GraphStorm 是一个低代码企业图机器学习 (ML) 框架,它为机器学习从业者提供了一种基于行业规模的图形数据构建、训练和部署图形机器学习解决方案的简单方法。尽管GraphStorm可以在小图表的单个实例上高效运行,但在使用亚马逊弹性计算云集群(亚马逊EC2)实例或亚马逊SageMaker以分布式模式扩展到企业级图表时,它确实大放异彩。
今天,亚马逊云科技AI 发布了 GraphStorm v0.4。此版本引入了与 DGL-GraphBolt 的集成,这是一个新的图形存储和采样框架,它使用紧凑的图形表示和流水线采样来降低内存要求并加快图形神经网络 (GNN) 的训练和推理。对于本文中研究的大规模数据集,推理加速速度提高了3.6倍,每个周期的训练加速速度提高了1.4倍,甚至可能有更大的加速。
为了实现这一目标,带有 DGL-GraphBolt 的 GraphStorm v0.4 解决了图学习的两个关键挑战:
- 内存限制 — GraphStorm v0.4 为图形结构和特征提供了紧凑的分布式存储,这些存储空间可能会在多 TB 的范围内增长。例如,一个具有 10 亿个节点、每个节点 512 个特征和 100 亿条边的图形将需要超过 4 TB 的内存来存储,这就需要分布式计算。
- 图形采样 — 在多层 GNN 中,您需要对每个节点的邻居进行采样以传播其表示形式。这可能导致采样节点数量呈指数级增长,有可能访问整个图表以获取单个节点的表示形式。GraphStorm v0.4 提供高效的流水线图采样。
在这篇文章中,我们演示了GraphBolt如何增强GraphStorm在分布式环境中的性能。我们提供了一个在 SageMaker 上使用 GraphStorm 和 GraphBolt 进行分布式训练的实际操作示例。最后,我们将分享如何将亚马逊 SageMaker Pipelines 与 GraphStorm 一起使用。
GraphBolt:管道驱动的图形采样
GraphBolt是由DGL团队开发的新数据加载和图形采样框架。它简化了从异构图中高效采样并获取相应特征所需的操作。GraphBolt 为异构图引入了一种新的、更紧凑的图形结构表示法,称为融合压缩稀疏列 (FcSC)。这可以将存储异构图的内存成本降低多达 56%,允许用户在内存中拟合更大的图形,并有可能使用更小、更具成本效益的实例进行 GNN 模型训练。
GraphStorm v0.4 与 GraphBolt 无缝集成,允许用户在其 GNN 工作流程中利用其性能改进。用户在启动图形构建和训练作业--use-graphbolt true时只需要提供额外的参数即可。
解决方案概述
常见的模型开发过程是对完整数据的子集进行本地模型探索,当你对结果满意时,训练全尺度模型。这种设置允许在对完整数据集进行训练之前进行更便宜的探索。GraphStorm 和 SageMaker Pipelines 允许您通过创建可在本地运行的模型管道来检索模型指标来实现这一点,准备就绪后,在 SageMaker 上的完整数据上运行管道,生成模型、预测和图形嵌入以用于下游任务。在下一节中,我们将介绍如何为 GraphStorm 设置此类管道。
我们在下图中演示了这样的设置,用户可以在单个 EC2 实例上进行模型开发和初始训练,当他们准备好使用完整数据进行训练时,将繁重的工作交给 SageMaker 进行分布式训练。使用 SageMaker Pipelines 训练模型具有多种好处,例如降低成本、可审计性和沿袭跟踪。
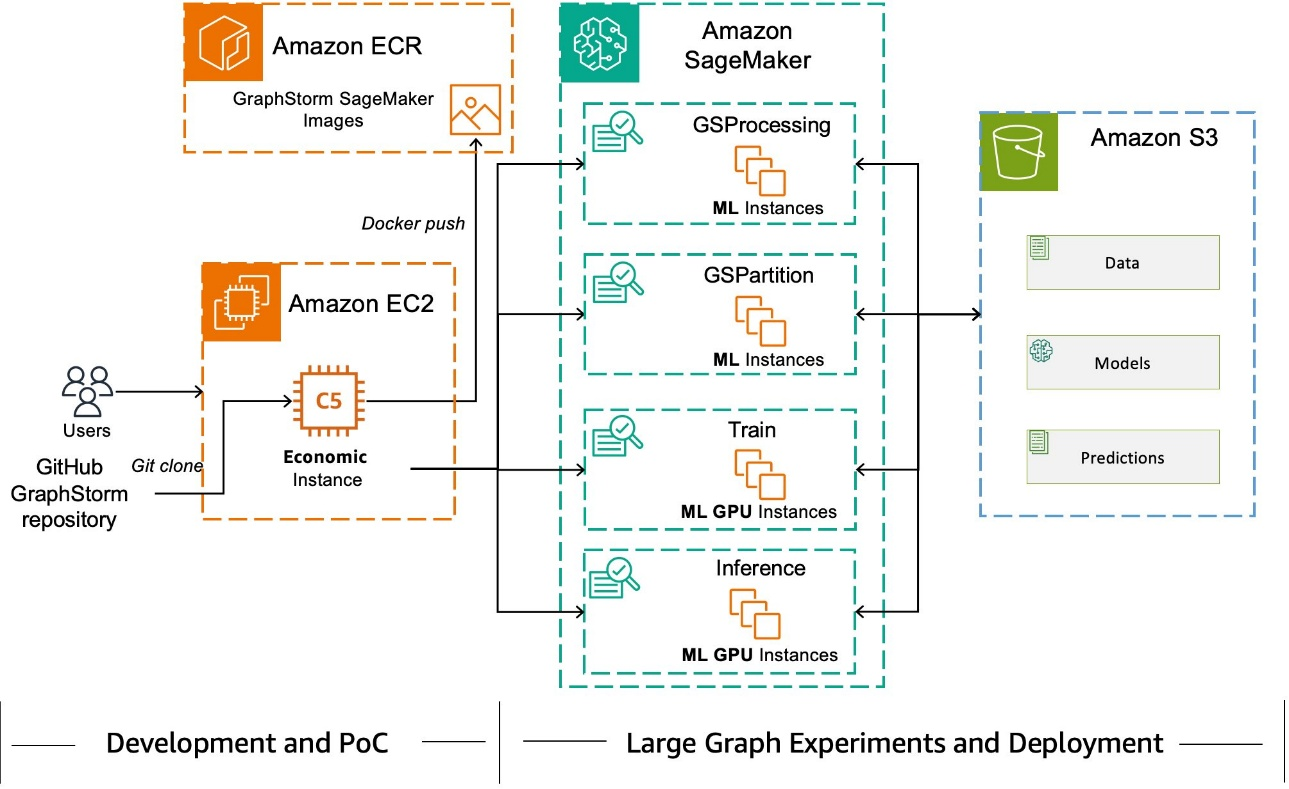
先决条件
要运行此示例,您将需要一个亚马逊云科技账户、一个亚马逊 SageMaker Studio 域以及运行 BYOC SageMaker 任务所需的权限。
为 SageMaker 分布式训练设置环境
您将使用 GraphStorm 存储库中提供的示例代码来运行此示例。
设置环境大约需要 10 分钟。首先,设置你的 Python 环境来运行示例:
conda init
eval $SHELL
# Create a new env for the post
conda create --name gsf python=3.10
conda activate gsf
# Install dependencies for local scripts
pip install torch==2.3.0 --index-url https://download.pytorch.org/whl/cpu
pip install sagemaker boto3 ogb pyarrow
# Verify installation, might take a few minutes for first run
python -c "import sagemaker; import torch"
# Clone the GraphStorm repository to access the example code
git clone https://github.com/awslabs/graphstorm.git ~/graphstorm
构建 GraphStorm SageMaker CPU 镜像
接下来,构建并推送 GraphStorm PyTorch Docker 镜像,用于运行小规模数据的图形构建、训练和推理作业。你的角色需要能够从亚马逊 ECR 公共库中提取镜像,创建亚马逊弹性容器注册表(亚马逊 ECR)存储库并将图像推送到你的私有 ECR 注册表。
# Enter you account ID here
ACCOUNT_ID=<aws-account-id>
REGION=us-east-1
cd ~/graphstorm
bash docker/build_graphstorm_image.sh --environment sagemaker --device cpu
bash docker/push_graphstorm_image.sh -e sagemaker -r $REGION -a $ACCOUNT_ID -d cpu
# This will create an ECR repository and push an image to
# ${ACCOUNT_ID}.dkr.ecr.us-east-1.amazonaws.com/graphstorm:sagemaker-cpu
下载和准备数据集
在这篇文章中,我们使用两个引文数据集来演示 GraphStorm 的可扩展性。开放图形基准 (OGB) 项目托管了许多图表数据集,可用于对图形学习系统的性能进行基准测试。对于小规模演示,我们使用ogbn-arxiv数据集,为了演示GraphStorm的大规模学习能力,我们使用了OGBN-Papers100M数据集。
准备 ogbn-arxiv 数据集
下载规模较小的 ogbn-arxiv 数据集进行本地测试,然后再在亚马逊云科技上启动更大规模的 SageMaker 任务。该数据集有大约 170,000 个节点和 120 万条边。使用以下代码下载数据并为 GraphStorm 做好准备:
# Provide the S3 bucket to use for output
BUCKET_NAME=<your-s3-bucket>
您可以使用以下脚本直接下载、转换数据并将其上传到亚马逊简单存储服务 (Amazon S3):
cd ~/graphstorm/examples/sagemaker-pipelines-graphbolt
python convert_arxiv_to_gconstruct.py \
--output-s3-prefix s3://$BUCKET_NAME/ogb-arxiv-input
这将在 Amazon S3 中创建表格图表数据,您可以通过运行以下代码进行验证:
aws s3 ls s3://$BUCKET_NAME/ogb-arxiv-input/
edges/
nodes/
splits/
gconstruct_config_arxiv.json
最后,上传 GraphStorm 训练配置文件以供 arxiv 用于训练和推理:
# Upload the training configurations to S3
aws s3 cp ~/graphstorm/training_scripts/gsgnn_np/arxiv_nc.yaml \
s3://$BUCKET_NAME/yaml/arxiv_nc_train.yaml
aws s3 cp ~/graphstorm/inference_scripts/np_infer/arxiv_nc.yaml \
s3://$BUCKET_NAME/yaml/arxiv_nc_inference.yaml
在 SageMaker 上准备 OGBN-Papers100m 数据集
Papers-100m 数据集是一个大规模的图形数据集,添加反向边后有 1.11 亿个节点和 32 亿条边。
要下载数据并将其作为亚马逊 SageMaker 处理步骤进行预处理,请使用以下代码。你可以启动任务,让任务在后台运行,同时继续完成帖子的其余部分,稍后再返回到这个数据集。该作业大约需要 45 分钟才能运行。
# Navigate to the example code
cd ~/graphstorm/examples/sagemaker-pipelines-graphbolt
# Build and push a Docker image to download and process the papers100M data
bash build_and_push_papers100M_image.sh -a $ACCOUNT_ID -r $REGION
# This creates an ECR repository and pushes an image to
# $ACCOUNT_ID.dkr.ecr.$REGION.amazonaws.com/papers100m-processor
# Run a SageMaker job to do the processing and upload the output to S3
SAGEMAKER_EXECUTION_ROLE_ARN=<your-sagemaker-execution-role-arn>
aws configure set region $REGION
python sagemaker_convert_papers100m.py \
--output-bucket $BUCKET_NAME \
--execution-role-arn $SAGEMAKER_EXECUTION_ROLE_ARN \
--region $REGION \
--instance-type ml.m5.4xlarge \
--image-uri $ACCOUNT_ID.dkr.ecr.$REGION.amazonaws.com/papers100m-processor
这将在中生成经过处理的数据s3://$BUCKET_NAME/ogb-papers100M-input,然后可以将其用作 GraphStorm 的输入。当此任务运行时,您可以创建 GraphStorm 管道。
创建 SageMaker 管道
运行以下命令创建 SageMaker 管道:
# Navigate to the example code
cd ~/graphstorm/examples/sagemaker-pipelines-graphbolt
PIPELINE_NAME="ogbn-arxiv-gs-pipeline"
bash deploy_arxiv_pipeline.sh \
--account $ACCOUNT_ID\
--bucket-name $BUCKET_NAME --execution-role $SAGEMAKER_EXECUTION_ROLE_ARN \
--pipeline-name $PIPELINE_NAME \
--use-graphbolt false
检查管道
运行前面的代码将创建一个 SageMaker 管道,该管道配置为按顺序运行三个 SageMaker 作业:
- 一项 GConstruct 任务,用于在 Amazon S3 上将表格文件输入转换为二进制分区图
- 一项 GraphStorm 训练任务,用于训练节点分类模型并将模型保存到 Amazon S3
- 一项 GraphStorm 推理作业,可为测试集中的所有节点生成预测,并为所有节点创建嵌入
要查看管道,请导航到 SageMaker AI Studio,选择您用于创建管道的域名和用户配置文件,然后选择 Open Studio。
在导航窗格中,选择 “管道”。应该有一个名为的管道ogbn-arxiv-gs-pipeline。选择管道,这将带您进入管道的 “执行” 选项卡。选择 Graph 查看工作流步骤。
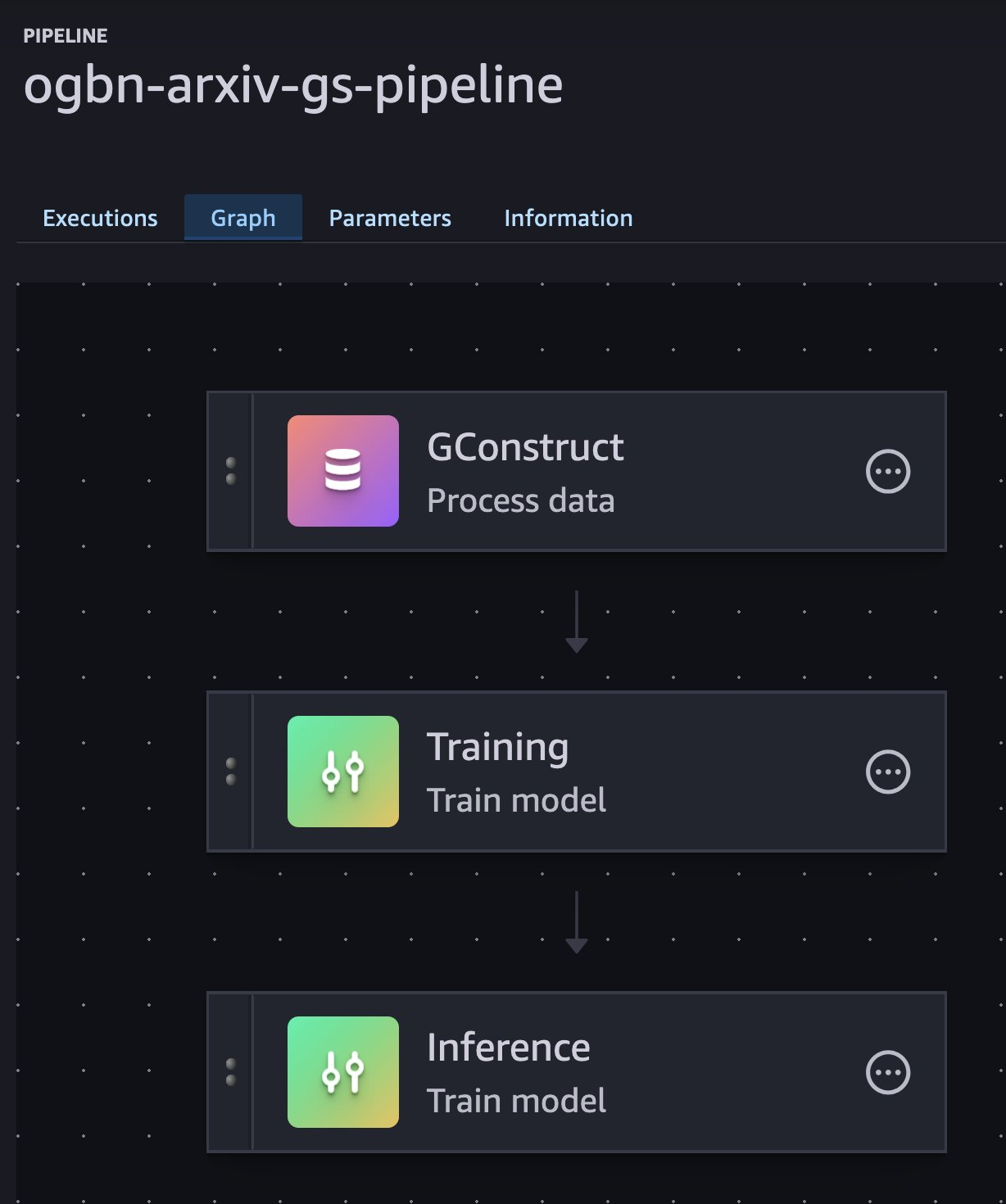
在 ogbn-arxiv 本地运行 SageMaker 管道
ogbn-arxiv 数据集足够小,你可以在本地运行管道。运行以下命令启动管道的本地执行:
# Allow the local containers to inherit亚马逊云科技credentials
export USE_SHORT_LIVED_CREDENTIALS=1
python ~/graphstorm/sagemaker/pipeline/execute_sm_pipeline.py \
--pipeline-name ogbn-arxiv-gs-pipeline \
--region us-east-1 \
--local-execution | tee arxiv-local-logs.txt
我们将日志输出保存到arxiv-local-logs.txt。稍后您将使用它来分析训练速度。
运行管道大约需要 5 分钟。管道完成后,它将打印一条如下所示的消息:
Pipeline execution 655b9357-xxx-xxx-xxx-4fc691fcce94 SUCCEEDED
您可以使用提供的analyze_training_time.py脚本和您创建的日志文件检查平均周期和评估时间:
python analyze_training_time.py --log-file arxiv-local-logs.txt
Reading logs from file: arxiv-local-logs.txt
=== Training Epochs Summary ===
Total epochs completed: 10
Average epoch time: 4.70 seconds
=== Evaluation Summary ===
Total evaluations: 11
Average evaluation time: 1.90 seconds
这些数字将根据您的实例类型而有所不同;在这种情况下,这些是在 m6in.4xlarge 实例上报告的值。
创建 GraphBolt 管道
现在,您已经建立了性能基准,您可以创建另一个使用 GraphBolt 图形表示法来比较性能的管道。
您可以使用相同的管道创建脚本,但更改两个变量,提供新的管道名称并设置--use-graphbolt为“true”:
# Deploy a GraphBolt-enabled pipeline
PIPELINE_NAME_GB="ogbn-arxiv-gs-graphbolt-pipeline"
bash deploy_arxiv_pipeline.sh \
--account $ACCOUNT_ID \
--bucket-name $BUCKET_NAME --execution-role $SAGEMAKER_EXECUTION_ROLE_ARN \
--pipeline-name $PIPELINE_NAME_GB \
--use-graphbolt true
# Execute the pipeline locally
python ~/graphstorm/sagemaker/pipeline/execute_sm_pipeline.py \
--pipeline-name $PIPELINE_NAME_GB \
--region us-east-1 \
--local-execution | tee arxiv-local-gb-logs.txt
分析训练日志,你可以看到每个纪元的时间有所缩短:
python analyze_training_time.py --log-file arxiv-local-gb-logs.txt
Reading logs from file: arxiv-local-gb-logs.txt
=== Training Epochs Summary ===
Total epochs completed: 10
Average epoch time: 4.21 seconds
=== Evaluation Summary ===
Total evaluations: 11
Average evaluation time: 1.63 seconds
对于如此小的图表,性能提升不大,每个纪元时间约为 13%。有了大数据,潜在的收益要大得多。在下一节中,您将为 Papers-100M 创建管道并训练模型,这是一个包含 1.11 亿个节点和 32 亿条边的引文图。
为分布式训练创建 SageMaker 管道
在准备 Papers-100m 数据的 SageMaker 处理任务完成处理并将数据存储在 Amazon S3 中之后,您可以设置一个管道来在该数据集上训练模型。
构建 GraphStorm GPU 镜
在这项工作中,您将使用大型 GPU 实例,因此这次您将构建和推送 GPU 映像:
cd ~/graphstorm
bash ./docker/build_graphstorm_image.sh --environment sagemaker --device gpu
bash docker/push_graphstorm_image.sh -e sagemaker -r $REGION -a $ACCOUNT_ID -d gpu
为 Papers-100M 部署和运行管道
在部署新管道之前,将 Papers-100M 的训练 YAML 配置上传到 Amazon S3:
aws s3 cp \
~/graphstorm/training_scripts/gsgnn_np/papers100M_nc.yaml \
s3://$BUCKET_NAME/yaml/
现在,您可以为 Papers-100m 部署初始管道了:
# Navigate to the example code
cd ~/graphstorm/examples/sagemaker-pipelines-graphbolt
PIPELINE_NAME="ogb-papers100M-pipeline"
bash deploy_papers100M_pipeline.sh \
--account $ACCOUNT_ID \
--bucket-name $BUCKET_NAME --execution-role $SAGEMAKER_EXECUTION_ROLE_ARN \
--pipeline-name $PIPELINE_NAME \
--use-graphbolt false
在 SageMaker 上运行管道,让它在后台运行:
# Navigate to the example code
cd ~/graphstorm/examples/sagemaker-pipelines-graphbolt
PIPELINE_NAME="ogb-papers100M-pipeline"
bash deploy_papers100M_pipeline.sh \
--account $ACCOUNT_ID \
--bucket-name $BUCKET_NAME --execution-role $SAGEMAKER_EXECUTION_ROLE_ARN \
--pipeline-name $PIPELINE_NAME \
--use-graphbolt false
您的账户需要满足所请求实例的所需配额。在这篇文章中,训练作业的默认值设置ml.g5.48xlarge为四个,处理作业的默认值设置为一个ml.r5.24xlarge实例。要调整您的 SageMaker 服务配额,您可以使用服务配额控制台。要并行运行两条管道,即不使用 GraphBolt 和使用 GraphBolt,则需要 8 x $TRAIN_GPU_INSTANCE 和 2 x $GCONSTRUCT_INSTANCE.
接下来,您可以在启用 GraphBolt 的情况下部署和运行另一个管道:
# Deploy the GraphBolt-enabled pipeline
PIPELINE_NAME_GB="ogb-papers100M-graphbolt-pipeline"
bash deploy_papers100M_pipeline.sh \
--account $ACCOUNT_ID\
--bucket-name $BUCKET_NAME --execution-role $SAGEMAKER_EXECUTION_ROLE_ARN \
--pipeline-name $PIPELINE_NAME_GB \
--use-graphbolt true
# Execute the GraphBolt pipeline on SageMaker
python ~/graphstorm/sagemaker/pipeline/execute_sm_pipeline.py \
--pipeline-name $PIPELINE_NAME_GB \
--region us-east-1 \
--async-execution
比较支持 Graphbolt 的训练的性能
两个管道都完成后(大约需要 4 个小时),您可以比较两种情况的训练时间。
在 SageMaker 控制台的管道页面上,应该有两个名为ogb-papers100M-pipeline和的新管道。ogb-papers100M-graphbolt-pipeline选择 OGB-Papers100M-Pipeline,这将带你进入管道的 “执行” 选项卡。复制最近一次成功执行的名称,并使用该名称来运行训练分析脚本:
python analyze_training_time.py \
--pipeline-name $PIPELINE_NAME\
--execution-name execution-1734404366941
您的输出将如下所示的代码:
== Training Epochs Summary ===
Total epochs completed: 15
Average epoch time: 73.95 seconds
=== Evaluation Summary ===
Total evaluations: 15
Average evaluation time: 15.07 seconds
现在对支持 Graphbolt 的管道执行同样的操作:
python analyze_training_time.py \
--pipeline-name $PIPELINE_NAME_GB \
--execution-name execution-1734463209078
您将看到每个纪元和评估时间的缩短:
== Training Epochs Summary ===
Total epochs completed: 15
Average epoch time: 54.54 seconds
=== Evaluation Summary ===
Total evaluations: 15
Average evaluation time: 4.13 seconds
在不损失准确性的情况下,最新版本的GraphStorm每周期的训练加速速度提高了约1.4倍,评估时间的加速速度提高了3.6倍!根据数据集的不同,加速可能更大,如DGL团队的基准测试所示。
结论
这篇文章展示了与DGL-GraphBolt集成的GraphStorm 0.4如何显著加快大规模的GNN训练和推理,在Papers-100m数据集上测得的速度分别提高了1.4和3.6倍。如 DGL 基准测试所示,根据数据集的不同,甚至可以实现更大的加速。
我们鼓励使用大型图形数据的机器学习从业者试用 GraphStorm。其低代码接口简化了在亚马逊云科技上构建、训练和部署图形机器学习解决方案,使您可以专注于建模而不是基础设施。
要开始使用,请访问 GraphStorm 文档和 GraphStorm GitHub 存储库。
作者简介
 西奥多·瓦西洛迪斯是亚马逊网络服务的高级应用科学家,他在那里研究分布式机器学习系统和算法。他领导了GraphStorm的分布式图形处理库GraphStorm处理的开发,并且是GraphStorm的核心开发人员。他于 2019 年获得斯德哥尔摩皇家理工学院计算机科学博士学位。
西奥多·瓦西洛迪斯是亚马逊网络服务的高级应用科学家,他在那里研究分布式机器学习系统和算法。他领导了GraphStorm的分布式图形处理库GraphStorm处理的开发,并且是GraphStorm的核心开发人员。他于 2019 年获得斯德哥尔摩皇家理工学院计算机科学博士学位。
 宋翔是亚马逊网络服务的高级应用科学家,他在那里开发了包括GraphStorm、DGL和DGL-KE在内的深度学习框架。他领导了亚马逊海王星机器学习的开发,这是海王星的一项新功能,它使用图形神经网络来处理存储在海王星图形数据库中的图形。他现在正在领导 GraphStorm 的开发,这是一款适用于企业用例的开源图形机器学习框架。他于 2014 年在上海复旦大学获得计算机系统与建筑博士学位。
宋翔是亚马逊网络服务的高级应用科学家,他在那里开发了包括GraphStorm、DGL和DGL-KE在内的深度学习框架。他领导了亚马逊海王星机器学习的开发,这是海王星的一项新功能,它使用图形神经网络来处理存储在海王星图形数据库中的图形。他现在正在领导 GraphStorm 的开发,这是一款适用于企业用例的开源图形机器学习框架。他于 2014 年在上海复旦大学获得计算机系统与建筑博士学位。
 Florian Saupe 是亚马逊云科技AI/ML 研究的首席技术产品经理,为图形机器学习小组等科学团队以及从事大规模分布式训练、推理和故障恢复的机器学习系统团队提供支持。在加入亚马逊云科技之前,Florian 曾在博世领导自动驾驶技术产品管理,曾在麦肯锡公司担任战略顾问,并曾担任控制系统和机器人科学家,他拥有该领域的博士学位。
Florian Saupe 是亚马逊云科技AI/ML 研究的首席技术产品经理,为图形机器学习小组等科学团队以及从事大规模分布式训练、推理和故障恢复的机器学习系统团队提供支持。在加入亚马逊云科技之前,Florian 曾在博世领导自动驾驶技术产品管理,曾在麦肯锡公司担任战略顾问,并曾担任控制系统和机器人科学家,他拥有该领域的博士学位。