我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用亚马逊 SageMaker JumpStart 使用 Falcon 创建 HCLS 文档摘要应用程序
医疗保健和生命科学 (HCLS) 客户正在采用生成式 AI 作为从数据中获取更多收益的工具。用例包括文档摘要,以帮助读者专注于文档的关键点,以及将非结构化文本转换为标准化格式以突出重要属性。凭借独特的数据格式和严格的监管要求,客户正在寻找选择性能最高、最具成本效益的模型,以及进行必要的自定义(微调)以适应其业务用例的能力。在这篇文章中,我们将引导你使用
解决方案概述
您还可以确保推理负载数据不会离开您的 VPC。您可以将模型配置为单租户端点,并通过网络隔离进行部署。此外,您可以使用 SageMaker JumpStart 中的私有模型中心功能并将批准的模型存储在其中来管理和管理满足您自己的安全要求的选定模型集。
SageMaker JumpStart 模型中心包括完整的笔记本电脑,用于部署和查询每个模型。截至撰写本文时,SageMaker JumpStart 模型中心有六个版本的猎鹰可用:猎鹰 40B Instruct BF16、Falcon 40B BF16、Falcon 180B BF16、Falcon 180B Chat BF16、Falcon 7B Instruct BF16 和 Falcon 7B BF16。这篇文章使用了 Falcon 7B Instruct 模型。
在以下部分中,我们将介绍如何通过在 SageMaker Jumpstart 上部署 Falcon 7B 来开始进行文档摘要。
先决条件
在本教程中,您需要一个具有 SageMaker 域的 亚马逊云科技 账户。如果你还没有 SageMaker 域名,请参阅 Onboard to
使用 SageMaker JumpStart 部署 Falcon 7B
要部署您的模型,请完成以下步骤:
- 从 SageMaker 控制台导航到您的 SageMaker Studio 环境。
- 在 IDE 中,在导航窗格的 SageMaker JumpStart 下,选择 型号、笔记本电脑、解决方案 。
- 将 Falcon 7B Instruct 模型部署到端点进行推断。
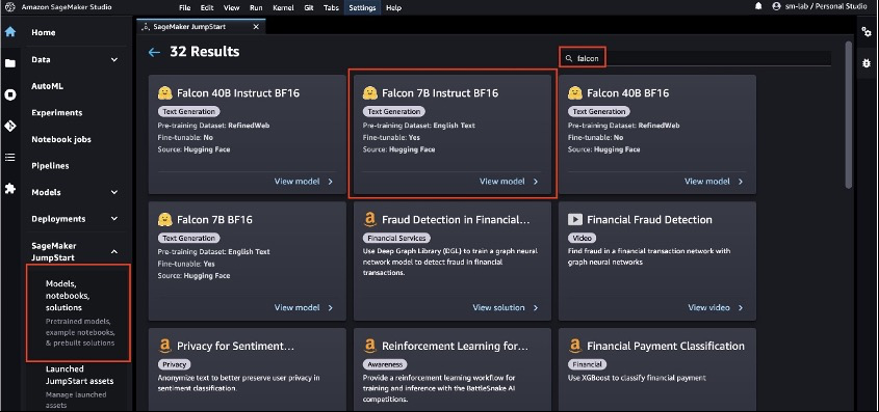
这将打开 Falcon 7B Instruct BF16 模型的模型卡。在此页面上,您可以找到 “ 部署 ” 或 “ 训练 ” 选项以及在 SageMaker Studio 中打开示例笔记本的链接。这篇文章将使用来自 SageMaker JumpStart 的示例笔记本来部署该模型。
- 选择 “ 打开笔记本 ” 。
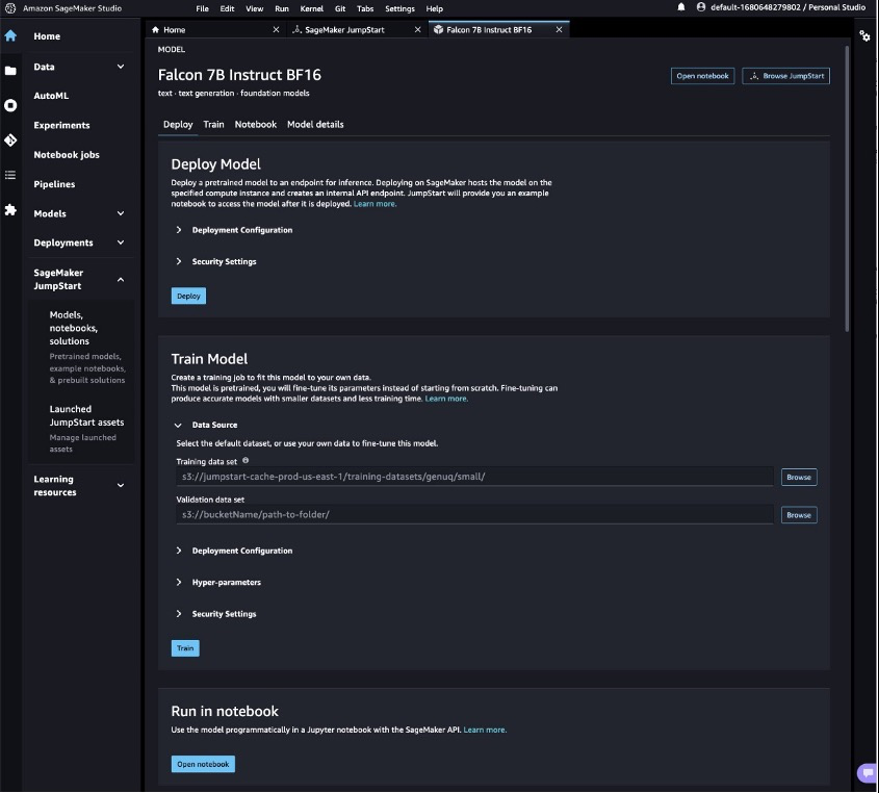
- 运行笔记本电脑的前四个单元来部署 Falcon 7B Instruct 端点。
你可以在已启动的 JumpStart 资产 页面上看到已部署的 JumpStart 模型。
- 在导航窗格中的 SageMaker Jumpstart 下 ,选择 已 启动的 JumpStart 资源。
- 选择 模型端点 选项卡以查看终端节点的状态。
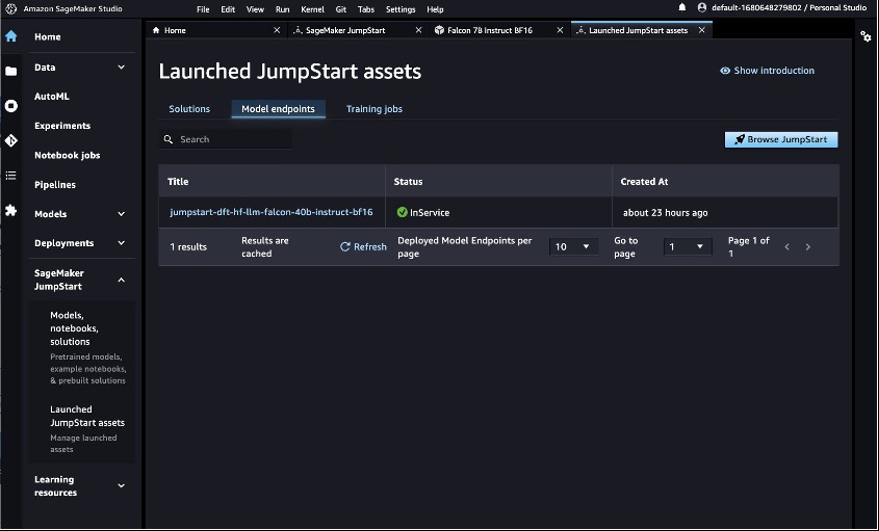
部署 Falcon LLM 端点后,您就可以查询模型了。
运行你的第一个查询
要运行查询,请完成以下步骤:
- 在 “ 文件 ” 菜单上,选择 “ 新建 和 笔记本 ” 以打开新的笔记本。
你也可以在
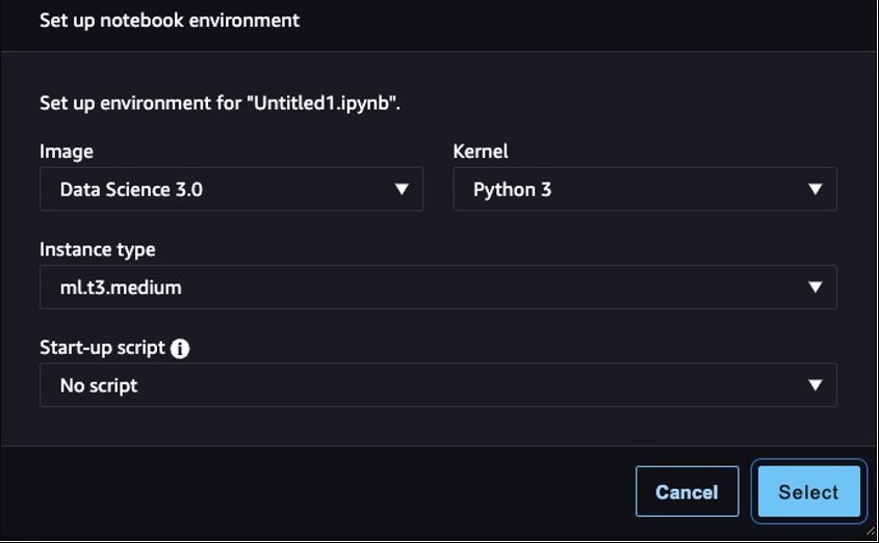
- 出现提示时,选择映像、内核和实例类型。在这篇文章中,我们选择了数据科学 3.0 图片、Python 3 内核和 ml.t3.medium 实例。
- 通过在第一个单元格中输入以下两行来导入 Boto3 和 JSON 模块:
- 按 住 Shift + Enter 键 运行单元格。
- 接下来,你可以定义一个调用你的端点的函数。此函数接受字典负载并使用它来调用 SageMaker 运行时客户端。然后它反序列化响应并打印输入和生成的文本。
有效负载包括作为输入的提示以及将传递给模型的推理参数。
- 您可以在提示符下使用这些参数来调整用例的模型输出:
使用摘要提示进行查询
这篇文章使用样本研究论文来演示摘要。示例文本文件涉及生物医学文献中的自动文本摘要。完成以下步骤:
-
下载 PDF 并将文本复制到名为document.txt的文件中 。 - 在 SageMaker Studio 中,选择上传图标并将文件上传到您的 SageMaker Studio 实例。
Falcon LLM 开箱即用,为文本摘要提供支持。
-
让我们创建一个使用即时工程技术来总结
document.txt的函数 :
你会注意到,对于较长的文档,会出现错误——Falcon和所有其他 LLM 一样,对作为输入传递的代币数量有限制。我们可以使用 LangChain 增强的摘要功能来绕过这个限制,它允许将更大的输入传递给 LLM。
导入并运行汇总链
LangChain 是一个开源软件库,允许开发人员和数据科学家在不管理复杂的机器学习交互的情况下快速构建、调整和部署自定义生成应用程序,通常用于在短短几行代码中抽象出生成式 AI 语言模型的许多常见用例。LangChain 对 亚马逊云科技 服务的支持包括对 SageMaker 终端节点的支持。
LangChain 为 LLM 提供了一个可访问的接口。它的功能包括用于即时模板和提示链接的工具。这些链可用于在单次调用中汇总比语言模型支持的长度更长的文本文档。您可以使用 map-reduce 策略对长文档进行汇总,方法是将长文档分解成可管理的块,对它们进行汇总,然后将其合并(如果需要,还可以再次进行汇总)。
- 让我们开始安装 LangChain:
- 导入相关模块并将长文档分解成块:
- 为了让 LangChain 有效地与 Falcon 一起工作,你需要为有效的输入和输出定义默认的内容处理器类:
-
您可以将自定义提示定义为
promptTemplate 对象,即使用 LangChain 进行提示的主要工具,用于地图缩减汇总方法。这是一个可选步骤,因为如果加载汇总链(load_summarimize_chain)中的参数未定义,则默认情况下会提供映射和组合提示。
- LangChain 支持在 SageMaker 推理端点上托管的 LLM,因此,您可以通过 LangChain 初始化连接以提高可访问性,而不是使用 亚马逊云科技 Python 开发工具包:
- 最后,您可以使用以下代码加载汇总链并对输入文档运行摘要:
由于
详细 参数设置为
,因此您将看到 map-reduce 方法的所有中间输出。这对于跟踪事件顺序以得出最终摘要很有用。使用这种 map-reduce 方法,您可以有效地总结文档,比模型的最大输入令牌限制通常允许的时间长得多。
Tru
e
清理
使用完推理端点后,请务必将其删除,以免通过以下几行代码产生不必要的成本:
在 SageMaker JumpStart 中使用其他基础模型
利用 SageMaker JumpStart 中提供的其他基础模型进行文档摘要所需的设置和部署开销最小。LLM 偶尔会随输入和输出格式的结构而变化,随着向 SageMaker JumpStart 添加新模型和预制解决方案,根据任务实现的不同,您可能需要更改以下代码:
-
如果您通过 summarize
() 方法(该方法不使用 LangChain)进行 汇总,则可能需要更改有效负载参数的 JSON 结构,以及query_endpoint () 函数中对响应变量的处理 -
如果你通过 LangChain 的 l
oad_summarize_chain () 方法进行汇总,则可能需要修改 Cont entHandlerTextSummarization 类,特别是 transform_input () 和 transforLLM 期望的负载 和m_output ()函数,才能正确处理LLM 返回的输出
基础模型不仅在推理速度和质量等因素上有所不同,而且在输入和输出格式方面也有所不同。有关预期的输入和输出,请参阅 LLM 的相关信息页面。
结论
Falcon 7B Instruct 模型在 SageMaker JumpStart 模型中心上线,适用于多种用例。这篇文章演示了如何使用 SageMaker JumpStart 将自己的 Falcon LLM 端点部署到您的环境中,并在 SageMaker Studio 中进行首次实验,从而使您能够快速对模型进行原型设计并无缝过渡到生产环境。借助Falcon和LangChain,您可以大规模有效地总结医疗保健和生命科学的长篇文档。
有关在 亚马逊云科技 上使用生成式 AI 的更多信息,请参阅
作者简介
 John Kitaok
a 是亚马逊网络服务的解决方案架构师。John 帮助客户在 亚马逊云科技 上设计和优化 AI/ML 工作负载,以帮助他们实现业务目标。
John Kitaok
a 是亚马逊网络服务的解决方案架构师。John 帮助客户在 亚马逊云科技 上设计和优化 AI/ML 工作负载,以帮助他们实现业务目标。
 Josh Famestad
是亚马逊网络服务的解决方案架构师。Josh 与公共部门客户合作,构建和执行基于云的方法,以实现业务优先事项。
Josh Famestad
是亚马逊网络服务的解决方案架构师。Josh 与公共部门客户合作,构建和执行基于云的方法,以实现业务优先事项。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。