我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用大型模型推断容器在 亚马逊云科技 Inferentia2 上部署大型语言模型
你不必是机器学习 (ML) 方面的专家就能体会到大型语言模型 (LLM) 的价值。更好的搜索结果、视障人士的图像识别、利用文本创建新颖的设计以及智能聊天机器人只是这些模型如何促进各种应用程序和任务的一些例子。
机器学习从业者不断提高这些模型的准确性和功能。结果,这些模型的规模扩大,推广效果更好,例如在变压器模型的演变中。我们在之前的一
在这篇文章中,我们采用了同样的方法,但将模型托管在
三大支柱
下图代表了硬件和软件的各个层面,它们可以帮助您解锁大型语言模型的最佳价格和性能。亚马逊云科技 Neuron 和
是用于在 亚马逊云科技 Inferentia 上运行深度学习工作负载的软件开发工具包。最后,DjlServing 是集成在容器中的服务解决方案。
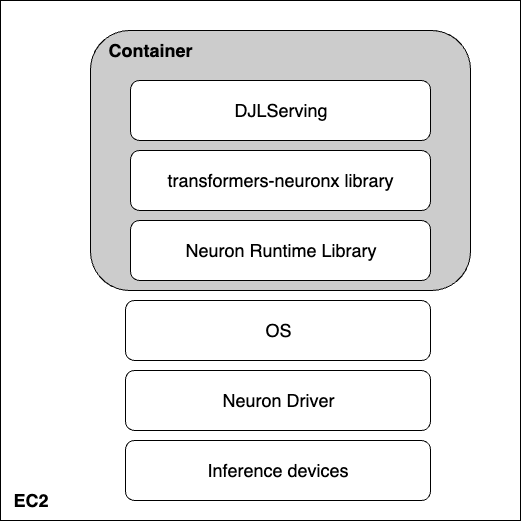
硬件:推论
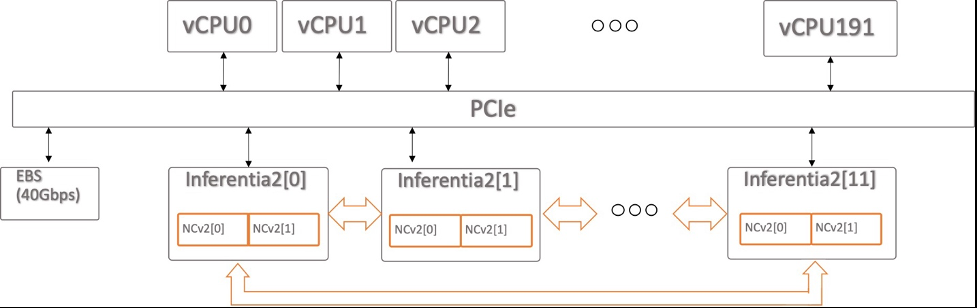
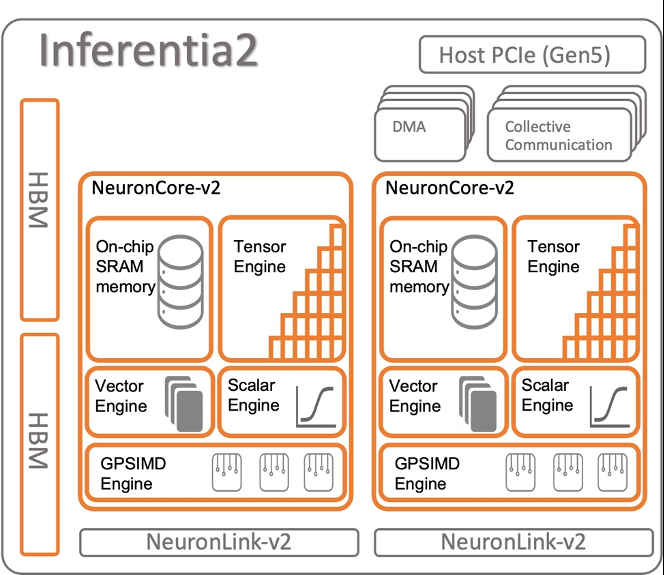
亚马逊云科技 Inferentia 专为 亚马逊云科技 推理而设计,是一款高性能、低成本的机器学习推理加速器。在这篇文章中,我们使用了第二代专门构建的机器学习推理加速器 亚马逊云科技 Inferentia2(可通过 Inf2 实例获得)。
这可以有效地在 亚马逊云科技 Inferentia2 设备上对模型进行分片(例如通过 Tensor Parallelism),从而优化延迟和吞吐量。这对于大型语言模型特别有用。有关基准性能数据,请参阅 亚马逊云科技
亚马逊 EC2 Inf2 支持 NeuronLink v2,这是一种低延迟、高带宽的芯片间互连,可实现 AllReduce 和 AllGather 等高性能集体通信操作。
神经元和变形金刚-神经元
硬件层之上是用于与 亚马逊云科技 Inferentia 交互的软件层。亚马逊云科技 Neuron 是用于在 亚马逊云科技 Inferentia 和 亚马逊云科技 T
transform@@
ers-neuronx
是一个由 亚马逊云科技 Neuron 团队 构建的开源
之所以需要张量并行性,是因为模型非常大,无法放入单个加速器 HBM 内存中。
Transform
以下是为 亚马逊云科技 Neuron 优化的变压器解码器模型设置张量并行度(参与分片矩阵乘法运算的 NeuronCore 数量)的一些原则:
ers-neuronx 中的 AWS Neuron 运行时对张量并行性的
支持大量使用了 allReduce 等集体 操作。
- 注意力的数量需要被张量并行度整除
- 模型权重和键值缓存的总数据大小必须小于张量并行度的 16 GB
-
目前,Neuron 运行时在 T
rn 1 上支持 1、2、8 和 32 度的张量并行度,在 Inf2 上支持张量并行度 1、2、4、8 和 24
djlServing
DjlServing 是一款高性能模型服务器,于 2023 年 3 月增加了对 亚马逊云科技 Inferentia2 的支持。亚马逊云科技 模型服务器团队提供了一个
DJL 也是 Rubikon 对 Neuron 的支持的一部分,其中包括 djlServing 和 transformers-neuronx 之间的集成。
djlServing 模型服务器和 transfor
mers-neuronx 库是容器的核心组件,旨在为变形
金刚库支持的 LLM 提供服务。该容器和后续的 DLC 将能够在亚马逊 EC2 Inf2 主机上的 亚马逊云科技 Inferentia 芯片上加载模型以及已安装的 亚马逊云科技inferentia 驱动程序和工具包。在这篇文章中,我们解释了两种运行容器的方式。
第一种方法是在不编写任何额外代码的情况下运行容器。您可以使用
engine=Python
option.entryPoint=djl_python.transformers_neuronx
option.task=text-generation
option.model_id=facebook/opt-1.3b
option.tensor_parallel_degree=2
或者,你可以自己编写
您还可以在s
文件,但这需要实现模型加载和推理方法,以充当 DjlServing API 与 transformers-neuronx API 之间的桥梁,在本例中为 transformers-neuronx API。
erving.proper
ties 文件中提供可配置的参数,以便在模型加载期间获取。有关可配置参数的完整列表,请参阅
以下代码是一个
model.py
文件示例。s
erving.prop
erti es 文件与前面显示的文件类似。
def load_model(properties):
"""
Load a model based from the framework provided APIs
:param: properties configurable properties for model loading
specified in serving.properties
:return: model and other artifacts required for inference
"""
batch_size = int(properties.get("batch_size", 2))
tp_degree = int(properties.get("tensor_parallel_degree", 2))
amp = properties.get("dtype", "f16")
model_id = "facebook/opt-13b"
model = OPTForCausalLM.from_pretrained(model_id, low_cpu_mem_usage=True)
...
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = OPTForSampling.from_pretrained(load_path,
batch_size=batch_size,
amp=amp,
tp_degree=tp_degree)
model.to_neuron()
return model, tokenizer, batch_size
让我们看看在 Inf2 实例上这一切是什么样子。
启动推理硬件
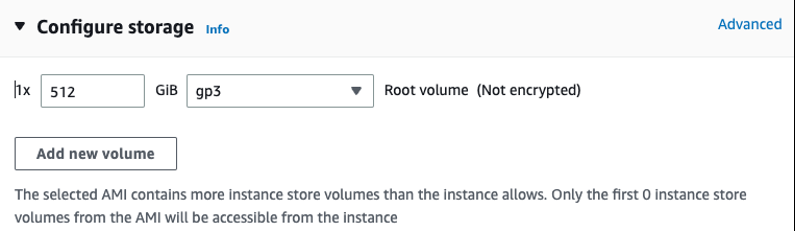
我们首先需要启动一个 inf.42xlarge 实例来托管我们的 OPT-13b 模型。我们使用
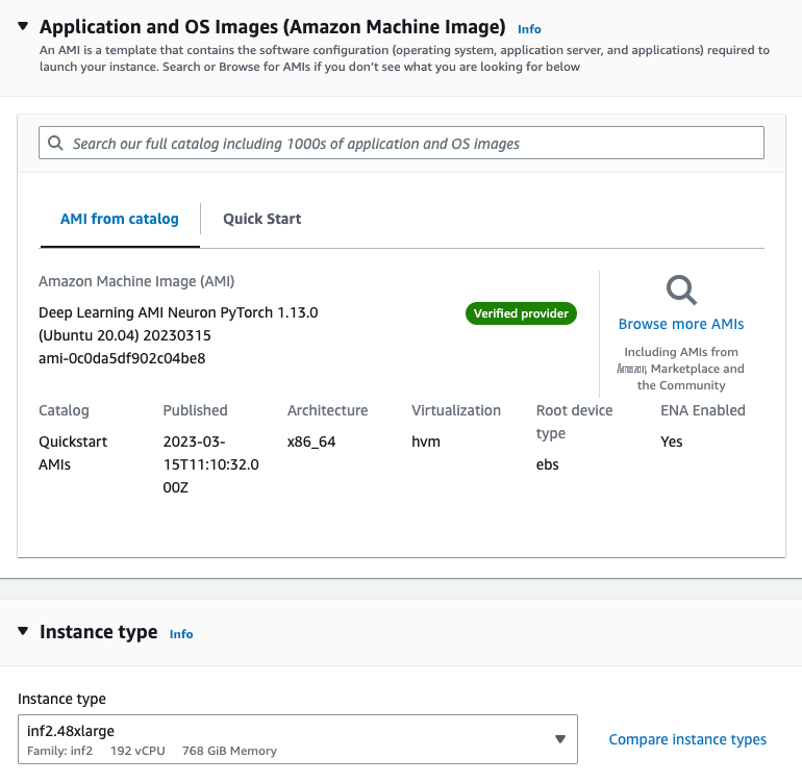
我们将实例的存储空间增加到 512 GB,以适应大型语言模型。
安装必要的依赖关系并创建模型
我们 使用我们的 AMI
日志
和
模型
设置子目录 并创建一个 s
erving.proper
ties 文件。
我们可以使用
erving.proper
ties文件。参见以下代码:
option.model_id=facebook/opt-1.3b
option.batch_size=2
option.tensor_parallel_degree=2
option.n_positions=256
option.dtype=fp16
option.model_loading_timeout=600
engine=Python
option.entryPoint=djl_python.transformers-neuronx
#option.s3url=s3://djl-llm/opt-1.3b/
#can also specify which device to load on.
#engine=Python ---because the handles are implement in python.
这指示 DJL 模型服务器使用 OPT-13B 模型。我们将批量大小设置为 2 并且
dtype=f16
以使模型适合神经元设备。DJL 服务支持动态批处理,通过设置相似的
tensor_parallel_
degree 值,我们可以提高推理请求的吞吐量,因为我们将推理分布在多个 NeuronCore 上。我们还设置了
n_positions=256
, 因为这会告知我们期望模型的最大长度。
我们的实例有 12 台 亚马逊云科技 Neuron 设备或 24 台 NeuronCore,而我们的 OPT-13B 模型需要 40 个注意力。例如,设置
tensor_parallel_degree=8 意味着每 8 个 Ne
uronCore 将托管一个模型实例。如果将所需的注意力标记 (40) 除以 NeuronCore 的数量 (8),则每台 NeuronCore 会分配 5 个注意力标头,或者在每台 亚马逊云科技 Neuron 设备上分配 10 个注意力标头。
您可以使用以下示例
model.py
文件,该文件定义了模型并创建了处理函数。你可以对其进行编辑以满足你的需求,但请确保 transfor
mer
s-neuronx 可以支持它。
cat serving.propertiesoption.tensor_parallel_degree=2
option.batch_size=2
option.dtype=f16
engine=Pythoncat model.pyimport torch
import tempfile
import os
from transformers.models.opt import OPTForCausalLM
from transformers import AutoTokenizer
from transformers_neuronx import dtypes
from transformers_neuronx.module import save_pretrained_split
from transformers_neuronx.opt.model import OPTForSampling
from djl_python import Input, Output
model = None
def load_model(properties):
batch_size = int(properties.get("batch_size", 2))
tp_degree = int(properties.get("tensor_parallel_degree", 2))
amp = properties.get("dtype", "f16")
model_id = "facebook/opt-13b"
load_path = os.path.join(tempfile.gettempdir(), model_id)
model = OPTForCausalLM.from_pretrained(model_id,
low_cpu_mem_usage=True)
dtype = dtypes.to_torch_dtype(amp)
for block in model.model.decoder.layers:
block.self_attn.to(dtype)
block.fc1.to(dtype)
block.fc2.to(dtype)
model.lm_head.to(dtype)
save_pretrained_split(model, load_path)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = OPTForSampling.from_pretrained(load_path,
batch_size=batch_size,
amp=amp,
tp_degree=tp_degree)
model.to_neuron()
return model, tokenizer, batch_size
def infer(seq_length, prompt):
with torch.inference_mode():
input_ids = torch.as_tensor([tokenizer.encode(text) for text in prompt])
generated_sequence = model.sample(input_ids,
sequence_length=seq_length)
outputs = [tokenizer.decode(gen_seq) for gen_seq in generated_sequence]
return outputs
def handle(inputs: Input):
global model, tokenizer, batch_size
if not model:
model, tokenizer, batch_size = load_model(inputs.get_properties())
if inputs.is_empty():
# Model server makes an empty call to warmup the model on startup
return None
data = inputs.get_as_json()
seq_length = data["seq_length"]
prompt = data["text"]
outputs = infer(seq_length, prompt)
result = {"outputs": outputs}
return Output().add_as_json(result)
mkdir -p models/opt13b logs
mv serving.properties model.py models/opt13b
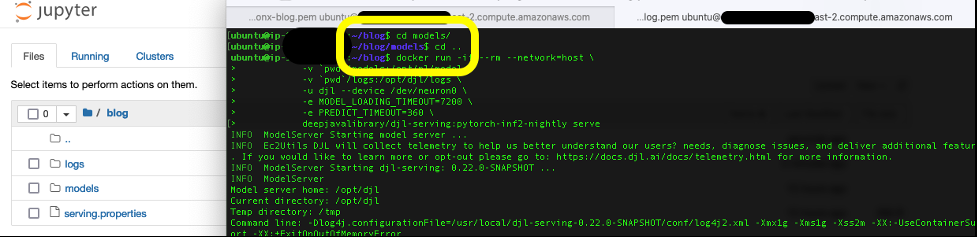
运行服务容器
推理之前的最后一步是提取 DJL 服务容器的 Docker 镜像并在我们的实例上运行它:
docker pull deepjavalibrary/djl-serving:0.22.0-pytorch-inf2
提取容器镜像后,运行以下命令来部署模型。确保您位于包含
日志
和
模型
子目录的正确目录中,因为该命令会将它们映射到容器的
/op
t/ 目录。
docker run -it --rm --network=host \
-v `pwd`/models:/opt/ml/model \
-v `pwd`/logs:/opt/djl/logs \
-u djl --device /dev/neuron0 --device /dev/neuron10 --device /dev/neuron2 --device /dev/neuron4 --device /dev/neuron6 --device /dev/neuron8 --device /dev/neuron1 --device /dev/neuron11 \
-e MODEL_LOADING_TIMEOUT=7200 \
-e PREDICT_TIMEOUT=360 \
deepjavalibrary/djl-serving:0.21.0-pytorch-inf2 serve
运行推断
现在我们已经部署了模型,让我们用一个简单的 CURL 命令对其进行测试,将一些 JSON 数据传递到我们的端点。因为我们将批量大小设置为 2,所以我们传递了相应数量的输入:
curl -X POST "http://127.0.0.1:8080/predictions/opt13b" \
-H 'Content-Type: application/json' \
-d '{"seq_length":2048,
"text":[
"Hello, I am a language model,",
"Welcome to Amazon Elastic Compute Cloud,"
]
}'

前面的命令在命令行中生成响应。这个模型很健谈,但它的反应证实了我们的模型。多亏了推理,我们才能够对我们的法学硕士进行推断!
清理
完成后不要忘记删除您的 EC2 实例,以节省成本。
结论
在这篇文章中,我们部署了一个 Amazon EC2 Inf2 实例来托管 LLM,并使用大型模型推断容器进行了推断。您了解了 亚马逊云科技 Inferentia 和 亚马逊云科技 Neuron SDK 如何相互作用,使您能够以最佳的性价比轻松部署 LLM 进行推断。请继续关注 Inferentia 的更多功能和新创新的更新。有关神经元的更多示例,请参阅
作者简介
 李庆伟
是亚马逊网络服务的机器学习专家。在他破坏了顾问的研究补助金账户并未能兑现他所承诺的诺贝尔奖之后,他获得了运筹学博士学位。目前,他帮助金融服务和保险行业的客户在 亚马逊云科技 上构建机器学习解决方案。在业余时间,他喜欢阅读和教学。
李庆伟
是亚马逊网络服务的机器学习专家。在他破坏了顾问的研究补助金账户并未能兑现他所承诺的诺贝尔奖之后,他获得了运筹学博士学位。目前,他帮助金融服务和保险行业的客户在 亚马逊云科技 上构建机器学习解决方案。在业余时间,他喜欢阅读和教学。
 Peter Chung
是 亚马逊云科技 的解决方案架构师,热衷于帮助客户从他们的数据中发现见解。他一直在构建解决方案,以帮助公共和私营部门中的组织做出以数据为导向的决策。他拥有所有 亚马逊云科技 认证以及两个 GCP 认证。他喜欢喝咖啡、做饭、保持活跃以及与家人共度时光。
Peter Chung
是 亚马逊云科技 的解决方案架构师,热衷于帮助客户从他们的数据中发现见解。他一直在构建解决方案,以帮助公共和私营部门中的组织做出以数据为导向的决策。他拥有所有 亚马逊云科技 认证以及两个 GCP 认证。他喜欢喝咖啡、做饭、保持活跃以及与家人共度时光。
 Aaqib Ansari 是亚马逊
SageMaker Inference 团队的软件开发工程师。他专注于帮助 SageMaker 客户加快模型推断和部署。在业余时间,他喜欢远足、跑步、摄影和素描。
Aaqib Ansari 是亚马逊
SageMaker Inference 团队的软件开发工程师。他专注于帮助 SageMaker 客户加快模型推断和部署。在业余时间,他喜欢远足、跑步、摄影和素描。
 蓝青
是 亚马逊云科技 的软件开发工程师。他一直在亚马逊开发多款具有挑战性的产品,包括高性能机器学习推理解决方案和高性能记录系统。Qing的团队成功地在亚马逊广告中推出了第一个十亿参数模型,所需的延迟非常低。Qing 对基础设施优化和深度学习加速有深入的了解。
蓝青
是 亚马逊云科技 的软件开发工程师。他一直在亚马逊开发多款具有挑战性的产品,包括高性能机器学习推理解决方案和高性能记录系统。Qing的团队成功地在亚马逊广告中推出了第一个十亿参数模型,所需的延迟非常低。Qing 对基础设施优化和深度学习加速有深入的了解。
 Frank Liu
是 亚马逊云科技 深度学习的软件工程师。他专注于为软件工程师和科学家开发创新的深度学习工具。在业余时间,他喜欢与朋友和家人一起远足。
Frank Liu
是 亚马逊云科技 深度学习的软件工程师。他专注于为软件工程师和科学家开发创新的深度学习工具。在业余时间,他喜欢与朋友和家人一起远足。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。