我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用部署在亚马逊 SageMaker 上的生成式人工智能生成创意广告
生成式人工智能(GenAI)有可能彻底改变创意广告。现在,通过重新训练 GenAI 模型并为模型提供一些输入,例如文本提示(描述场景的句子和模型要生成的物体),您可以创建各种各样的新颖图像,例如产品镜头。
在这篇文章中,我们将探讨如何利用这种变革性技术大规模制作引人入胜的创新广告,尤其是在处理大量图像时。通过利用 GenAI 的力量,特别是通过修复技术,我们可以无缝创建图像背景,从而产生视觉上令人惊叹和引人入胜的内容,并减少不必要的图像伪像(称为
模型
幻觉)。 我们还通过利用
我们使用修复作为基于 Genai 的图像生成的关键技术,因为它为替换图像中缺失的元素提供了强大的解决方案。但是,这带来了一些挑战。例如,对图像中对象位置的精确控制可能会受到限制,从而导致潜在问题,例如图像伪影、浮动对象或未混合边界,如以下示例图像所示。

为了克服这个问题,我们在本文中建议通过使用最少的监督生成大量 逼 真的图像,在创作自由和高效制作之间取得平衡。为了扩展提议的生产解决方案并简化 AI 模型在 亚马逊云科技 环境中的部署,我们使用 SageMaker 终端节点进行演示。
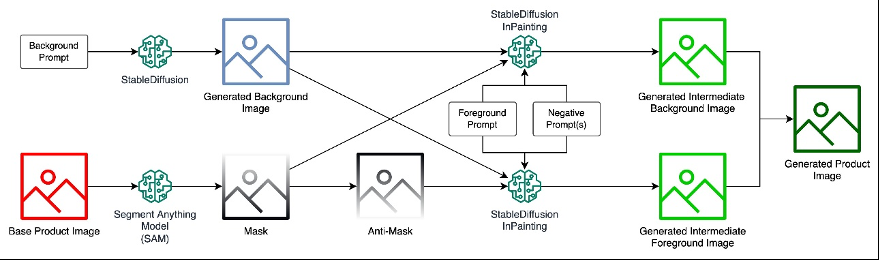
特别是,我们建议将修复过程拆分为一组图层,每个图层可能有一组不同的提示。该过程可以概括为以下步骤:
- 首先,我们提示输入一般场景(例如,“后面有树的公园”),然后将物体随机放置在该背景上。
- 接下来,我们通过提示物体所在的位置(例如,“在草地上野餐或木桌”),在物体的中下半部分添加一个图层。
- 最后,我们使用与背景相同的提示在物体的中上部添加一个与背景层相似的图层。
该过程的好处是提高了物体的真实感,因为相对于背景环境,可以更好地感知物体的缩放和定位,符合人类的期望。下图显示了提议的解决方案的步骤。

解决方案概述
为了完成任务,需要考虑以下数据流:
-
分段任意模型 (SAM) 和稳定扩散修复 模型托管在Sage Maker 端点中。 - 背景提示用于使用稳定扩散模型创建生成的背景图像
- 基础产品图像通过 SAM 生成掩码。面具的反面称为反面罩。
- 生成的背景图像、蒙版以及前景提示和负面提示用作稳定扩散修复模型的输入,以生成生成的中间背景图像。
- 同样,生成的背景图像、防掩模以及前景提示和负面提示被用作稳定扩散修复模型的输入,以生成生成的中间前景图像。
- 生成的产品图像的最终输出是通过组合生成的中间前景图像和生成的中间背景图像来获得的。
先决条件
我们开发了一
您将需要一个具有 AW
- 亚马逊云科技 CloudFormation
-
SageMaker
-
尽管 SageMaker 端点提供了运行机器学习模型的实例,但为了运行生成式 AI 模型等繁重的工作负载,我们使用支持 GPU 的 SageMaker 端点。有关定价的更多信息, 请参阅
亚马逊 SageMaker 定价。 -
我们使用支持 NVIDIA A10G 的实例
ml.g5.2xlarge 来托管模型。
-
尽管 SageMaker 端点提供了运行机器学习模型的实例,但为了运行生成式 AI 模型等繁重的工作负载,我们使用支持 GPU 的 SageMaker 端点。有关定价的更多信息, 请参阅
-
亚马逊 Simple Storage Servic e (亚马逊 S3)
欲了解更多详情,请查看
掩盖产品的感兴趣区域
通常,我们需要提供要放置的物体的图像和描绘物体轮廓的蒙版。这可以使用
使用 SAM 生成掩码
借助先进的生成式 AI 技术 SAM,我们可以毫不费力地为图像中的各种物体生成高质量的蒙版。SAM 使用在大量数据集上训练的深度学习模型来准确识别和分割感兴趣的对象,从而提供精确的边界和像素级掩码。这项突破性技术通过自动执行手动创建口罩的耗时和劳动密集型任务,彻底改变了图像处理工作流程。借助 SAM,企业和个人现在可以快速生成用于物体识别、图像编辑、计算机视觉任务等的口罩,从而开启视觉分析和操作的无限可能性。
在 SageMaker 端点上托管 SAM 模型
我们使用笔记本
我们使用
中的推理代码 并将其打包到一个
code.tar.gz 文件
中,我们用它来创建 SageMaker 端点。该代码下载 SAM 模型,将其托管在端点上,并提供运行推理和生成输出的入口点:
SAM_ENDPOINT_NAME = 'sam-pytorch-' + str(datetime.utcnow().strftime('%Y-%m-%d-%H-%M-%S-%f'))
prefix_sam = "SAM/demo-custom-endpoint"
model_data_sam = s3.S3Uploader.upload("code.tar.gz", f's3://{bucket}/{prefix_sam}')
model_sam = PyTorchModel(entry_point='inference_sam.py',
model_data=model_data_sam,
framework_version='1.12',
py_version='py38',
role=role,
env={'TS_MAX_RESPONSE_SIZE':'2000000000', 'SAGEMAKER_MODEL_SERVER_TIMEOUT' : '300'},
sagemaker_session=sess,
name='model-'+SAM_ENDPOINT_NAME)
predictor_sam = model_sam.deploy(initial_instance_count=1,
instance_type=INSTANCE_TYPE,
deserializers=JSONDeserializer(),
endpoint_name=SAM_ENDPOINT_NAME)调用 SAM 模型并生成掩码
以下代码是
结果:
raw_image = Image.open("images/speaker.png").convert("RGB")
predictor_sam = PyTorchPredictor(endpoint_name=SAM_ENDPOINT_NAME,
deserializer=JSONDeserializer())
output_array = predictor_sam.predict(raw_image, initial_args={'Accept': 'application/json'})
mask_image = Image.fromarray(np.array(output_array).astype(np.uint8))
# save the mask image using PIL Image
mask_image.save('images/speaker_mask.png')下图显示了从产品图像中获得的生成的掩膜。

使用修复来创建生成的图像
通过将修复的力量与 SAM 生成的掩码和用户的提示相结合,我们可以创建出色的生成的图像。修复利用先进的生成式 AI 技术智能地填充图像中缺失或被掩盖的区域,将其与周围内容无缝融合。使用 SAM 生成的面具作为指导,将用户的提示作为创意输入,修复算法可以生成视觉上连贯且符合情境的内容,从而生成令人惊叹的个性化图像。这种技术的融合开辟了无限的创作可能性,使用户能够将他们的愿景转化为生动、引人入胜的视觉叙事。
在 SageMaker 端点上托管稳定的扩散修复模型
与 2.1 类似,我们使用笔记本
我们使用
中的推理代码 并将其打包到一个
code.tar.gz
文件中,我们用它来创建 SageMaker 端点。该代码下载稳定扩散修复模型,将其托管在端点上,并提供运行推理和生成输出的入口点:
INPAINTING_ENDPOINT_NAME = 'inpainting-pytorch-' + str(datetime.utcnow().strftime('%Y-%m-%d-%H-%M-%S-%f'))
prefix_inpainting = "InPainting/demo-custom-endpoint"
model_data_inpainting = s3.S3Uploader.upload("code.tar.gz", f"s3://{bucket}/{prefix_inpainting}")
model_inpainting = PyTorchModel(entry_point='inference_inpainting.py',
model_data=model_data_inpainting,
framework_version='1.12',
py_version='py38',
role=role,
env={'TS_MAX_RESPONSE_SIZE':'2000000000', 'SAGEMAKER_MODEL_SERVER_TIMEOUT' : '300'},
sagemaker_session=sess,
name='model-'+INPAINTING_ENDPOINT_NAME)
predictor_inpainting = model_inpainting.deploy(initial_instance_count=1,
instance_type=INSTANCE_TYPE,
serializer=JSONSerializer(),
deserializers=JSONDeserializer(),
endpoint_name=INPAINTING_ENDPOINT_NAME,
volume_size=128)调用稳定扩散修复模型并生成新图像
与调用 SAM 模型的步骤类似,笔记本电脑
结果:
raw_image = Image.open("images/speaker.png").convert("RGB")
mask_image = Image.open('images/speaker_mask.png').convert('RGB')
prompt_fr = "table and chair with books"
prompt_bg = "window and couch, table"
negative_prompt = "longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, letters"
inputs = {}
inputs["image"] = np.array(raw_image)
inputs["mask"] = np.array(mask_image)
inputs["prompt_fr"] = prompt_fr
inputs["prompt_bg"] = prompt_bg
inputs["negative_prompt"] = negative_prompt
predictor_inpainting = PyTorchPredictor(endpoint_name=INPAINTING_ENDPOINT_NAME,
serializer=JSONSerializer(),
deserializer=JSONDeserializer())
output_array = predictor_inpainting.predict(inputs, initial_args={'Accept': 'application/json'})
gai_image = Image.fromarray(np.array(output_array[0]).astype(np.uint8))
gai_background = Image.fromarray(np.array(output_array[1]).astype(np.uint8))
gai_mask = Image.fromarray(np.array(output_array[2]).astype(np.uint8))
post_image = Image.fromarray(np.array(output_array[3]).astype(np.uint8))
# save the generated image using PIL Image
post_image.save('images/speaker_generated.png')下图显示了精制后的蒙版、生成的背景、生成的产品图像和后处理的图像。

生成的产品图片使用以下提示:
- 背景生成 — “椅子、沙发、窗户、室内”
- 油漆 —— “除了书”
清理
在这篇文章中,我们使用了两个支持 GPU 的 SageMaker 端点,这占了大部分成本。应关闭这些端点,以免在不使用端点时产生额外费用。我们提供了一个名为
端点。我们还使用 SageMaker 笔记本来托管模型并运行推理。因此,如果不使用笔记本实例,最好将其停止。
结论
生成式 AI 模型通常是需要特定资源才能高效运行的大规模机器学习模型。在这篇文章中,我们使用广告用例演示了 SageMaker 端点如何为托管生成式 AI 模型(例如文本到图像基础模型 Stable Diffusion)提供可扩展的托管环境。我们演示了如何托管和根据需要运行两个
详细代码可在
作者简介
 Fabian Benitez-Quiroz 是 A
WS 专业服务领域的物联网边缘数据科学家。他拥有俄亥俄州立大学计算机视觉和模式识别博士学位。Fabian 参与帮助各行各业的客户在物联网设备和云端以低延迟运行机器学习模型。
Fabian Benitez-Quiroz 是 A
WS 专业服务领域的物联网边缘数据科学家。他拥有俄亥俄州立大学计算机视觉和模式识别博士学位。Fabian 参与帮助各行各业的客户在物联网设备和云端以低延迟运行机器学习模型。
 Romil Shah
是 亚马逊云科技 专业服务的高级数据科学家。Romil 在计算机视觉、机器学习和物联网边缘设备方面拥有 6 年以上的行业经验。他参与帮助客户优化和部署边缘设备和云端的机器学习模型。他与客户合作制定优化和部署基础模型的策略。
Romil Shah
是 亚马逊云科技 专业服务的高级数据科学家。Romil 在计算机视觉、机器学习和物联网边缘设备方面拥有 6 年以上的行业经验。他参与帮助客户优化和部署边缘设备和云端的机器学习模型。他与客户合作制定优化和部署基础模型的策略。
 Han Man
是位于加利福尼亚州圣地亚哥的 亚马逊云科技 专业服务的高级数据科学和机器学习经理。他拥有西北大学的工程博士学位,并拥有多年管理顾问经验,为制造业、金融服务和能源领域的客户提供咨询。如今,他热衷于与来自不同垂直行业的关键客户合作,在 亚马逊云科技 上开发和实施 ML 和 GenAI 解决方案。
Han Man
是位于加利福尼亚州圣地亚哥的 亚马逊云科技 专业服务的高级数据科学和机器学习经理。他拥有西北大学的工程博士学位,并拥有多年管理顾问经验,为制造业、金融服务和能源领域的客户提供咨询。如今,他热衷于与来自不同垂直行业的关键客户合作,在 亚马逊云科技 上开发和实施 ML 和 GenAI 解决方案。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。