我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
采纳建议并监控预测扩展以获得最佳计算容量
这篇文章由 EC2 高级产品经理 Ankur Sethi 和 亚马逊云科技 Compute 高级专家解决方案架构师 Kinnar Sen 撰写。
回顾:预测扩展
EC2 Auto Scaling 通过管理底层集群的容量和运行状况来帮助客户保持应用程序的可用性。在预测性扩展之前,EC2 Auto Scaling 提供了动态扩展策略,例如
推出预测性扩展是为了使扩展行动具有主动性,因为它可以预测计算需求所需的变化并相应地进行扩展。扩展操作由集合机器学习 (ML) 决定,该机器学习 (ML) 使用来自您的 Auto Scaling 组扩展模式的数据以及来自我们观测结果的数十亿个数据点构建。预测扩展应用于需求变化迅速但具有重复模式、实例需要很长时间才能初始化的应用程序,或者您 为常规需求模式手动调用
预测扩展的新增功能
可以在非可变的 “仅限预测” 模式下配置预测扩展策略,以评估预测的准确性。当你准备好开始扩展时,你可以切换到 “预测和缩放” 模式。现在,我们规范性地建议,如果您的策略有可能提高可用性和降低成本,是否应将其切换到 “预测和规模” 模式,从而节省手动进行此类评估的时间和精力。您可以通过在 “仅限预测” 模式下创建多个预测扩展策略来测试不同的配置,然后选择在可用性和成本改善方面表现最佳的策略。
监控和可观察性是
在以下部分中,我们将深入探讨这两个功能的细节。
预测性扩展建议
按照这篇预测扩展
这项新功能为根据可用性和成本节约因素在 “预测和扩展” 模式下开启预测扩展提供了规范性指导。为了确定可用性和节省的成本,我们将预测与实际容量和所需的最佳容量进行比较。此所需容量是根据您的实例的运行值是否高于还是低于您在预测扩展策略配置中定义的扩展指标的目标值来推断的。例如,如果一个 Auto Scaling 组以 20% 的 CPU 利用率运行 10 个实例,而预测扩展策略中定义的目标为 40%,则这些实例的运行未得到充分利用 50%,并且假定所需容量为 5 个实例(当前容量的一半)。对于 Auto Scaling 群组,我们会根据您感兴趣的时间范围(默认为两周)汇总预测性扩展对成本节省和可用性的影响。可用性影响衡量的是实际指标值高于您为每个策略定义的最佳目标值的时间长度。同样,成本节约根据每个已定义策略的基础 Auto Scaling 组的容量利用率来衡量总共节省的费用。最终成本和可用性将引导我们根据以下内容提出建议:
- 如果可用性增加(或保持不变),成本降低(或保持不变),则开启预测和扩展
- 如果可用性降低,则禁用预测扩展
- 如果可用性提高会增加成本,则客户应根据其成本可用性权衡阈值接听电话

上图显示了控制台如何反映预测性扩展策略的建议。您将获得有关该策略是否可以提高可用性和降低成本的信息,因此建议切换到预测和规模。为了节省成本,您可能需要降低最低容量,并以提高动态扩展策略的利用率为目标。
为了从此功能中获得最大价值,我们建议您在仅预测模式下创建多个具有不同配置的预测扩展策略,选择不同的指标和/或不同的目标值。目标值是改变容量预测的激进程度的重要杠杆。较低的目标值会增加容量预测,从而提高应用程序的可用性。但是,这也意味着要在
持续监控预测性扩展
根据建议在 “预测和扩展” 模式下使用预测扩展策略后,您必须监控预测扩展策略以了解需求模式变化或预测不准确。我们推出了两个新的CloudWatch预测扩展指标,分别是 “PredictiveScalingLoadForecast” 和 “predictiveScalingCapacityForeca使用 CloudWatch 指标数学功能,您可以创建用于衡量预测准确性的自定义指标。例如,要监控您的保单是超额还是预测不足,您可以发布单独的指标来衡量相应的错误。在下图中,我们展示了如何使用度量数学表达式来创建平均绝对误差,从而对负荷预测进行过度预测。由于预测性扩展只能增加容量,因此在策略过度预测时发出警报以防止不必要的成本很有用。
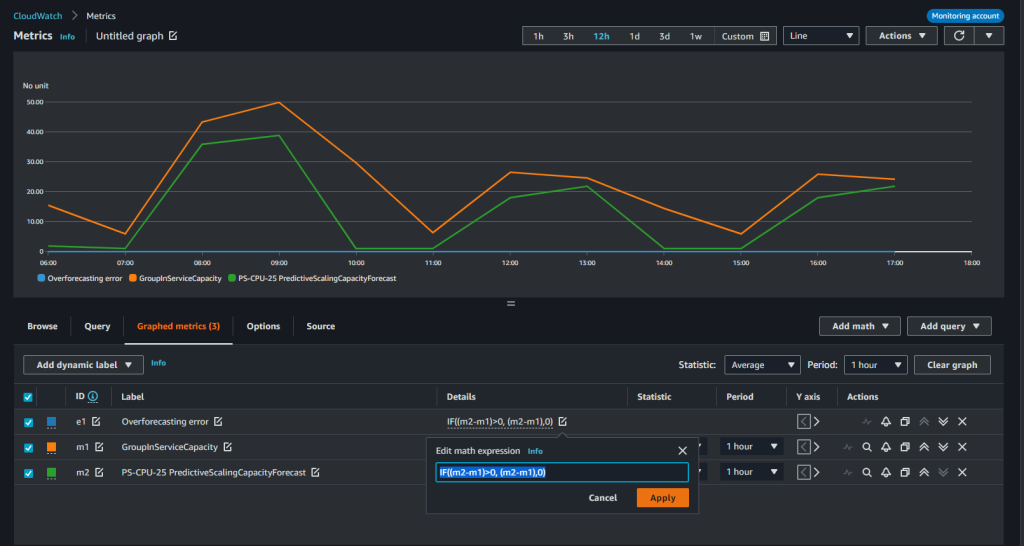
在上图中,Auto Scaling 组的总 CPU 利用率由橙色的 m1 指标表示,而策略的预测负载由绿色的 m2 指标表示。我们使用以下表达式来获得过度预测误差与实际值的比率。
IF ((m2-m1) >0,(m2-m1) ,0)) /m1
接下来,我们将设置警报,使用
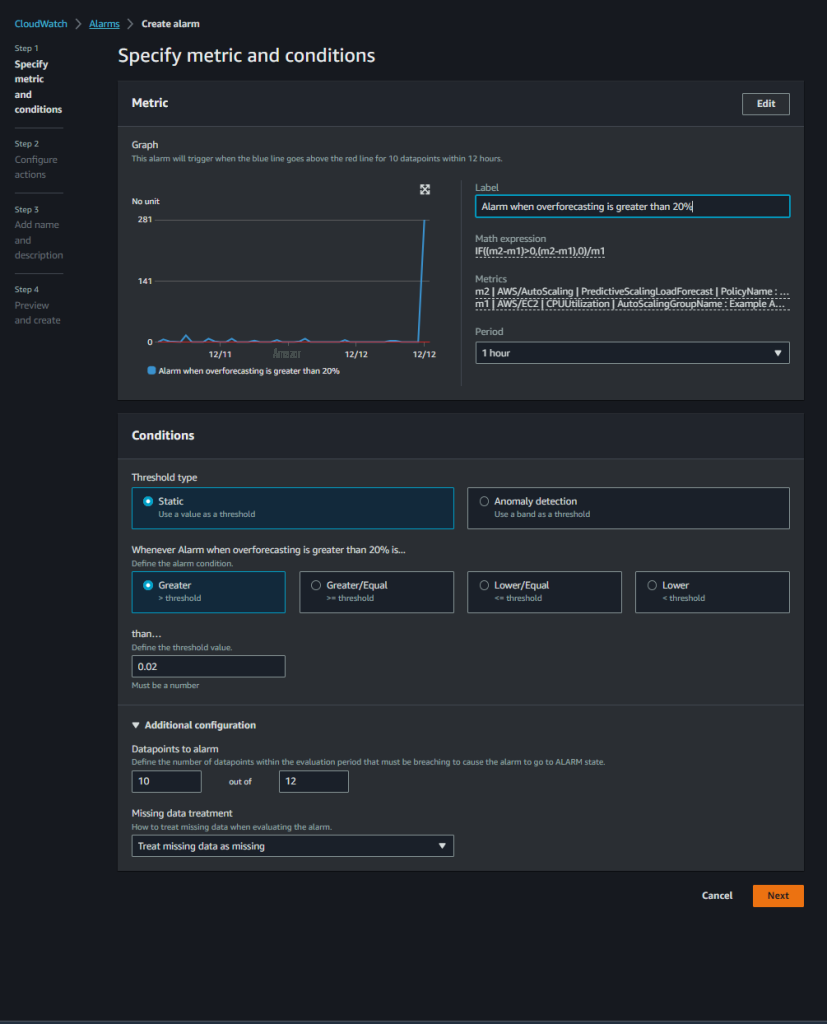
在上面的屏幕截图中,我们设置了一个警报,当我们的自定义精度指标在过去 12 个数据点中有 10 个高于 0.02(20%)时触发,这意味着过去 12 个小时中的 10 个小时。我们更喜欢对更多数据点发出警报,这样我们就只有在预测性扩展持续给出不准确的结果时才会收到通知。
结论
借助这些新功能,您可以更明智地决定预测性扩展是否适合您以及哪种配置最合理。我们建议您从 “仅限预测” 模式开始,然后根据建议切换到 “预测和规模”。进入预测和扩展模式后,预测性扩展将开始采取主动扩展操作,以便在预测需求出现之前启动您的实例并准备好为工作负载做出贡献。然后持续监控预测,以保持应用程序的高可用性和成本优化。您还可以使用新的预测扩展指标和 CloudWatch 功能,例如指标数学、警报和通知,在预测长期偏离设定阈值时进行监控并采取行动。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。