我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 亚马逊云科技 上的自动数据分析从应用程序日志中获得运营见解
ADA 提供了一个基础平台,可供数据分析师在包括 IT、财务、营销、销售和安全在内的各种用例中使用。ADA 的开箱即用的 CloudWatch 数据连接器允许从部署 ADA 的同一 亚马逊云科技 账户的 CloudWatch 日志中提取数据,或者从不同的 亚马逊云科技 账户中提取数据。
在这篇文章中,我们将演示应用程序开发人员或应用程序测试人员如何使用 ADA 来获得在 亚马逊云科技 中运行的应用程序的运营见解。我们还演示了如何使用 ADA 解决方案连接到 亚马逊云科技 中的不同数据源。我们首先
解决方案概述
在本节中,我们将介绍演示的解决方案架构并解释工作流程。
下图概述了使用 ADA 深入了解应用程序日志的架构和工作流程。

工作流程包括以下步骤:
- 计划使用 EventBridge 每隔 2 分钟触发 Lambda 函数。
-
Lambda 函数发出存储在 /aws/lambda/cdkstack-adaloggenLambdaFunction 下的指定 CloudWatch 日志组中的日志。应用程序日志使用 Apache 日志格式架构生成,但以 JSON 格式存储在 CloudWatch 日志组中。 - CloudWatch、亚马逊 S3 和 DynamoDB 的数据产品是在 ADA 中创建的。CloudWatch 数据产品连接到存储应用程序(Lambda 函数)日志的 CloudWatch 日志组。Amazon S3 连接器连接到存储历史日志的 S3 存储桶文件夹。DynamoDB 连接器连接到 DynamoDB 表,其中存储了应用程序引用的状态代码和历史日志。
- 对于每种数据产品,ADA 部署数据管道基础设施以从源中提取数据。数据提取完成后,您可以通过 ADA 查询工作台使用 SQL 编写查询。
-
您可以登录 ADA 门户并从 Query Workbench 编写 SQL 查询,以深入了解应用程序日志。您可以选择保存查询并与同一域中的其他 ADA 用户共享查询。ADA 查询功能由
Amazon Athena 提供支持 ,这是一项无服务器的交互式分析服务,提供了一种简化、灵活的方法来分析 PB 级数据。 - Tableau 配置为通过 ADA 出口端点访问 ADA 数据产品。然后,您可以创建一个包含两个图表的仪表板。第一张图表是一张热图,显示了与应用程序 API 端点相关的 HTTP 错误代码的普遍性。第二张图表是一个条形图,显示了历史数据中排名前 10 位的 HTTP 错误代码总数。
先决条件
对于这篇文章,你需要完成以下先决条件:
-
安装 亚马逊云科技 命令行接口 (亚马逊云科技 CLI)、AWS 云开发套件 (亚马逊云科技 CDK)先决条件 、特定于 Typescript 的先决条件 和 git。 -
在您 的 亚马逊云科技 账户中@@
部署 ADA 解决方案,位于美国东部 1 区域。-
在启动 ADA
亚马逊云科技 CloudFormation 堆栈时提供管理员邮件。这是 ADA 发送根用户密码所必需的。如果启用了多因素身份验证 (MFA),则需要管理员电话号码才能接收一次性密码消息。在本演示中,未启用 MFA。
-
在启动 ADA
-
构建和部署示例应用程序(可在
GitHub 存储库 中找到 )解决方案,以便可以在您的us-east-1 区域的账户中配置以下资源: 模拟日志应用程序的 Lambda 函数和每- 隔 2 分钟调用应用程序功能的 EventBridge 规则。
- 包含相关存储桶策略的 S3 存储桶和包含历史应用程序日志的 CSV 文件。
- 包含查询数据的 DynamoDB 表。
-
服务所需的相关
亚马逊云科技 身份和访问管理 (IAM) 角色和权限。
-
(可选)安装第三方 BI 提供商
Tableau 桌面 。在这篇文章中,我们使用 Tableau 桌面版 2021.2。使用 Tableau 桌面应用程序的许可版本会涉及成本。有关其他详细信息,请参阅Tableau 许可 信息。
部署和设置 ADA
成功部署 ADA 后,您可以使用安装期间提供的管理员电子邮件
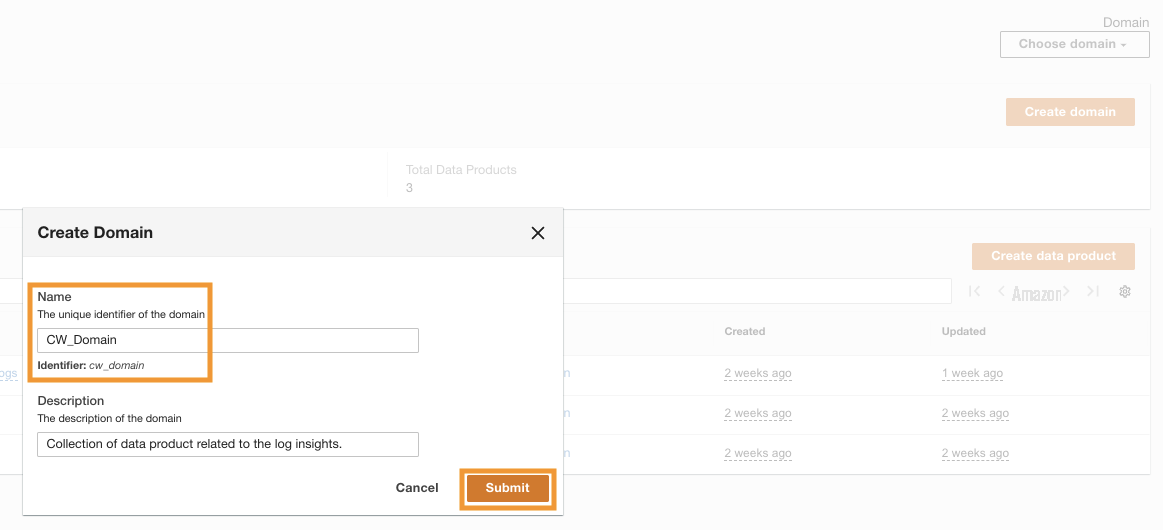
CW_
Domain 的
- 在 ADA 控制台上, 在导航窗格中选择 域名 。
- 选择 创建域名 。
-
输入名称(
CW_Domain)和描述,然后选择 提交。
使用 亚马逊云科技 CDK 设置示例应用程序基础设施
这些步骤执行以下操作:
- 安装库依赖关系
- 生成项目
- 生成有效的 CloudFormation 模板
- 在您的 亚马逊云科技 账户中使用 亚马逊云科技 CloudFormation 部署堆栈
部署大约需要 1-2 分钟,会创建 DynamoDB 查找表、Lambda 函数和包含历史日志文件作为输出的 S3 存储桶。将这些值复制到文本编辑应用程序,例如记事本。

创建 ADA 数据产品
我们为该演示创建了三种不同的数据产品,每个数据源都有一个,您将要查询这些数据源以获得运营见解。数据产品是已成功导入到 ADA 并且可以查询的数据集(表或 CSV 文件等数据的集合)。
创建 CloudWatch 数据产品
首先,我们通过将 ADA 设置为采集示例应用程序(Lambda 函数)的 CloudWatch 日志组,为应用程序日志创建数据产品。使用
cdkStack.lambdaFunction 输出获取 Lamb
da 函数 ARN 并在 CloudWatch 控制台上找到相应的 CloudWatch 日志组 ARN。

然后完成以下步骤:
- 在 ADA 控制台上,导航到 ADA 域并创建 CloudWatch 数据产品。
- 在 “ 名称 ” 中输入一个名称。
- 对于 来源类型, 选择 亚马逊 CloudWatch 。
- 禁用 自动 PII 。
ADA 具有在导入期间自动检测个人身份信息 (PII) 数据的功能,该功能默认处于启用状态。在本演示中,我们禁用了数据产品的此选项,因为 PII 数据的发现不在本演示的范围内。
-
选择 “
下一步
” 。

-
搜索并选择从上一步中复制的 CloudWatch 日志组 ARN。

-
复制日志组 ARN。

- 在数据产品页面上,输入日志组 ARN。
- 对于 CloudWatch 查询 ,输入您希望 ADA 从日志组中获取的查询。
在此演示中,我们查询 @message 字段是因为我们有兴趣从日志组中获取应用程序日志。

- 选择初始导入后如何触发数据更新。
可以将 ADA 配置为以灵活的时间间隔(最多 15 分钟或更晚)或按需从源中提取数据。在演示中,我们将数据更新设置为每小时运行一次。
- 选择 “ 下一步 ” 。

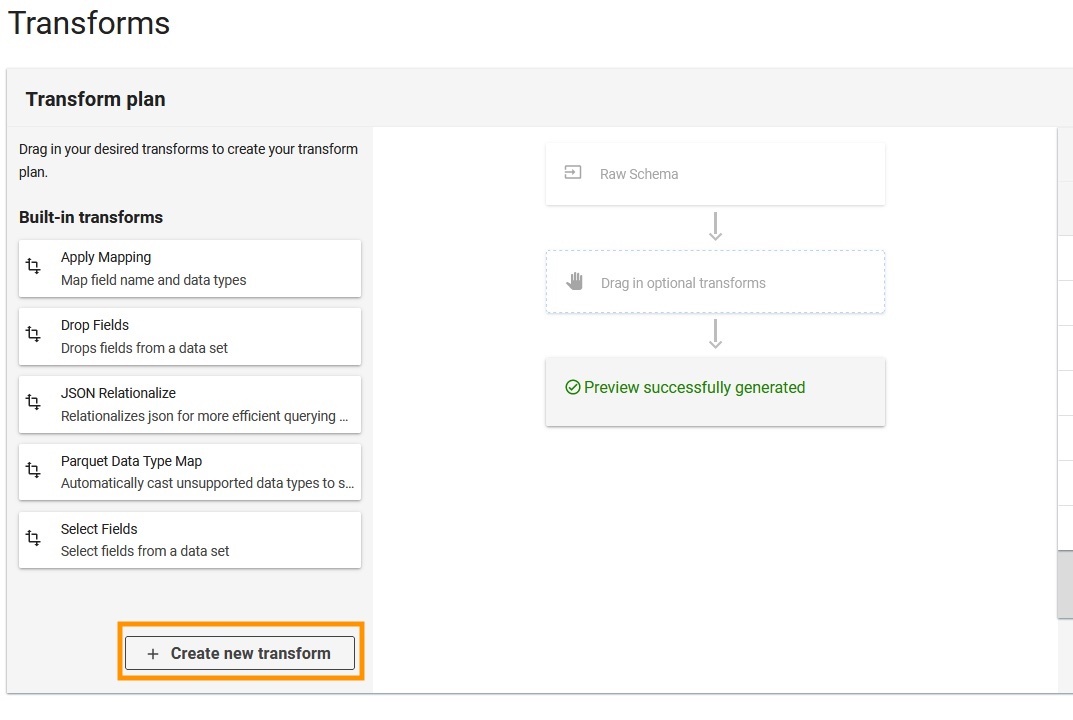
接下来,ADA 将连接到日志组并查询架构。由于日志采用 Apache 日志格式,因此我们将日志转换为单独的字段,以便我们可以对特定的日志字段运行查询。ADA 提供四种
-
选择 “
转换架构”
。

-
选择 “
创建新变换
” 。
-
从 /asset/transform_log
s/ 文件夹上传apache-log-extractor-transform.py脚本。 -
选择 “
提交
” 。
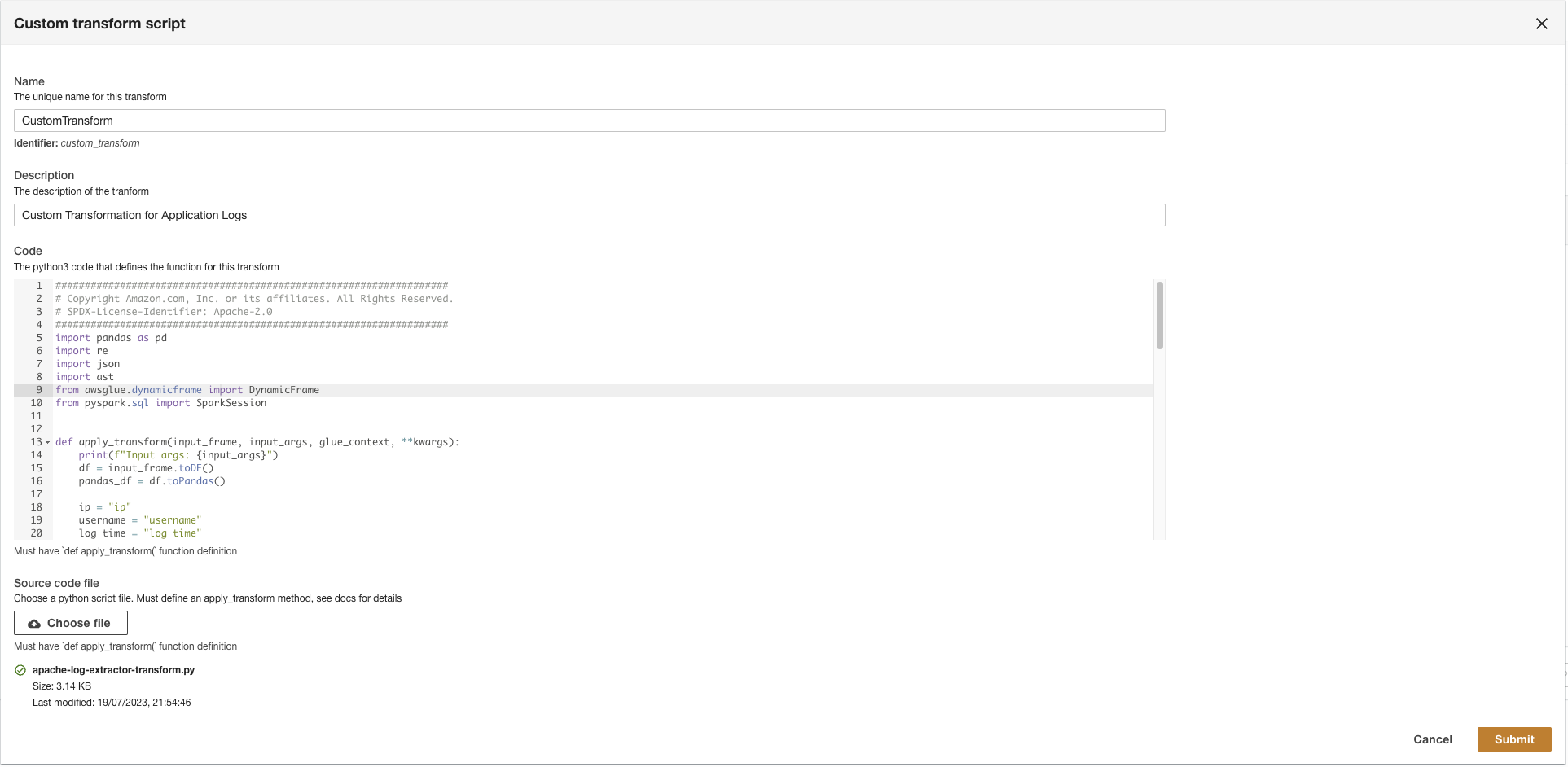
ADA 将使用脚本转换 CloudWatch 日志并呈现经过处理的架构。
-
选择 “
下一步
” 。

- 在最后一步中,查看步骤并选择 S ubmit 。
ADA 将开始数据处理,创建数据管道,并准备要从查询工作台查询的 CloudWatch 日志组。此过程需要几分钟才能完成,并将显示在 ADA 控制台 的数据产品 下 。
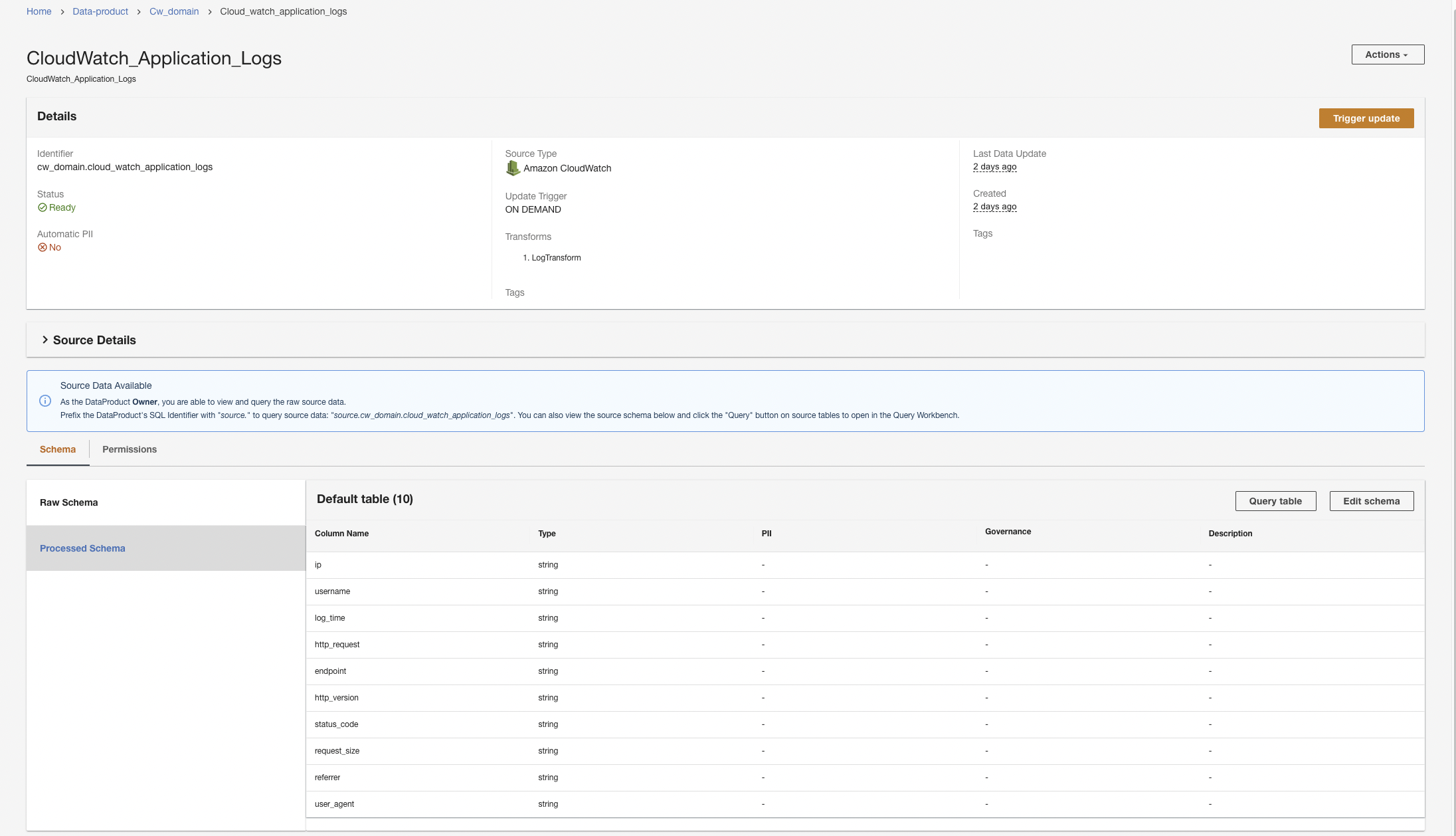
创建亚马逊 S3 数据产品
我们重复这些步骤,添加来自 Amazon S3 数据源的历史日志,并从 DynamoDB 表中查找参考数据。对于这两个数据源,我们不创建自定义转换,因为数据格式采用 CSV(用于历史日志)和关键属性(用于参考查找数据)。
- 在 ADA 控制台上,创建新的数据产品。
-
输入名称(hi
st_logs ),然后选择 亚马逊 S3。

-
从
cdkStack.S3 输出变量中复制亚马逊 S3 URI(arn: aws: s3:: 之后的文本 ),然后导航到亚马逊 S3 控制台。 -
在搜索框中,输入复制的文本,打开 S3 存储桶,选择
/ logs 文件夹,然后选择复制 S3 URI。
历史日志存储在此路径中。

- 导航回 ADA 控制台并输入复制的 S3 URI 以获取 S3 位置 。
- 对于 更新触发器 ,请选择 按需 更新, 因为历史日志的更新频率未指定。
- 对于 “ 更新策略 ” ,选择 “ 追 加”,将新导入的数据附加 到现有数据。
- 选择 “ 下一步 ” 。
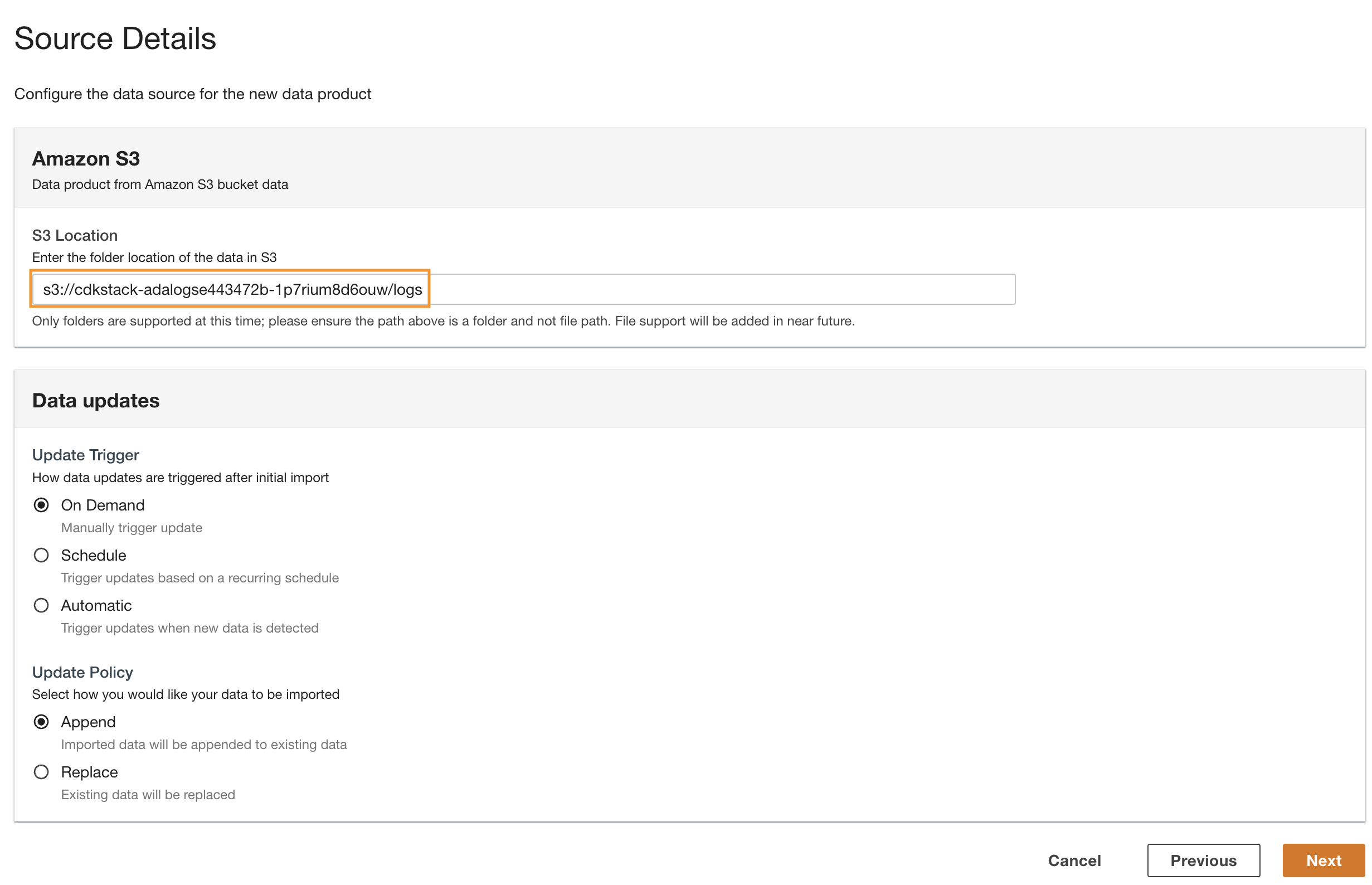
ADA 处理所选文件夹路径中文件的架构。由于日志采用 CSV 格式,因此 ADA 无需额外转换即可读取列名。但是,
状态代码
列 和
请求大小列由 ADA
推断为长类型。我们希望使数据产品之间的列数据类型保持一致,以便我们可以联接数据表并查询数据。列
状态代码 将
用于在数据表中创建联接。
- 选择 “ 转换架构 ” 将两列的数据类型更改为字符串数据类型。

在应用数据类型转换之前,请记下 “ 架构预览 ” 窗格中突出显示的列名。
- 在 转换计划 窗格的 内置转换 下 ,选择 应用映射 。
此选项允许您将数据类型从一种类型更改为另一种类型。
![]()
- 在 “ 应用映射 ” 部分中,取消选择 “ 删除其他字段” 。
如果未禁用此选项,则仅保留转换后的列,所有其他列将被删除。因为我们想保留所有列,所以我们禁用了这个选项。
-
在 “ 字段映射” 下的 “ 旧名称” 和 “ 新名称 ” 下 ,输入status_code,对于 新类型 ,输入字符串。

-
选择 “
添加项目”
。

- 对于 旧名称 和 新名称 ,输入 request_size,对于 新数据类型 ,输入字符串。
- 选择 “ 提交 ” 。
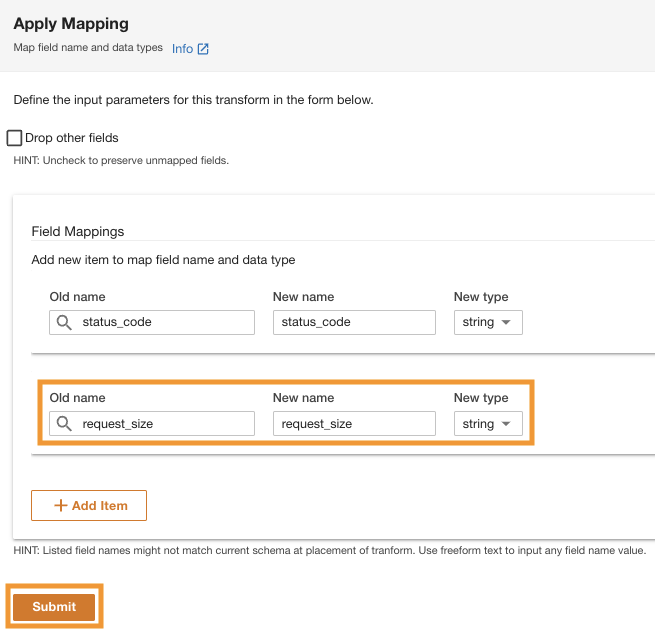
ADA 将在亚马逊 S3 数据源上应用映射转换。记下 “ 架构预览 ” 窗格中的列类型。
- 选择 “ 查看示例 ” 以预览应用转换的数据。

ADA 将显示 PII 数据确认,以确保只有授权用户才能查看数据,或者数据集不包含任何 PII 数据。
- 选择 “ 同意 ” 继续查看示例数据。

请注意,该架构与 CloudWatch 日志组架构相同,因为当前应用程序和历史应用程序日志均采用 Apache 日志格式。

- 在最后一步中,查看配置并选择 S ubmit 。

ADA 开始处理来自 Amazon S3 源的数据,创建后端基础设施并准备数据产品。此过程需要几分钟,具体取决于数据的大小。

创建 DynamoDB 数据产品
最后,我们创建了一个 DynamoDB 数据产品。完成以下步骤:
- 在 ADA 控制台上,创建新的数据产品。
-
输入名称(
查询),然后选择 亚马逊 DynamoDB 。
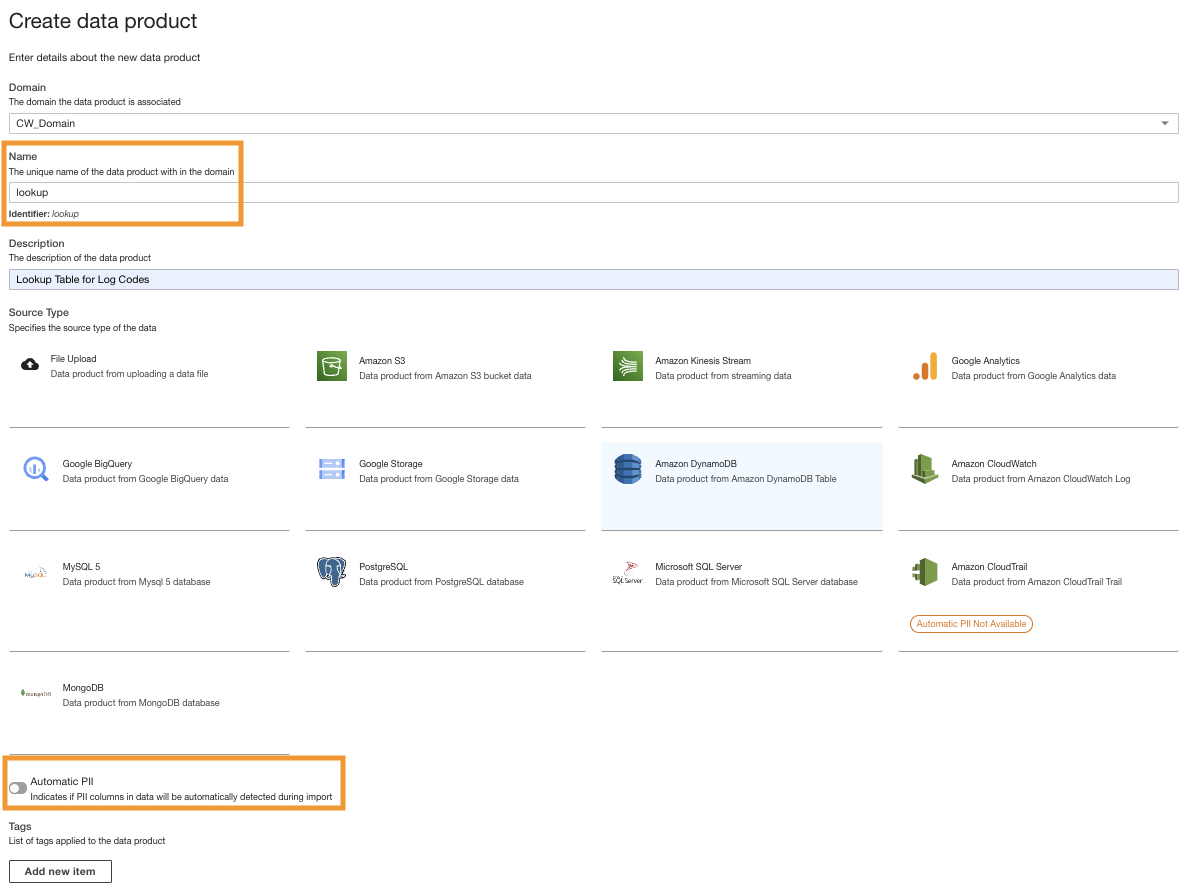
-
输入 DynamoDB 表 ARN 的
cdk.dynamodbtable 输出变量。
此表包含将在本演示中用作查找表的关键属性。对于查询数据,我们使用的是 HTTP 代码以及代码的长短描述。你也可以使用 PostgreSQL、MySQL 或 CSV 文件源作为替代方案。
- 对于 “ 更新触发器 ” ,选择 “ 按需 ” 。
更新将按需提供,因为查询时查询主要用于参考目的,查询数据的任何更新都可以使用按需触发器在 ADA 中更新。
- 选择 “ 下一步 ” 。
ADA 从底层 DynamoDB 架构中读取架构,并提供用于可选转换的列名和类型。我们将继续选择默认架构,因为列类型与 CloudWatch 日志组和 Amazon S3 CSV 数据源中的类型一致。通过在数据源中保持一致的数据类型,我们可以编写查询,通过使用列字段联接表来获取记录。例如,DynamoDB 架构 中的列
键
对应于亚马逊 S3 和 Cloud
Watch 数据产品 中的状态码
。我们可以使用列名
键
编写可以联接三个表的查询 。下一节将显示一个示例。
-
选择 “
继续使用当前架构”
。

- 查看配置并选择 提交 。
ADA 将处理来自 DynamoDB 表数据源的数据并准备数据产品。根据数据的大小,此过程需要几分钟。

现在,我们已经由 ADA 处理了所有三种数据产品,可供您运行查询。

使用查询工作台查询数据
ADA 允许您对数据产品运行查询,同时抽象数据源并使用 SQL(结构化查询语言)进行访问。您可以像查询关系数据库中的表一样编写查询和联接表。我们通过两个用户场景演示了 ADA 的查询能力。在这两种情况下,我们都会将应用程序日志数据集加入到错误代码查找表中。在第一个用例中,我们查询当前应用程序日志,以确定访问次数最多的前 10 个应用程序端点以及相应的 HTTP 状态码:
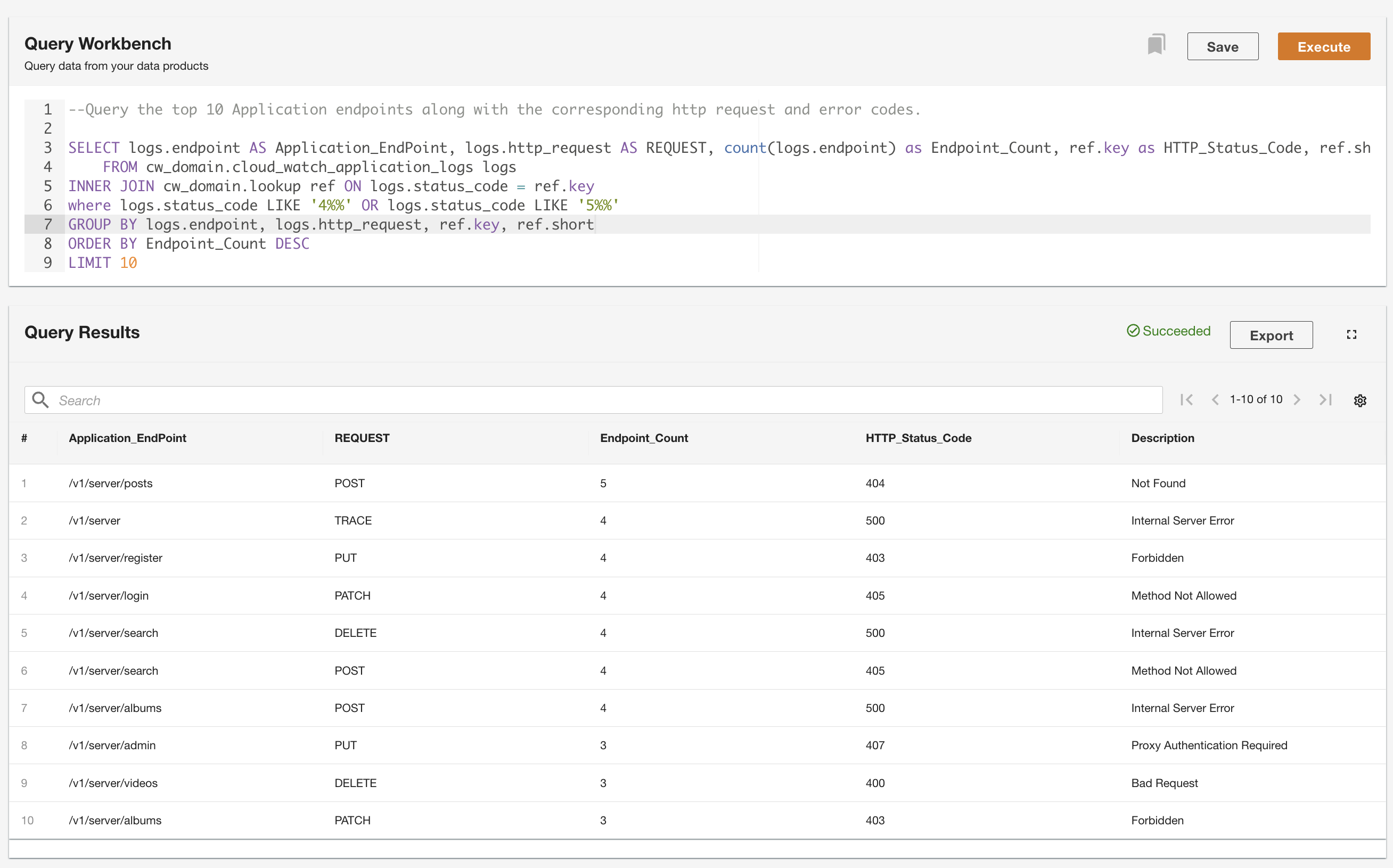
在第二个示例中,我们查询历史日志表以获取错误最多的前 10 个应用程序端点,以了解端点调用模式:
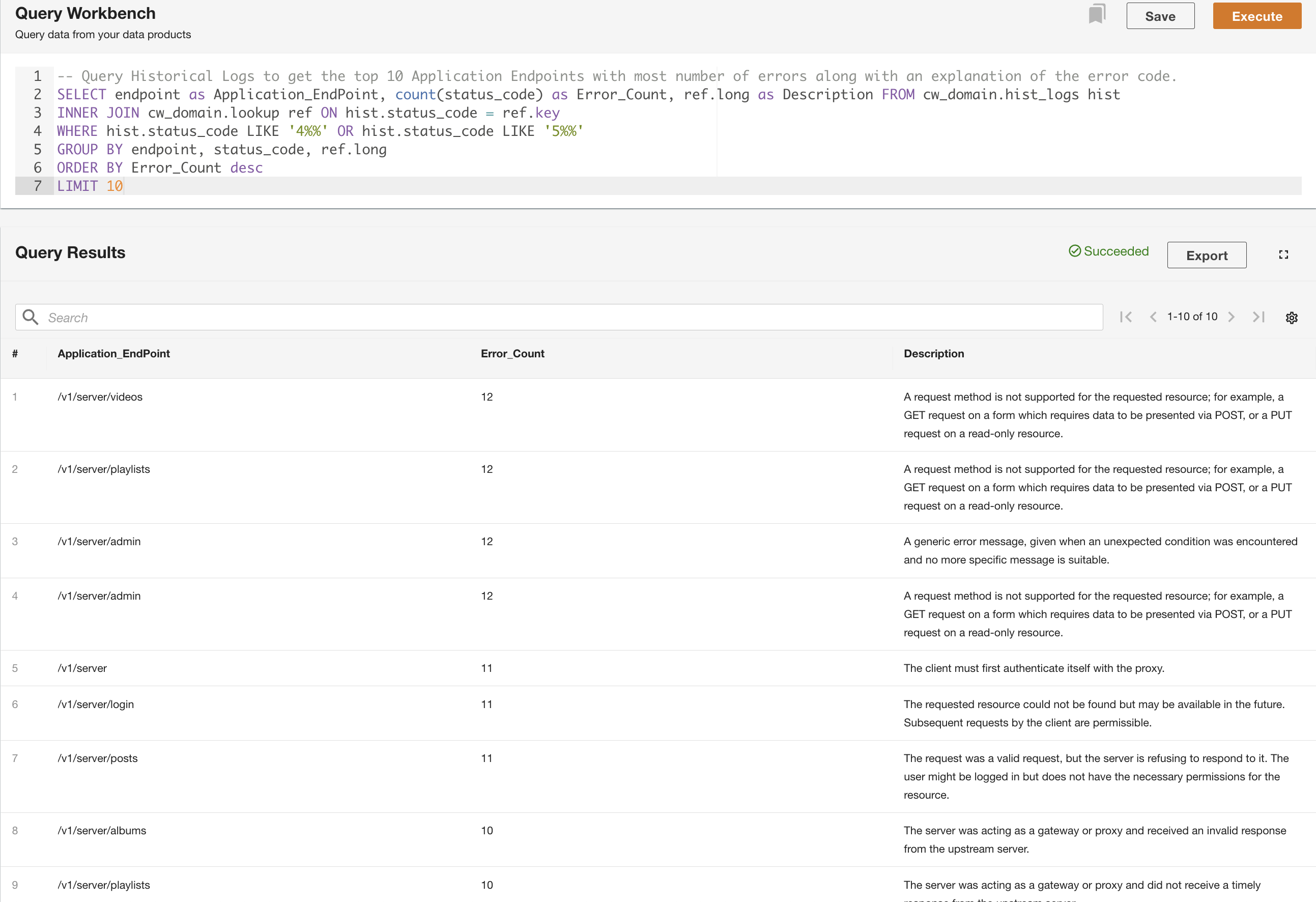
除查询外,您还可以选择保存查询并与同一域中的其他用户共享保存的查询。可以直接从查询工作台访问共享查询。查询结果也可以导出为 CSV 格式。
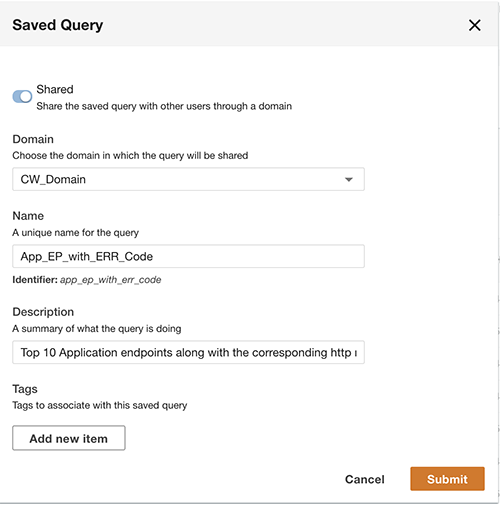
在 Tableau 中直观 ADA 数据产品
ADA 提供了
cw
_domain 下填充这三个数据产品。

然后,我们使用 HTTP 状态码作为联接列在三个数据库之间建立关系,如以下屏幕截图所示。Tableau 允许我们在在线和离线模式下使用数据源。在在线模式下,Tableau 将连接到 ADA 并实时查询数据产品。在离线模式下,我们可以使用 “ 提取 ” 选项从 ADA 中提取数据并将数据导入 Tableau。在此演示中,我们将数据导入 Tableau 以提高查询的响应速度。然后,我们保存 Tableau 工作簿。我们可以通过选择数据库和 立即 更新 来检查来自数据源的数据 。

利用 Tableau 中的数据源配置,我们可以在 ADA 数据产品上创建自定义报告、图表和可视化效果。让我们考虑两个可视化的用例。
如下图所示,我们使用 Tableau 的内置

我们还创建了一个条形图,以描述按照 HTTP 错误代码数量排序的历史日志中的应用程序端点。在此图表中,我们可以看到
/v1/server/admin
端点生成的 HTTP 错误状态代码最多。

清理
清理示例应用程序基础架构分为两个步骤。首先,要删除为此演示目的而配置的基础架构,请在终端中运行以下命令:
对于以下问题,输入 y,亚马逊云科技 CDK 将删除为演示部署的资源:
或者,您可以通过 亚马逊云科技 CloudFormation 控制台移除资源,方法是导航到 CDKStack 堆栈并选择 “删除”。
第二步是卸载 ADA。有关说明,请参阅
结论
在这篇文章中,我们演示了如何使用 ADA 解决方案从存储在两个不同数据源中的应用程序日志中获得见解。我们演示了如何在 亚马逊云科技 账户上安装 ADA 以及如何使用 亚马逊云科技 CDK 部署演示组件。我们在 ADA 中创建了数据产品,并使用 ADA 的内置数据连接器为数据产品配置了相应的数据源。我们演示了如何使用标准 SQL 查询数据产品并生成有关日志数据的见解。我们还将 Tableau Desktop 客户端(第三方 BI 产品)连接到 ADA,并演示了如何针对数据产品构建可视化。
ADA 可自动采集、转换、管理和查询不同数据集的过程,并简化数据的生命周期管理。ADA 的预建连接器允许您从不同的数据源提取数据。具有 亚马逊云科技 产品和服务基础知识的软件团队将能够在几个小时内建立一个运营数据分析平台,并提供对数据的安全访问。然后,可以使用直观的独立网络用户界面轻松快速地查询数据。
立即试用 ADA,轻松管理数据并从中获得见解。
作者简介
 Aparajithan Vaidyanathan 是 AW
S 的首席企业解决方案架构师。他支持企业客户在 亚马逊云科技 云上迁移工作负载并实现其现代化。他是一名云架构师,在设计和开发企业、大型和分布式软件系统方面拥有 23 年以上的经验。他专门研究机器学习和数据分析,专注于数据和特征工程领域。他是一名有抱负的马拉松运动员,他的爱好包括远足、骑自行车以及与妻子和两个男孩共度时光。
Aparajithan Vaidyanathan 是 AW
S 的首席企业解决方案架构师。他支持企业客户在 亚马逊云科技 云上迁移工作负载并实现其现代化。他是一名云架构师,在设计和开发企业、大型和分布式软件系统方面拥有 23 年以上的经验。他专门研究机器学习和数据分析,专注于数据和特征工程领域。他是一名有抱负的马拉松运动员,他的爱好包括远足、骑自行车以及与妻子和两个男孩共度时光。
![]() Rashim Rahman
是一名来自澳大利亚悉尼的软件开发人员,在软件开发和架构方面拥有 10 多年的经验。他主要致力于为常见的客户用例和业务问题构建大规模开源 亚马逊云科技 解决方案。在业余时间,他喜欢运动,喜欢与朋友和家人共度时光。
Rashim Rahman
是一名来自澳大利亚悉尼的软件开发人员,在软件开发和架构方面拥有 10 多年的经验。他主要致力于为常见的客户用例和业务问题构建大规模开源 亚马逊云科技 解决方案。在业余时间,他喜欢运动,喜欢与朋友和家人共度时光。
 哈菲兹·萨杜拉
是亚马逊网络服务的首席技术产品经理。Hafiz 专注于 亚马逊云科技 解决方案,旨在通过解决常见的业务问题和用例来帮助客户。
哈菲兹·萨杜拉
是亚马逊网络服务的首席技术产品经理。Hafiz 专注于 亚马逊云科技 解决方案,旨在通过解决常见的业务问题和用例来帮助客户。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。