我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
在 Amazon CloudWatch 中使用异常值检测来检测灰度故障
您过去可能遇到过这样的情况:您的系统的单个用户或一小部分用户报告的事件影响了他们的体验,但您的可观测性系统并未显示出任何明显的影响。客户体验与系统对其运行状况的观察之间的差异被称为 差异可观测性 y。换句话说, 不同的视角观察故障的方式不同,这些都是灰色故障。灰色故障是指即使客户体验受到影响,但发生的系统仍未检测到的正常故障。灰色故障可能源于您的工作负载及其所依赖的依赖关系。
要及时准确地响应和缓解灰色故障,就需要将其转化为已检测到的故障。这篇文章将帮助您制定可观测性策略,使用异常值检测将灰色失效转化为检测到的故障。异常值检测是检测与系统中均值或中值相去甚远的数据点的过程。
在这篇博客文章中,您将学习如何使用 CloudWatch 贡献者见解来执行异常值检测。这种方法将帮助您找到灰色故障的来源,否则这些故障可能仅使用标准可用性或延迟指标就无法检测到。通过比较主机和可用区的错误率或延迟,您将能够将灰色故障转换为可以响应的检测到的故障。
为什么灰色故障表现为异常值
想象一下亚马逊弹性计算云 (Amazon EC2) 服务器队列中有 50 个实例,分布在多个可用区的 Auto Scaling 组中,位于亚马逊弹性负载均衡器 (ELB) 后面,如下图所示。其中一个实例的亚马逊弹性区块存储 (EBS) 容量降低,使其无法成功处理客户请求。这种损害不会影响其响应
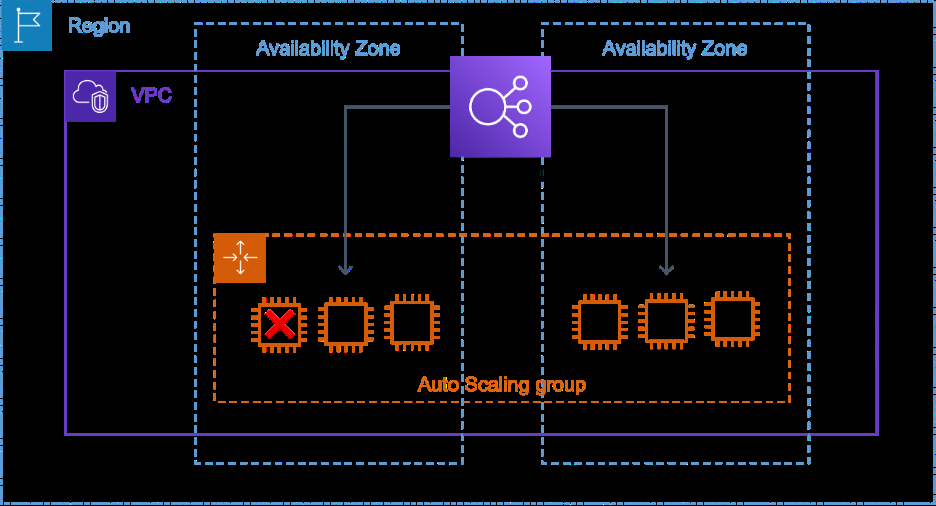
图 1 — 负载均衡器后面的自动扩展组中的 EC2 实例,其中一个实例被认为运行状况良好,但无法处理客户请求
每台服务器的错误率指标将显示 EBS 容量受损的 EC2 实例与所有其他队列之间存在显著差异。但是,在部署了 10 个或 100 个实例时,为每个实例创建可用性或延迟警报既不典型也不切实际,尤其是当它们被视为临时资源,不断被配置或终止时。每台服务器的警报成本也可能高得令人望而却步,它们不会通知您一个实例的错误率明显高于其他实例,这正是我们想知道的。异常值检测可帮助操作员区分由单一资源造成的影响与由多种资源引起的影响。它还消除了许多运行状况良好的资源可能对单个不健康主机生成的故障和延迟指标产生的抑制作用。
寻找单主机灰色故障
我们将使用贡献者洞察来查找队列中的异常值。首先,我们记录收到的用于处理的每个工作单元(例如 HTTP 请求、SQS 消息、批处理作业等)的指标。CloudWatch
在我们的示例中,实例正在向 CloudWatch Logs 写入包含 InstanceID、错误、成功、延迟等数据元素的结构化日志。您可以在 CloudWatch 中创建贡献者见解规则,以绘制这些日志文件中错误数量的主要贡献者。以下示例规则定义将确定构成队列中出现的故障总数的 EC2 实例。
使用此规则,CloudWatch 会显示与以下内容类似的图表:
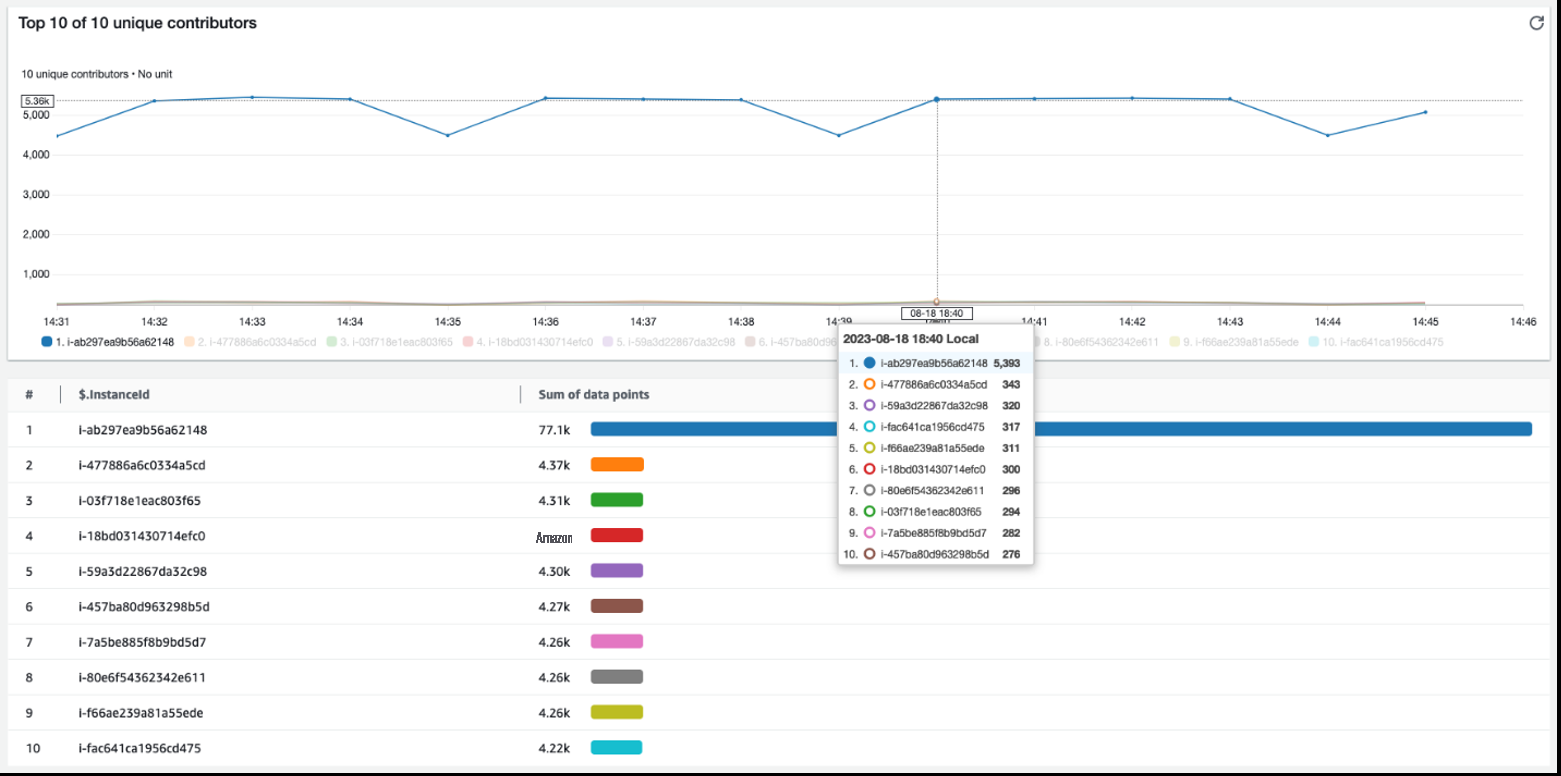
图 2 — 前端机群故障原因的贡献者见解图
此处显示的所有实例都会产生一定数量的错误,但是实例 i-ab297ea9b56a62148 在异常值中 脱颖而出,错误数几乎是错误数的 20 倍。Contributor Insights 规则可以清楚地显示灰色故障的影响,并将其转化为检测到的故障。
我们的目标是自动检测此类故障并减少操作员的干预。我们将使用 CloudWatch 警报指标数学和贡献者见解规则来实现自动化。以下警报定义将在单个实例造成至少 70% 的错误总数时发出警报。这个数量代表了这篇文章,它不是一个规范性的数字,你的阈值可能是 30% 或 50%,这可能会根据你的舰队规模和用例而有所不同。
上面的警报定义并未告知我们作为最大贡献者的具体实例,仅告知我们贡献者超过了定义的阈值。要找到最大贡献者,您可以让此警报发送触发 Lambda 函数的 SNS 通知。该函数可以使用

图 3 — 将提供贡献者洞察规则的 EMF 日志发布到 CloudWatch 后,警报会调用 Lambda 函数,该函数会自动找到导致错误的最大因素
如果您决定根据此类警报采取自动操作,请确保实施速度控制,以防止太多实例在短时间内终止。相反,你可能需要通知人工操作员让他们参与进来。
查找单可用区灰色故障
我们经常看到灰色故障的另一个地方是在单个可用区内。在这种情况下,短暂的网络故障或影响区域服务的损坏有时会表现为灰色故障。您可以使用与检测单实例灰度故障相同的异常值检测机制来检测单可用区灰色故障。
为此,您需要您的实例在其日志文件中将其
在灰色失效期间,生成的图形将与下图类似。
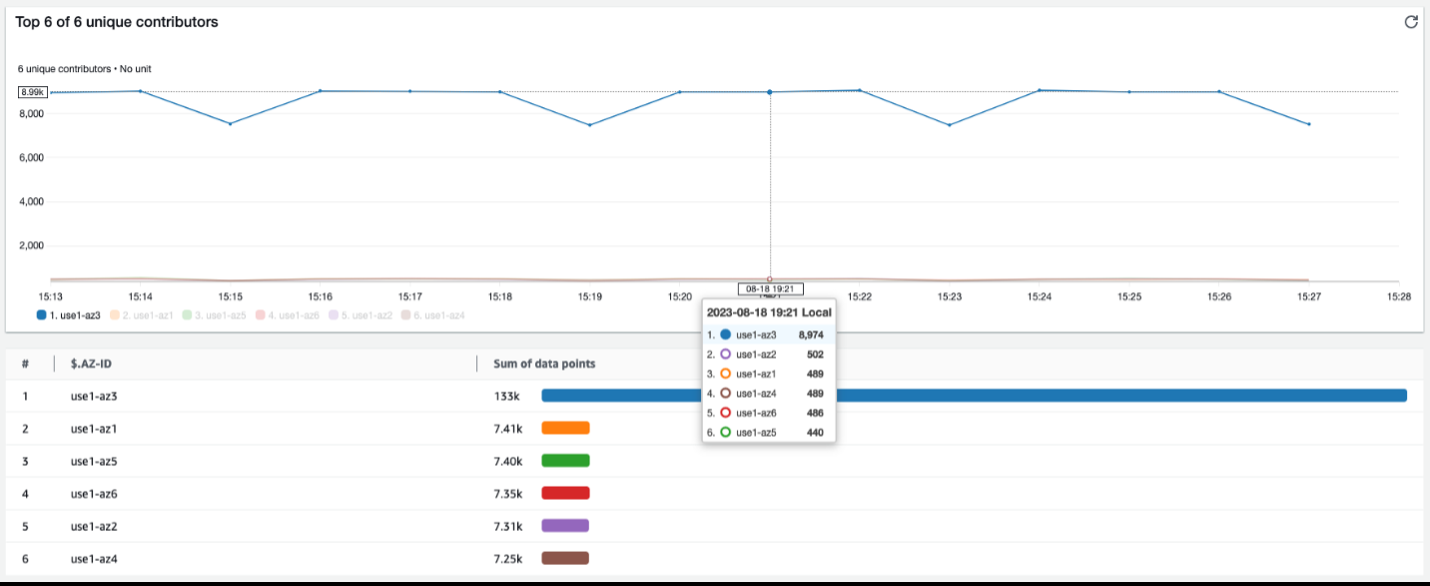
图 4 — 绘制可用区故障率的影响因素
该图向我们显示,与正在使用的任何其他可用区相比,use1-az3 的故障率也几乎是 20 倍。当您看到此类结果时,可以使用上一节中提到的相同自动化来检测哪个可用区受到影响。作为回应,您可以使用诸如 Ama
后续步骤
在这篇文章 中,我们描述了如何使用 CloudWatch 贡献者见解来识别异常值和发现灰色故障。这可以帮助您将灰色故障转化为可以准确响应和缓解的检测到的故障。在此处了解有关 CloudWatch 贡献者见解的
作者简介
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。