我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
亚马逊 SageMaker Ground Truth Plus 中的几次点击分段掩码标签
2019 年,
极限点击,校正点击次数灵活
现在,我们增强了该工具,允许额外点击边界点,从而为机器学习模型提供实时反馈。这使您可以创建更准确的分段掩码。在以下示例中,由于阴影附近的边界较弱,初始分割结果不准确。重要的是,该工具在允许实时反馈的模式下运行——它不需要您一次指定所有点。相反,你可以先点击四次鼠标,这将触发机器学习模型生成分段掩码。然后,您可以检查此掩码,找出任何潜在的不准确之处,然后根据需要再次单击,以 “推动” 模型,得出正确的结果。

我们之前的贴标工具允许您准确点击四次鼠标(红点)。初始分割结果(红色阴影区域)不准确,因为阴影附近的边界很弱(红色蒙版的左下角)。
使用我们的增强标签工具,用户再次首先单击四次鼠标(上图为红点)。然后,你有机会检查生成的分段掩码(上图为红色阴影区域)。您可以再次点击鼠标(下图中的绿色圆点)以使模型优化蒙版(底部图中的红色阴影区域)。

与该工具的原始版本相比,增强版在物体可变形、非凸起以及形状和外观变化时提供了改进的结果。
我们首先运行基线工具(仅需四次极限点击)来生成分割掩膜,然后评估其平均交叉点(MiOU),这是衡量分割掩码精度的常用指标,从而模拟了该改进工具在样本数据上的性能。然后,我们应用了模拟校正点击次数,并在每次模拟点击后评估了 MiOU 中的改进。下表总结了这些结果。第一行显示 MiOU,第二行显示错误(由 100% 减去 MiOU 得出)。只需再点击五次鼠标,我们就可以将此任务的错误减少9%!
| . | . | Number of Corrective Clicks | . | |||
| . | Baseline | 1 | 2 | 3 | 4 | 5 |
| mIoU | 72.72 | 76.56 | 77.62 | 78.89 | 80.57 | 81.73 |
| Error | 27% | 23% | 22% | 21% | 19% | 18% |
与 Ground Truth 和性能分析集成
为了将此模型与 Ground Truth 集成,我们遵循下图所示的标准架构模式。首先,我们将机器学习模型构建到 Docker 镜像中,然后将其部署到
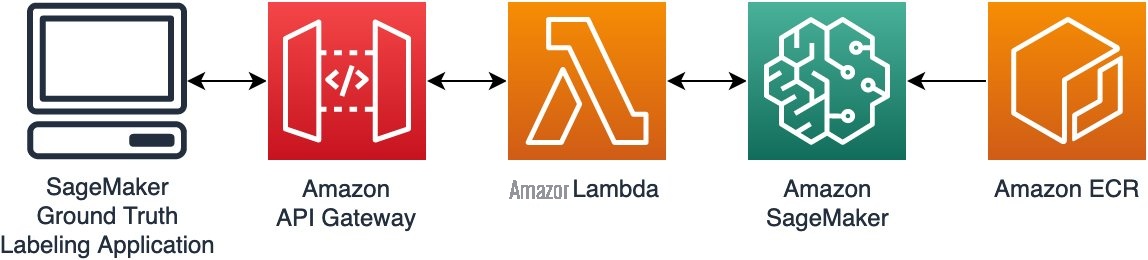
对于专门构建的 ML 工具,您可以根据自己的用例遵循这种通用模式,并将其与自定义 Ground Truth 任务用户界面集成。有关更多信息,请参阅
在预置此架构并使用
在下图中,我们显示了 SageMaker 实时推理端点原生发出的模型延迟指标。我们可以轻松地在 CloudWatch 中使用各种指标数学函数来显示延迟百分位数,例如 p50 或 p90 延迟。
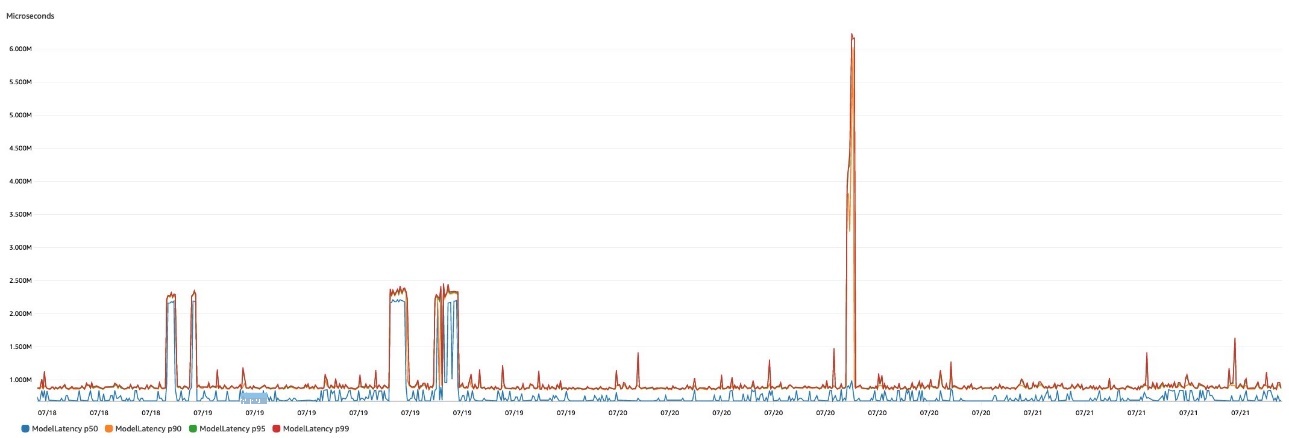
下表汇总了我们用于语义分割的增强型极限点击工具针对三种实例类型的结果:p2.xlarge、p3.2xlarge 和 g4dn.xlarge。尽管 p3.2xlarge 实例提供了最低的延迟,但 g4dn.xlarge 实例提供了最佳的成本性能比。
| SageMaker Instance Type | p90 Latency (ms) | ||
| 1 | p2.xlarge | 751 | |
| 2 | p3.2xlarge | 424 | |
| 3 | g4dn.xlarge | 459 |
结论
在这篇文章中,我们介绍了用于语义分割注释任务的 Ground Truth 自动分段功能的扩展。尽管该工具的原始版本允许您精确点击四次鼠标,从而触发模型提供高质量的分段掩码,但该扩展程序使您能够进行更正的单击,从而更新和指导机器学习模型做出更好的预测。我们还介绍了一种基本的架构模式,您可以使用该模式将交互式工具部署和集成到 Ground Truth 标签用户界面中。最后,我们总结了模型延迟,并展示了如何使用 SageMaker 实时推理端点轻松监控模型性能。
要了解有关该工具如何降低标签成本和提高准确性的更多信息,请访问
作者简介
 乔纳森·巴克
(Jonathan Buck) 是亚马逊网络服务的软件工程师,从事机器学习和分布式系统的交叉工作。他的工作包括制作机器学习模型和开发由机器学习提供支持的新型软件应用程序,以将最新功能交到客户手中。
乔纳森·巴克
(Jonathan Buck) 是亚马逊网络服务的软件工程师,从事机器学习和分布式系统的交叉工作。他的工作包括制作机器学习模型和开发由机器学习提供支持的新型软件应用程序,以将最新功能交到客户手中。
 李二然 是亚马
逊 亚马逊云科技 AI 人类在环服务的应用科学经理。他的研究兴趣是三维深度学习以及视觉和语言表现学习。此前,他是 Alexa AI 的资深科学家、Scale AI 的机器学习负责人和 Pony.ai 的首席科学家。在此之前,他曾在Uber ATG的感知团队和优步的机器学习平台团队工作,致力于自动驾驶、机器学习系统和人工智能战略计划的机器学习。他的职业生涯始于贝尔实验室,曾是哥伦比亚大学的兼职教授。他在ICML'17和ICCV'19上共同教授教程,并在Neurips、ICML、CVPR、ICCV共同组织了多个研讨会,内容涉及自动驾驶的机器学习、三维视觉和机器人、机器学习系统和对抗性机器学习。他在康奈尔大学拥有计算机科学博士学位。他是 ACM 研究员和 IEEE 研究员。
李二然 是亚马
逊 亚马逊云科技 AI 人类在环服务的应用科学经理。他的研究兴趣是三维深度学习以及视觉和语言表现学习。此前,他是 Alexa AI 的资深科学家、Scale AI 的机器学习负责人和 Pony.ai 的首席科学家。在此之前,他曾在Uber ATG的感知团队和优步的机器学习平台团队工作,致力于自动驾驶、机器学习系统和人工智能战略计划的机器学习。他的职业生涯始于贝尔实验室,曾是哥伦比亚大学的兼职教授。他在ICML'17和ICCV'19上共同教授教程,并在Neurips、ICML、CVPR、ICCV共同组织了多个研讨会,内容涉及自动驾驶的机器学习、三维视觉和机器人、机器学习系统和对抗性机器学习。他在康奈尔大学拥有计算机科学博士学位。他是 ACM 研究员和 IEEE 研究员。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。