我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
扩展 Java 应用程序以直接访问 Amazon S3 中的文件,无需重新编译
多年来,Java 编程语言一直是软件开发中最常用的语言之一,如今存在大量的 Java 应用程序。几乎所有应用程序都以某种方式与文件进行交互,但其中大多数都是为了与基于块存储的文件系统进行交互而编写的,无法直接读取或写入位于对象存储中的文件。鉴于
在 2011 年发布的 Java 7 中,引入了
在 SPI 的基础上,我开发了
在这篇文章中,我介绍了 aws-nio-spi-for-s3 包的好处、设计决策和实现,以及如何在不修改代码或重新编译应用程序的情况下将其用于基于 java 的应用程序。通过允许 Java 应用程序和 Amazon S3 之间的直接交互,可以更轻松地实现将文件移至 Amazon S3 的成本、规模、性能和持久性优势。
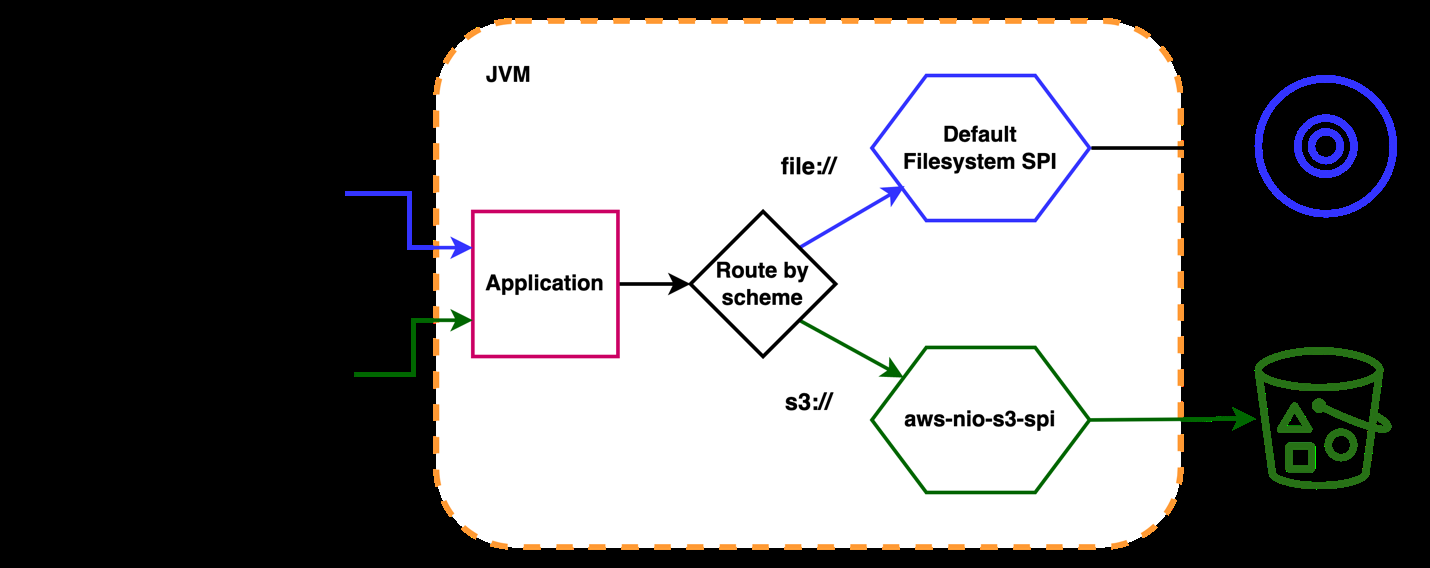
它是如何工作的
SPI 实现在 JVM 中注册为来自 “s
3
” 架构的 URI 的提供者。例如,如果应用程序输入为
s3://some-bucket/input/file
,则 JVM 会透明地将 I/O 操作委托给该库。
来自 S3 对象的字节可以使用
s3seekableBytechannel 读取,它是 java.nio.Channel.seekableBytechannel
的实现。
S3SeekableBytechannel 使用内存中的 ByteB
uffers 预读缓存,并针对通常按顺序读取字节
的场景进行了优化。
还支持写入亚马逊 S3。但是,所有写入操作都收集在一个临时文件中,该文件会在关闭 I/O 通道时上传到 Amazon S3。
设计决策和实施
由于 Amazon S3 是对象存储而不是文件系统,因此我面临着许多重要的设计决策,这些决策涉及如何将关键 Java 文件系统接口映射到 Amazon S3 概念。
例如,S3 存储桶表示为由 Software.amazon.nio.spi.s3.s3FileSystem 类实现的
一种选择是将所有 Amazon S3 表示为单个
java.nio.spi.file
System。
文件系统
,存储桶是顶级文件夹。尽管 S3 存储桶名称是全球唯一的,并且命名空间由所有 亚马逊云科技 账户共享,但它们归个人账户所有,拥有自己的权限、区域和潜在的终端节点。所有这些都会增加复杂性。因此,S3 存储桶似乎是最接近
文件系统
接口的模拟。
另一个重要的设计决策是如何表示文件和目录。文件(Java NIO.2 中的
路径
)是 S3 对象的相对直接类似物。但是目录更为复杂。Amazon S3 没有目录,只有存储桶和密钥。例如,在
s3://mybucket/path/to/file/object
中,存储桶名称是
mybucket,密钥将是 /pat
h/to/file
/
object。按照惯例,在键 中使用
/
被视为路径分隔符。因此, 即使该目录不存在, 也可以将
对象
推断为名为
/path/to/file/
的目录中的文件。aws-nio-spi-for-s3 软件包在我所谓的 “类似 POSIX” 路径表示形式下推断目录。这些逻辑是在项目的 p
osixLik
ePathPathPresention对象中编码的。我称之为 “类似 POSIX”,因为不可能有完美的表现形式。
例如,如果 Amazon S3 路径以
或者
/
、/结尾,则该路径被推断为目录。
/..
或仅包含
。
或者
。。
。
因此,这些路径被推断为目录
,
/dir/、/dir/
。
/dir/。。
。但是, 不能将 d
i
推断为目录。这是因为 Amazon S3 不包含可用于进行此推断的元数据,两者都可能是一个文件。这与真正的 POSIX 文件系统不同,在真正的 POSIX 文件系统中,如果
r
和 /dir
/dir/
是一个目录,则
/dir
和 相对于
/
的 d
ir
也必须是一个目录。
还做出了其他几项决定,例如处理隐藏文件、符号链接和时间戳。完整描述位于该项目的
用例示例:基因组学数据
存储在 Amazon S3 中的大文件是基因组学研究和开发的标准。有一些流行的Java应用程序专门用于分析这些数据,例如
作为 “直接进入” 提供商的 aws-nio-spi-for-s3 软件包
使用该包的最简单方法是将包的 JAR 文件包含在 Java 应用程序的类路径中。举一个具体的例子,通过使用流行的基因组学应用程序 G
java -classpath nio-spi-for-s3-1.2.1-all.jar:gatk-package-4.2.2.0-local.jar \ org.broadinstitute.hellbender.Main \ CountReads -I s3://EXAMPLE_BUCKET/example-genome.hg38.bam
由于提供的输入参数 (
-
I ) 是亚马逊 S3 URI,并且提供商 jar 位于 JVM 的类路径中(
nio-spi-for-s3-1.2.1-all.jar ),因此 GATK 读取来自亚马逊 S3
的输入,就好像从本地文件系统读取输入一样。任何利用 Java NIO.2 进行文件操作的 Java 应用程序都可以使用相同的方法。应用程序的
安全
好处
aws-nio-spi-for-s3 软件包适用于任何使用 Java NIO.2 库的应用程序,自 2011 年 7 月以来,这些库一直是推荐的默认库。当在类路径中找到该包时,JVM 会自动使用它。无需修改或重新编译应用程序。
以前作为本地文件路径或 file
://
URI 提供给应用程序的输入和输出现在可以作为
s3://
URI 提供。此外,aws-nio-spi-for-s3 软件包会自动处理对这些 URI 的文件操作。本地文件和 S3 对象可以同时在同一个应用程序中使用,因此可以将潜在的应用程序输入逐步迁移到 Amazon S3。
当应用程序使用 aws-nio-spi-for-s3 包在 JVM 中运行时,可以在读取第一个字节后立即开始计算。无需等待文件复制到磁盘,从而避免了可能较长的复制时间。与其他解决方案不同,无需将 S3 对象本地化到本地或挂载存储,这样就省去了额外基础设施的成本,也无需开发解决方案来同步本地和 Amazon S3 文件。
通过避免使用专门的 FUSE 挂载软件,我们无需进行额外的配置、创建挂载点和后台守护程序进程,这些进程通常需要根权限才能部署和运行。
今天就开始吧
在这篇文章中,我讨论了 nio-spi-for-s3 软件包,它提供了一种非常轻量级的解决方案,当你想要让现有 Java 应用程序读取或写入 Amazon S3 时,无需预置额外的基础设施或驱动程序,也无需将文件编组到本地存储。使用该软件包,您可以轻松地从 Amazon S3 的功能中受益,而无需修改现有应用程序。
你可以
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。