我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 SageMaker Lakehouse Iceberg REST 端点将 Snowflake 连接到 S3 表
当今的组织寻求能够提供最大灵活性和可访问性的数据分析解决方案。客户需要使用他们首选的查询引擎随时获得数据,并打破不同计算环境中的障碍。同时,他们希望在这些解决方案中使用单一数据副本,以跟踪血统,提高成本效益并更好地扩展。可用于大规模查询表格数据的丰富工具生态系统迅速使 Apache Iceberg 成为各组织的热门选择。
Snowflake 让企业 AI 变得简单、互联且值得信赖。全球成千上万的公司,包括数百家全球最大的公司,使用 Snowflake 的人工智能数据云来共享数据、构建应用程序并通过人工智能为业务提供动力。2024 年 6 月,Snowflake 宣布 Iceberg 表格正式上市,将该平台的性能和简单性引入了开放式表格格式。
Snowflake 和 Amazon S3 Tables 最近开发的内置 Iceberg 支持为组织提供了一种强大的数据湖管理新方法。在 Snowflake 中,您可以利用平台的弹性和高性能计算,使用典型的 Snowflake 表的查询语义,并与 S3 表中可在计算环境中互操作的单一数据副本进行交互。在存储层,S3 Tables 为 Iceberg 引入了专门构建的优化,可提高性能、简化安全控制以及开箱即用的自动表维护。这种方法将 Snowflake 数据处理能力的优势与 S3 表格相结合,为组织提供了一种更简化的方法来利用开放数据标准。
在这篇文章中,我们将介绍如何设置 Snowflake 以使用 Amazon SageMaker Lakehouse Iceberg REST 端点访问 S3 表,而 Amazon Lake Formation 则管理存储凭证的售卖。我们首先使用 Amazon Athena 来创建数据并将其添加到表中,然后使用 Lake Formation 来进行访问控制。接下来,我们将逐步设置 Snowflake 来注册外部目录并查询表。
注意:在发布此博客文章时,Snowflake 提供的凭证售卖功能处于预览阶段。此外,Snowflake 以只读模式提供外部目录。这些功能的范围将来可能会发生变化。
解决方案概述
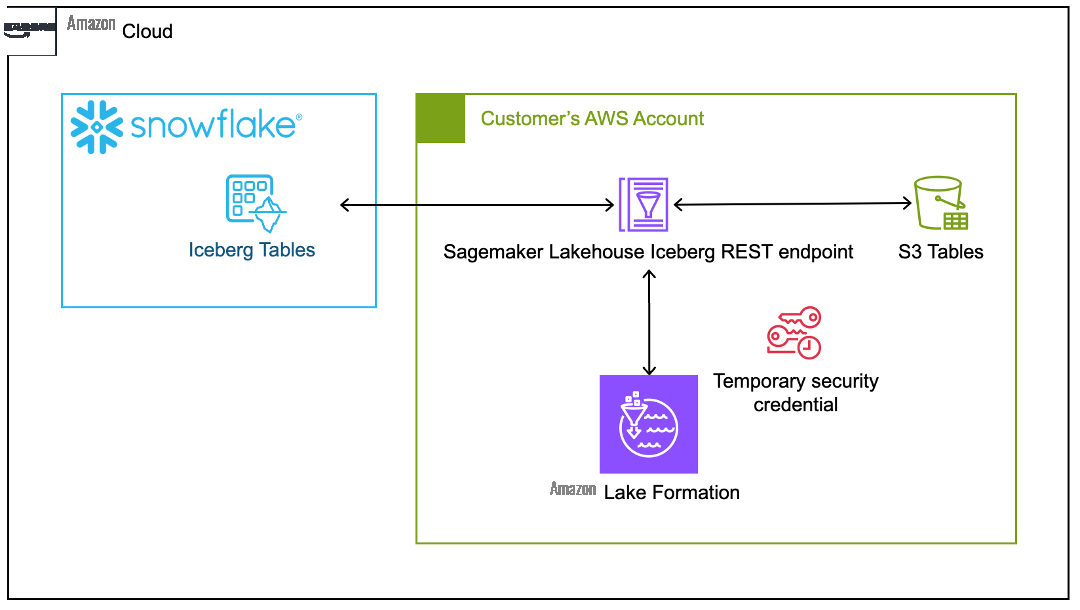
这篇文章将使用 SageMaker Lakehouse Iceberg REST 端点的目录集成以及 Snowflake 中的签名版本 4(SigV4)身份验证。
先决条件
- 一个 Snowflake 账户。
- 启用亚马逊云科技分析集成的 S3 表存储桶。在这篇文章中,我们将我们的存储桶命名为 "s3tables-snowflake-integration"。
- 一个 Amazon Identity and Access Management (IAM) 角色,是 Data Catalog 账户中的 Lake Formation 数据湖管理员。有关说明,请转到创建数据湖管理员。
解决方案演练
第 1 部分 设置命名空间、表和加载数据
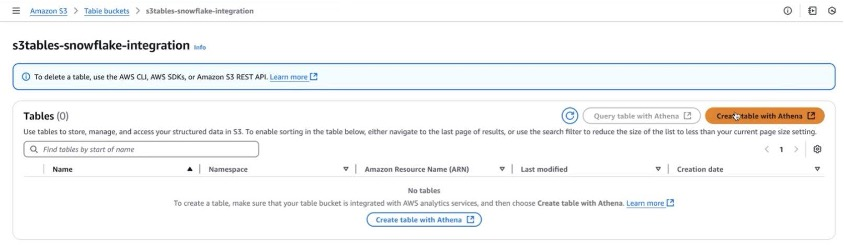
第 1 步:登录 Amazon S3 控制台并从导航面板中选择表存储桶。选择 "s3tables-snowflake-integration" 存储桶。
第 2 步:选择 "使用 Athena 创建表"。
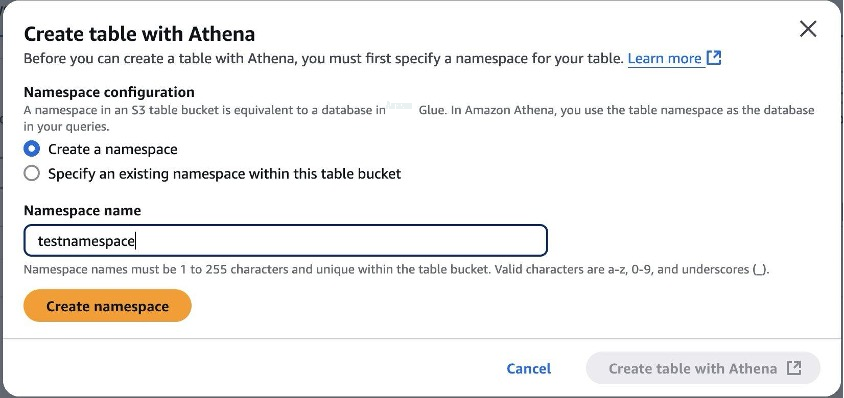
第 3 步:创建名为 "testnamespace" 的命名空间。
第 4 步:在创建命名空间时,你应该看到这个屏幕。选择 "使用 Athena 创建表格"。
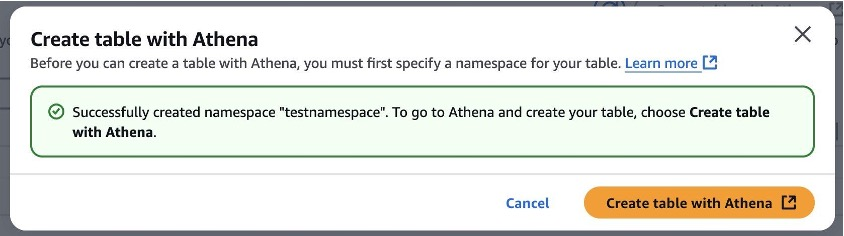
第 5 步:通过 Athena 创建一个 "daily_sales" 表。
CREATE TABLE `testnamespace`.daily_sales (
sale_date date,
product_category string,
sales_amount double)
PARTITIONED BY (month(sale_date))
TBLPROPERTIES ('table_type' = 'iceberg')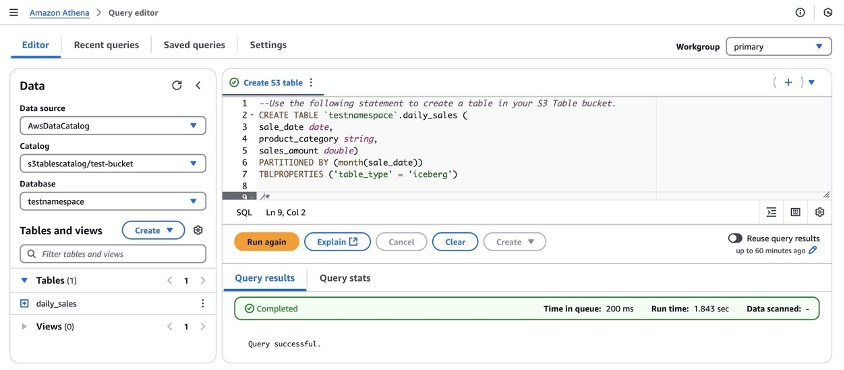
第 6 步:使用 Athena 将示例行插入 "daily_sales" 表中。
INSERT INTO daily_sales
VALUES
(DATE '2024-01-15', 'Laptop', 900.00),
(DATE '2024-01-15', 'Monitor', 250.00),
(DATE '2024-01-16', 'Laptop', 1350.00),
(DATE '2024-02-01', 'Monitor', 300.00),
(DATE '2024-02-01', 'Keyboard', 60.00),
(DATE '2024-02-02', 'Mouse', 25.00),
(DATE '2024-02-02', 'Laptop', 1050.00),
(DATE '2024-02-03', 'Laptop', 1200.00),
(DATE '2024-02-03', 'Monitor', 375.00);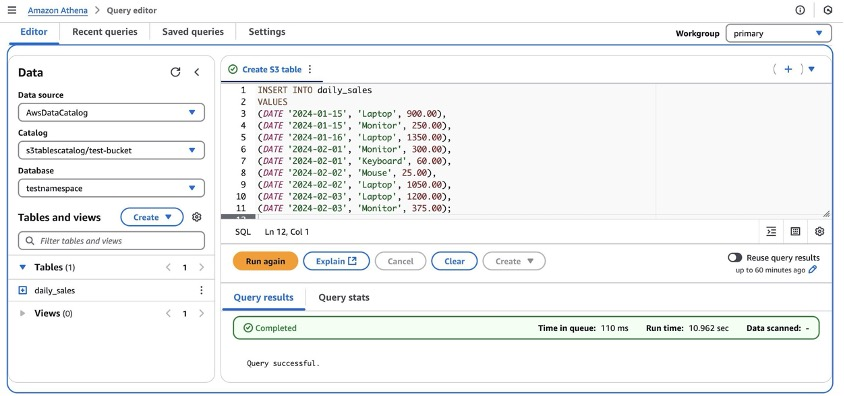
接下来,我们将介绍 Snowflake 访问此表所需的配置。
第 2 部分 为 Snowflake 设置 IAM 角色以通过 Amazon Lake Formation 访问 S3 表
首先,我们创建一个 IAM 角色,Snowflake 将代入该角色来访问 Amazon Glue 和 Lake Formation API。为此,我们创建了以下策略和角色:
第 1 步:创建策略并将其命名为 "irc-glue-lf-policy"。以下是通过亚马逊云科技管理控制台执行此操作的一些步骤:
1.1。打开 IAM 控制台。
1.2。在控制台的导航窗格中,选择策略,然后选择创建策略选项。
1.3。在策略编辑器中,选择 JSON 并粘贴以下策略。
1.3.1。将以下策略中的<region>、<account-id>、<s3_table_bucket_name>和<database_name>替换为您的值。在本文的其余部分中,我们使用 "myblognamespace" 作为数据库名称。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"glue:GetCatalog",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:GetTable",
"glue:GetTables"
],
"Resource": [
"arn:aws:glue:<region>:<account-id>:catalog",
"arn:aws:glue:<region>:<account-id>:catalog/s3tablescatalog",
"arn:aws:glue:<region>:<account-id>:catalog/s3tablescatalog/<s3_table_bucket_name>",
"arn:aws:glue:<region>:<account-id>:table/s3tablescatalog/<s3_table_bucket_name>/<database_name>/*",
"arn:aws:glue:<region>:<account-id>:database/s3tablescatalog/<s3_table_bucket_name>/<database_name>"
]
},
{
"Effect": "Allow",
"Action": [
"lakeformation:GetDataAccess"
],
"Resource": "*"
}
]
}第 2 步:在 IAM 控制台中按照以下步骤创建名为 "snowflake_access_role" 的角色。
2.1。在控制台的导航窗格中,选择角色并选择创建角色选项。
2.2。选择亚马逊云科技账户。
2.3。选择 "下一步",然后选择您之前在步骤 1 中创建的名为 "irc-glue-lf-policy" 的策略。
2.4。选择 "下一步" 并输入 "snowflake_access_role" 作为角色名称。
2.5。选择创建角色。
2.6。此角色的信任关系将在稍后更新。创建角色后,您需要使用 Lake Formation 定义对该角色的访问权限。
注意:如果您对 Amazon Glue 使用加密,则必须修改策略以添加 Amazon Key Management Service (Amazon KMS) 权限。有关更多信息,请参阅在 Amazon Glue 中设置加密。
第 3 部分 使用 Lake Formation 定义访问控制
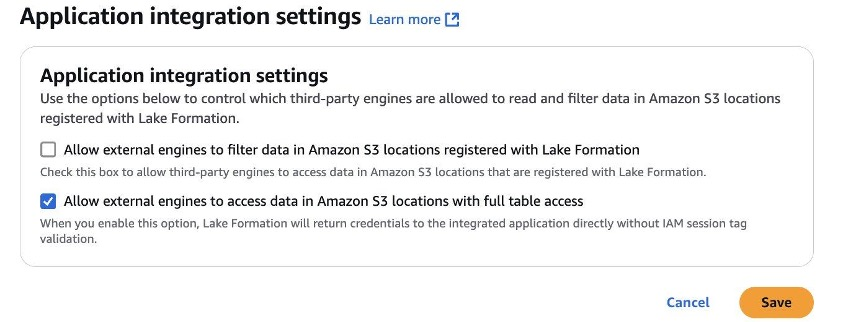
第 1 步:我们首先从应用程序集成设置开始,它允许第三方引擎访问 S3 表。在 Lake Formation 控制台中,为外部引擎启用全表访问权限以访问数据。
1.1。以数据湖管理员用户身份登录并前往 Amazon Lake Formation。
1.2。在左侧窗格中,展开 "管理" 部分
1.3。选择应用程序集成设置,然后选择允许外部引擎以全表访问权限访问 Amazon S3 位置中的数据。
1.4。单击 "保存"。
第 2 步:接下来,我们向资源上的 snowflake_access_role 授予以下权限,如下表所示。
2.1 在 Lake Formation 控制台导航窗格中,选择 "数据权限",然后选择 "授予"。
2.2。在 "委托人" 部分中,选择 "IAM 用户和角色" 单选按钮,也可以从下拉列表中选择 snowflake_access_role。
2.3。在 LF 标签或目录资源部分中,选择命名数据目录资源:
2.3.1。选择 "<accountid>:s3tablescatalog/s3tables-snowflake-integration目录"。
2.3.2。为数据库选择测试命名空间。
2.3.3。为表格选择 daily_sales。
2.4。为表权限选择 SUPER。
2.5。选择 "授予"。
通过 Lake Formation 和 IAM 进行的权限配置现已完成。接下来,我们来看看 Snowflake 的设置。
第 4 部分 在 Snowflake 中设置 SageMaker Lakehouse Iceberg REST 集成
第 1 步:以有权创建数据库和创建目录集成的管理员用户身份登录 Snowflake。
第 2 步:导航到工作表并运行以下命令,通过提供以下参数来创建数据库和目录集成。
- S3 表命名空间作为
CATALOG_NAMESPACE - SageMaker Lakehouse Iceberg REST 端点作为
CATALOG_URI AWSAccountID:s3tablescatalog/table-bucket-name作为WAREHOUSE- 为 Snowflake 创建的 IAM 角色为
SIGV4_IAM_ROLE - 将目录集成配置为
ACCESS_DELEGATION_MODE = VENDED_CREDENTIALS以使用 Lake Formation 提供的临时凭证访问数据集。将<account-id>和<region>替换为您的亚马逊云科技环境的值。
create database rest_catalog_db;
CREATE CATALOG INTEGRATION glue_rest_catalog_int
CATALOG_SOURCE = ICEBERG_REST
TABLE_FORMAT = ICEBERG
CATALOG_NAMESPACE = 'testnamespace'
REST_CONFIG = (
CATALOG_URI = 'https://glue.<region>.amazonaws.com/iceberg'
CATALOG_API_TYPE = AWS_GLUE
WAREHOUSE = '<account-id>:s3tablescatalog/s3tables-snowflake-integration'
ACCESS_DELEGATION_MODE = VENDED_CREDENTIALS
)
REST_AUTHENTICATION = (
TYPE = SIGV4
SIGV4_IAM_ROLE = 'arn:aws:iam::<account-id>:role/snowflake_access_role'
SIGV4_SIGNING_REGION = '<region>'
)
REFRESH_INTERVAL_SECONDS = 120
ENABLED = TRUE;第 3 步:按照以下步骤获取详细信息,以更新为通过 Snowflake 访问表存储桶而创建的角色的信任关系("snowflake_access_role")。
步骤 4:使用以下命令验证目录集成。
SELECT SYSTEM$VERIFY_CATALOG_INTEGRATION('glue_rest_catalog_int');

第 5 步:运行以下命令将 S3 表挂载为 Snowflake 表。
create iceberg table s3tables_dailysales
CATALOG='glue_rest_catalog_int'
CATALOG_TABLE_NAME="daily_sales"
AUTO_REFRESH = TRUE;第 5 部分 通过 Snowflake 访问 S3 表
第 1 步:以有权使用创建的目录集成的管理员用户身份登录 Snowflake。
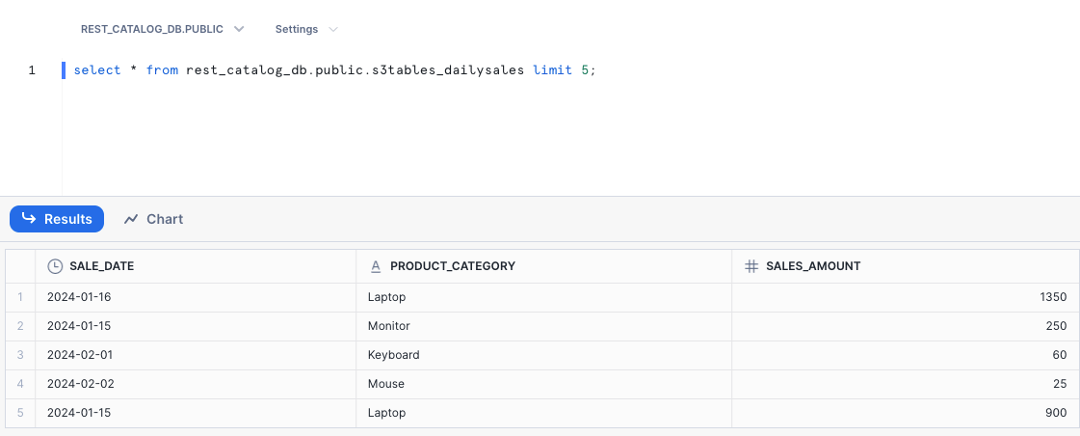
第 2 步:运行以下命令在 "S3Tables" 存储桶中查询 "s3tables_dailysales" 表。
正在清理
要清理资源,请完成以下步骤:
- 删除 S3 表。
- 删除命名空间。
- 删除 S3 表存储桶。
- 您还可以使用以下命令在 Snowflake 中删除 Iceberg 表、目录集成和数据库:
DROP ICEBERG TABLE s3tables_dailysales;
DROP CATALOG INTEGRATION glue_rest_catalog_int;
DROP DATABASE rest_catalog_db;结论
在这篇文章中,我们研究了使用 SageMaker Lakehouse Iceberg REST 端点将你的 Snowflake 环境连接到查询 S3 表。将 Snowflake 与亚马逊云科技相结合,您可以通过多种选择来构建交易数据湖,用于分析和其他用例,例如数据共享和协作。

阿里特拉·古普塔
阿里特拉·古普塔是亚马逊云科技 Amazon S3 团队的高级技术产品经理。他帮助客户建立和扩展数据湖。居住在西雅图的他喜欢在业余时间下象棋和打羽毛球。

Jeemin Sim
Jeemin Sim 是 Snowflake 的产品经理,专注于简化数据架构,帮助组织使用 Snowflake 释放开放格式的全部潜力。Jeemin 还喜欢吃美味的食物,也喜欢和她的橙色猫咪利奥共度时光。

迪帕拉·阿加瓦尔
Deepmala Agarwal 担任亚马逊云科技数据专家解决方案架构师。她热衷于帮助客户在亚马逊云科技上构建可扩展、分布式和数据驱动的解决方案。工作之余,Deepmala 喜欢与家人共度时光、散步、听音乐、看电影和做饭!

弗兰克·达勒佐特
Frank Dallezotte 是亚马逊云科技的高级解决方案架构师,他热衷于与独立软件供应商合作,在亚马逊云科技上设计和构建可扩展的应用程序。他具有创建软件、实施构建管道和在云端部署这些解决方案的经验。

Srividya Parthasarathy
Srividya Parthasarathy 是 Amazon Lake Formation 团队的高级大数据架构师。她与产品团队和客户合作,为他们的分析数据平台构建强大的功能和解决方案。她喜欢构建数据网格解决方案并与社区共享。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。