我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用亚马逊 SageMaker 地理空间功能和定制 SageMaker 模型进行损失评估
在这篇文章中,我们将介绍如何使用具有地理空间功能的
随着自然灾害频率和严重程度的增加,我们必须为决策者和急救人员提供快速而准确的损失评估。在此示例中,我们使用地理空间图像来预测自然灾害的损失。地理空间数据可以在自然灾害发生后立即用于快速识别建筑物、道路或其他关键基础设施的损坏情况。在这篇文章中,我们将向您展示如何训练和部署用于灾难损失分类的地理空间分割模型。我们将应用程序分为三个主题:模型训练、模型部署和推理。
模型训练
在这个用例中,我们使用
本示例中使用的数据集来自
在此示例中,我们仅使用灾前和灾后图像来预测灾后损失分类(分段掩码)。我们不使用灾前建筑物分段掩码。之所以选择这种方法,是为了简单起见。还有其他方法可以处理此数据集。XView2 竞赛的许多获胜方法都使用了两步解决方案:首先,预测灾前建筑轮廓分割掩码。然后,建筑物轮廓和损坏后的图像被用作预测损坏等级的输入。我们把这个留给读者来探索其他建模方法,以提高分类和检测性能。
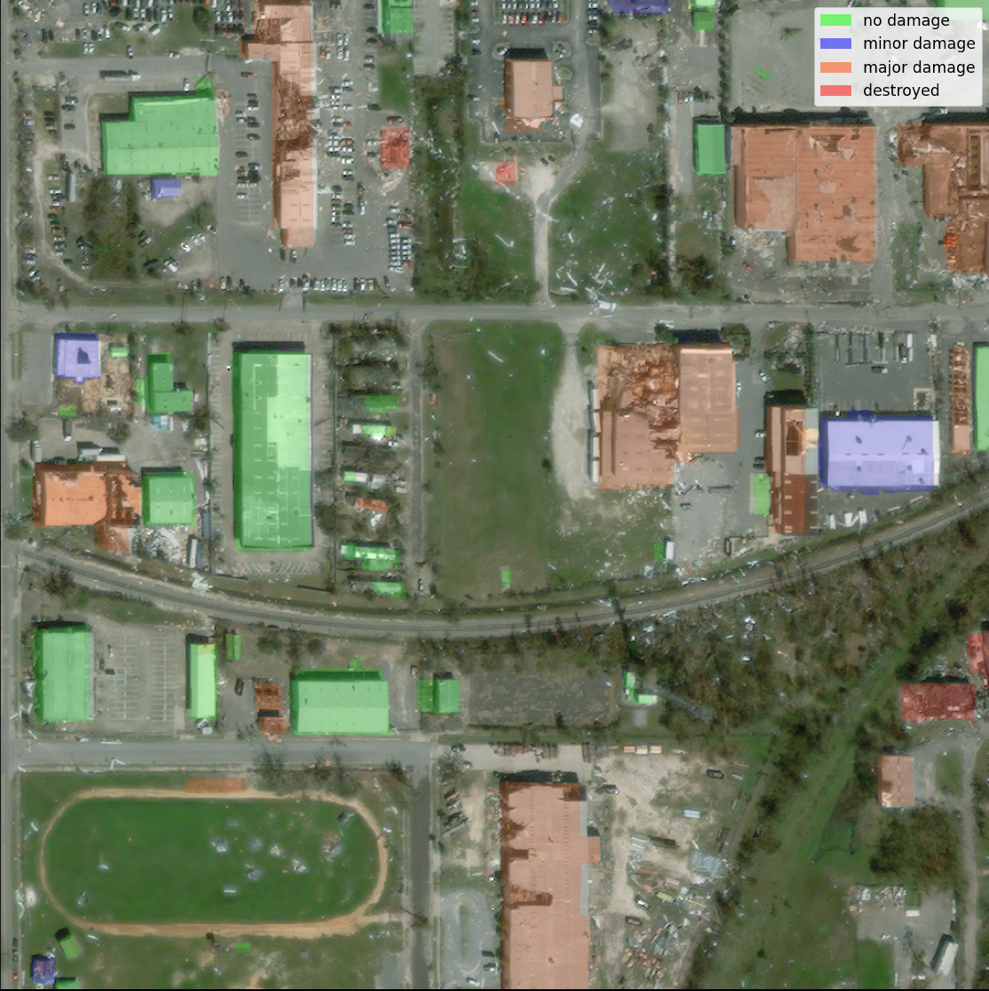
预训练的 SegFormer 架构旨在接受单个三色通道图像作为输入并输出分割掩码。我们可以通过多种方式修改模型以接受卫星前后的图像作为输入,但是,我们使用了一种简单的堆叠技术将两张图像堆叠成六色通道图像。我们在XView2训练数据集上使用标准增强技术对模型进行了训练,以预测灾后分割掩码。请注意,我们确实将所有输入图像的大小从 1024 像素调整为 512 像素。这是为了进一步降低训练数据的空间分辨率。该模型是使用 SageMaker 使用单个基于 p3.2xlarge GPU 的实例训练的。下图显示了经过训练的模型输出的示例。第一组图像是验证集中的损坏前和损坏后的图像。

下图显示了预测的伤害掩码和地面真相伤害面具。
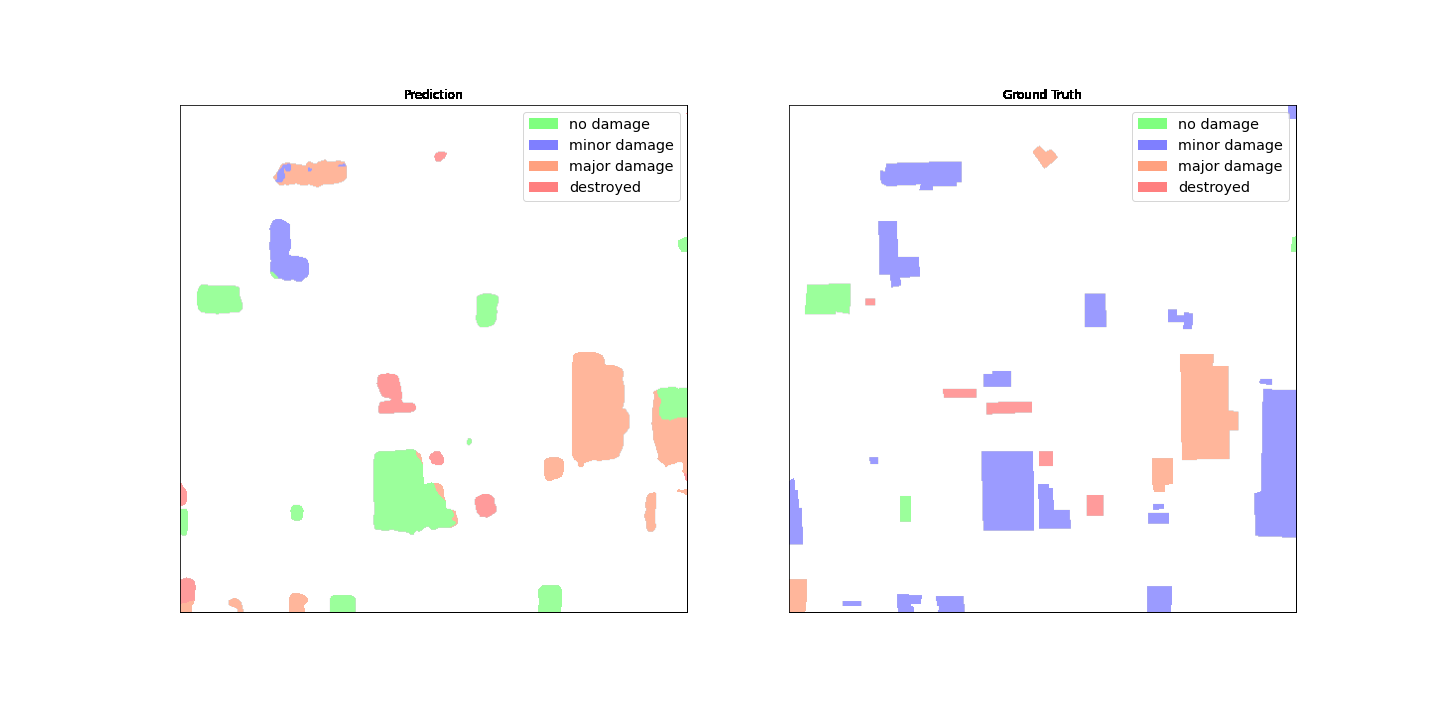
乍一看,与地面实况数据相比,该模型的表现似乎并不理想。许多建筑物的分类不正确,将轻微损坏与未损坏混为一谈,并且对单个建筑物轮廓显示了多种分类。但是,在审查模型性能时,一个有趣的发现是,它似乎已经学会了对建筑物损坏分类进行本地化。每座建筑物可以分为
无伤害
、
轻微损坏
、
重大伤害
或
被摧毁
。预测的伤害掩码显示,模型已将中间的大型建筑物归类为基本
无伤害
,但右上角被归类为已
摧毁
。这种子建筑物伤害定位可以通过显示每座建筑物的局部伤害来进一步帮助响应者。
模型部署
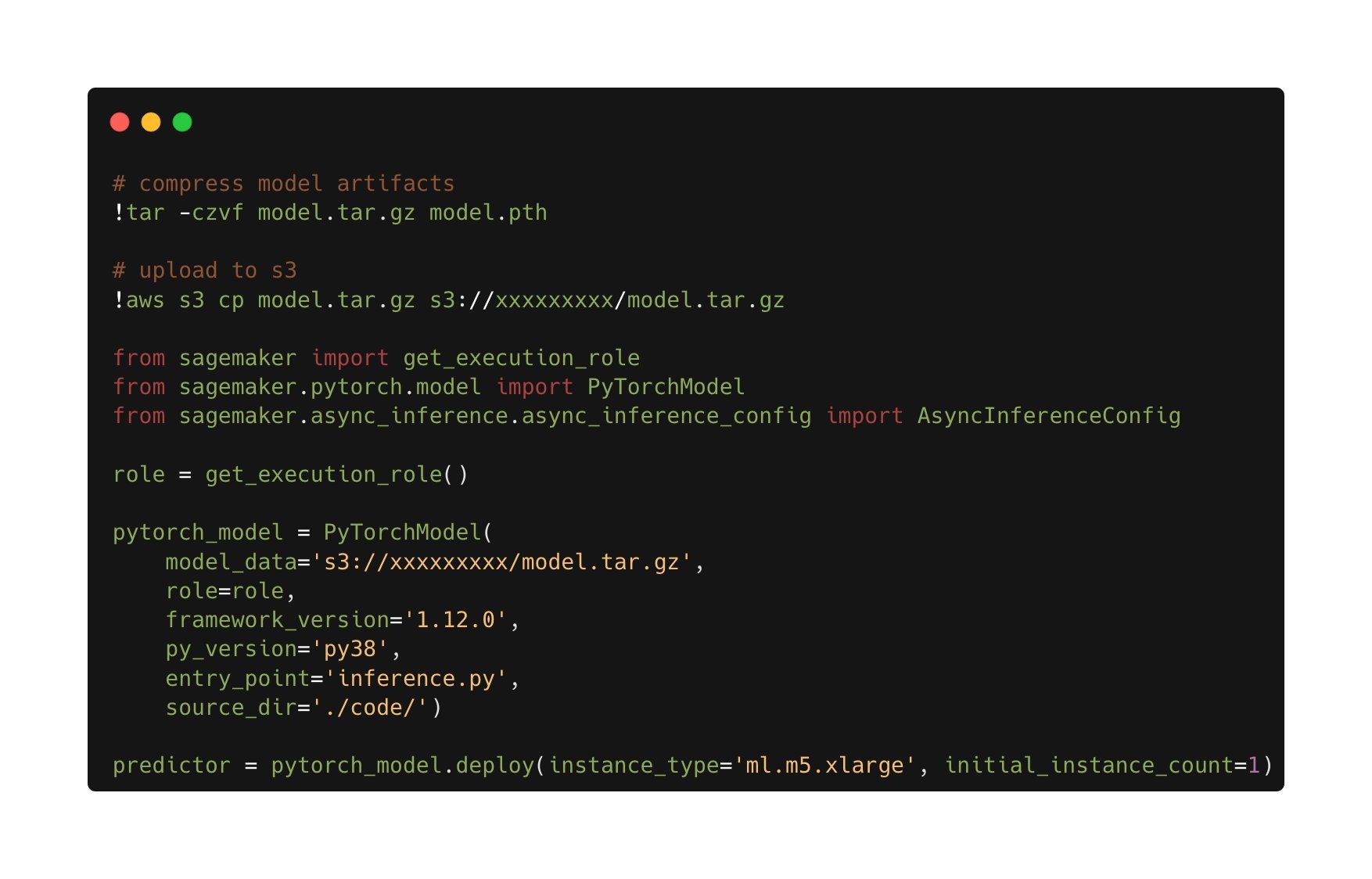
然后,将经过训练的模型部署到异步 SageMaker 推理端点。请注意,我们选择异步端点是为了延长推理时间、增加有效负载输入大小,并能够在不使用端点时将该端点缩减为零实例(不收费)。下图显示了异步端点部署的高级代码。我们首先压缩保存的 PyTorch 状态字典,然后将压缩后的模型工件上传到
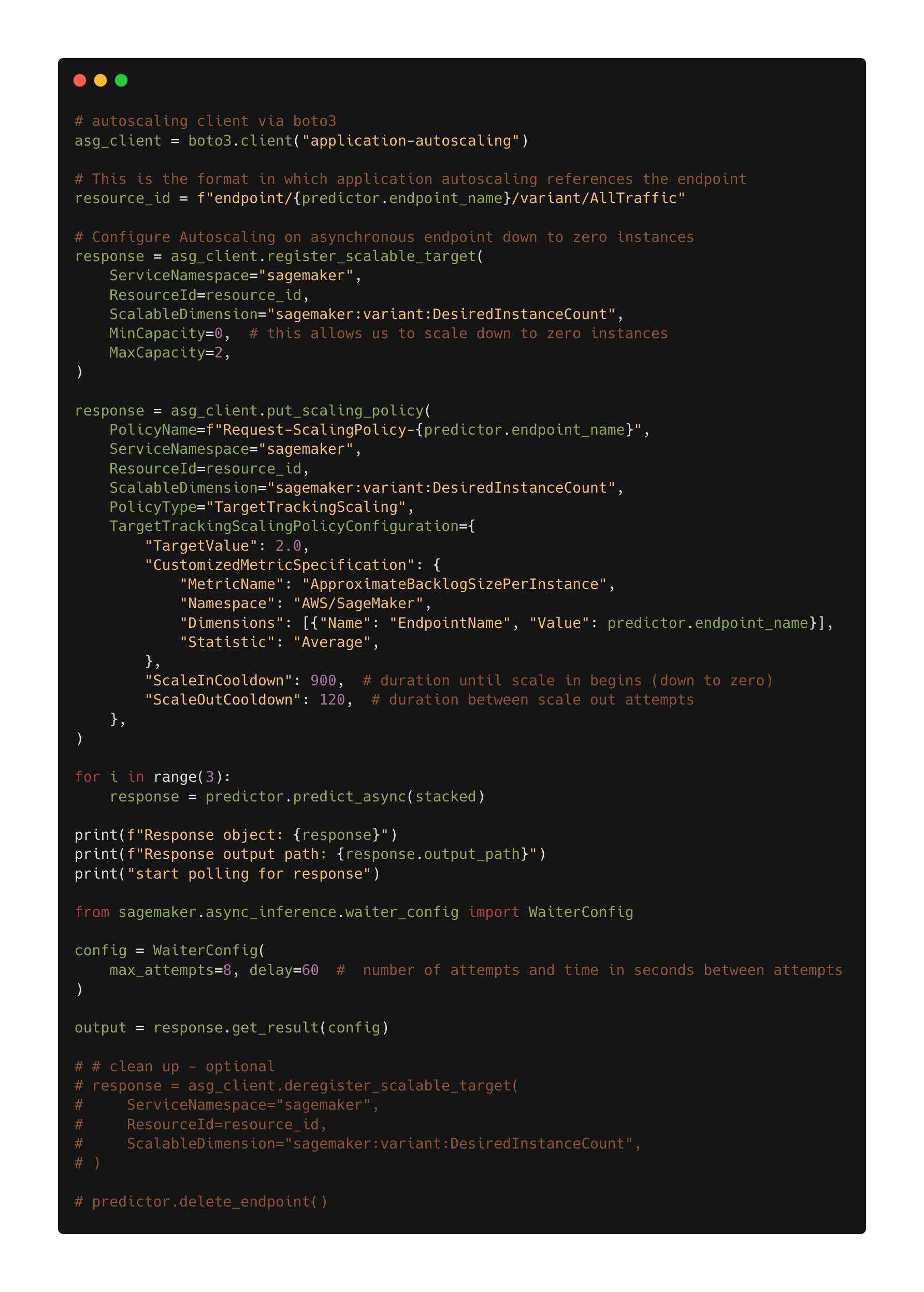
下图显示了异步推理端点的自动扩展策略的代码。
请注意,还有其他端点选项,例如实时、批处理和无服务器,可用于您的应用程序。您需要选择最适合该用例的选项,并回想一下,
模型推断
部署经过训练的模型后,我们现在可以使用
定义作业配置后,我们可以提交作业。任务完成后,我们会将结果导出到 Amazon S3。请注意,我们只能在任务完成后导出结果。任务的结果可以导出到用户在导出任务配置中指定的 Amazon S3 位置。现在,借助 Amazon S3 中的新数据,我们可以使用已部署的模型进行损失预测。我们首先将数据读入内存,然后将灾前和灾后的图像堆叠在一起。
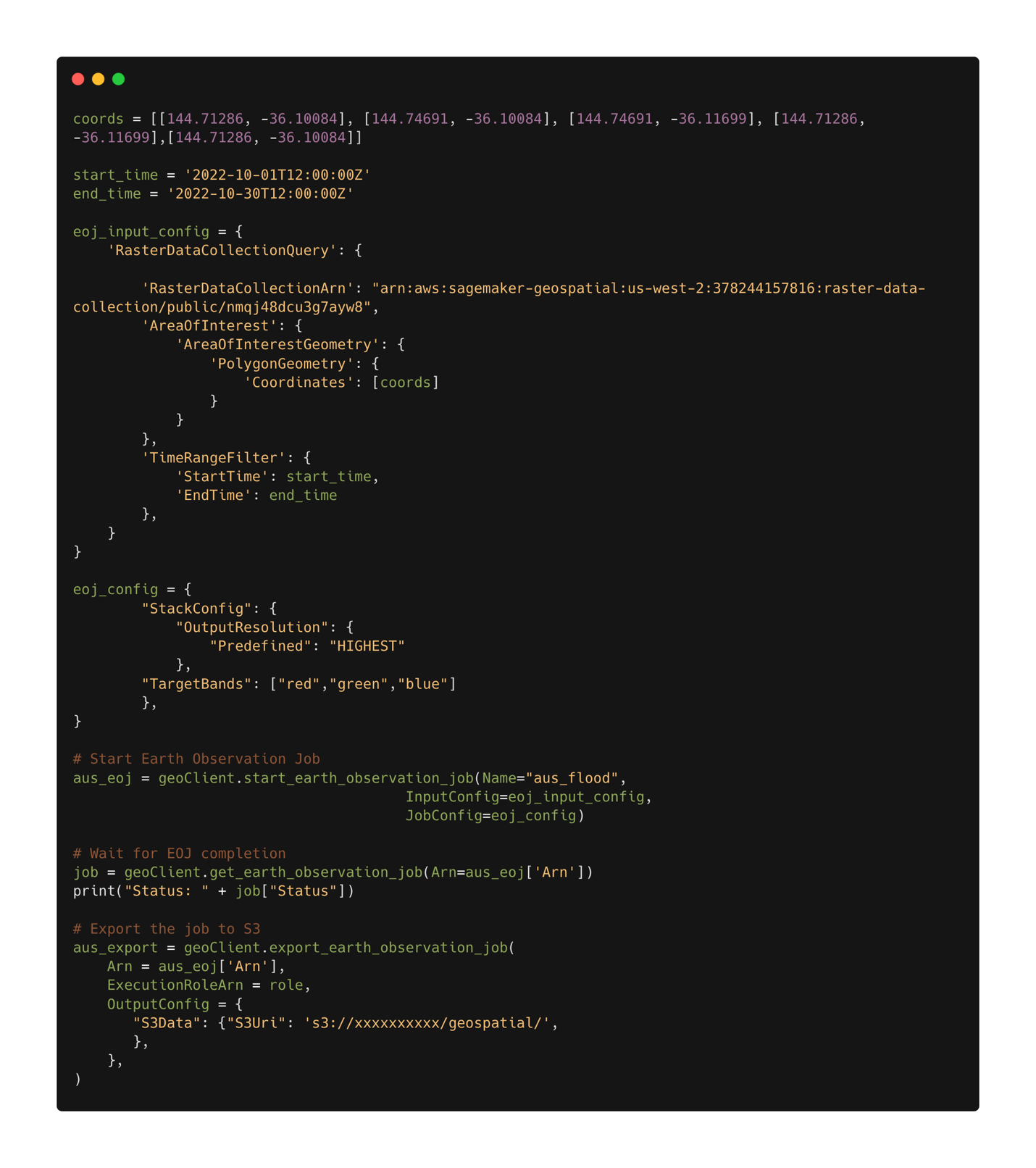
罗切斯特洪水的分段掩码结果如下图所示。在这里,我们可以看到,该模型已确定洪水区域内的位置可能遭到破坏。另请注意,推理图像的空间分辨率与训练数据的空间分辨率不同。提高空间分辨率可以帮助建模性能;但是,由于采用多尺度模型架构,这对于 SegFormer 模型来说并不像对其他模型那么重要。


损失评估
结论
在这篇文章中,我们展示了如何使用具有
立即使用您自己的模型试用 SageMaker 地理空间功能;我们期待看到您接下来会构建什么。
作者简介

*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。