我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
检测并修复亚马逊文档数据库中的低基数索引
当您运行数十或数百个 Amazon DocumentDB 集群时,主动检测和监控基数变化非常重要。尽管在某些情况下可能需要低基数索引,或者集合足够小以至于目前不会造成任何问题,但在许多情况下,大型集合的低基数索引会导致性能问题。在这篇文章中,我们将介绍审查和修复现有 Amazon DocumentDB 集群的低基数索引的步骤。
为了演示这一点,我们使用
低基数检测实用程序概述
此实用程序可以对 DocumentDB 集群的每个集合中的文档(默认每个索引 100K)进行采样,以创建基数报告。然后,用户可以查看此报告,重点关注低于建议的 1% 基数的指数。该脚本会对每个集合的随机样本进行集合扫描,根据样本大小和实例类型,它可能会影响持续的工作负载。你可以在非生产环境中运行它,也可以使用不主动提供流量的读取器实例。
GitHub 存储库包含有关如何加载示例数据、创建测试索引和运行基数测试的说明。如果你在自己的集群上运行它,你可以跳到自
下表汇总了基数测试脚本支持的参数。除了
--connection-string
之外 ,其余都是可选参数。默认情况下,基数测试在所有数据库和集合上运行。您可以通过传入--database 或
--collections 参数将测试范围缩小到单个数据库
或
集合
。
| Parameter | Details | Default |
--uri
|
Connection string of Amazon DocumentDB instance. | N/A |
--max-collections
|
Maximum number of collections to scan in a database. | 100 |
--threshold
|
Index cardinality threshold percentage. Indexes with less than this percentage will be reported. Value should be numeric integers or decimal type. | 1 |
--databases
|
Command separated list of databases to check cardinality. | All |
--collections
|
Command separated list of collections to check cardinality. | All |
--sample-count
|
Max documents to sample for each index. Increasing this limit may result in higher IOPS cost and extended runtime. | 100000 |
先决条件
用于运行该实用程序的主机必须满足以下先决条件:
-
通过
ssh-tunnel 或在同一 VPC 内的亚马逊弹性计算云(亚马逊 EC2) 实例外壳中通过 CLI 访问 DocumentDB 集群。 -
- Python 3.9+ 安装了 Pandas
- Mongo 客户端 4.0+
设置并运行基数检测实用程序
要配置和使用该实用程序,请执行以下操作:
-
通过 mongo 外壳连接到亚马逊 DocumentDB(确保您的集合中有索引)。你可以在 mongo shell 中运行以下查询:

- 从 GitHub 下载项目和 DocumentDB 连接证书。
-
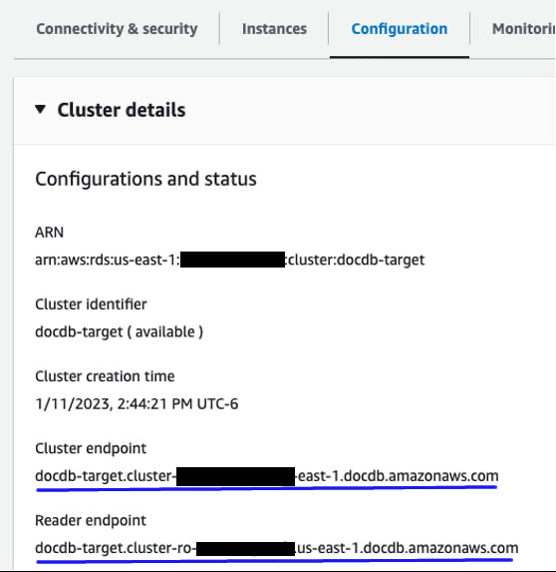
在亚马逊文档数据库控制台上查找亚马逊 DocumentDB 集群或读取器终端节点。导航到您的数据库,然后选择 “
配置
” 选项卡。复制并保存该端点。
-
运行该实用程序,将变量
[DOCDB-USER] 、[DOCDB-PASS]和 [DOCDB-ENDPOINT]替换为集群的信息。tls=true&tlscafile=Global-bundle.pem” 脚本可能需要几分钟才能完成。 输出将与以下屏幕截图类似:
在此示例
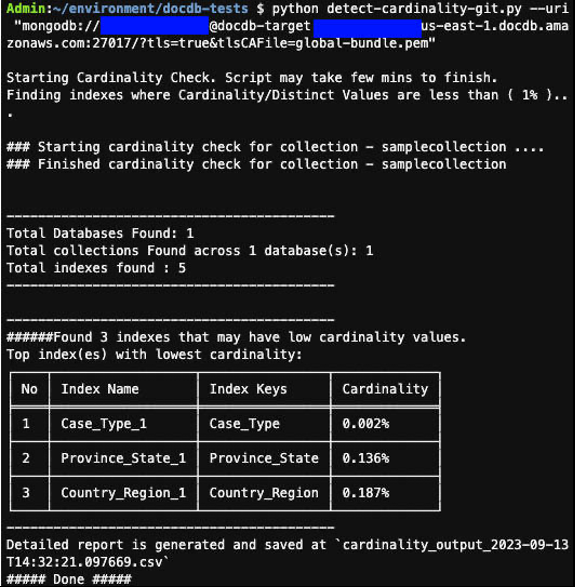
中,脚本发现 5 个索引中,有 3 个(忽略_id索引)低于 1% 的低基数阈值。该脚本还将包含详细报告的 CSV 文件保存在当前目录中,该文件类似于以下屏幕截图: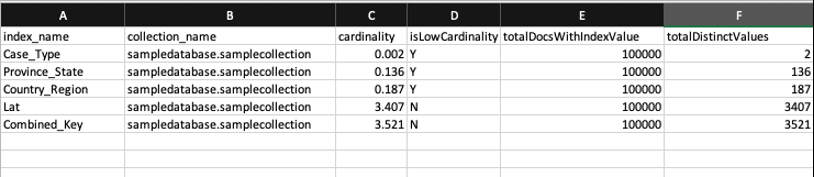
该报告显示,C
ase_Type
、
省份_类型
和
国家/地区
是基数较低的指数 ,可能不是索引的理想候选指标。
此实用程序可能会读取大量数据(每个索引有 100,000 个文档),因此建议在 QA 或代表性环境中运行此脚本。为了安全起见,你可以在非高峰时段运行它。您也可以
修复低基数指数
本节介绍如何修复索引基数检测实用程序生成的报告中发现的低基数索引。
删除未使用的索引
索引通常处于未使用状态,因为要求已更改或创建索引是错误的。Amazon DocumentDB 会统计索引的使用次数。有关如何查找和删除未使用的索引的说明,请参阅
如果可能,建立复合索引
如果用户同时搜索所有三个搜索子句,则构建复合索引而不是添加多个搜索子句是有意义的。你可以用下面的代码来做到这一点:
在这篇文章中提到的示例中,我们检查了
样本收集
指数的基数,发现三个基数较低的索引:案例类型、国家/地区和省份。
为了确保复合索引得到利用,查询中提供的字段的顺序必须与索引的顺序相同。根据集合的大小,可能需要几分钟到几小时才能完成索引的创建。如
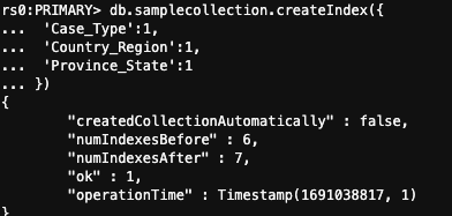
创建索引后,您可以查看解释 E
xecutationStats
状态的查询,以确保索引已被使用,并且 nRetur
ned 属性 显示的数字较小
。
您可以使用类似于以下内容的查询进行测试:
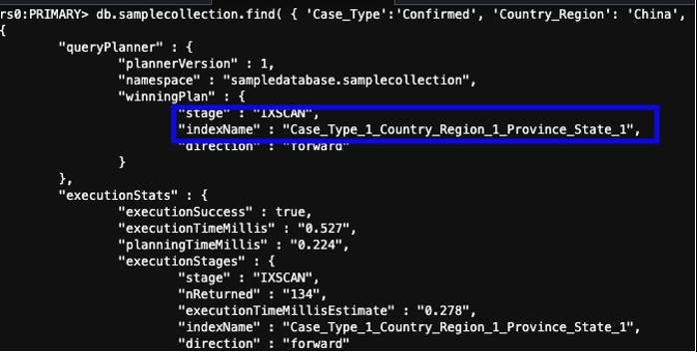
前面的查询大规模运行的成本较低。确认索引已创建后,您可以保留复合索引并删除不再使用的索引。这还有助于减少存储空间并可能提高数据采集性能。
清理
以下命令将删除作为Github项目中描述的说明的一部分而创建的数据库、集合和索引。如果您没有使用所使用的示例数据库,请跳过此测试。
结论
当您的集合大小开始增长到数百万个文档,并且您必须不断扩展实例以满足内存和 CPU 要求时,低基数通常会成为一个问题。这使得基数卫生对于大型馆藏非常重要,但也最好密切关注小型馆藏的基数,因为它们将来可能会带来问题。在这篇文章中,我们解释了如何使用
在评论部分发布您的问题或反馈,或者创建一个 Github 问题,建议对脚本进行改进。
作者简介
 Puneet Rawal
是一位驻芝加哥的高级解决方案架构师,专门研究 亚马逊云科技 数据库。他在架构和管理大型数据库系统方面拥有 20 多年的经验。
Puneet Rawal
是一位驻芝加哥的高级解决方案架构师,专门研究 亚马逊云科技 数据库。他在架构和管理大型数据库系统方面拥有 20 多年的经验。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。