我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 Amazon SageMaker Canvas 加强生命科学运营
根据 Grand View Research 的数据,生命科学行业正在经历显著增长,预计从 2023 年到 2030 年,全球实验室用品市场将以 7.5% 的复合年增长率增长。随着组织面临越来越大的优化运营压力,Amazon SageMaker Canvas 提供了直面这些挑战的能力。我们将深入探讨 SageMaker Canvas 的实际应用,展示它如何优化研究实验室的库存管理和简化药品制造中的缺陷预测。
使用时间序列分析预测实验室库存
我们的第一个示例侧重于实验室库存管理的时间序列预测。目标是根据实验室库存的历史使用情况,预测试剂和其他消耗品等实验室库存的未来使用情况。这可以帮助实验室有效地规划库存支出。
我们的分析利用我们自己创建的合成数据集来模拟试剂和消耗品的实验室库存。这些数据包含了实际的使用模式、季节性、趋势和产品相关性。实验室可以从其实验室系统(例如电子实验室笔记本(ELN)、实验室信息管理系统(LIMS)或采购系统中获取类似的数据。图 1 显示了合成数据集及其分布的视图。
 图 1 — 显示实验室清单数据集的数据类型和分布的表格
图 1 — 显示实验室清单数据集的数据类型和分布的表格
我们导入了数据,并查看了来自 Amazon SageMaker Data Wrangler 的《数据质量和见解报告》。然后,我们让 Chat 进行数据准备以对数据进行排序并创建滞后功能。滞后要素是目标变量的转换版本,其中每个值按特定数量的时间段移至过去。我们还要求 Chat 进行数据准备以处理缺失值并清理占位符值。
这些准备步骤有助于揭示潜在的模式和趋势,从而做出更可靠的预测和明智的决策。
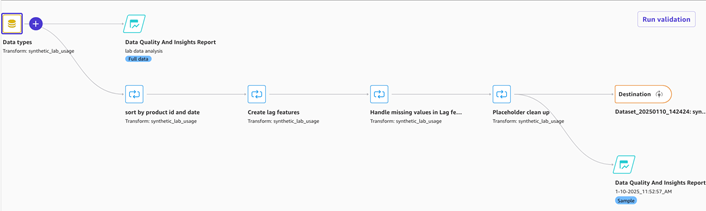
图 2 — 显示转换的 Amazon SageMaker Data Wrangler 数据流和《数据质量洞察报告》
分析库存预测模型
在准备数据后,我们建立了一个预测模型来预测库存使用情况。我们选择了标准版本配置,因为它可以很好地平衡此类预测问题的准确性和处理时间。
预测模型表现出稳定的表现,平均加权分位数损失为 0.152。它显示出很高的准确性,平均绝对百分比误差为 24.7%,加权绝对百分比误差为 20.1%。实际上,这意味着,如果模型预测需要 100 单位的试剂,则实际使用量通常在 75-125 个单位之间,这对于提前一个月的计划来说足够了,但需要考虑安全库存。
均方根误差为 12.374 表示预测值和实际值之间的偏差最小,而平均绝对比例误差 0.670 表明该模型的误差比天真的预测方法的误差小约 33%。与基本预测方法相比,这种改进表明该模型已成功捕获了有意义的库存使用模式。
对于实验室管理人员而言,这些结果表明该模型可以可靠地支持库存规划决策,尽管考虑到预测的不确定性,保持 25% 的安全库存缓冲是明智之举。有关这些指标的详细解释,请浏览指标参考。
使用模型时,应考虑其在分位数上的表现有多一致、对简单预测方法的改进以及整体准确性。考虑这些特征如何与您的特定预测需求和方差容忍度相一致。要了解更多信息,请阅读 "你的模型好吗?深入了解 Amazon SageMaker Canvas 高级指标。"您可以通过阅读客观指标来找到有关当前指标的详细信息。
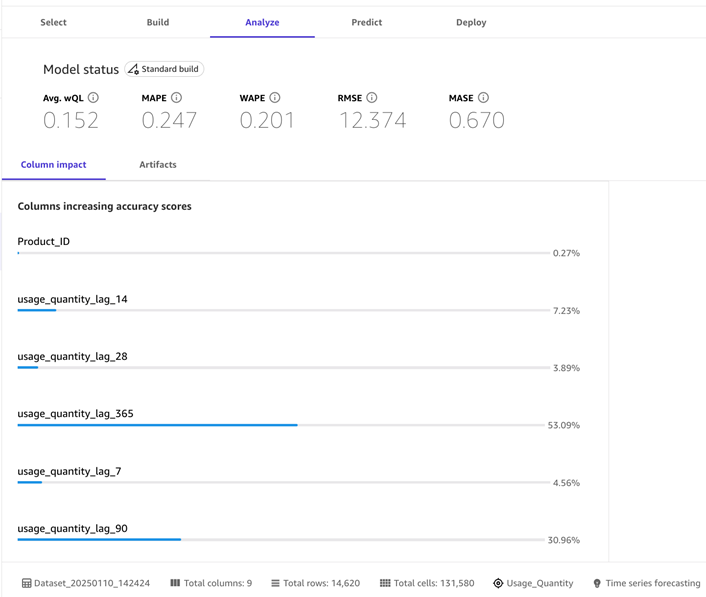
图 3 — 模型状态提供模型指标
进行预测和部署库存模型
要进行单一预测,您可以使用带有时间序列预测模型的单一预测步骤。这将建立对单个数据点的预测,并更改单个值以查看它们如何影响预测结果。在图 4 中,示例项目是 2024 年 12 月 31 日至 2025 年 1 月 30 日期间的 DNA 提取试剂盒。显示了四种不同的预测。P50 表示表示优秀估计值的中位数(第 50 个百分位数)。P25 是第 25 个百分位数(下限估计值),P75 和 P90 是第 75 和第 90 个百分位估计值(上限估计值)。
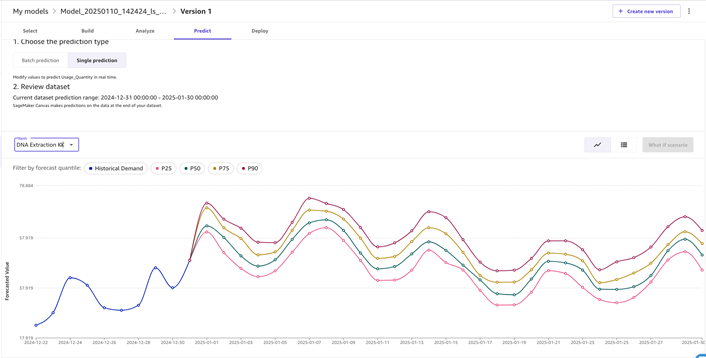 图 4 — 特定项目和范围的单一预测类型
图 4 — 特定项目和范围的单一预测类型
当您准备好将模型部署到终端节点、在 Amazon SageMaker Canvas 之外使用模型进行实时预测并与现有应用程序集成时,请按照将模型部署到终端节点文档进行操作。
制造缺陷预测
在下一个示例中,我们将演示如何建立预测模型来识别药品制造过程中的缺陷。这种能力对于优化生产效率、减少昂贵的返工和提高整体产品质量至关重要。
我们的示例数据集包括影响缺陷率的全面指标,例如产量、供应链质量、质量控制、维护、库存、员工生产率、能源使用和增材制造详情。
数据准备和特征分析
使用 Amazon SageMaker 数据管理器导入数据、创建数据流并生成数据质量和见解报告。以下是图 5 中的功能摘要,提供了有关数据的详细信息,包括有效性、缺失值、高和中等严重性警告以及预测能力。摘要指出,该数据集百分之百有效,缺失百分比为零,高/中警告为零。这意味着数据干净完整,不需要额外的特征工程或数据预处理。
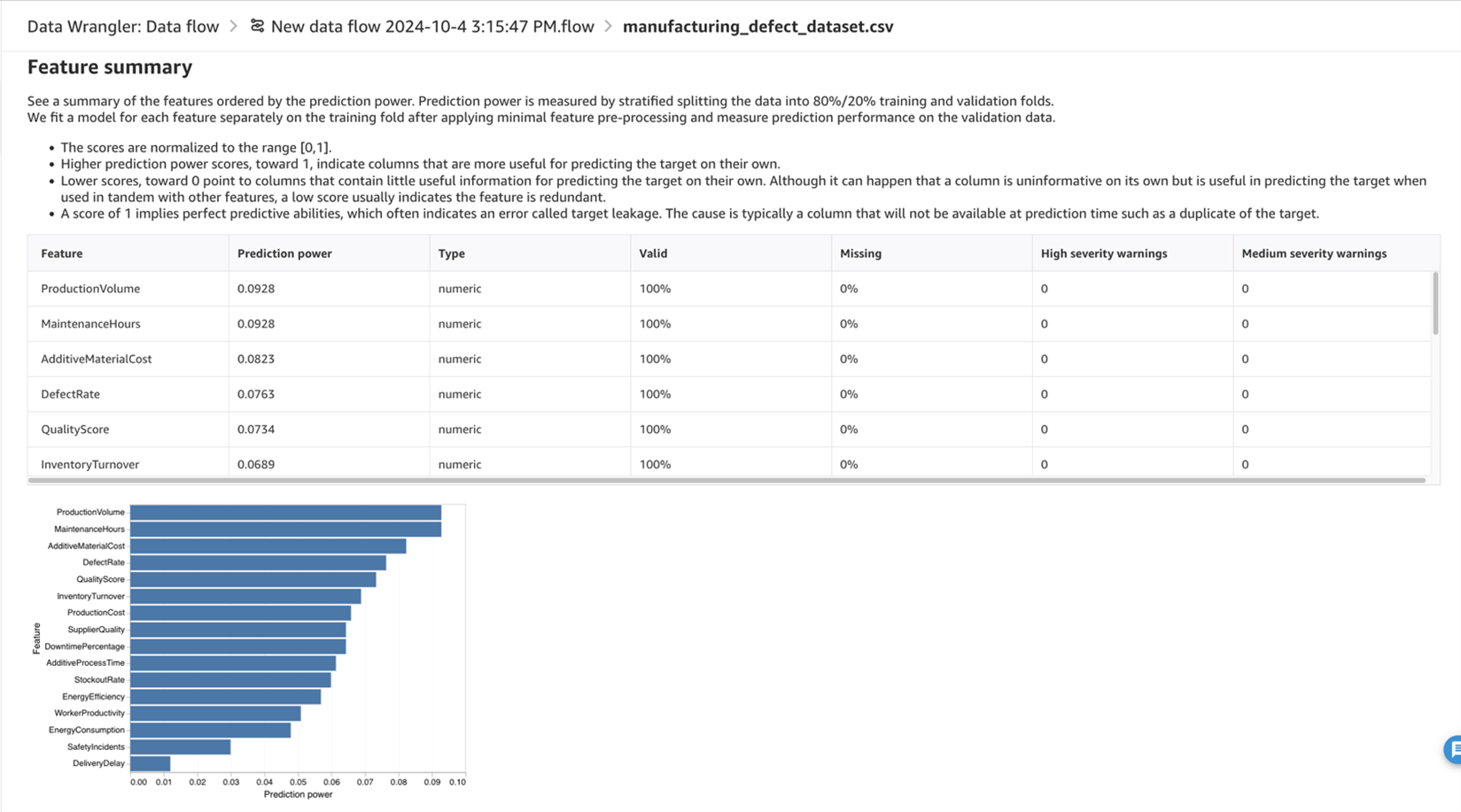 图 5 — 功能摘要,显示预测功效、类型、高和中度警告
图 5 — 功能摘要,显示预测功效、类型、高和中度警告
我们选择维护时间的目标列。SageMaker Canvas 为我们检测到模型类型为 2 个类别的预测。您可以浏览有关自定义模型工作原理的更多详细信息。但是,我们有兴趣进行快速构建,在这个初始阶段,将速度置于精度之上。快速构建完成后,现在让我们在 "分析" 部分检查模型的性能和见解。
模型性能和见解
在模型分析概述中,SageMaker Canvas 按影响力最大到最小的顺序显示列影响。在此用例示例中,维护时间对预测缺陷状态的影响最大。图 6 描绘了模型的分析,显示了准确性、F1 分数、列对可预测性的影响以及 MaintenanceHours 对缺陷状态预测的散点图。在这里,"维护时间" 是对缺陷状态影响最大的专栏。
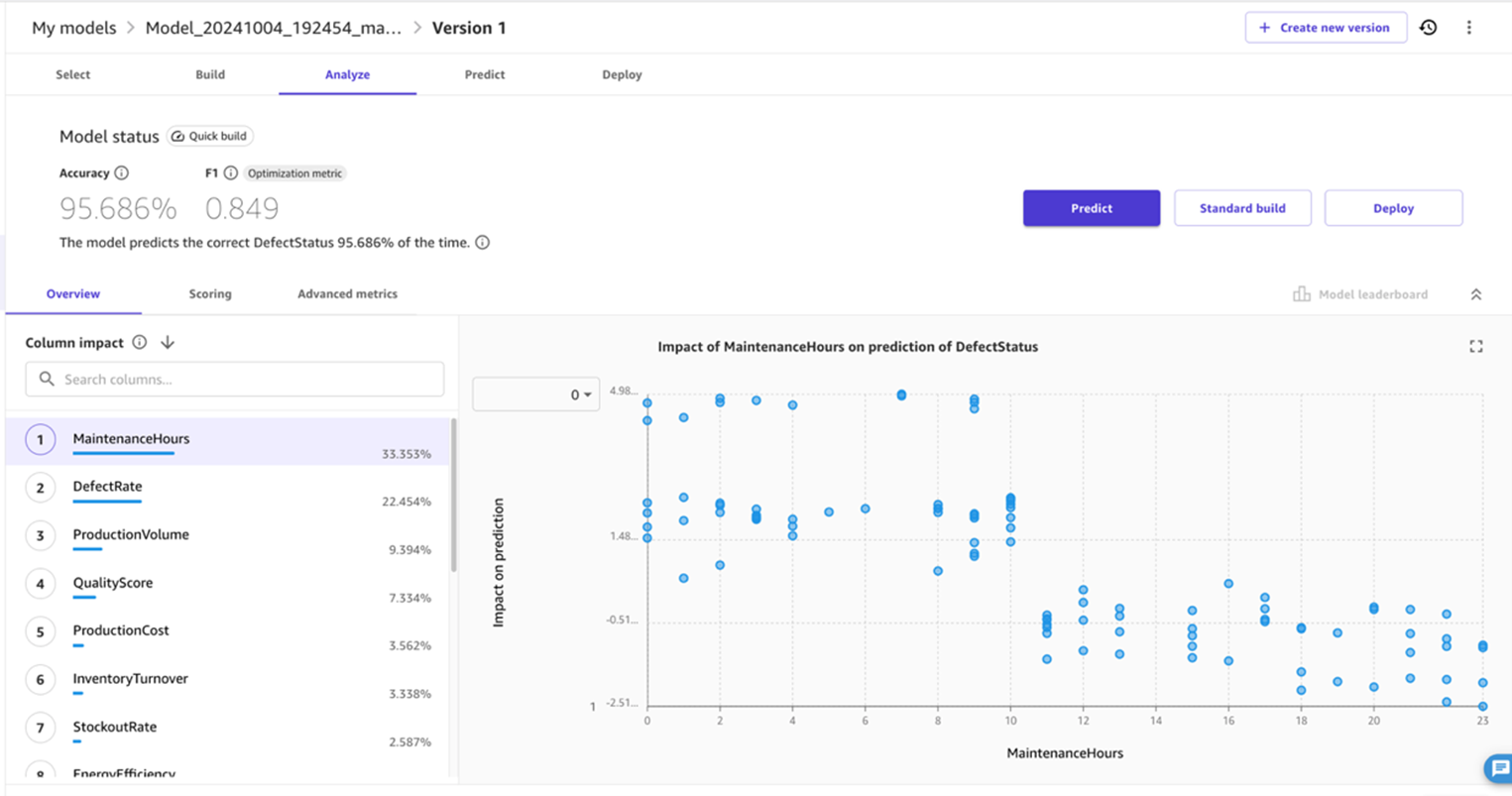 图 6 — 模型分析
图 6 — 模型分析
在预测机器缺陷的模型中,我们取得了令人鼓舞的结果:
- 准确度:95.686%
- F1 分数(优化指标):0.849
高准确度分数表明我们的模型在超过 95% 的情况下对机器状态(有缺陷或无缺陷)进行了正确分类。我们的优化指标 F1 得分为 0.849,这表明在识别缺陷时在精度和召回率之间取得了很好的平衡。您可以通过阅读我们的分类预测指标文档来了解更多信息。
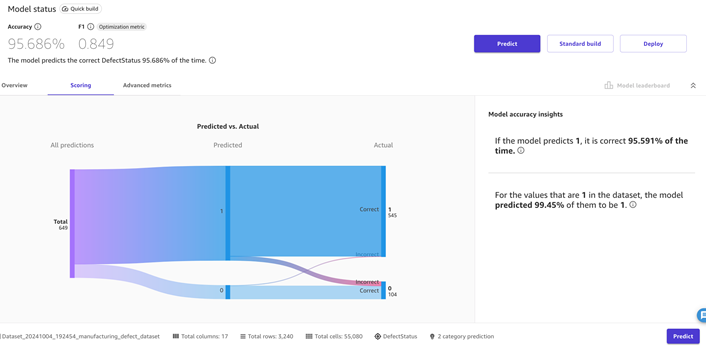 图 7-将预测与实际测量值进行比较。
图 7-将预测与实际测量值进行比较。
我们可以测试不同的值,看看它们如何影响预测结果。我们还可以按照使用手动批量预测的步骤来测试我们的模型,或者您可以选择在更新数据集时设置自动更新,以进行自动批量预测。
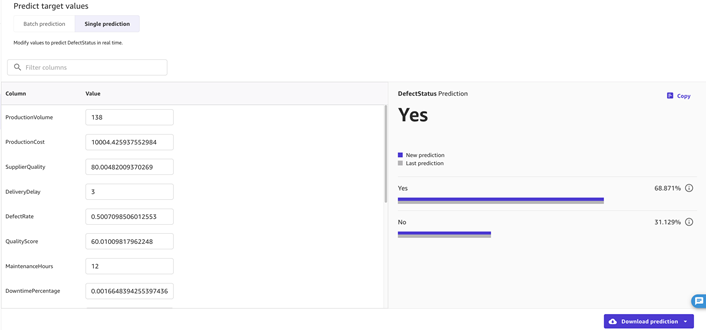 图 8 — 使用单一预测预测目标值
图 8 — 使用单一预测预测目标值
准备好在 Amazon SageMaker Canvas 之外部署模型后,就可以创建终端节点。然后设置 Amazon SageMaker 模型监控器进行持续监控。了解 SageMaker 模型监视器的工作原理。
结论
实验室运营和药品制造领域的团队正在寻求简便性、更高的效率、更少的返工以及主动发现工作中的问题。但是,技能组合的分离可能使数据科学家没有理解生命科学数据的专业知识,或者生命科学专家没有构建可扩展机器学习应用程序的软件技能。
Amazon SageMaker Canvas 通过用户友好的可视化界面和强大的模型训练功能赋予生命科学团队增强运营成果,从而填补了这一职责。通过利用 SageMaker Canvas,组织可以普及机器学习,并在其生命科学工作流程中实现数据驱动的决策。
联系亚马逊云科技代表,了解我们如何帮助加速您的业务。
开始为您的组织使用 Amazon SageMaker Canvas
- 在亚马逊云科技生命科学页面上探索特定行业的解决方案
- Amazon SageMaker Canvas 客户感言
- 教程:Amazon SageMaker Canvas 入门
- 使用 Amazon SageMaker Canvas 进行生命科学和医疗保健预测分析
- 使用 Amazon SageMaker Canvas 预测心脏病的无代码机器学习方法

詹姆斯·盖恩斯
詹姆斯·盖恩斯是亚马逊云科技医疗保健和生命科学高级解决方案架构师。他在高度监管的环境中拥有背景,包括国防部和制药行业。James 拥有所有有效的亚马逊云科技认证,专门从事云迁移、应用程序现代化和高级分析,以推动医疗保健和生命科学领域的创新。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。