我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 Amazon Redshift ML 创建、训练和部署多层感知器 (MLP) 模型
Red shift ML 在后台使用
Amazon Redshift ML 支持监督学习,包括回归、二元分类、多类分类和使用 K-Means 的无监督学习。您可以选择指定 XgBoost、MLP 和线性学习者模型类型,这些模型是用于解决分类或回归问题的监督学习算法,与传统的超参数优化技术相比,速度显著提高。
在这篇博客文章中,我们将向您展示如何使用 Redshift ML 使用多层感知器 (MLP) 算法来解决二进制分类问题,该算法探讨了不同的训练目标并从验证集中选择最佳解决方案。
多层感知器 (MLP) 是一种深度学习方法,用于训练多层人工神经网络,也称为深度神经网络。它是一个前馈人工神经网络,可从一组输入生成一组输出。MLP 的特点是在输入层和输出层之间以有向图的形式连接的多层输入节点。MLP 使用反向传播来训练网络。MLP 广泛用于解决需要监督学习的问题,以及计算神经科学和并行分布式处理的研究。它还用于语音识别、图像识别和机器翻译。
就在Redshift ML(由亚马逊SageMaker Autopilot提供支持)中使用MLP而言,它目前支持表格数据。
解决方案概述
要使用 MLP 算法,您需要提供代表维度值的输入或列,还需要提供标签或目标,即您要预测的值。
使用 Redshift ML,您可以在表格数据上使用 MLP 来解决回归、二元分类或多类分类问题。MLP 的更独特之处在于,MLP 的输出函数也可以是线性函数或连续函数。它不必像一般回归模型那样是一条直线。
在此解决方案中,我们使用二进制分类来检测基于信用卡交易数据的欺诈行为。分类模型和 MLP 的区别在于,逻辑回归使用逻辑函数,而感知器使用阶跃函数。使用多层感知器模型,机器可以学习权重系数,帮助它们对输入进行分类。这种线性二进制分类器在将输入数据排列和分类为不同类别方面非常有效,允许基于概率的预测并将项目分为多个类别。多层感知器具有学习非线性模型和实时训练模型的优势。
对于此解决方案,我们首先将数据提取到 Amazon Redshift 中,然后将其分发用于模型训练和验证,然后使用 Amazon Redshift ML 特定查询创建模型,从而创建并利用生成的 SQL 函数来最终预测欺诈性交易。
先决条件
首先,我们需要一个 Amazon Redshift 集群或 Ama
有关 Redshift ML 的介绍及其设置说明,请参阅使用 SQL 在 Amazon Redshift
要创建具有默认 IAM 角色的简单集群,请参阅在 A
使用的数据集
在这篇文章中,我们使用
该数据集包含欧洲持卡人在 2013 年 9 月用信用卡进行的交易。
该数据集显示了两天内发生的交易,在284,807笔交易中,我们有492起欺诈行为。数据集非常不平衡,正面类别(欺诈)占所有交易的0.172%。
它仅包含作为
以下是示例记录:
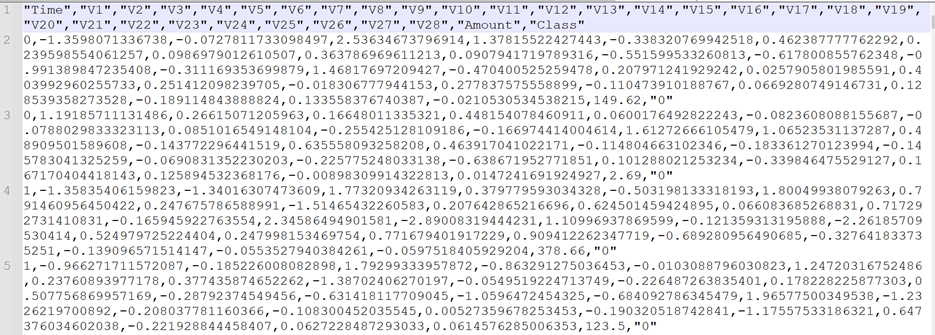
准备数据
使用以下 SQL 将信用卡数据集加载到亚马逊 Redshift 中。你可以使用
|
Alternately we have provided a notebook you may use to execute all the sql commands that can be downloaded
|
要创建表,请使用以下命令:
加载数据
要将数据加载到亚马逊 Redshift 中,请使用以下 COPY 命令:
在创建模型之前,我们希望通过拆分 80% 的数据集进行训练,20% 用于验证,将数据分成两组,这是 ML 中的常见做法。将训练数据输入到 ML 模型中,以确定模型的最佳算法。创建模型后,我们使用验证数据来验证模型的准确性。
因此,在 “
creditcardsfrauds
” 表中,我们根据 “
txtime
” 值检查数据的分布,并确定大约80%数据的截止值以训练模型。
由此,txtime 的最高值为 120954(基于 txtime 的最小值、最大值、按窗口函数排序和 ceil(count (*) *0.80)值的分布),在此基础上,我们认为用于创建训练数据的'
txtim
e'字段值小于120954的交易记录。然后,我们通过预测其余20%数据的 “
类别
” 属性来验证该模型是否正确识别欺诈性交易,从而验证该模型的准确性。
80% 的截止值的分布不一定总是基于订购时间。也可以根据正在考虑的用例随机获取。
在 Redshift ML 中创建模型
在这里,在命令的设置部分中,您需要设置一个
S3_BUCKET ,用于导出发送到 SageMaker 的数据并存储
模型工件。
S3_BUC
KET 设置是命令的必填参数,而
MAX_RUNTIME
是可选参数,它指定了训练的最大时间。此参数的默认值为 90 分钟(5400 秒),但是您可以通过在命令中明确指定它来覆盖它,就像我们在此处将其设置为运行 9600 秒所做的那样。
前面的语句在后台启动
您可以在 Amazon Redshift 中使用 SHO
x_runtime
参数中,模型的创建进度应处于 “
就绪
” 状态。
要检查模型的状态,请使用以下命令:
我们从上表中注意到,训练数据的
详细地说,F1-Score 是精度和召回率的谐波平均值。它使用以下公式将精度和召回率合并为一个数字:
![]()
在哪里,精确度意味着:在所有积极的预测中,有多少是真正积极的?
而且 Recall 意味着:在所有真正的阳性病例中,有多少预测为阳性?
F1 分数可以介于 0 到 1 之间,其中 1 表示将每个观测值完美分类为正确类别的模型,0 表示无法将任何观测值归类为正确类别的模型。因此,F1 分数越高越好。
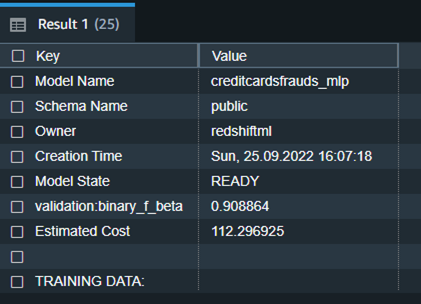
以下是模型训练完成后前面命令的详细表格结果。
| Model Name | creditcardsfrauds_mlp |
| Schema Name | public |
| Owner | redshiftml |
| Creation Time | Sun, 25.09.2022 16:07:18 |
| Model State | READY |
| validation:binary_f_beta | 0.908864 |
| Estimated Cost | 112.296925 |
| TRAINING DATA: | . |
| Query | SELECT * FROM CREDITCARDSFRAUDS WHERE TXTIME < 120954 |
| Target Column | CLASS |
| PARAMETERS: | . |
| Model Type | mlp |
| Problem Type | BinaryClassification |
| Objective | F1 |
| AutoML Job Name | redshiftml-20221118035728881011 |
| Function Name | creditcardsfrauds_mlp_fn |
| . | creditcardsfrauds_mlp_fn_prob |
| Function Parameters | txtime v1 v2 v3 v4 v5 v6 v7 v8 v9 v10 v11 v12 v13 v14 v15 v16 v17 v18 v19 v20 v21 v22 v23 v24 v25 v26 v27 v28 amount |
| Function Parameter Types | int4 float8 float8 float8 float8 float8 float8 float8 float8 float8 float8 float8 float8 float8 float8 float8 float8 float8 float8 float8 float8 float8 float8 float8 float8 float8 float8 float8 float8 float8 |
| IAM Role | default |
| S3 Bucket | redshift-ml-blog-mlp |
| Max Runtime | 54000 |
Redshift ML 现在支持二元分类模型的预测概率。对于机器学习中的分类问题,对于给定的记录,每个标签可以关联一个概率,该概率表示该记录真正属于该标签的可能性。当基于所选标签的置信度高于模型返回的特定阈值时,客户可以选择将概率与标签一起使用。
默认情况下,二元分类模型的预测概率是计算的,并且在创建模型时会创建附加函数,而不会影响 ML 模型的性能。
在上面的片段中,你会注意到预测概率的增强为模型函数添加了另一个函数作为后缀 (
_prob ),其名称为 “cred
”,可用于获取预测概率。
itcardsfrauds
_mlp_fn_prob
此外,您可以检查
通过回答以下问题,模型可解释性有助于理解预测原因:
- 为什么该模型预测当有人去另一个国家旅行并以不同的货币提取大量资金时,会出现负面结果,例如信用卡被封锁?
- 模型如何做出预测?许多信用卡数据可以采用表格格式,根据涉及多层完全连接的神经网络的MLP流程,我们可以分辨出哪个输入特征实际对模型输出做出了贡献及其大小。
- 为什么模型做出了错误的预测?例如,尽管交易是合法的,但为什么该卡仍被封锁?
- 哪些特征对模型行为的影响最大?影响预测的因素是否仅仅取决于刷卡的地点,甚至是一天中的时间和异常的信用消费?
运行以下 SQL 命令从可解释性报告中检索值:

在前面的屏幕截图中,我们只选择了从 e
模型验证
现在,让我们运行预测查询并在验证数据集中验证模型的准确性:

我们可以在这里观察到,Redshift ML能够正确地将99.88%的交易识别为欺诈性或非欺诈性。
现在,你可以继续使用这个 SQL 函数
creditcardsfrauds_mlp_fn
在 SQL 查询的任何部分 进行本地推断,同时分析、可视化或报告新到的数据和现有数据!
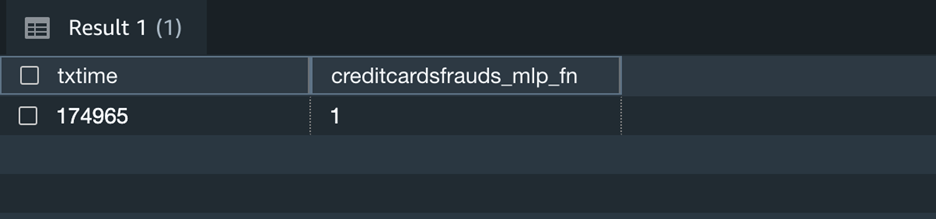
根据推断,这里的输出 1 表示新捕获的交易是欺诈性的。
此外,您可以更改上述查询以包括上述场景中标签输出的预测概率,并决定是否仍喜欢使用模型的预测。
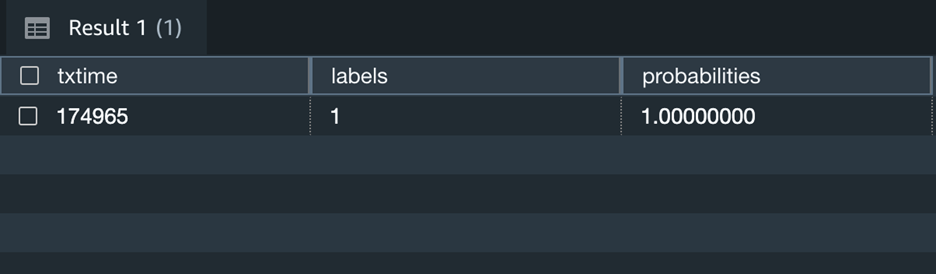
上面的屏幕截图显示,该交易具有100%的欺诈可能性。
清理
为了避免将来产生费用,您可以在不使用 Redshift 集群时将其停止。如果你仅出于实验目的运行了这篇博客文章中的练习,你甚至可以完全终止 Redshift 集群。如果您改用无服务器版本的Redshift,则在使用之前,它不会花费任何费用。但是,如前所述,如果您使用的是 Redshift 的预配置版本,则必须停止或终止集群。
结论
Redshift ML 使所有级别的用户都能轻松地使用 SQL 接口创建、训练和调整模型。在这篇文章中,我们向您介绍了如何使用 MLP 算法创建二进制分类模型。然后,您可以使用这些模型使用简单的 SQL 命令进行预测并获得有价值的见解。
要了解有关 RedShift 机器学习的更多信息,请访问
作者简介




*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。