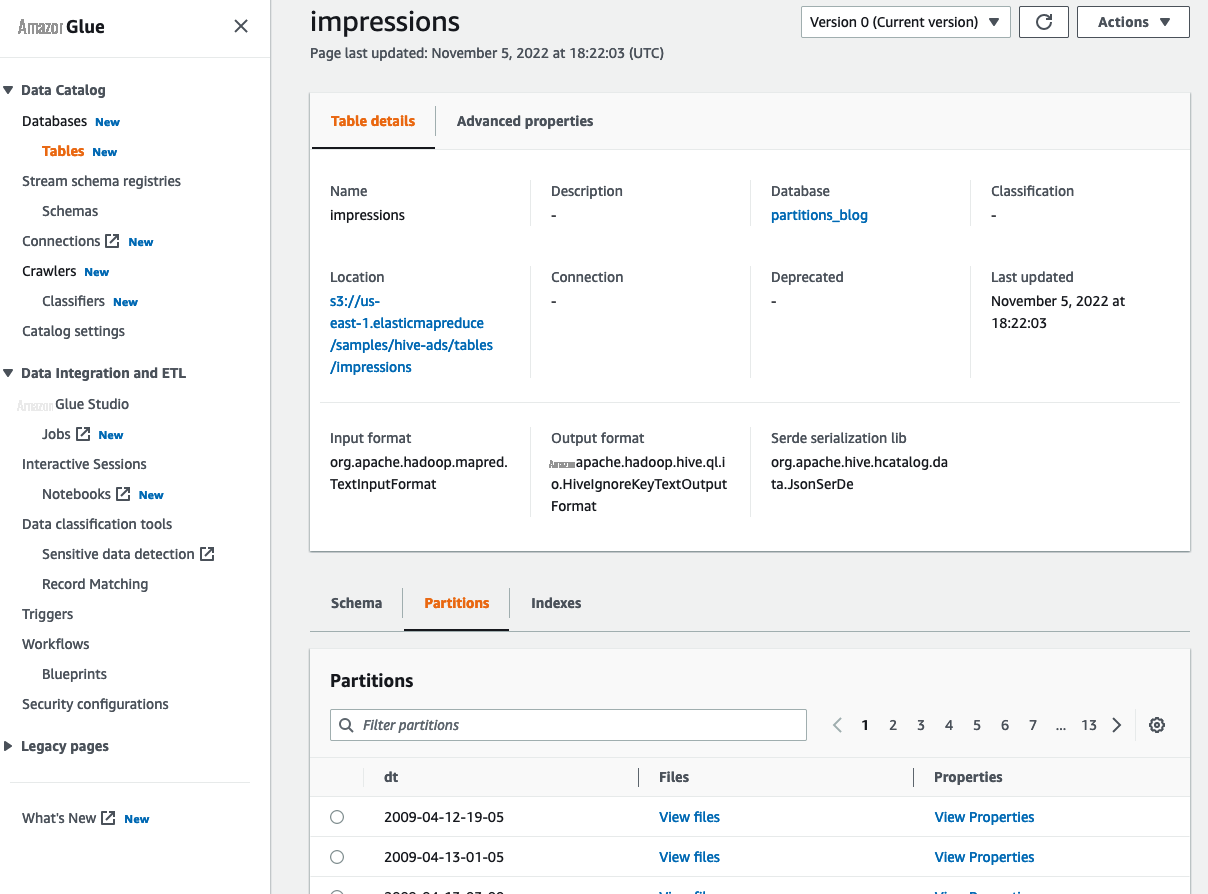
以下屏幕截图显示了分区属性的示例。
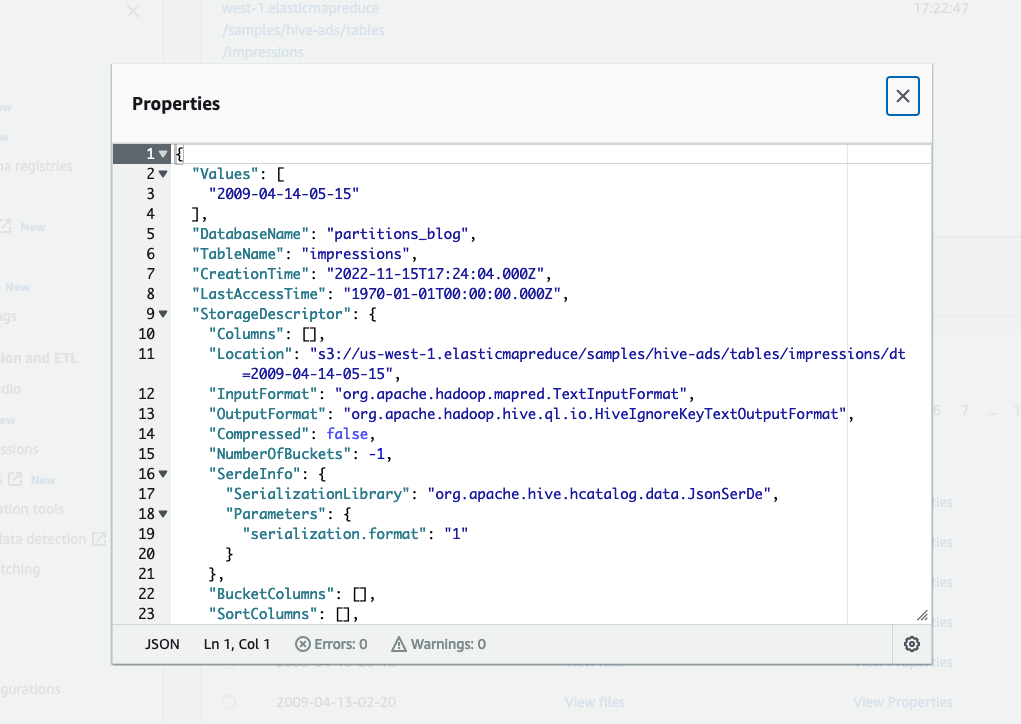
我们还可以使用
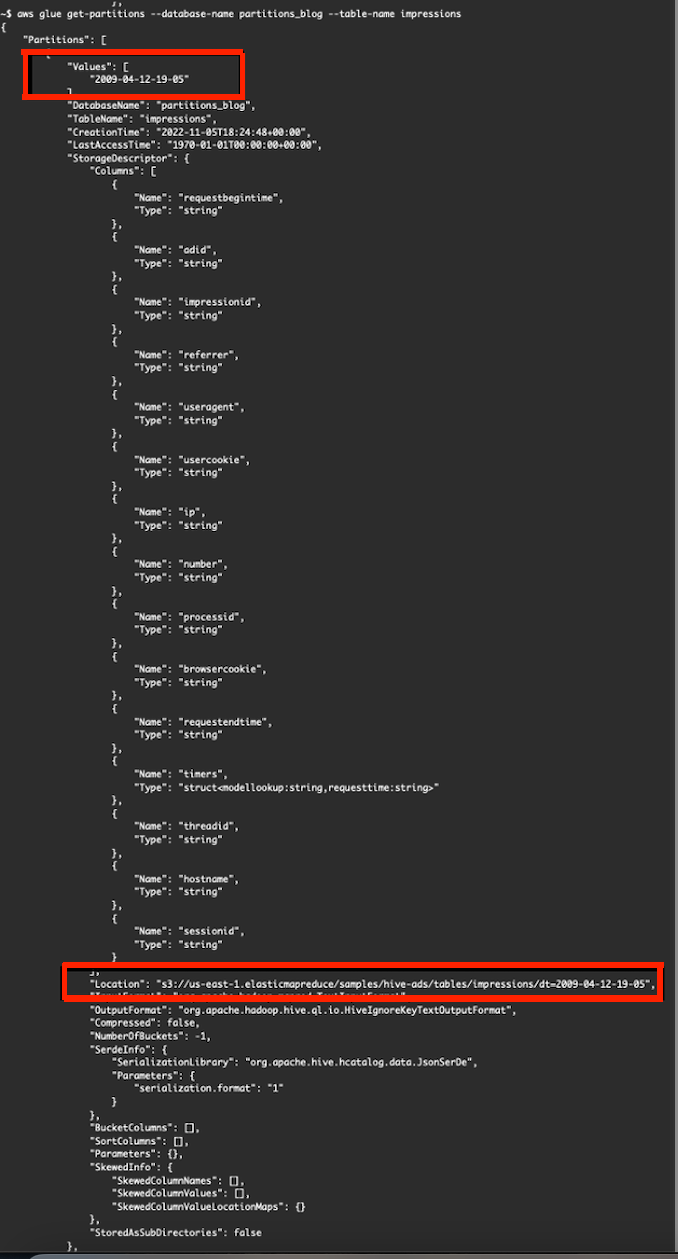
在
获取分区
中 ,元素
“值”
定义分区值,
“位置”
元素 定义应用程序要查询的 S3 路径:
从分区
dt= "2009-04-12-19-05" 查询数据时,应用程序仅列出并读取 S3 路径 s3://us-east-1.elasticmapreduce/samples/hive-ads/tables/impressions/dt="2009-04-12-19-05"
中的文件。
在数据目录的表中添加分区的不同方法
有多种方法可以将分区加载到表中。
对于接下来的示例,我们需要删除并重新创建表。在 Athena 查询编辑器中运行以下命令:
之后,重新创建表:
单独创建分区
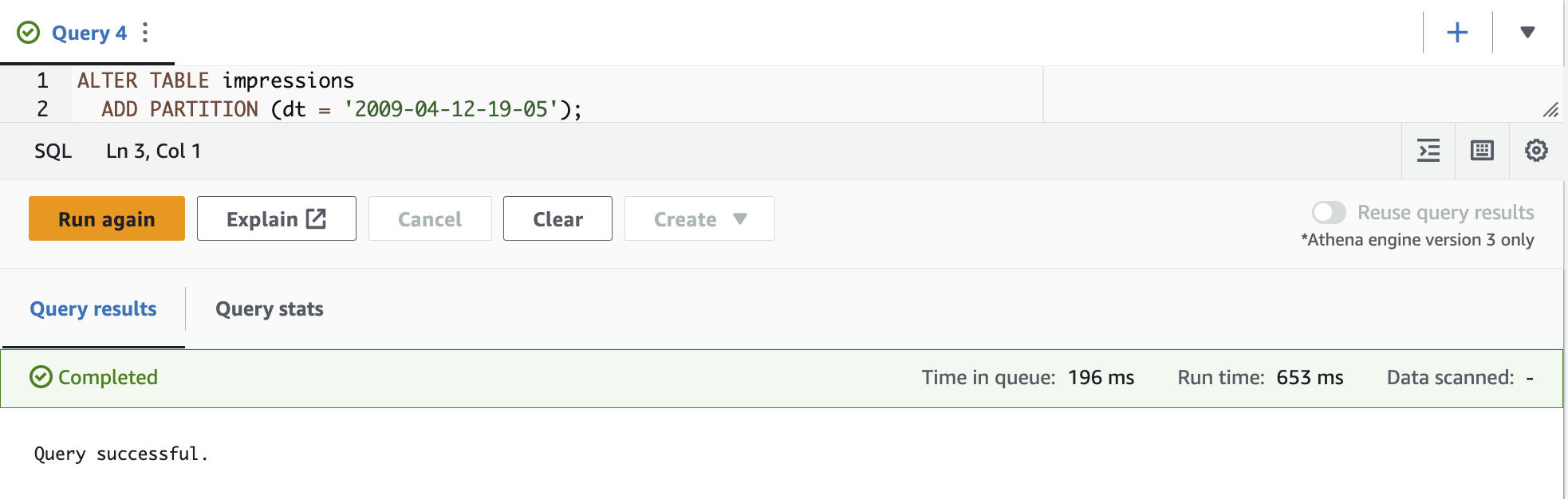
如果数据在预定时间(例如每小时或每天一次)到达一个 S3 存储桶,则可以单独添加分区。其中一种方法是在雅典娜上运行
ALTER TABLE ADD PARTITION DDL
查询。
我们在这个查询中使用 Athena 作为示例。你可以在亚马逊 EMR 上的 Hive、
要使用 Athena 加载分区,我们需要使用
ALTER TABLE ADD
PARTITION 命令,该命令可以在表中创建一个或多个分区。
ALTER TABLE ADD
PARTION 支持在 Amazon S3 上使用驼峰大小写 (
s3://bucket/table/dayOfTheYear=20)、Hive 格式 (s3://bucket/table/dayoftheyear=20 ) 和
AWS CloudTra il 日志使用的非 Hive 样式分区方案创建的分区,后者使用单独的路径组件作为日期部分,例如 s3://bucket/data/2021/01/26/us/6fc7845e.json。
要将分区加载到表中,可以在 Athena 查询编辑器中运行以下查询:
有关更多信息,请参阅
另一种选择是使用 亚马逊云科技 Glue API。亚马逊云科技 Glue 提供了两个 API,用于将分区加载到表
create_partition () 和
中。 有关 API 参数,请参阅
batch
_create_partition ()
以下示例使用 亚马逊云科技 CLI:
这两个命令(雅典娜 中的
ALTER TA
BLE 和 亚马逊云科技 Glu
e API 创建分区
)都将根据表定义创建分区增强功能。
使用 MSCK 修复表加载多个分区
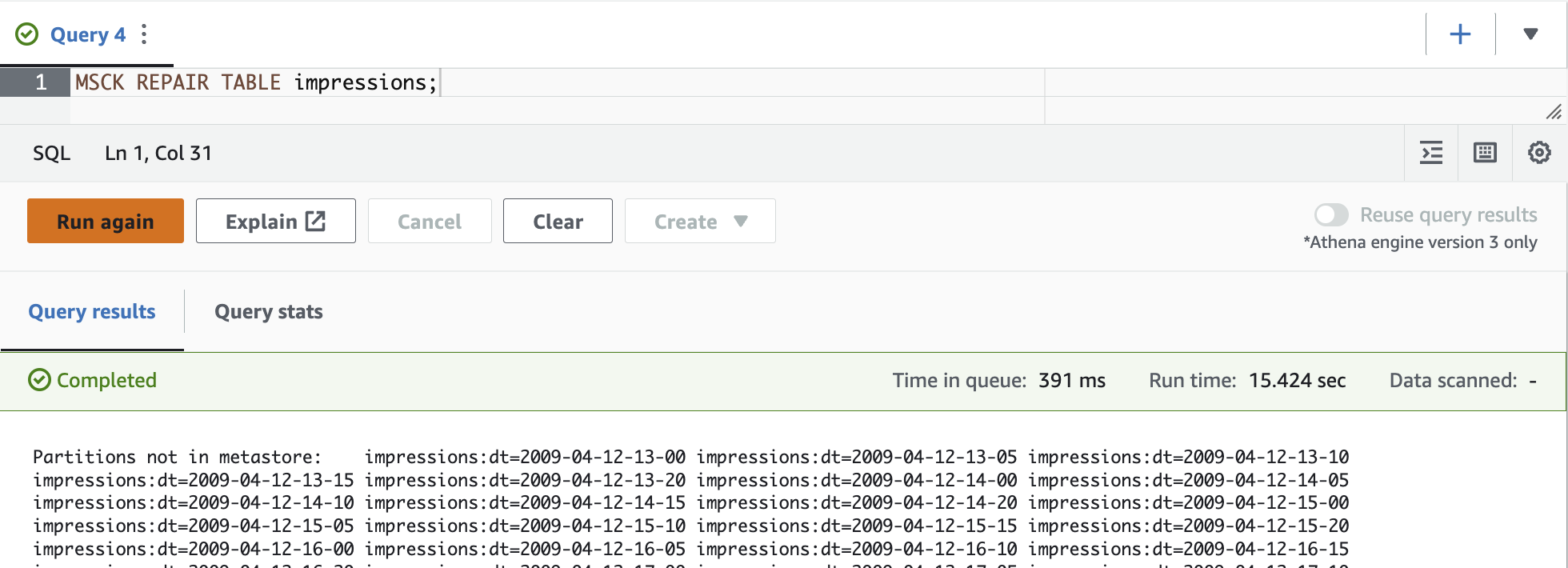
你可以在 Athena 中加载多个分区。
MSCK REPAIR TABLE
是一条 DDL 语句,用于扫描表的位置属性中定义的 整个 S3 路径。
雅典娜列出了搜索 Hive 兼容分区的 S3 路径,然后将现有分区加载到 亚马逊云科技 Glue 表的元数据中。需要在数据目录中创建表,并且数据源必须来自 Amazon S3 才能运行。您可以使用 亚马逊云科技 Glue API 创建表,也可以通过在 Athena 中运行 CREAT
E TABLE 语句来 创建表
。创建表后,运行
MSCK 修复表
来加载分区。
服务配额中的 DDL 查询超时参数定义了 DDL 语句可以运行多长时间。运行时间随着 S3 路径中文件夹或分区数量的增加而增加。
MSCK REPAIR TA
BLE 命令最适合首次创建表或数据和分区元数据之间的奇偶性存在不确定性时。
它支持以小写形式创建并使用 Hive 风格的分区格式(例如,year=2023/month=6/day=01)创建的文件夹。
由于
MSCK REPAI R TABLE
会扫描文件夹及其子文件夹以找到匹配的分区方案,因此应将单独表的数据保存在单独的文件夹层次结构中。
每个
MSCK REPAIR TABLE
命令都会列出表格位置中指定的整个文件夹。如果您经常添加新分区(例如,每 5 分钟或每小时添加一次),可以考虑安排
ALTER TABLE AD
D PARTITION 语句仅加载语句中定义的分区,而不是扫描整个 S3 路径。
MSCK REPAIR TABLE 在数据目录中创建的分区 增强了表
定义中的架构。请注意,雅典娜不收取 DDL 语句的费用,这使得
MSCK REPAIR TA
BLE 成为 一种更简单、更实惠的加载分区的方式。
使用 亚马逊云科技 Glue 爬虫添加多个分区
在将分区加载到表中时,亚马逊云科技 Glue 爬虫可提供更多功能。爬虫会自动识别 Amazon S3 中的分区、提取元数据并在数据目录中创建表定义。爬虫可以抓取以下
爬虫可以帮助自动创建表并将分区加载到表中。它们按小时收费,按秒计费。您可以通过更改样本大小等参数或将其指定为仅抓取新文件夹来优化爬网程序的性能。
如果数据架构发生变化,Crawler 将相应地更新表和分区架构。Crawler 配置选项具有诸如更新数据目录中的表定义、仅添加新列、忽略更改且不更新数据目录中的表等参数,这些参数告诉搜寻器如何在需要时更新表并改进表架构。
爬虫可以从同一个数据源创建和更新多个表。当 亚马逊云科技 Glue 爬虫扫描 Amazon S3 并检测到多个目录时,它会使用启发式方法来确定表的根目录在目录结构中的位置以及哪些目录是表的分区。
要创建 亚马逊云科技 Glue 爬虫,请完成以下步骤:
- 在 亚马逊云科技 Glue 控制台上, 在导航窗格的 “ 数据目录 ” 下选择 “ 爬虫 ”。
-
选择 “
创建爬虫
”。
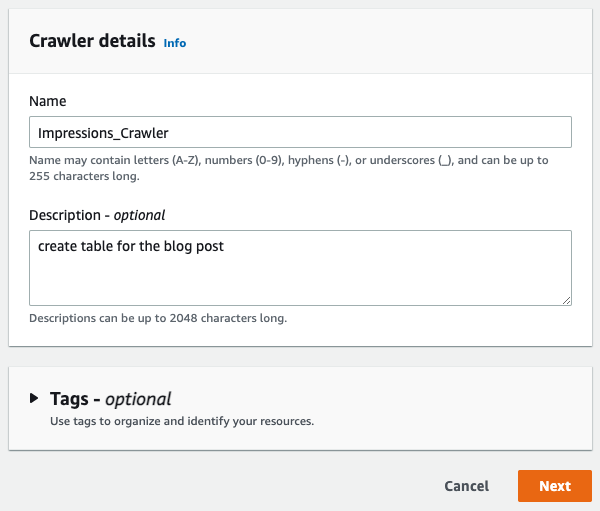
-
提供名称和可选描述,然后选择
下一步
。
-
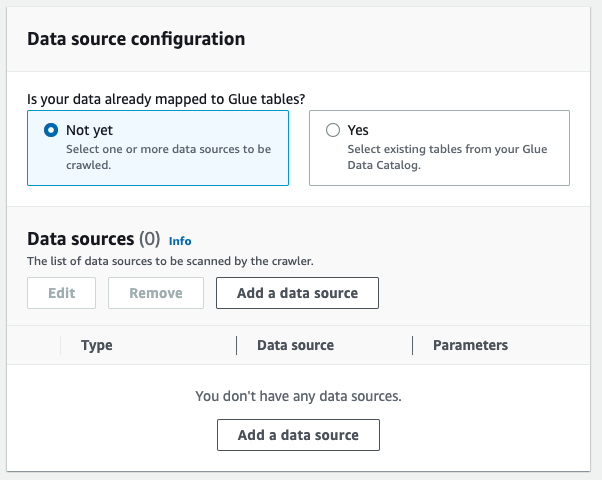
在 “
数据源配置
” 下 ,选择 “
还 没有
”, 然后选择 “
添加数据源
” 。
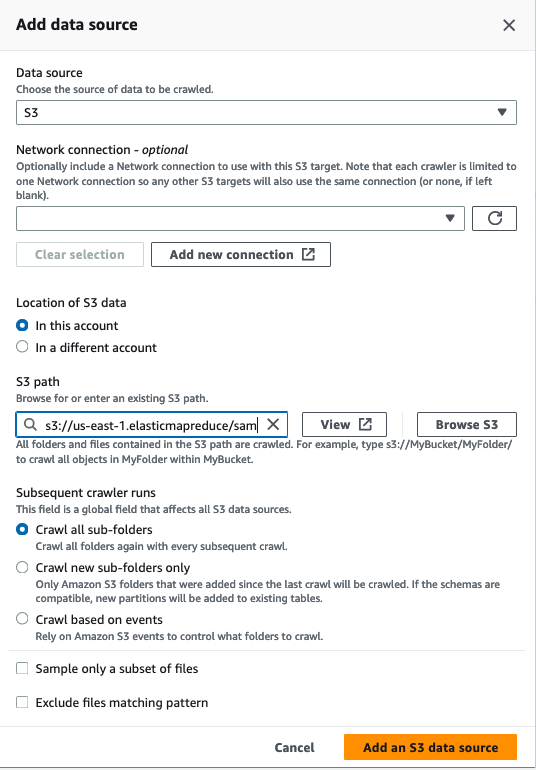
- 对于 数据源 ,选择 S3 。
-
对于
S3 路
径 ,输入展示数据的路径 (
s3://us-east-1.elasticmapreduce/samples/hive-ads/tables/impressions)。 - 为后续的爬虫运行选择首选项。
-
选择
添加 S3 数据源
。
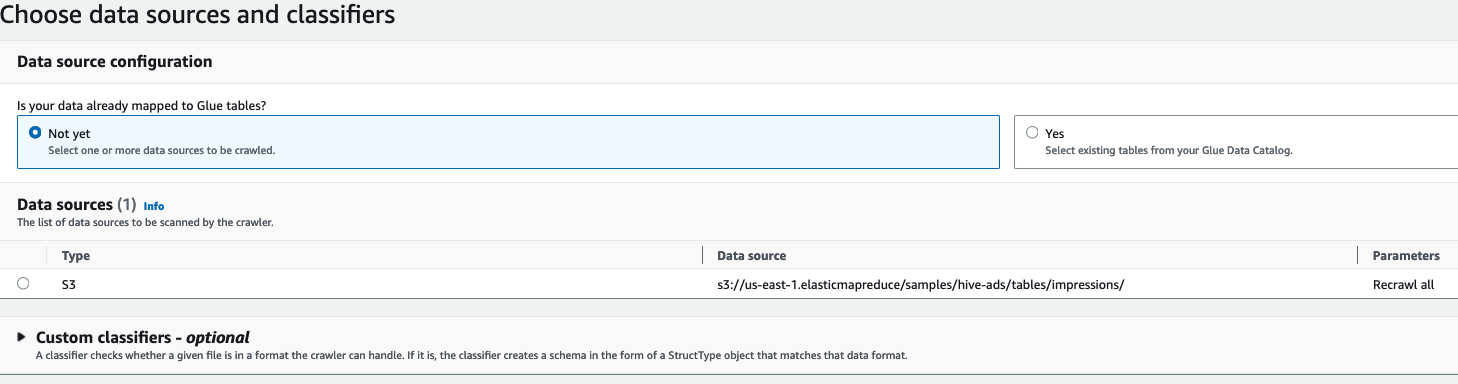
-
选择您的数据源,然后选择 “
下一步
” 。
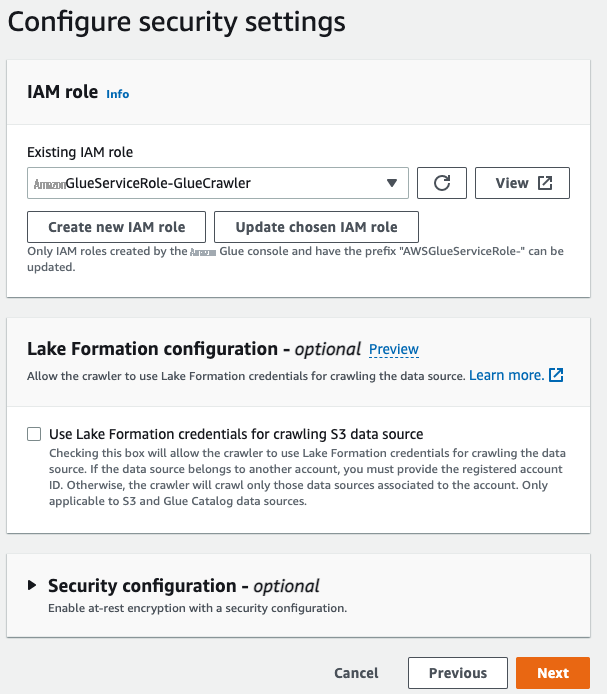
-
在
IAM 角色
下 ,选择现有
的 亚马逊云科技 身份和访问管理 (IAM) 角色或选择 创建新的 IAM 角色 。 -
选择 “
下一步
” 。
-
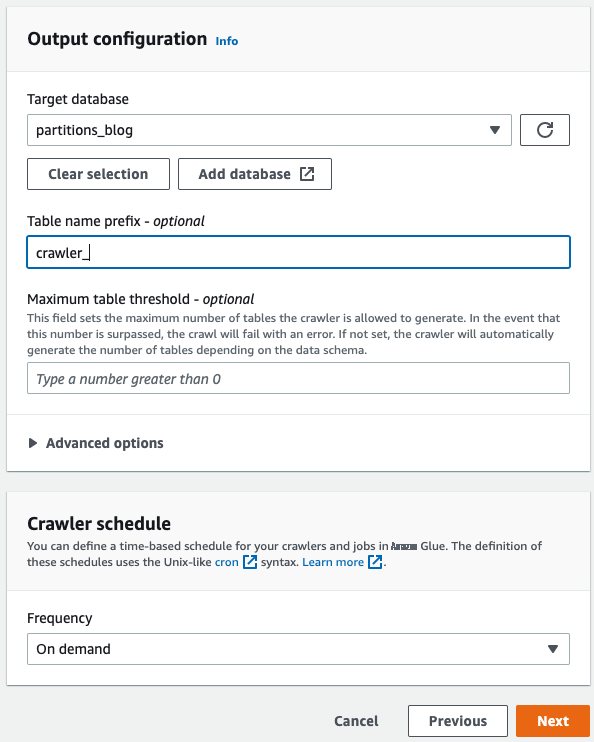
对于
目标数据库
,选择
分区_博客。 -
对于
表名前缀
,输入 c
rawler_。
我们使用表前缀在表名前面添加自定义前缀。例如,如果你将前缀字段留空并在
s3://my-bucket/some-table-backup
上启动爬虫,它会创建一个名为 some-table-backup 的表。
如果你将 c
rawler_
添加为前缀,它会创建一个名 为 crawler_some-table-backup 的表。
-
选择您的爬虫时间表,然后选择
Next
。
- 查看您的设置并创建爬虫。
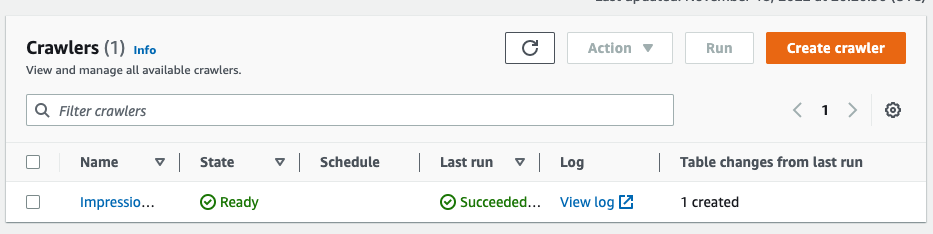
-
选择您的爬虫并选择 “
运行
”。

等待爬虫完成运行。
你可以前往 Athena 查看表格是否已创建:
在采集和编目时对存储在 Amazon S3 中的数据进行分区
前面的示例处理的是 Amazon S3 中已经存在的数据。如果您使用 亚马逊云科技 Glue 任务在 Amazon S3 上写入数据,则可以通过
启用 “enable
UpdateCatalog=True” 参数来选择使用 DynamicFrames 创建分区。 有关详细信息
DynamicFrame 支持使用一系列按键进行本机分区,在创建接收器时使用 PartitionKeys 选项。例如,以下 Python 代码以 Parquet 格式将数据集写入 Amazon S3,写入按
“年份”
字段分区的目录中。从 亚马逊云科技 Glue 作业中提取数据并注册分区后,您可以利用在其他分析引擎(例如 Athena)上运行的查询中的这些分区。
结论
这篇文章展示了对您的Amazon S3数据进行分区的多种方法,这些方法通过避免不必要的数据扫描来帮助降低成本,还可以提高流程的整体性能。我们进一步描述了 亚马逊云科技 Glue 如何使有效的分区元数据管理成为可能,从而使您能够优化 亚马逊云科技 Glue 和 Athena 中的存储和查询操作。这些分区方法可以帮助优化扫描大量数据或长时间运行的查询,并降低扫描成本。
我们希望你能试试这些选项!
作者简介
 安德森·桑托斯
是亚马逊网络服务的高级解决方案架构师。他与 亚马逊云科技 企业客户合作,提供指导和技术援助,帮助他们在使用 亚马逊云科技 时提高解决方案的价值。
安德森·桑托斯
是亚马逊网络服务的高级解决方案架构师。他与 亚马逊云科技 企业客户合作,提供指导和技术援助,帮助他们在使用 亚马逊云科技 时提高解决方案的价值。
 Arun Pradeep Selvaraj
是一名高级解决方案架构师,也是 亚马逊云科技 Analytics TFC 的一员。Arun 热衷于与客户和利益相关者合作进行云端的数字化转型和创新,同时继续学习、构建和重塑。他富有创造力、快节奏、深深地着迷于客户,并利用向后工作的流程来构建现代架构,以帮助客户解决其独特的挑战。
Arun Pradeep Selvaraj
是一名高级解决方案架构师,也是 亚马逊云科技 Analytics TFC 的一员。Arun 热衷于与客户和利益相关者合作进行云端的数字化转型和创新,同时继续学习、构建和重塑。他富有创造力、快节奏、深深地着迷于客户,并利用向后工作的流程来构建现代架构,以帮助客户解决其独特的挑战。
 帕特里克·穆勒
是一位高级解决方案架构师,也是数据实验室的重要成员。他在分析、数据仓库和分布式系统方面拥有 20 多年的专业知识,为我们带来了丰富的知识。Patrick 的热情在于评估新技术并帮助客户提供创新的解决方案。在空闲时间,他喜欢看足球。
帕特里克·穆勒
是一位高级解决方案架构师,也是数据实验室的重要成员。他在分析、数据仓库和分布式系统方面拥有 20 多年的专业知识,为我们带来了丰富的知识。Patrick 的热情在于评估新技术并帮助客户提供创新的解决方案。在空闲时间,他喜欢看足球。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。