我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
在所有 Graviton 内核上启动基于虚幻引擎的游戏
这篇文章由首席解决方案架构师 Yahav Biran 和南澳游戏部负责人 Matt Trescot(美洲)撰写
从历史上看,创建和运行复杂游戏服务器的艺术将开发人员锁定在单一的 CPU 架构中,通常是英特尔/AMD。我们的开发人员告诉我们,一旦为给定的处理器构建了游戏服务器,就很难引入不同的 CPU 架构。在本文中,我们将向您展示如何构建完全支持
专用的游戏服务器需要以可预测的每个 CPU 内核的滴答速率支持多个玩家;此外,3D 计算等玩家事件需要以相同的滴答率批量发送给连接的玩家,以获得有趣和公平的游戏体验。因此,它要求将 CPU 内核完全分配给游戏会话,以避免同步多线程导致的上下文切换。结果,游戏服务器运营商问我们如何在基于 x86 的服务器上
我们着手将两台服务器的CPU容量加载到它们的CPU容量,因此我们使用了30个射击机器人(

图 1 — 在两种类型的 CPU 上进行负载测试期间,机器人生成
游戏服务器从 12:30 开始,我们在 12:40 之前添加了 30 个机器人,每个会话有 5 个玩家,其中两个服务器(上图 — Lyra-x86 和 Lyra-Graviton)都已满足 CPU 容量。我们让游戏运行 10 个游戏会话,每个会话 11 分钟,并观察到游戏服务器的出站流量(中间图 — pod_network_tx_bytes)和内存分配(下图)。
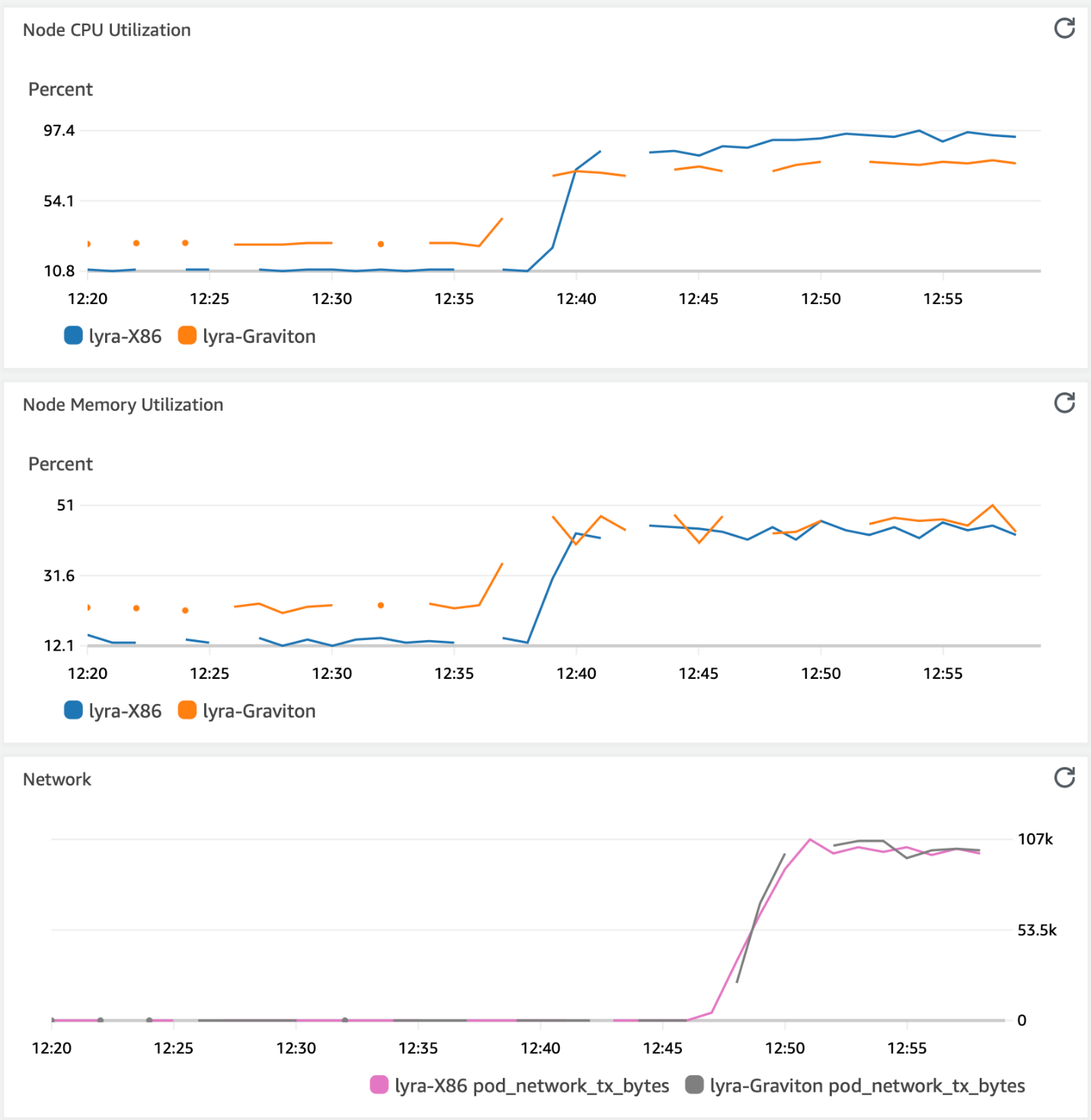
图 2 — 仿真期间的资源使用情况
模拟表明,基于稳定的出站流量和两台服务器的内存消耗,连接的客户端可以获得接近真实的游戏体验。X86 实例(Lyra-x86)的 CPU 使用率为 97%,而 Graviton 实例(Lyra-Graviton)消耗了 75%。
这篇文章的其余部分解释了如何利用Graviton的性价比优势。我们将从支持这两个 CPU 架构的游戏镜像构建过程开始。接下来,我们将描述如何部署游戏、玩游戏并观察结果。
我们是如何构建多平台游戏映像的
为了更好地适应博客格式,对以下代码和配置摘录进行了编辑。完整的示例代码发布在
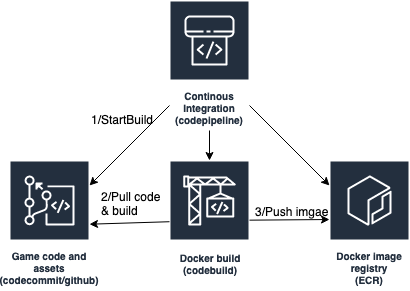
图 3 — 游戏持续集成
我们使用 亚马逊云科技 CodePipeline 来自动化游戏构建过程。首先,使用
构建过程需要创建两个不同的映像,因为 Amazon Graviton 实例使用 ARM RISC(精简指令集计算机),而英特尔使用 CISC(复杂指令集计算机)。我们修改了与 Docker 多平台映像的现有持续集成,因此游戏镜像同时引用 Graviton 和 x86 处理器,以简化持续交付系统中的配置。
第一步(1/startBuild)是使用
避免使用特定平台的软件包名称(如 amd64 和 aarch64)来简化编译脚本。例如,不要使用:
ARG arch=aarch64 或 amd64
RUN curl” https://awscli.amazonaws.com/awscli-exe-linux${ARCH}.zip”
运行解压缩 awscliv2.zip
跑。/aws/安装
使用:
运行 pip 安装 awscli
接下来,我们通过重用 x86 的 docker 构建步骤来构建(2/提取代码并构建)镜像,然后在基于 Graviton 的实例上运行它(参见 buildAssets 和 Buil
请注意,我们的示例使用 Graviton 和 x86 的 CodeBuild 映像来构建相同的代码和配置。额外的 CodeBuild 步骤(buildAmAssets)与原始步骤(buildAssets)同时运行,全新构建的总构建时间保持 12 分钟,使用 ECR 缓存进行持续增量构建时的总构建时间保持 5 分钟。
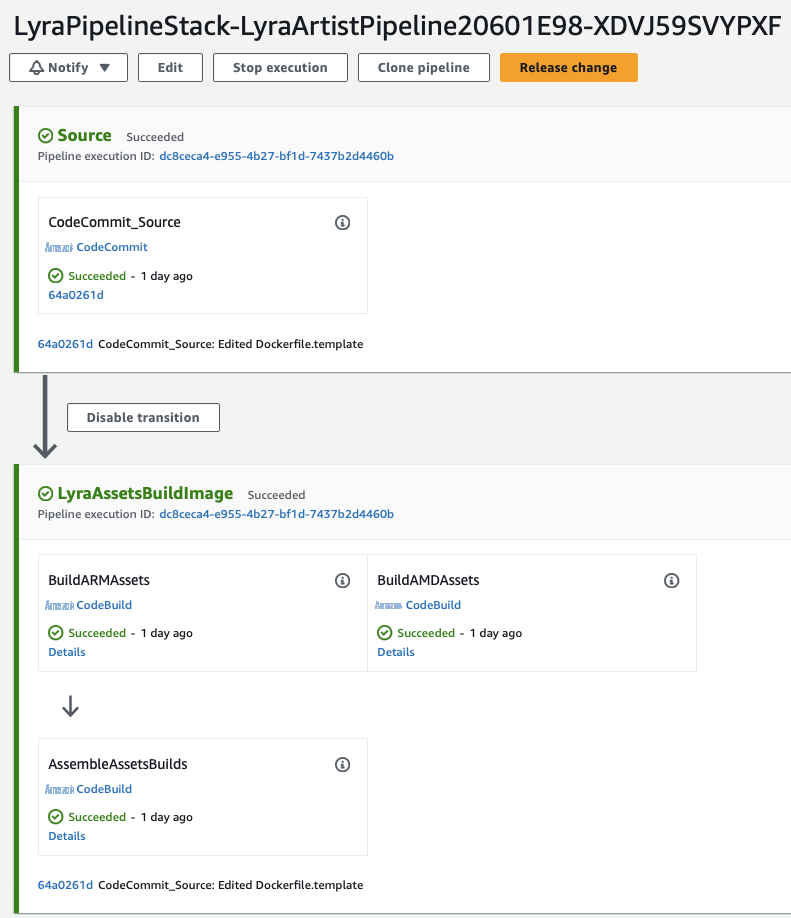
图 4 — 在 ECR 中提取代码并使用单个图像 URI 生成两个图像的 CodePipeline
我们是如何部署游戏的
我们在
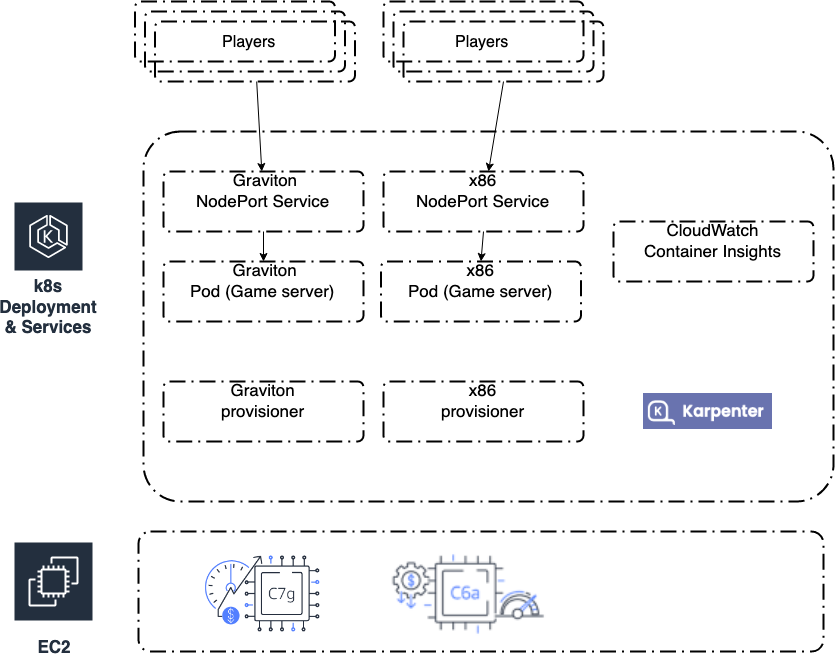
我们使用多平台 docker 镜像来确保两个 k8s 部署变体运行相同的代码和配置。我们使用
最后,我们使用 pod 生命周期 preStop 挂钩在 pod 终止时清理服务。
image: $AWS_ACCOUNT.dkr.ecr.$AWS_REGION.amazonaws.com/lyra:lyra_starter_game
imagePullPolicy: Always
command: ["/usr/local/lyra_starter_game/LyraServer.sh"]
lifecycle:
postStart:
exec:
command:["/usr/local/lyra_starter_game/create_node_port_svc.sh"]
preStop:
exec:
command:["kubectl delete svc `kubectl get svc|grep $POD_NAME | awk '{print $1}'`"]按照教程亲自尝试一下,并按照快速入门说明部署 Amazon EKS 容器洞察。
玩游戏并观察游戏服务器性能
玩游戏的最后一步是发现游戏服务器端点并将游戏客户端连接到 Lyra Game Starter 服务器。
在下面的示例中,我们的游戏服务器端点是:
34.216.42。162:32384,35.82.31。15:32019
[$] kubectl 获取 svc | grep NodePort| awk '{打印 $1,5 美元}'
lyramd64-6bf8cdd4db-ts7hq-svc-34-216-42-162 7777:32384 /UDP
lyrarm64-5568b7bc6c-wtrqx-svc-35-82-31-15 7777:32019 /UDP
如果你在构建阶段还没有这样做,请为你最喜欢的操作系统编译和打包客户端二进制文件,然后连接游戏服务器。在 Windows 上:
。/Binaries/Win64/
。/Binaries/Win64/
见,此处设置了-WINDOWED 、-resx=
resy= 命令行
。这使您能够在同一个屏幕上看到两个客户端窗口以进行测试。
此时你将进入两个游戏会话所以准备好射击 30 个机器人 😀

结论
Graviton 实例提供了为大量玩家提供卓越游戏体验所需的可扩展性、性能和成本效益。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。