我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 Amazon EMR Serverless 为大数据工作负载定义每个团队的资源限制
客户在运行开发、测试或生产等工作负载的不同团队之间分配云资源时面临挑战。当您有不同的业务线用户时,也会出现资源分配问题。目标不仅是确保为生产工作负载和关键团队持续提供足够的资源,还要防止临时作业使用所有资源,并防止由于错误配置或未优化的代码而延迟其他关键工作负载。这些团队的成本控制和使用情况跟踪也是一个关键因素。
在传统的大数据和 Hadoop 集群以及
在这篇文章中,我们展示了如何使用 EMR serverless 为大数据工作负载定义每个团队的资源限制。
解决方案概述
下图说明了我们的解决方案架构。我们看到,两个不同的团队,即生产团队和开发团队,正在将他们的工作分别提交给两个具有专用资源的不同的 EMR 应用程序(分别是 ProdApp 和 DevApp)。
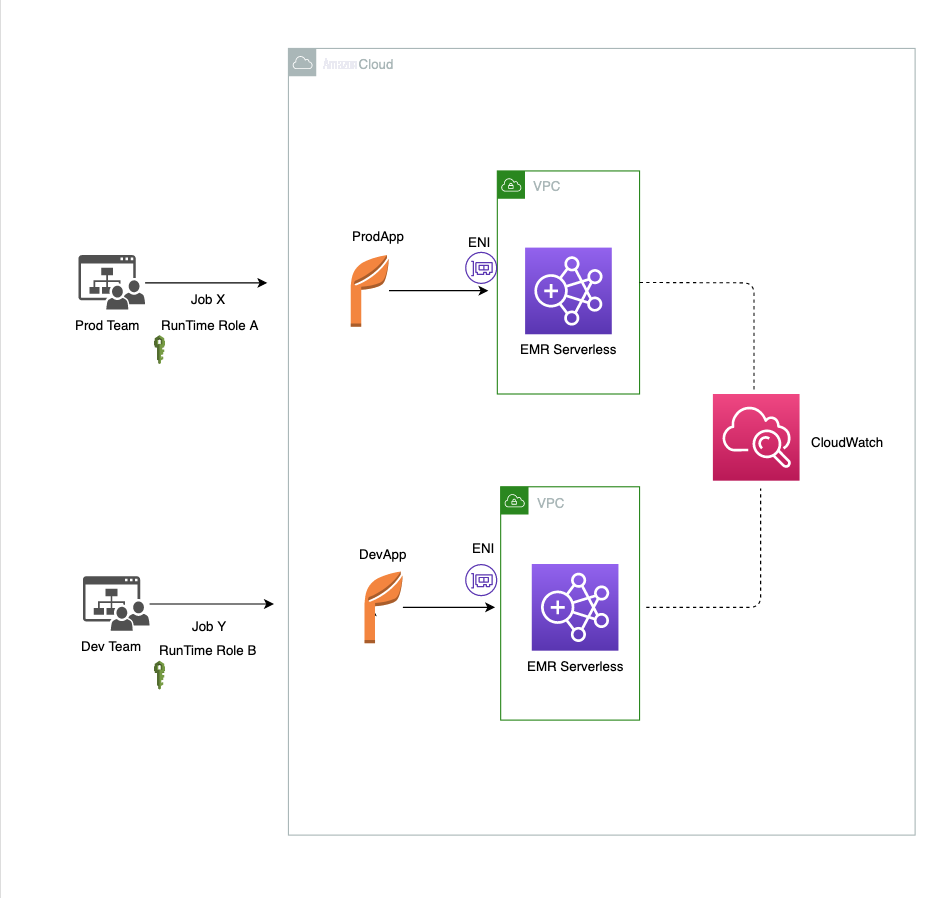
EMR Serverless 提供帐户、应用程序和任务级别的控制,以限制 CPU、内存或磁盘等资源的使用。在以下部分中,我们将讨论其中的一些控件。
账户级别的服务配额
对于每个账户的最大并发 vCPU,Amazon EMR Serverless 的默认配额为 16。换句话说,一个新账户在给定时间点在所有 EMR Serverless 应用程序中最多可以运行 16 个 vCPU。但是,此配额可根据使用模式自动调整,使用模式在账户和区域级别进行监控。
应用程序级别的资源限制和运行时配置
除了账户级别的配额外,管理员还可以使用名为 “
您还可以选择在应用程序级别指定常见的运行时和监控配置,否则您将在特定的作业配置中使用这些配置。这有助于为在应用程序下运行的所有作业创建标准化的运行时环境。这可能包括诸如定义作业需要访问的常用连接设置、所有作业默认将继承的日志配置或帮助平衡临时工作负载的 Spark 资源设置等设置。您可以在作业级别覆盖这些配置,但是在应用程序中定义它们可以帮助减少单个作业所需的配置。
有关更多详细信息,请参阅
作业级别的运行时配置
在应用程序级别设置服务、应用程序配额和运行时配置后,您还可以选择在作业级别覆盖或添加新配置。例如,您可以使用不同的 Spark 作业参数来定义该特定作业可以运行的最大执行器数量。
Spark.dynamicalLocation.maxExecut
ors 就是这样一个参数, 它定义了作业中执行者数量的上限,因此可以控制 EMR 无服务器应用程序中的工作人员数量,因为每个执行器都在一个工作器中运行。此参数是
通过这些配置,您可以控制账户、应用程序和任务中使用的资源。例如,您可以创建具有预定义的最大容量的应用程序来限制成本,或者配置有资源限制的作业,以便允许同时运行多个临时作业而不会消耗太多资源。
最佳做法和注意事项
EMR Serverless 进一步扩展了这些使用场景,提供了特性和功能,可根据您的工作负载要求实施以下设计注意事项和最佳实践:
-
为确保用户或团队仅向其批准的应用程序提交任务,您可以使用基于标签的
亚马逊云科技 身份和访问管理 (IAM) 策略条件。有关更多详细信息,请参阅使用标签进行访问控制 。 -
您可以将
自定义映像 用作属于具有不同用例和软件要求的不同团队的应用程序。EMR 6.9.0 及更高版本可以使用自定义映像。自定义映像允许您将各种应用程序依赖项打包到单个容器中。使用自定义映像的一些重要好处包括能够使用自己的 JDK 和 Python 版本、应用组织特定的安全策略以及将 EMR Serverless 集成到构建、测试和部署管道中。有关更多信息,请参阅自定义 EMR 无服务器 映像。 -
如果您需要估算在 EMR 无服务器上运行一个 Spark 作业的成本,则可以使用开源工具
EMR Serverless Estimator。 此工具分析 Spark 事件日志,为您提供成本估算。更多详情,请参阅亚马逊 EMR S erverless 成本估算器 - 我们建议您通过将工作人员数量乘以工作人员人数来确定相对于支持的工作人员规模的最大容量。例如,如果您想将拥有 50 个工作线程的应用程序限制为 2 个 vCPU、16 GB 内存和 20 GB 磁盘,请将最大容量设置为 100 vCPU、800 GB 内存和 1000 GB 磁盘。
-
在创建 EMR 无服务器应用程序时,您可以使用标签来帮助搜索和筛选资源,或者使用 亚马逊云科技 Cost Explorer 跟踪 A
WS 成本 。 您还可以使用标签来控制谁可以向特定应用程序提交任务或修改其配置。有关更多详细信息,请参阅标记您的资源 。 -
您可以在创建应用程序时配置
预初始化的容量 ,这样可以使资源随时可供您提交的时间敏感型作业使用。 - 您可以运行的并发作业数量取决于重要因素,例如最大容量限制、每项任务所需的工作人员以及使用 VPC 时的可用 IP 地址。
-
EMR Serverless 将设置
弹性网络接口 (ENI),以便与您的 VPC 中的资源进行安全通信。确保您的子网中有足够的 IP 地址来完成任务。 - 最佳做法是从多个可用区中选择多个子网。这是因为您选择的子网决定了可用于运行 EMR Serverless 应用程序的可用区域。每个工作人员在其启动的子网中使用一个 IP 地址。确保配置的子网有足够的 IP 地址供您计划运行的工作人员数量使用。
资源使用情况跟踪
EMR Serverless 不仅允许云管理员限制每个应用程序的资源,还使他们能够监控应用程序并跟踪这些应用程序中的资源使用情况。有关更多详细信息,请参阅
您还可以部署 亚马逊云科技 CloudFormation 模板来为
结论
在这篇文章中,我们讨论了EMR Serverless如何使云和数据平台管理员能够在不同级别、为不同的组织单位、用户和团队以及关键和非关键工作负载之间有效地分配和限制云资源。EMR 无服务器资源限制功能可确保云成本得到控制并有效跟踪资源使用情况。
作者简介
 高拉夫·夏尔马 是亚马逊网络服务(A
WS)的专业解决方案架构师(分析),为美国公共部门客户的云之旅提供支持。工作之余,高拉夫喜欢与家人共度时光和读书。
高拉夫·夏尔马 是亚马逊网络服务(A
WS)的专业解决方案架构师(分析),为美国公共部门客户的云之旅提供支持。工作之余,高拉夫喜欢与家人共度时光和读书。
 达蒙·科尔特西
是亚马逊网络服务的首席开发者倡导者。他开发工具和内容来帮助简化数据工程师的生活。工作不费吹灰之力时,他仍然会在业余时间建立数据管道并拆分日志。
达蒙·科尔特西
是亚马逊网络服务的首席开发者倡导者。他开发工具和内容来帮助简化数据工程师的生活。工作不费吹灰之力时,他仍然会在业余时间建立数据管道并拆分日志。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。