我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
Exafunction 支持 亚马逊云科技 Inferentia,为机器学习推理解锁最佳性价比
在所有行业中,机器学习 (ML) 模型越来越深,工作流程变得越来越复杂,工作负载的运行规模也越来越大。由于这项投资直接带来了更好的产品和体验,因此投入了大量精力和资源来提高这些模型的准确性。另一方面,使这些模型在生产中高效运行是一项艰巨的任务,尽管它们是实现性能和预算目标的关键,但却经常被忽视。在这篇文章中,我们将介绍 Exafunction 和
解决方案概述
ExaDePloy 如何解决部署效率问题
为了确保计算资源的有效利用,您需要考虑适当的资源分配、自动扩展、计算托管、网络成本和延迟管理、容错、版本控制和可重复性等。大规模而言,任何效率低下都会对成本和延迟产生重大影响,许多大公司已经通过建立内部团队和专业知识来解决这些效率低下的问题。但是,对于大多数公司来说,假设开发不是公司理想的核心竞争力的通用软件所产生的财务和组织开销是不切实际的。
ExaDeploy 旨在解决这些部署效率痛点,包括一些最复杂的工作负载(例如自动驾驶汽车和自然语言处理 (NLP) 应用程序中的工作负载)中出现的难题。在一些大型批量机器学习工作负载上,ExadePloy 在不牺牲延迟或准确性的前提下将成本降低了85%以上,集成时间仅为一个工程师日。事实证明,ExaDeploy 可以自动扩展和管理数千个同步硬件加速器资源实例,而不会降低系统性能。
exaDePloy 的主要功能包括:
- 在云端运行 :您的模型、输入或输出都不会离开您的私有网络。继续使用您的云提供商折扣。
- 共享加速器资源 :ExadePloy 通过支持多个模型或工作负载共享加速器资源来优化所使用的加速器。它还可以识别多个工作负载是否在部署同一个模型,然后在这些工作负载之间共享模型,从而优化所使用的加速器。其自动再平衡和节点耗尽功能可最大限度地提高利用率并最大限度地降低成本。

- 可扩展的无服务器部署模型 :ExadePloy 根据加速器资源饱和度自动扩展。动态缩减到 0 个或多达数千个资源。
- 支持各种计算类型 :您可以从所有主要 ML 框架以及任意 C++ 代码、CUDA 内核、自定义操作和 Python 函数中卸载深度学习模型。
- 动态模型注册和版本控制 :无需重建或重新部署系统即可注册和运行新模型或模型版本。
- 点对点执行 :客户端直接连接到远程加速器资源,从而实现低延迟和高吞吐量。他们甚至可以远程存储状态。
- 异步执行 :ExadePloy 支持异步执行模型,这允许客户端通过远程加速器资源工作并行处理本地计算。
- 容错远程管道 :ExadePloy 允许客户端动态地将远程计算(模型、预处理等)组合成具有容错保证的管道。ExaDeploy 系统通过自动恢复和重播来处理 Pod 或节点故障,因此开发人员无需考虑确保容错能力。
- 开箱即用的监控 :ExaDePloy 提供 Prometheus 指标和 Grafana 仪表板,用于可视化加速器资源使用情况和其他系统指标。
exaDePloy 支持 亚马逊云科技 推论
基于 亚马逊云科技 推理的 Amazon EC2 Inf1 实例专为深度学习特定的推理工作负载而设计。与当前一代 GPU 推理实例相比,这些实例可提供高达 2.3 倍的吞吐量和高达 70% 的成本节省。
ExaDeploy 现在支持 亚马逊云科技 Inferentia,它们共同解锁了通过专门构建的硬件加速和大规模优化资源协调而实现的性能提高和成本节约。让我们通过考虑一种非常常见的现代机器学习工作负载,来看看 ExaDeploy 和 亚马逊云科技 Inferentia 的综合优势:批处理的混合计算工作负载。
假设的工作负载特征:
- 15 毫秒仅限 CPU 的预处理/后处理
- 模型推断(在 GPU 上为 15 毫秒,在 亚马逊云科技 推理上为 5 毫秒)
- 10 个客户端,每个 20 毫秒发出一次请求
- CPU: Inferentia: GPU 的相对成本大约为 1:2:4(基于亚马逊 EC2 c5.xlarge、inf1.xlarge 和 g4dn.xlarge 的按需定价)
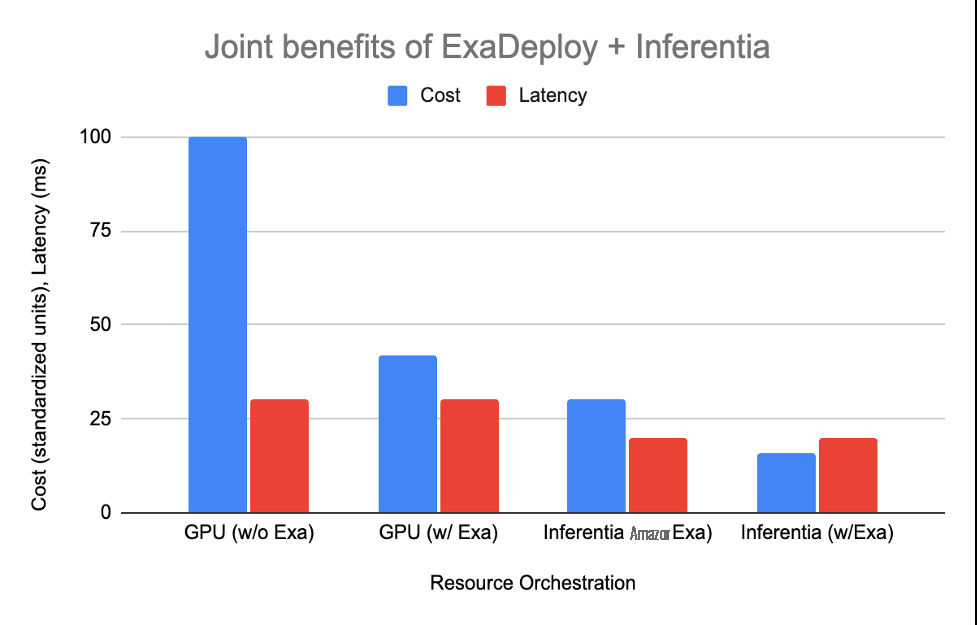
下表显示了每个选项是如何形成的:
| Setup | Resources needed | Cost | Latency |
| GPU without ExaDeploy | 2 CPU, 2 GPU per client (total 20 CPU, 20 GPU) | 100 | 30 ms |
| GPU with ExaDeploy | 8 GPUs shared across 10 clients, 1 CPU per client | 42 | 30 ms |
| 亚马逊云科技 Inferentia without ExaDeploy | 1 CPU, 1 亚马逊云科技 Inferentia per client (total 10 CPU, 10 Inferentia) | 30 | 20 ms |
| 亚马逊云科技 Inferentia with ExaDeploy | 3 亚马逊云科技 Inferentia shared across 10 clients, 1 CPU per client | 16 | 20 ms |
exaDePloy 上的 亚马逊云科技 推理示例
在本节中,我们将通过在 BERT PyTorch 模型上使用 inf1 节点的示例来介绍配置 ExaDePloy 的步骤。我们看到 bert-base 模型的平均吞吐量为每秒 1140 个样本,这表明,对于这种单一模型、单一工作负载场景,ExaDePloy 几乎没有带来任何开销。
步骤 1
:设置
可以使用我们的
inf1.xlarge 作为 AWS 推论
。
第 2 步 :设置 exaDepoy
第二步是设置 exaDePloy。通常,在 inf1 实例上部署 ExaDePloy 非常简单。安装程序主要遵循与在图形处理单元 (GPU) 实例上相同的程序。主要区别在于将模型标签从 GPU 更改为 亚马逊云科技 Inferentia 并重新编译模型。例如,使用 ExadePloy 的应用程序编程接口 (API) 从 g4dn 迁移到 inf1 实例只需要更改大约 10 行代码即可。
-
一种简单的方法是使用 Exafunction 的 它们部署核心 exaDePloy 组件以在亚马逊 EKS 集群中运行。Terraform 亚马逊云科技 Kubernetes 模块或 Helm 图表 。 -
将模型编译成序列化格式(例如 TorchScript、TF 保存的模型、ONNX 等)。对于 亚马逊云科技 推断,我们遵循了
本 教程。 - 在 ExaDePloy 的模块存储库中注册编译后的模型。
-
为模型准备数据(即,不是
exadePloy 特有数据)。
- 从客户端远程运行模型。
exaDeploy 和 亚马逊云科技 Inferentia:搭配起来更好
亚马逊云科技 Inferentia 正在突破模型推理吞吐量的界限,并在云中提供最低的每次推断成本。话虽如此,公司需要适当的协调才能大规模享受Inf1的性价比优势。机器学习服务是一个复杂的问题,如果内部解决这个问题,则需要与公司目标背道而驰的专业知识,而且往往会延迟产品周期。Exafunction的机器学习部署软件解决方案ExaDeploy已成为行业领导者。它甚至可以为最复杂的机器学习工作负载提供服务,同时提供流畅的集成体验和世界一流团队的支持。ExaDeploy 和 亚马逊云科技 Inferentia 共同提高了大规模推理工作负载的性能并节省了成本。
结论
在这篇文章中,我们向您展示了 Exafunction 如何支持 亚马逊云科技 推断以提高性能 ML。
作者简介
Nicholas Jiang,Exafunction 软件工程
Jonathan Ma,软件工程师,exafunction
Prem Nair,Exafunction 软件工程师
Anshul Ramachandran,Exafunction 软件工程师
Shruti Koparkar,亚马逊云科技 高级产品营销经理
Max Liu,亚马逊云科技 首席专家
郎剑英,亚马逊云科技 首席解决方案架构师
Kamran Khan,亚马逊云科技 高级技术产品经理
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。