我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 Amazon Athena 和联合视图扩展您的数据网格
在 Athena 中,我们将对非 Amazon S3 数据源的查询称为 联合 查询。 这些查询在基础数据库上运行,这意味着您无需学习新的查询语言即可分析数据,也无需单独使用提取、转换和加载 (ETL) 脚本来提取、复制和准备数据以供分析。
最近,Athena 增加了对
在这篇文章中,我们展示了如何在以数据生产者和消费者为特色的数据网格架构中创建和查询联合数据源的视图。
数据网格 一词 是指具有分散数据所有权的数据架构。数据网格使以领域为导向的团队提供了所需的数据,强调自助服务,并促进了专用数据产品的概念。在数据网格中,数据 生产者 向组织 公开数据集, 数据 使用者 订阅和使用生产者创建的数据产品。通过将数据所有权分配给跨职能团队,数据网格可以培养围绕数据的协作、发明和敏捷性文化。
让我们深入研究解决方案。
解决方案概述
在这篇文章中,想象一家假设的电子商务公司使用多个数据源,每个数据源扮演着不同的角色:
-
在 S3 数据湖中,电子商务记录存储在名为
Lineitems 的表中 -
适用于 Redis 的亚马逊 ElastiCache 存储国家和活动订单 数据,确保下游电子商务系统超快地读取运营数据 -
在
亚马逊关系数据库服务 (Amazon RDS) 上,MySQL 用于在订单、客户和供应商表中存储电子邮件地址和送货地址等数据 -
为了实现灵活和低延迟的读取和写入,Amazon DynamoDB 表包含零件和零件补充数据
我们想在数据网格设计中查询这些数据源。在以下部分中,我们将为 MySQL、DynamoDB 和 Redis 设置 Athena 数据源连接器,然后运行在这些数据源之间执行复杂联接的查询。下图描述了我们的数据架构。
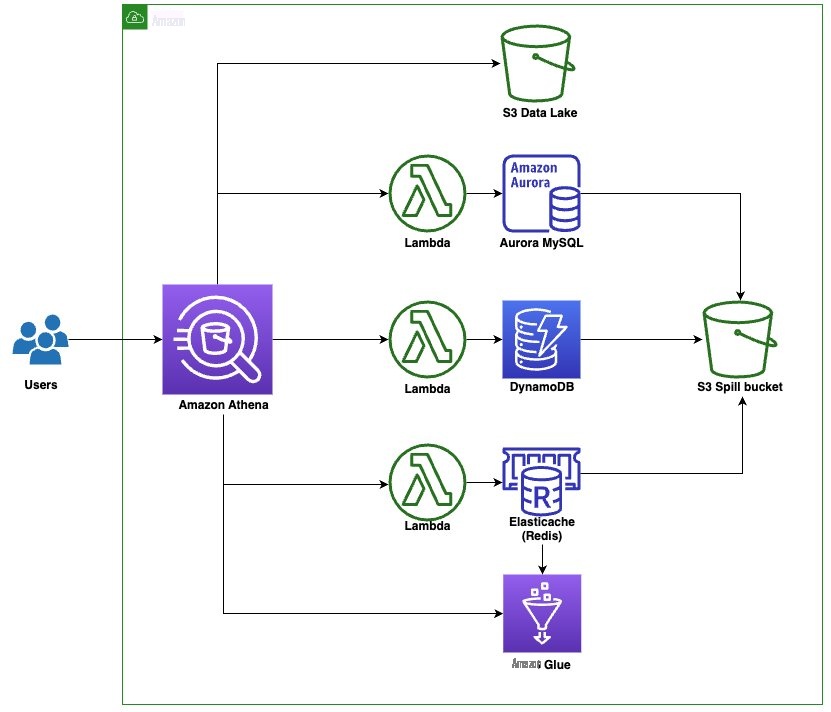
在继续使用此解决方案时,请注意,您将在您的账户中创建 亚马逊云科技 资源。我们已经为您提供了一个定义和配置所需资源
该模板旨在演示如何在 Athena 中使用联合视图,未经修改不得用于生产用途。此外,该模板使用 us-east-1 区域,未经修改将无法在其他地区使用。该模板创建的资源在使用时会产生成本。按照本文末尾的清理步骤删除资源并避免不必要的费用。
先决条件
在启动 CloudFormation 堆栈之前,请确保满足以下先决条件:
- 提供对 亚马逊云科技 服务访问权限的 亚马逊云科技 账户
-
一个 IAM 用户,拥有用于配置 A
WS 命令行接口 (亚马逊云科技 CLI) 的访问密钥和密钥,以及在 亚马逊云科技 CloudFormation 中创建 IAM 角色、IAM 策略和堆栈的权限
使用 亚马逊云科技 CloudFormation 创建资源
要开始使用,请完成以下步骤:
-
选择
启动堆栈
:

- 选择 “ 我确认此模板可以创建 IAM 资源 ” 。
CloudFormation 堆栈大约需要 20—30 分钟才能完成。您可以在 亚马逊云科技 CloudFormation 控制台上监控其进度。当状态显示为
CREATE_COM
PLETE 时 ,您的 亚马逊云科技 账户将拥有实施此解决方案所需的资源。
部署连接器并连接到数据源
有了资源,我们就可以开始将数据网格中的点点连接起来。首先,让我们将 CloudFormation 堆栈创建的数据源与雅典娜连接起来。
- 在 Athena 控制台上, 在导航窗格中选择 数据源 。
- 选择 “ 创建数据源 ” 。
- 对于 数据源 ,选择 MySQL ,然后选择 下一步 。
-
在
数据源名称
中 ,输入一个名称,例如
mysql。适用于 MySQL 的雅典娜连接器是一个 亚马逊云科技 Lambda 函数,由 CloudFormation 模板为你创建。 - 有关 连接的详细信息 , 请选择或输入 Lambda 函数 。
-
选择
mysql,然后选择 “ 下一步 ” 。 - 查看信息并选择 创建数据源 。
-
返回
数据源
页面并选择
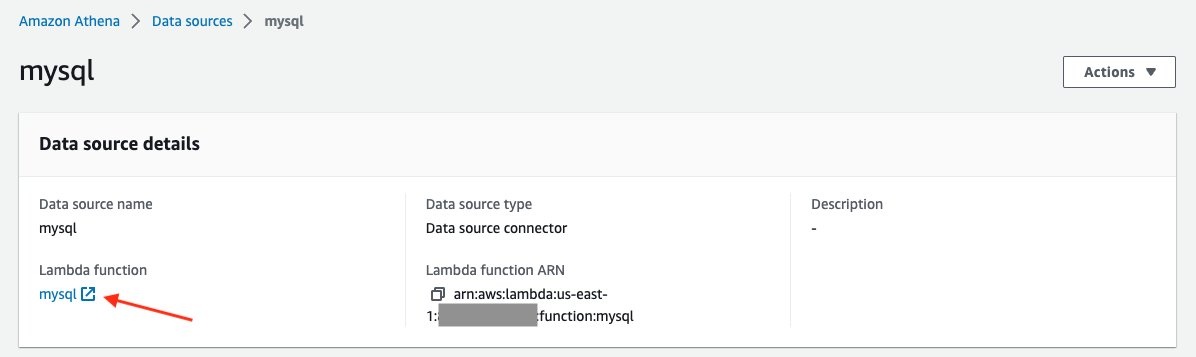
mysql。 -
在连接器详细信息页面上,选择
Lambda 函数
下的链接 以访问 Lambda 控制台并检查与此连接器关联的函数。
- 返回 Athena 查询编辑器。
-
对于
数据源
,选择
mysql。 -
对于
数据库
,选择
销售数据库。 - 对于 表 ,您应该看到可供您查询的 MySQL 表的列表。
- 重复这些步骤,为 DynamoDB 和 Redis 设置连接器。
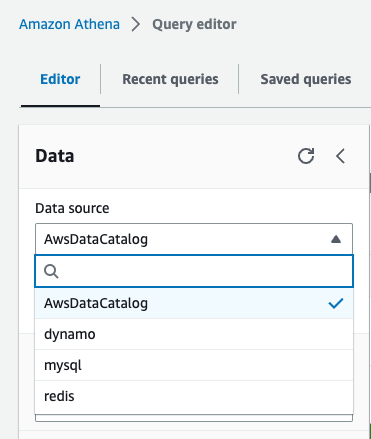
配置完所有四个数据源后,我们可以在数据源下 拉菜单中看到
数据源
。所有其他数据库和表,例如存储在 Amazon S3 上的行
项目 表,均在 AWS Gl
ue 数据目录中定义,可通过选择 亚马逊云科技Dat
aCatalog 作为数据源
进行访问。
使用 Athena 分析数据
配置好数据源后,我们就可以开始在数据网格架构中运行查询和使用联合视图了。首先,让我们尝试找出按供应商国家和年份细分的给定零件系列获得了多少利润。
对于这样的查询,我们需要针对每个国家和每年的计算每年订购的零件的利润,这些零件由每个国家的供应商填补。利润定义为描述指定行中零件的所有
订单项目的 [(l_extendedprice* (1-l_discountist))-(ps_supplycost * l_quantit
y)] 之和。
回答这个问题需要查询所有四个数据源(MySQL、DynamoDB、Redis 和亚马逊 S3),并且使用以下 SQL 即可完成:
在 Athena 控制台上运行此查询会生成以下结果。
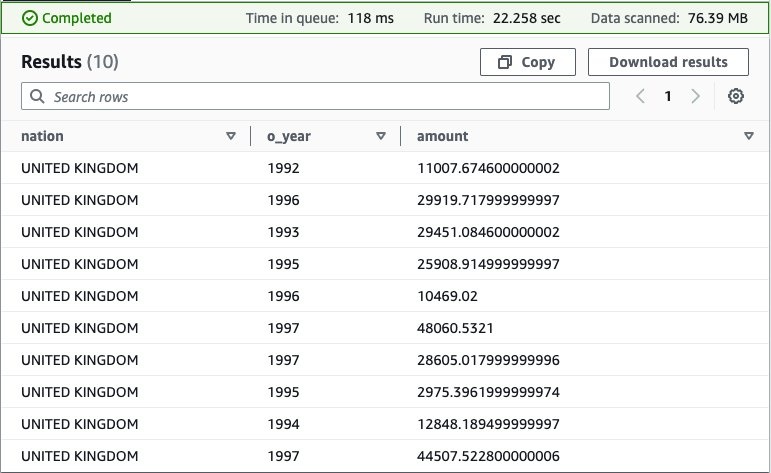
这个查询相当复杂:它涉及多个联接,需要对计算利润指标的正确方法有特殊的了解,而其他最终用户可能不具备这些指标。
为了简化这些用户的分析体验,我们可以将这种复杂性隐藏在视图后面。有关使用具有联合数据源的视图的更多信息,请参阅
使用以下查询在
data_lake 数据库的
alog 数据源下创建视图:
AWS
DataCat
接下来,运行一个简单的选择查询来验证视图是否已成功创建:
从 federated_view limit 10 中选择*
结果应该与我们之前的查询类似。
有了我们的视图,我们可以进行新的分析来回答由于需要复杂的查询语法而在没有视图的情况下会很困难的问题。例如,我们可以按国家找到总利润:
您的结果应与以下屏幕截图类似。
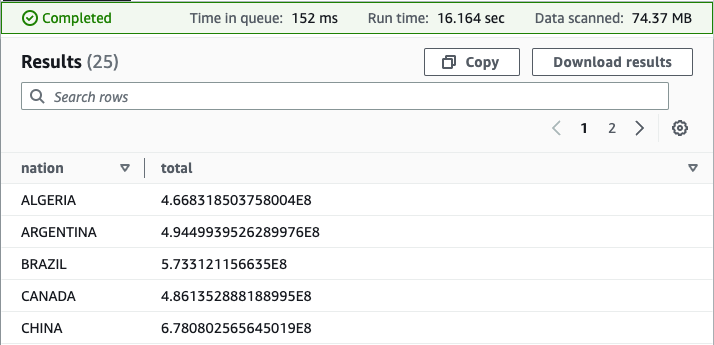
如你现在所见,联合视图使最终用户可以更轻松地对这些数据运行查询。用户可以自由查询由知识渊博的数据创建者定义的数据视图,而不必先获得每个基础数据源的专业知识。由于 Athena 联合查询是在存储数据的地方处理的,因此通过这种方法,我们可以避免从源系统中复制数据,从而节省宝贵的时间和成本。
在多用户模型中使用联合视图
到目前为止,我们已经满足了数据网格的原则之一:我们创建了一个数据产品(联合视图),该数据产品与其原始来源分离,可供消费者按需分析。
接下来,我们在多用户模型中使用联合视图,使我们的数据网格更进一步。为了简单起见,假设我们有一个生产者账户、我们用来创建四个数据源和联合视图的账户,以及一个消费者账户。使用生产者账户,我们向消费者账户授予从消费者账户查询联合视图的权限。
下图描述了这种设置和我们简化的数据网格架构。
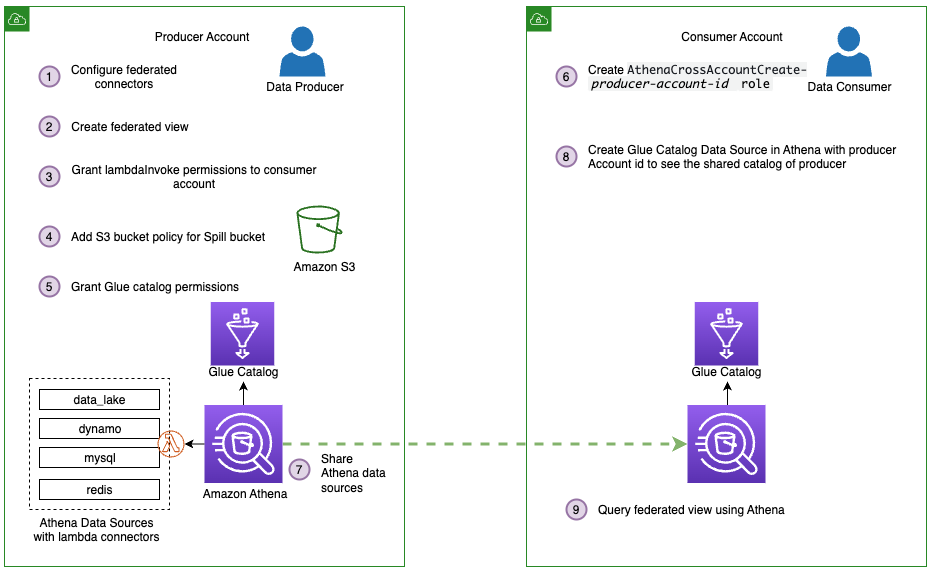
按照以下步骤将来自生产者的连接器和 亚马逊云科技 Glue 数据目录资源(包括我们的联合视图)与消费者账户共享:
-
与消费者账户共享数据源
mysql、redis、dynamo和data_lak e。有关说明,请参阅与账户B 共享账户 A 中的数据源 。请注意,账户 A 代表生产者,账户 B 代表消费者。共享数据时,请确保使用与之前相同的数据源名称。这是联合视图在跨账户模型中运行所必需的。 -
接下来,按照
跨账户访问 亚马逊云科技 Glue 数据目录中的步骤,与消费者账户共享生产者账户的 亚马逊云科技 Glue 数据目录 。对于数据源名称,请使用 shared_federated_catalog。 -
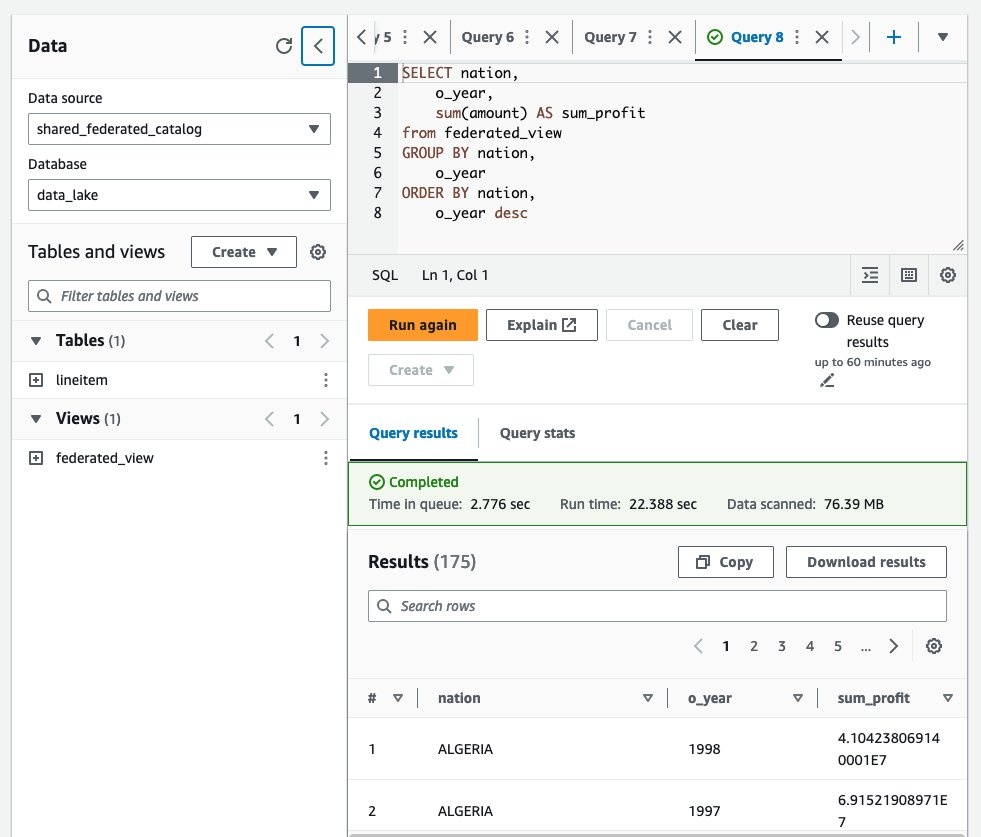
切换到消费者账户,导航到 Athena 控制台,确认在 shared_federatview。ed_catalog 数据目录和 data_lake 数据库的 “视图” 下方 列出了 federated_ - 接下来,在共享视图上运行示例查询以查看查询结果。
清理
要清理为这篇文章创建的资源,请完成以下步骤:
-
在 Amazon S3 控制台上,清空存储桶 athena-federation-workshop -
如果您使用的是 亚马逊云科技 CLI,请使用以下代码删除
athena-federation-workshop存储桶中的对象。确保在正确的存储桶上运行此命令。
aws s3 rm s3://athena-federation-workshop---递归 -
在 AWS CloudFormation 控制台或 AWS CLI 上,删除堆栈 athena-federated-view-blog。
摘要
在这篇文章中,我们演示了 Athena 联合视图的功能。我们创建了一个涵盖四个不同的联合数据源的视图,并对其进行了查询。我们还看到了如何将联合视图扩展到多用户数据网格并从消费者账户运行查询。
要利用联合视图,请确保您使用的是
作者简介

 Pathik Shah
是亚马逊 Athena 的高级大数据架构师。他于 2015 年加入 亚马逊云科技,此后一直专注于大数据分析领域,帮助客户使用 亚马逊云科技 分析服务构建可扩展且强大的解决方案。
Pathik Shah
是亚马逊 Athena 的高级大数据架构师。他于 2015 年加入 亚马逊云科技,此后一直专注于大数据分析领域,帮助客户使用 亚马逊云科技 分析服务构建可扩展且强大的解决方案。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。