我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用带有灾难恢复蓝图的跨区域只读副本部署多区域 Amazon RDS for SQL Server — 第 1 部分
灾难恢复和高可用性规划在确保业务运营的弹性和连续性方面起着至关重要的作用。在考虑 亚马逊云科技 上的灾难恢复策略时,有两个主要选项:区域内灾难恢复和跨区域灾难恢复。区域内灾难恢复和跨区域灾难恢复之间的选择取决于各种因素,包括应用程序和数据的重要性、监管要求、用户的地理分布、成本和复杂性。
要在 亚马逊云科技 上实施多区域灾难恢复解决方案,您必须首先确定基础设施的关键组件,并确定每个组件所需的恢复点目标 (RPO) 和恢复时间目标 (RTO)。RPO 是可接受的最大数据丢失量,RTO 是必须恢复系统之前可能经过的最大时间。
截至 2023 年 7 月,
在本系列中,我们重点关注需要在不同 亚马逊云科技 区域之间实现最佳可用性和灾难恢复的关键应用程序的需求。在第一篇文章中,我们将指导您完成为在两个 亚马逊云科技 地区使用
解决方案概述
该解决方案部署在两个 亚马逊云科技 区域,采用主动-被动策略,其中主(主动)区域托管工作负载并为流量提供服务。辅助(被动)区域用于灾难恢复。带有故障转移策略的 Amazon Route53 公共托管区域是为了在主要区域和次要区域之间路由互联网流量而创建的。Amazon Route 53 私有托管区域 CNAME 记录用于存储 SQL Server 端点的 RDS。应用程序使用这些记录连接到数据库。
下图说明了该架构的关键组件。
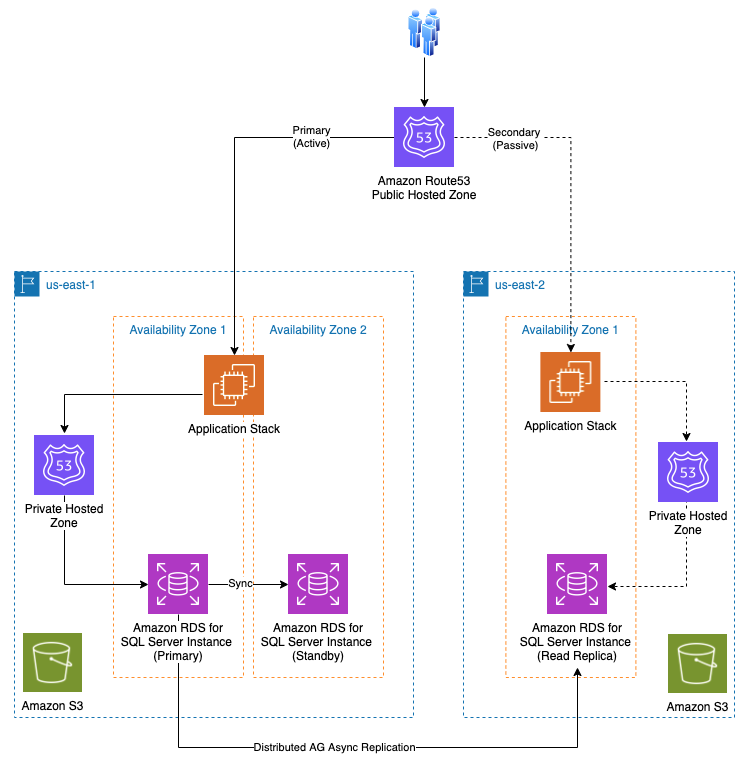
在我们的示例中,主 亚马逊云科技 区域被称为 us-east -1,次要 亚马逊云科技 区域被称为 us-east -2。 此外,请注意以下几点:
- 适用于 SQL Server 的 Amazon RDS 多可用区数据库实例部署在主 亚马逊云科技 区域,跨区域只读副本部署在辅助区域。
-
适用于 SQL Server 的 Amazon RDS 使用
分布式 可用性组配置跨区域只读副本(异步复制)。 - 应用程序堆栈部署在两个区域中并保持相同的发行版本。
-
为互联网流量提供服务的
Amazon Route53 公共托管区域 配置了 “故障转移”路由 策略。 -
Amazon Route53 私有托管区域 配置了 “简单” 路由策略,用于应用程序到 RDS 进行 SQL Server 实例连接。
待机接管主机
例如,如果您在 AWS 区域
us-east-2 中有一个名为 e
xamplebucket123
的亚马逊 S3 存储桶, 并且文件名为 in itiate_fa
ilover.dr
,则访问此 S3 文件的相应终端节点将是:https://examplebucket123.s3.us-east-2.amazonaws.com/initiate_failover.dr
当从指定终端节点收到的 HTTP 响应返回 4xx 或 5xx 的状态代码时,此运行状况检查被视为运行正常(这意味着,Route 53 运行状况检查代理无法解析该 Amazon S3 文件终端节点)。相反,如果响应返回 2xx 或 3xx 的状态码,则运行状况检查失败(这意味着,Route 53 运行状况检查代理能够解析 Amazon S3 文件终端节点)。这种方法被称为 Route53
请务必注意,不建议将互联网流量自动转移到辅助区域。在诸如主区域短暂的网络故障之类的情况下,自动故障转移可能会导致更长的停机时间。
先决条件
要实现此解决方案,您需要满足以下条件:
- 主要区域中的应用程序堆栈和适用于 SQL Server 的亚马逊 RDS 多可用区实例。
-
辅助区域中的应用程序堆栈和适用于 SQL Server 的 Amazon RDS 只读副本实例(交叉复制)。有关说明,请参阅将
跨区域只读副本与适用于 SQL Server 的亚马逊关系数据库服务一起 使用 。 -
创建只读副本后在主数据库实例中创建的任何服务器级对象(例如登录、SQL 代理作业等)都不会自动复制,您必须在只读副本中手动创建它们。因此,请确保这些对象在主要区域和次要区域之间保持同步。有关更多详细信息,请参阅
Amazon RDS 文档 。
草率排练
要部署此解决方案,请完成以下步骤:
-
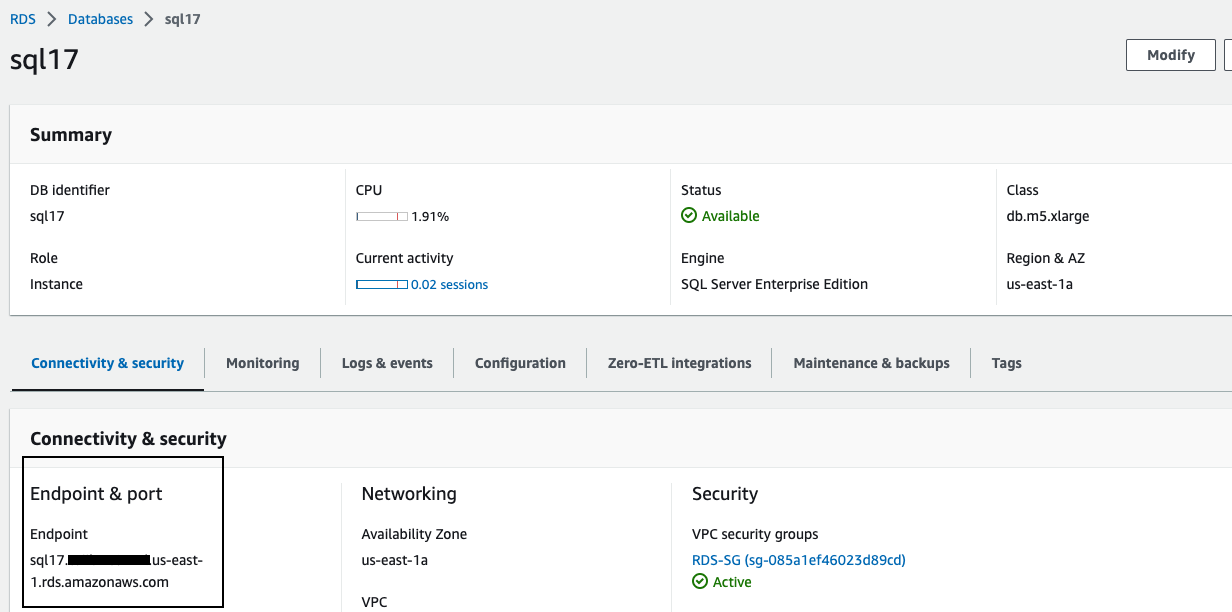
导航到主要区域的
亚马逊关系数据库服务 (RDS) 控制台 。 -
捕获 SQL Server 主要 RDS 实例的终端节点。
-
同样,导航到
次要区域中的 Amazon RDS 控制台 。 - 捕获 RDS for SQL Server 的端点跨区域只读副本。
-
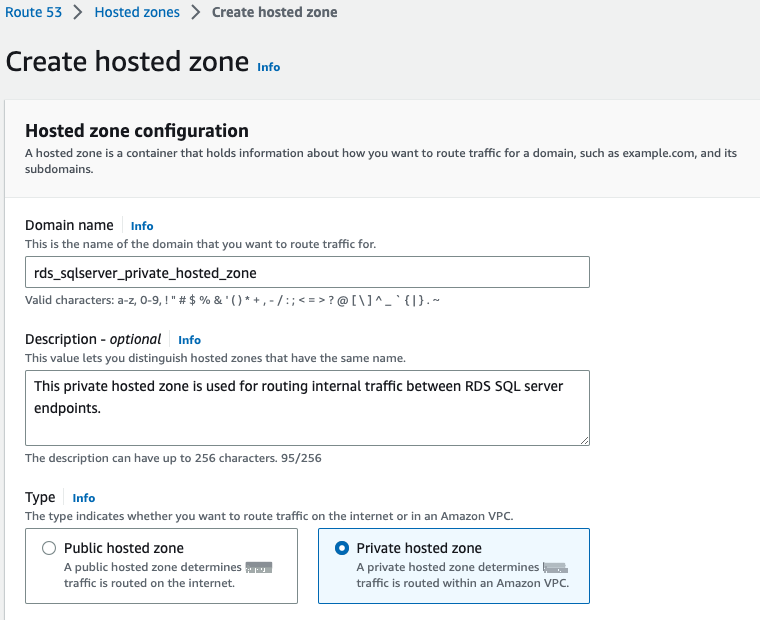
导航到
亚马逊 Route53 控制台 。 -
创建 新的私有托管区域 。
-
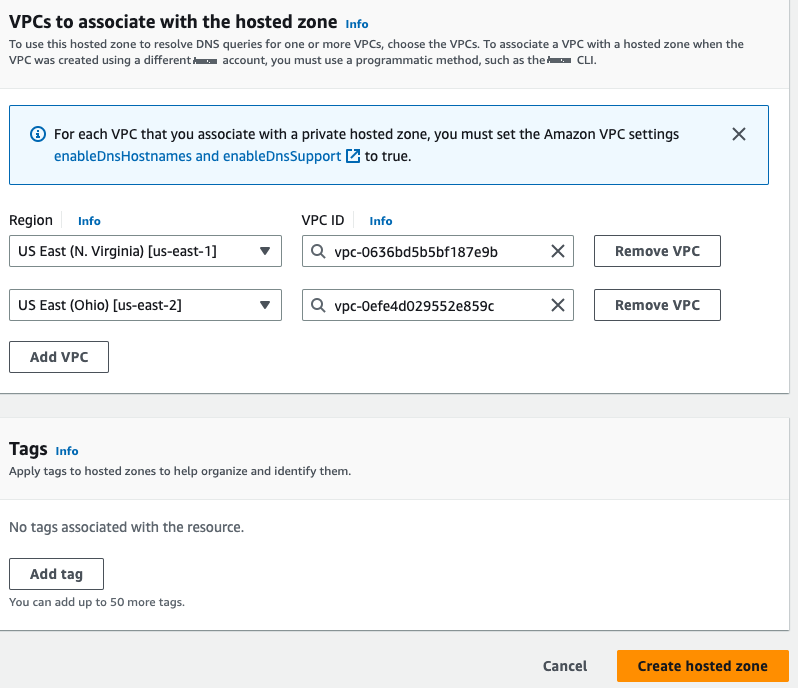
将两个区域的 VPC 关联到私有托管区域。这是必要的,因为私有托管区域在 Amazon VPC 内路由流量。
-
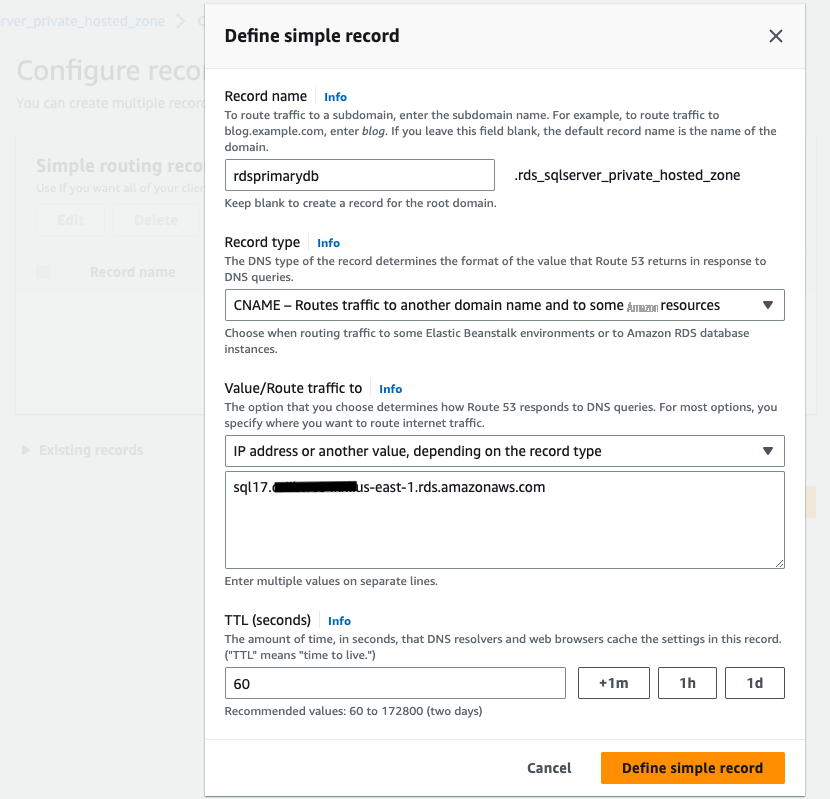
创建私有托管区域后,使用
简单的路由策略 添加两个 CNAME 记录。在我们的示例中,我们创建了以下 CNAME 记录:-
rdsprimarydb.rds_sqlserver_private_hosted_zone — 在主区域连接到 RDS for SQL Server。 -
rdssecondarydb.rds_sqlserver_private_hosted_zone — 连接到 RDS for SQLServer 跨区域只读副本。
-
-
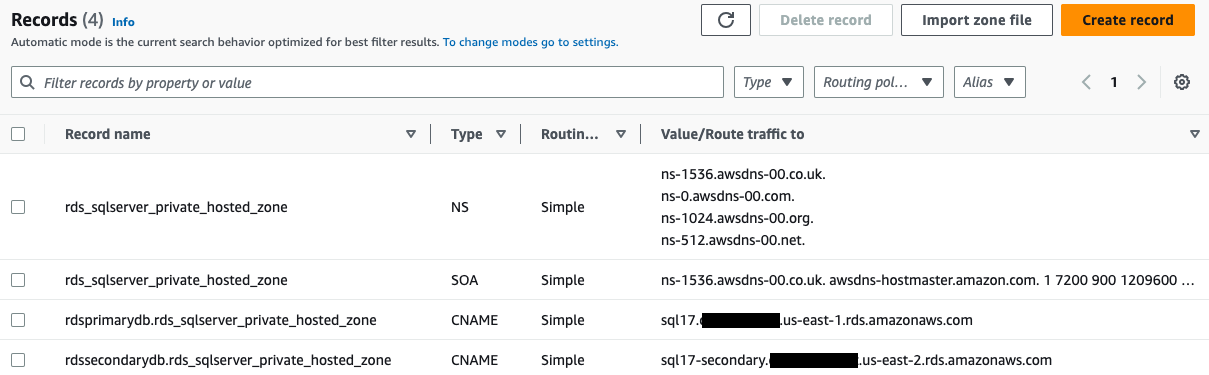
添加两个 CNAME 记录后,私有托管区域应如下屏幕截图所示。
-
在主区域更新您的应用程序配置,并在数据库连接字符串中使用 CNAME 记录
rdsprimarydb.rds_sqlserver_private_hosted_zone作为数据库主机名。 -
同样,使用 CNAME 记录
rdssecondarydb.rds_sqlserver_private_hosted_zone 更新辅助区域中的应用程序。此步骤可确保应用程序不直接使用 RDS 端点。因此,在故障转移期间,不需要更改应用程序。
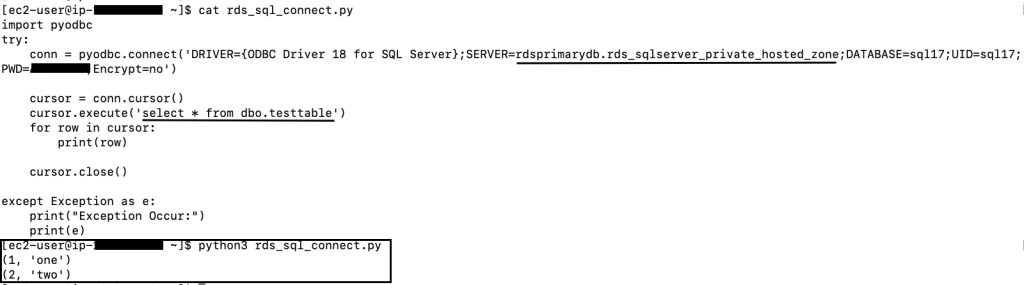
以下 python 代码是使用私有托管区域 CNAME 记录连接到 RDS for SQL Server 实例的示例代码:

- 在主要和次要区域创建新的 Amazon S3 存储桶。这些 S3 存储桶专用于托管灾难恢复文件。为了确保运行状况检查过程的安全性和完整性,必须仅限授权人员访问此存储桶。此时,当主要区域和次要区域都处于正常状态时,您可以将这些存储桶留空。
-
导航到
Amazon Route53 控制台 并创建Route53 公共托管区域 来管理您的公有域的互联网流量。
-
创建公共托管区域后,导航到
Amazon Route53 运行状况检查控制台 。 -
创建两个新的 Route53 运行状况检查,一个用于主区域故障转移,另一个用于辅助区域故障转移。这些运行状况检查将附加到主要和次要区域的故障转移记录。
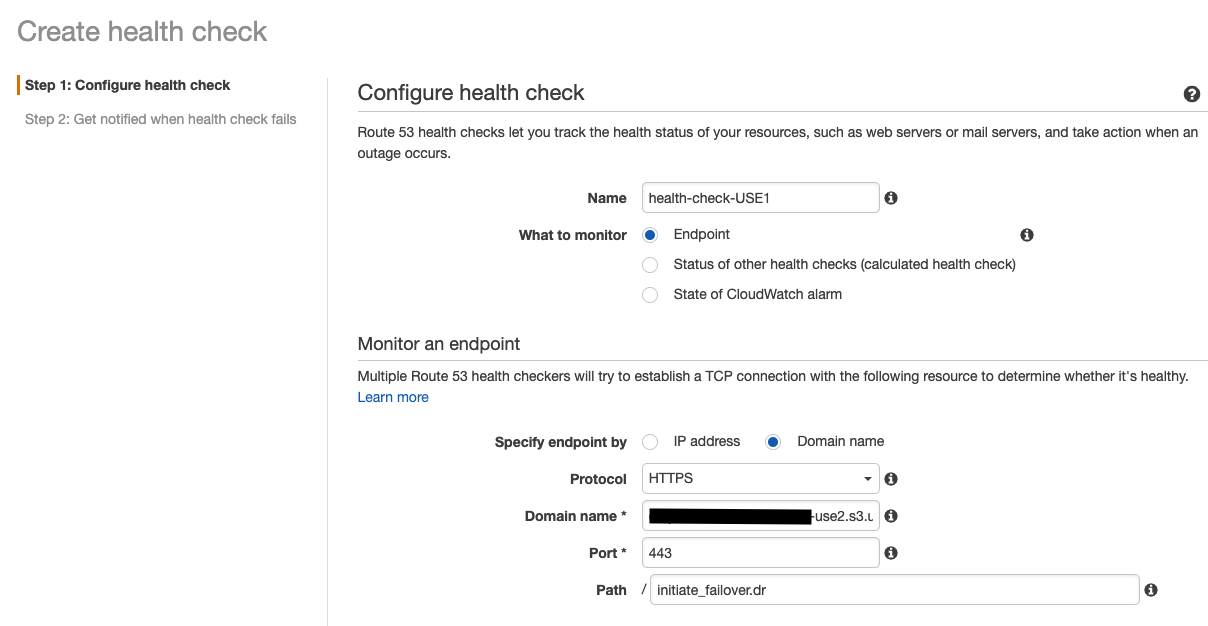
-
在创建运行状况检查页面上,
- 输入主要区域的运行状况检查名称。
- 然后为要监控的内容 选择 “ 端点 ” 选项。
- 在 监控器和端点 部分中,选择 域名 和协议 HTTPS 。
-
在域名下,指定辅助区域的 Amazon S3 存储桶终端节点。
例如:examplebucket123。s3.us-east-2.amazonaws.com -
在 “路径” 下,指定灾难恢复文件名。例如:in
itiate_failover.dr 在高级 配置部分 -
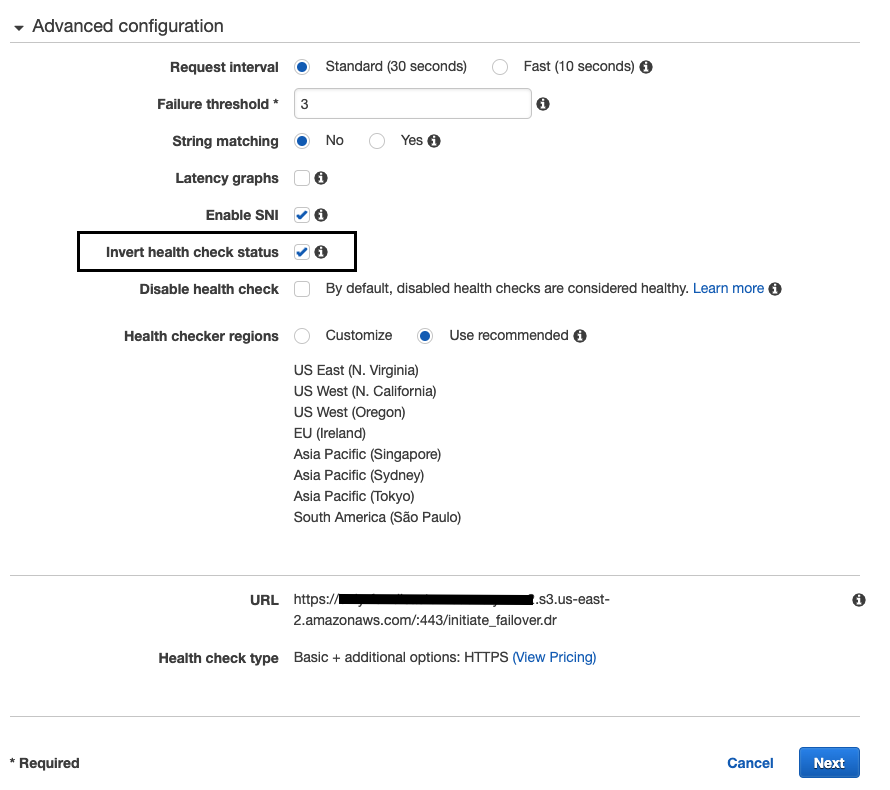
指定
故障转移阈值 和请求 间隔。 -
选中 “
反转运行状况检查状态 ” 选项,然后点击下一步。 - 提交 创建运行状况检查 。
重复相同的步骤,为辅助区域创建运行状况检查记录。
对于主区域运行状况检查,请指定来自辅助区域的 S3 文件终端节点,反之亦然。如果主区域变得不可访问,您将能够修改辅助区域中的 S3 文件并启动故障转移。 -
为主要和次要区域创建运行状况检查后,Amazon Route53 将启动运行状况检查并报告状态。

-
导航到在步骤 13 中 创建的
Route53 公共托管区域 并完成以下步骤:-
使用
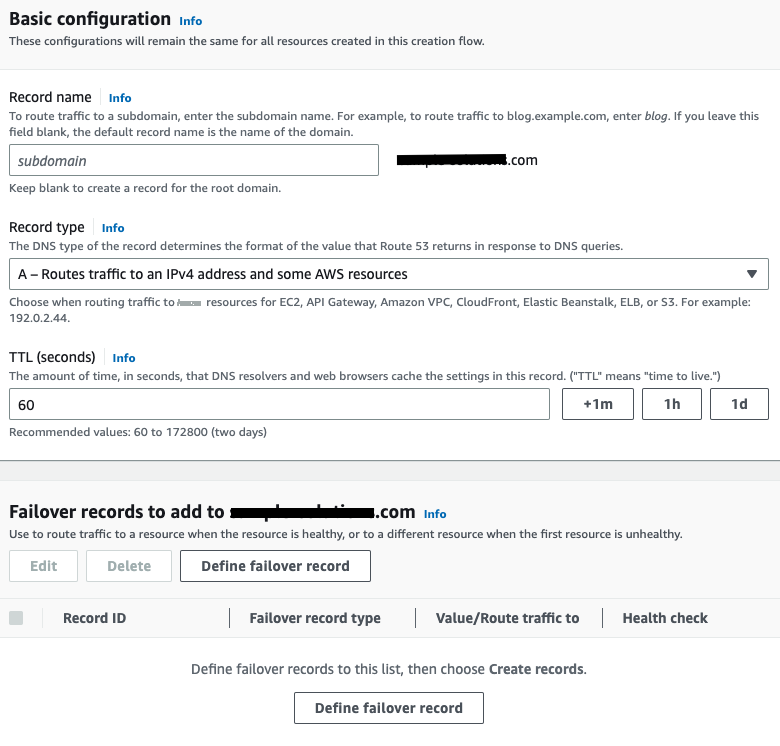
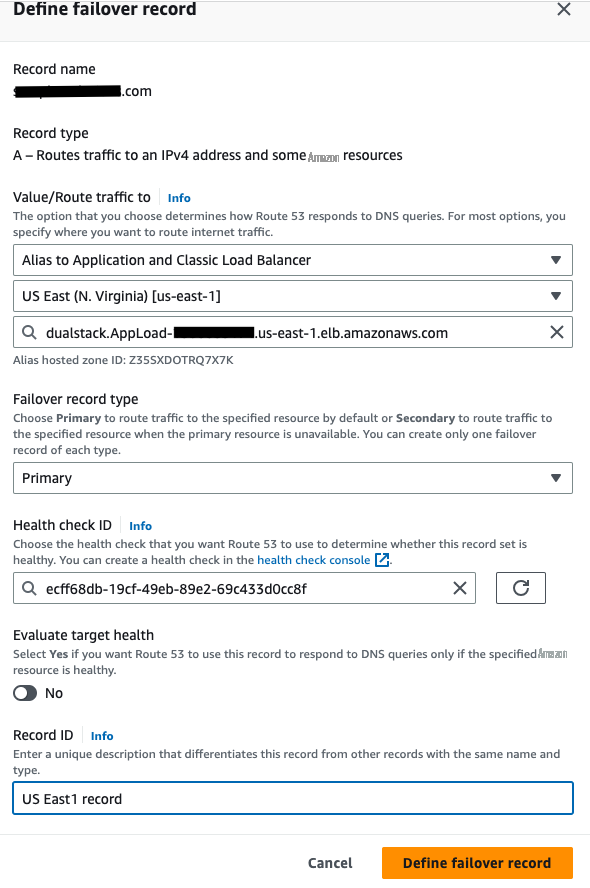
故障转移路由 策略 创建记录 。 - 单击 “ 定义故障转移记录 ” 。
- 将此记录与应用程序目标相关联。例如,Route53 支持应用程序负载均衡器、API 网关、VPC 终端节点或 S3 终端节点等。在此示例中,选择了应用程序负载平衡目标。
- 选择主要区域。
- 选择目标负载均衡器。
- 将故障转移记录类型指定为 主 记录类型 。
- 选择为主要区域创建的运行状况检查记录。
- 禁用 “评估目标生命值” 选项。
-
使用
-
提交
- 重复类似的步骤,为次要记录类型创建另一条记录。
公共托管区域配置完成后,应如下屏幕截图所示:
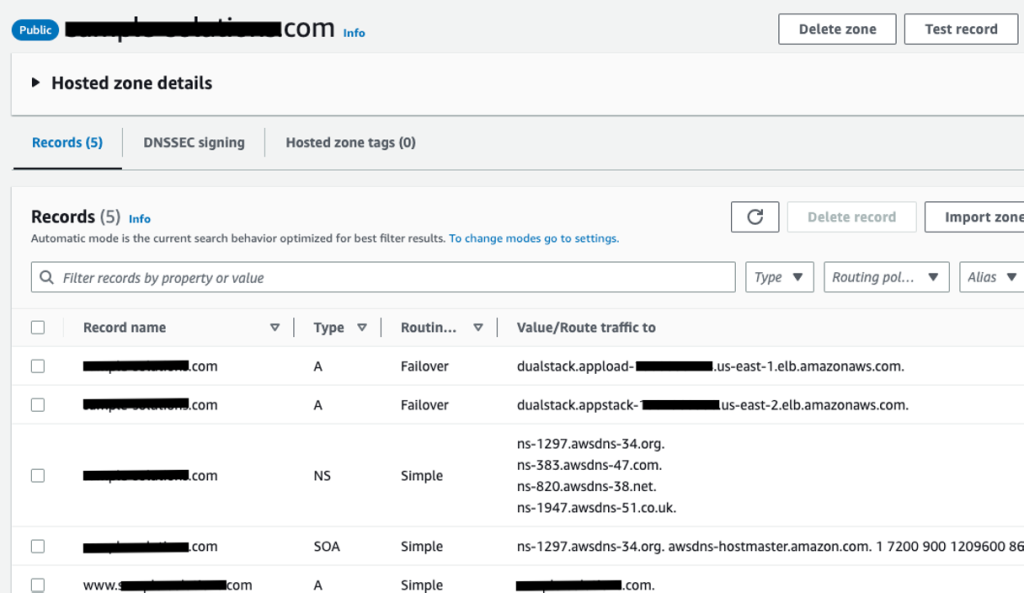
至此,使用亚马逊 Route53、亚马逊 S3 和适用于 SQL Server 的亚马逊 RDS 完成了灾难恢复蓝图的部署。此时,您应该能够通过互联网流量访问您的应用程序。

清理
在本系列的下一篇文章中,我们将使用此蓝图并向您展示如何执行跨区域故障转移。因此,如果您计划继续,请保留在此部署下创建的所有资源。
要删除为实施此解决方案而创建的资源,请完成以下步骤:
- 删除您创建的公有和私有托管区域。
- 将应用程序配置更改为其原始状态。
- 删除您创建的 Amazon S3 存储桶。
摘要
在这篇文章中,我们提供了有关如何实施跨区域灾难恢复蓝图的指导。Amazon Route53 公共托管区域策略中的 “备用接管主区域” 方法使组织能够保持对故障转移过程的控制,并在无法访问主区域时手动启动故障转移。
在本系列 的
如果您有任何评论或反馈,请将其留在评论部分。
作者简介
 Ravi Mathur
是 亚马逊云科技 的高级解决方案架构师。他与客户合作,为各种 亚马逊云科技 服务提供技术援助和架构指导。他在各种大型企业的软件工程和架构领域拥有多年的经验。
Ravi Mathur
是 亚马逊云科技 的高级解决方案架构师。他与客户合作,为各种 亚马逊云科技 服务提供技术援助和架构指导。他在各种大型企业的软件工程和架构领域拥有多年的经验。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。