我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
导出和可视化您的亚马逊云科技账户中的碳排放数据
2022 年 3 月,亚马逊云科技发布了客户碳足迹工具 (CCFT)。从那时起,客户使用亚马逊云科技管理控制台中提供的 CCFT 来了解与其云使用量相关的碳排放估算值。2025 年 4 月,亚马逊云科技在亚马逊云科技数据导出中添加了碳排放数据。此托管功能引入了按月自动将具有亚马逊云科技账户和亚马逊云科技区域粒度的碳排放数据导出到 Amazon S3 的功能。使用 Amazon Organizations 时,碳排放导出会提供与您的管理账户关联的所有成员账户的数据。
这篇文章解释了如何配置向 Amazon S3 的定期交付碳排放数据,以及如何在云智能控制面板 (CID) 的可持续发展代理指标控制面板中对导出的数据进行可视化。利用数据导出和 CID,您可以跟踪多个亚马逊云科技组织的排放,并能够构建自定义可视化效果并深入了解成员账户级别的粒度。
此前,一些客户使用作为实验性编程访问权限发布的示例代码提取了 CCFT 的信息,以编程方式收集整个亚马逊云科技组织的排放数据。如果您之前使用过"实验性编程访问",这篇文章还解释了如何在保留数据的同时删除应用程序并切换到亚马逊云科技数据导出。
将数据导出与分析和 BI 服务集成
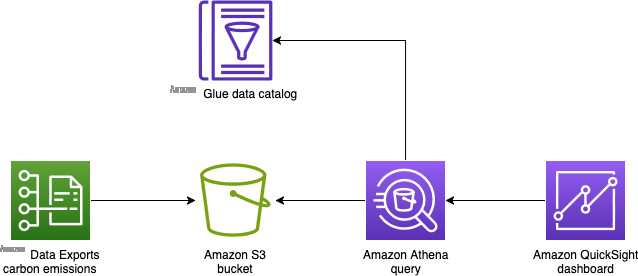
图 1:碳排放数据导出与分析和 BI 服务集成的架构图
亚马逊云科技数据导出会定期将碳排放数据导出到 Amazon S3。常见的架构是 Amazon Glue 数据目录将数据位置和结构的表元数据存储在 Amazon S3 中。Amazon Athena 是一项无需将数据加载到数据库即可对表运行标准 SQL 查询的服务。Amazon QuickSight 允许您使用来自各种数据集的数据来构建仪表板,包括 Athena 运行的 SQL 查询。
通过数据导出配置和查询碳排放数据
让我们来看看配置碳排放导出的两个选项:
- 选项 1:在亚马逊云科技控制台中手动创建所有资源,全部在一个亚马逊云科技账户中。选择此选项可逐步了解概念。
- 选项 2:使用 Amazon CloudFormation 模板以基础设施即代码 (IaC) 方式创建所有资源。如果您想收集一个或多个 Amazon Organizations 的碳排放数据、在单独的账户中处理碳排放数据或部署可持续发展代理指标控制面板,请选择此选项。
之后,无论您选择了哪个选项,您都可以使用 Athena 查询碳排放数据。
先决条件
要配置碳排放数据导出,请确保满足以下先决条件:
- 您的亚马逊云科技账户中必须有一个 Amazon S3 存储桶才能接收和存储您的数据导出。了解如何为数据导出设置 Amazon S3 存储桶。
- 要使用数据导出,需要向 Amazon Identity and Access Management (IAM) 用户授予在 IAM
bcm-data-exports namespace中访问操作的权限。了解有关数据导出的身份和访问管理的更多信息。 - 要访问数据导出碳排放表中的数据,您需要 IAM 权限
sustainability:GetCarbonFootprintSummary。
选项 1:手动创建碳排放数据导出和表格
1. 在亚马逊云科技控制台中为碳排放创建亚马逊云科技数据导出(详情请阅读有关创建数据导出的更多信息):
-
- 导航到账单和成本管理控制台中的亚马逊云科技数据导出功能
- 选择"创建"
- 输入导出名称,例如
carbon-emissions - 选择碳排放量作为数据表
- 选择您选择的 S3 存储桶名称和 S3 路径前缀
- 保留所有其他选项的默认值
- 选择"创建"
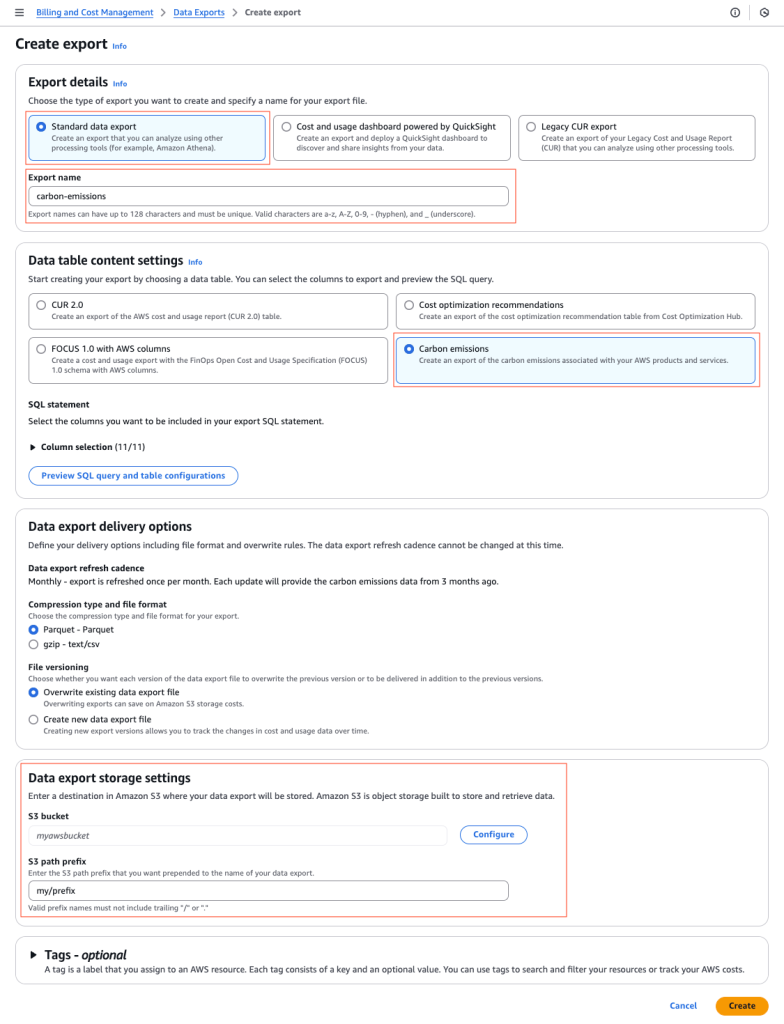
图 2:创建碳排放数据导出的屏幕截图
S3 存储桶名称、S3 路径前缀和导出名称是我们将在本文后面引用的数据导出路径的一部分。例如,最终的数据导出路径是 s3://<S3-bucket-name>/<s3-path-prefix>/<export-name>/data,如 s3://my-bucket/my/prefix/carbon-emissions/data。
您的碳排放数据(包括 38 个月的回填数据)最多可能需要 24 小时才能导出到 S3 存储桶。
2. 导出传输数据后,通过在 Amazon Athena 的查询编辑器中运行以下查询,在数据目录中创建表。选择 default 数据库,或为此表创建专用数据库。<database> 替换为 default 或您的专用数据库的名称,并 <Data export path> 替换为前面说明的数据导出路径。
CREATE EXTERNAL TABLE <database>.`carbon`(
`payer_account_id` string,
`usage_account_id` string,
`total_mbm_emissions_value` double,
`total_mbm_emissions_unit` string,
`model_version` string,
`product_code` string,
`usage_period_start` timestamp,
`usage_period_end` timestamp,
`last_refresh_timestamp` timestamp,
`region_code` string,
`location` string)
PARTITIONED BY (
`carbon_model_version` string,
`usage_period` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'<data export path>'3. 导出根据 Apache Hive 风格传送带有 S3 前缀的文件。每个前缀都包含其分区,这些分区编码为由等号连接的键值对:
<data export path>/carbon_model_version=xxx/usage_period=2025-02/<report-name>-00001.snappy.parquet
<data export path>/carbon_model_version=yyy/usage_period=2025-03/<report-name>-00001.snappy.parquet
当数据导出首次提供数据或每月数据刷新时,数据包含 usage_period 和 carbon_model_version 的值。必须将分区添加到 Glue 数据目录中。通过在 Athena 查询编辑器中运行以下查询,让 Athena 发现数据分区:
MSCK REPAIR TABLE <database>.`carbon`
现在,您可以通过 Athena 查询数据了。
选项 2:使用 IaC 创建碳排放数据导出和表格
让 Athena 可以访问数据的另一种方法是通过 Amazon CloudFormation 创建数据导出和表格。按照本研讨会中的说明进行操作。这些说明包括以编程方式创建碳排放数据导出、在单独账户中收集数据,以及创建 Amazon Glue 爬虫以定期发现新数据。
查询和下载数据
按照以下两个选项之一配置数据导出后,在 Amazon Athena 查询编辑器中使用以下查询测试数据检索:
SELECT * FROM <database>."carbon" LIMIT 10;
查询编辑器显示的结果与以下示例数据类似:

图 3:Amazon Athena 查询编辑器
您可以通过选择"下载结果 CSV"将结果下载为 CSV。
如果您没有看到任何结果,这可能是因为您的账户是最近创建的,或者没有任何碳排放数据可显示。阅读文档,详细了解您的碳排放估算。此外,请记住,您的碳排放数据和 38 个月的回填数据最多可能需要 24 小时才能导出到 S3 存储桶。
部署可视化新数据的仪表板
如果您遵循了选项 2,您现在可以设置可持续发展代理指标仪表板,以可视化碳排放数据。为此,请按照以下步骤操作:
- 按照云智能仪表板研讨会的第 3 步进行操作
- 在步骤 3.2 中,请保留"部署 CUDOS v5 仪表板"的默认值"是",因为这是可持续发展代理指标仪表板的要求
- 接下来,按照可持续发展代理指标部署指南中的说明,根据您配置的碳排放数据导出设置可视化效果
部署后,导航到您的仪表板和"碳排放"选项卡。下面的图 4 和 5 显示了仪表板的视觉效果,其中包含示例数据,使您能够:
- 发现所选亚马逊云科技账户的月度变化和趋势
- 深入了解您的主要贡献者
- 深入了解产品的碳排放分布
- 深入了解亚马逊云科技区域的碳排放分布
- 分析与亚马逊云科技区域和产品代码相关的碳排放流
- 发现多个亚马逊云科技组织的月度变化和趋势
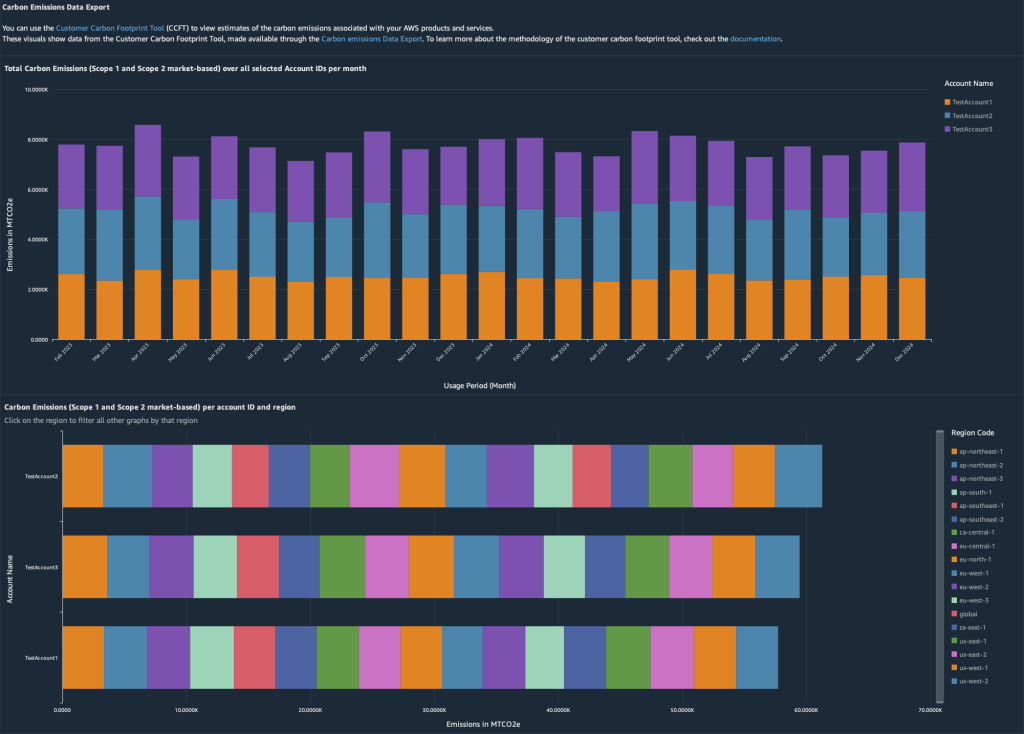
图 4:可持续发展代理指标仪表板"碳排放"选项卡的屏幕截图 (1/2)
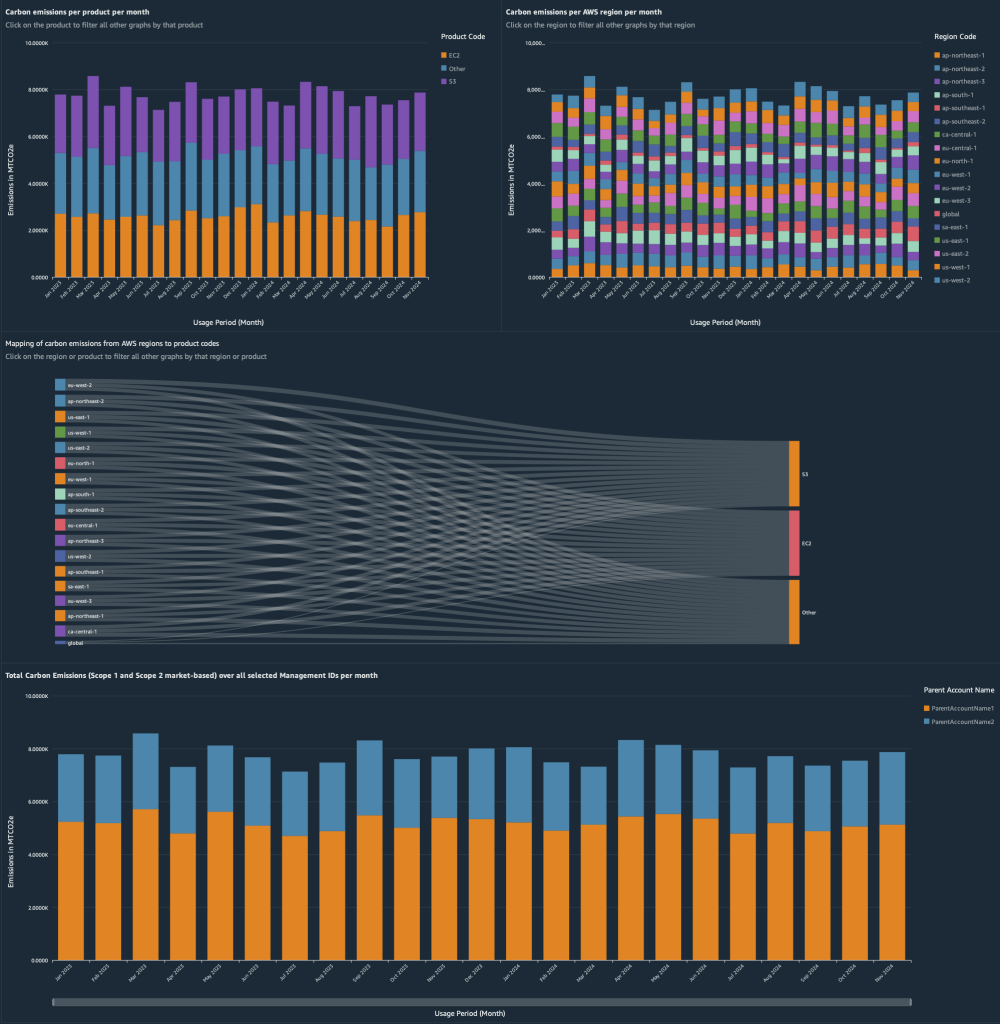
图 5:可持续发展代理指标仪表板"碳排放"选项卡的屏幕截图 (2/2)
删除实验访问资源,同时保留之前收集的数据
如果您之前使用过实验性编程访问权限,请删除该应用程序以停止产生任何费用。此示例代码使用的端点将于 2025 年 7 月 23 日停产,该示例将停止运行。我们建议改用数据导出。
通过以下任一方式删除堆栈:
• 使用亚马逊云科技 CLI:假设您使用 ccft-sam-script 堆栈名称,运行
aws cloudformation delete-stack —stack-name ccft-sam-script
• 使用 Amazon CloudFormation 控制台(有关分步说明,参见文档)
在堆栈删除期间,CloudFormation 将尝试删除空的 S3 存储桶。如果您的存储桶包含数据,除非您先清空存储桶,否则堆栈删除将失败。要保留您的历史数据,请将数据保留在存储桶中(这将防止堆栈删除),或者在继续删除之前备份数据。
当您删除堆栈时,Athena 数据库、表和视图将保留。如果您选择保留包含历史碳排放数据的 S3 存储桶,您仍然可以使用这些表格和视图进行分析。
在定期刷新数据时获得通知
您可以使用 Amazon S3 事件通知与 Amazon SNS 或 Amazon Lambda 相结合,为亚马逊云科技数据导出编写的新文件设置通知。如果您希望每次导出只收到一次通知,而不是每个单独的文件,请阅读 Amazon S3 文档中有关处理重复事件模式的更多信息。
按亚马逊云科技组织、区域和服务计算聚合数
如果您以 Amazon Organizations 的管理账户登录,则客户碳足迹工具控制面板会报告合并后的成员账户数据。如果您登录到会员账户,则客户碳足迹工具仅报告该账户的排放数据。
与 CCFT 主机体验不同,碳排放数据导出始终提供个人账户级别的排放数据,无论是付款人账户还是会员账户。如果您想按亚马逊云科技组织、区域或产品计算聚合,请从 Athena 查询编辑器中的以下查询开始:
SELECT
carbon_model_version,
model_version,
usage_period,
usage_period_start,
usage_period_end,
SUM(total_mbm_emissions_value) AS total_mbm_emissions_value,
total_mbm_emissions_unit,
payer_account_id,
product_code,
region_code,
location
FROM <database>.`carbon`
GROUP BY
carbon_model_version,
model_version,
usage_period,
usage_period_start,
usage_period_end,
total_mbm_emissions_unit,
payer_account_id,
product_code,
region_code,
location
如果您想按亚马逊云科技组织进行聚合,请从 SQL 语句的 SELECT 和 GROUP BY 部分中删除 product_code、region_code 和 location。同样,如果您想按亚马逊云科技区域进行聚合,请删除 payer_account_id 和 product_code。如果你想通过服务获得排放,只留下产品代码。
如果你想重用这个查询,你可以通过运行以下命令来创建一个视图,它是一个虚拟表,可以保存你的查询逻辑以供重复使用:
CREATE [ OR REPLACE ] VIEW <database>.<view_name> AS <select query above>
正在清理
如果您想删除创建的资源并遵循了选项 1,请手动删除以下资源:
- 您创建的数据导出
- 删除数据导出不会删除存储在 S3 存储桶中的任何对象。如果您不想保留它们,请手动删除 S3 对象和存储桶。
- 你创建的 Athena 表格
如果您创建了使用基础架构即代码的数据导出(选项 2),请按照下列 Teardown 说明进行操作。
结论
碳排放数据导出以 CSV 或 Parquet 格式向 Amazon S3 提供每月更新,从而简化了亚马逊云科技碳排放数据的收集和分析。这使您可以按照亚马逊云科技服务、账户和区域粒度自动处理整个亚马逊云科技组织的报告和仪表板的碳数据。
通过遵循本文中概述的设置步骤并利用云智能控制面板,您可以获得对亚马逊云科技碳排放估算值的宝贵见解,并做出明智的决策以优化您的云可持续发展工作。

Katja Philipp
卡佳·菲利普是亚马逊云科技的高级原型设计架构师。她与客户合作,使用人工智能、机器学习和生成式人工智能技术构建创新原型,以解决实际的业务挑战。Katja 热衷于可持续发展、无服务器以及如何利用技术来解决当前的挑战,创造更美好的未来。

Steffen Grunwald
斯特芬·格伦瓦尔德是亚马逊云科技的首席可持续发展解决方案架构师。他支持客户通过云解决他们的可持续发展挑战。他拥有长期的软件工程背景,喜欢深入研究应用程序架构和开发流程,以推动可持续性、性能、成本、运营效率并提高创新速度。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。