我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
在亚马逊 SageMaker 上连接亚马逊 EMR 和 rStudio
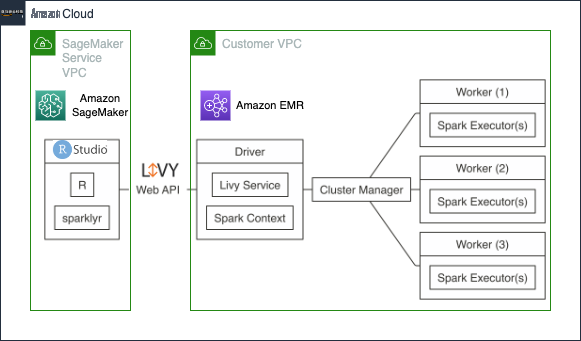
结合使用 SageMaker 上的 RStudio 等工具,用户可以分析、转换和准备大量数据,这是数据科学和机器学习工作流程的一部分。数据科学家和数据工程师使用在
在这篇文章中,我们将演示如何将 SageMaker 域上的 RStudio 与 EMR 集群连接起来。
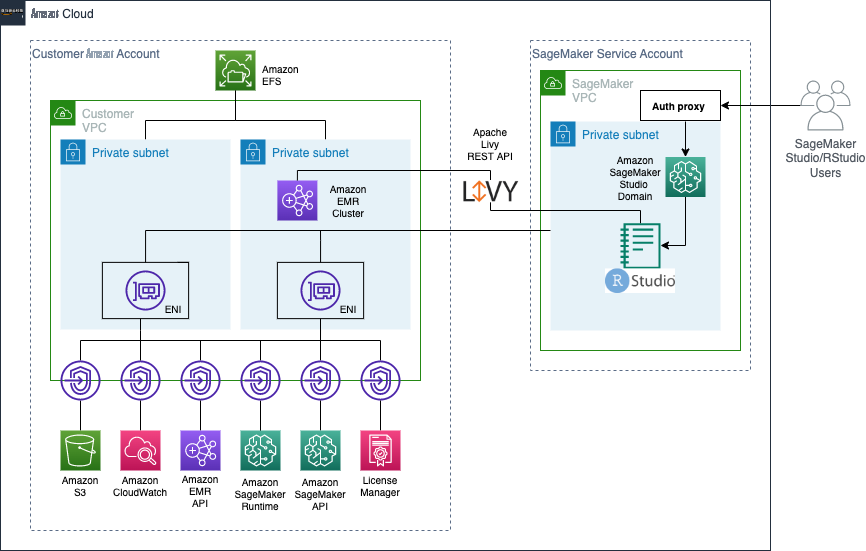
解决方案概述
我们使用
帖子中演示的所有代码都可以在我们的
先决条件
在部署任何资源之前,请确保您满足在 SageMaker 和 Amazon EMR 上设置和使用 RStudio 的所有要求:
-
Studio 工作台许可证 -
具有
亚马逊 EMR 权限的 AWS 身份和访问管理 (IAM) 角色
我们还将在 SageMaker 镜像上构建一个自定义 RStudio,因此请确保你已运行 Docker 并拥有所有必需的权限。有关更多信息,请参阅
使用 亚马逊云科技 CloudFormation 创建资源
我们使用 A
如果您已经有 RStudio 域和现有 EMR 集群,则可以跳过此步骤,开始在 SageMaker 映像上构建自定义 RStudio。用您的 EMR 集群和 rStudio 域的信息代替本节中创建的 EMR 集群和 rStudio 域。
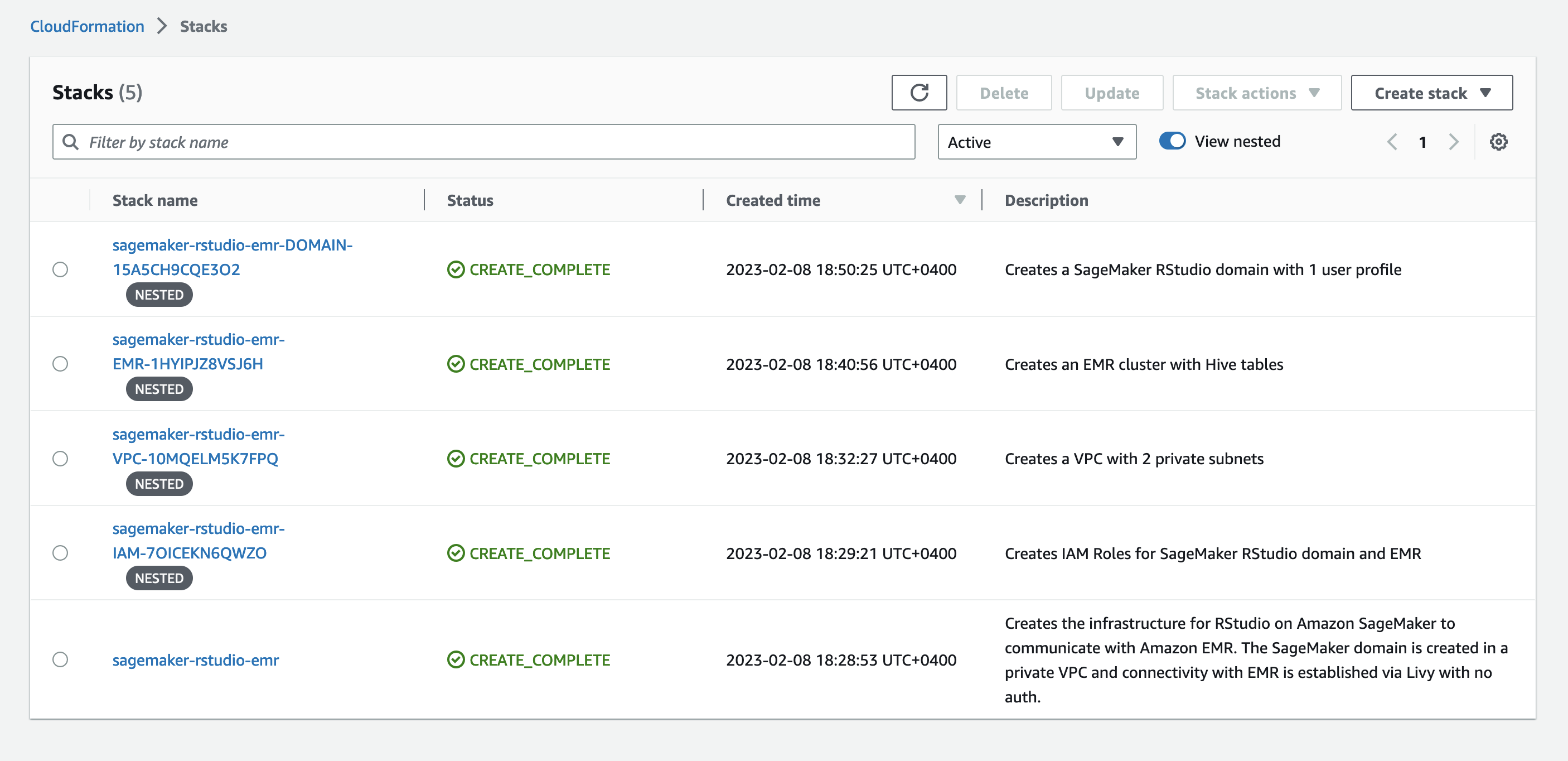
启动此堆栈会创建以下资源:
- 两个私有子网
- EMR Spark 集群
-
亚马逊云科技 Glu e 数据库和表 - 带有 rStudio 的 SageMaker
- SageMaker rStudio 用户个人资料
- SageMaker rStudio 域的 IAM 服务角色
- SageMaker rStudio 用户个人资料的 IAM 服务角色
完成以下步骤来创建您的资源:
选择 “ 启动堆栈 ” 来创建堆栈。
![]()
- 在 创建堆栈 页面上,选择 下一步 。
- 在 指定堆栈详细信息 页面上,为您的堆栈提供一个名称并将剩余选项保留为默认值,然后选择 下一步 。
- 在 配置堆栈选项 页面上,将选项保留为默认值,然后选择 下一步 。
- 在 “ 查看” 页面上 ,选择
- 我承认 亚马逊云科技 CloudFormation 可能会使用自定义名称创建 IAM 资源,并且
- 我承认 亚马逊云科技 CloudFormation 可能需要以下功能: CAPABILITY_AUTO_EXPAND。
- 选择 创建堆栈 。

该模板生成五个堆栈。
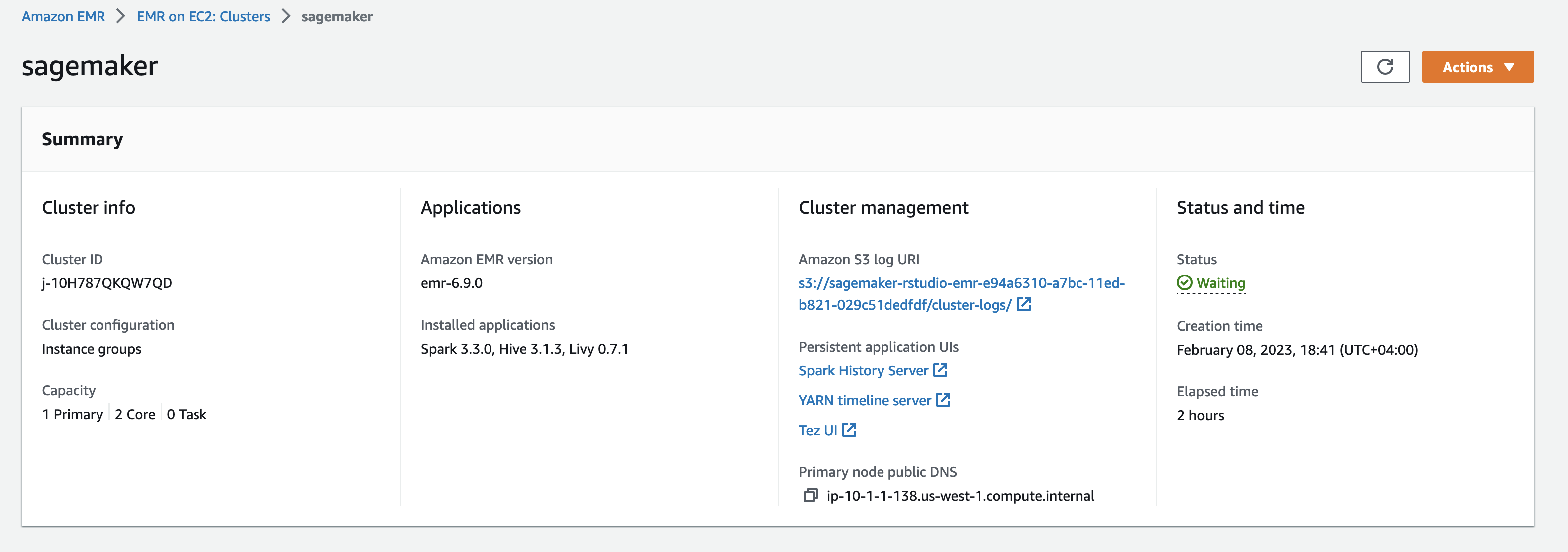
要查看已创建的 EMR Spark 集群,请导航到亚马逊 EMR 控制台。你会看到一个为你创建的集群,名为
sag
emaker。这是我们通过 SageMaker 上的 rStudio 连接到的集群。
在 SageMaker 映像上构建自定义 rStudio
我们已经创建了一个自定义镜像,它将安装 sparklyr 的所有依赖关系,并将与我们创建的 EMR 集群建立连接。
如果您使用自己的 EMR 集群和 RStudio 域,请相应地修改脚本。
确保 Docker 正在运行。首先进入我们的项目存储库:
我们现在将构建 Docker 镜像并将其注册到我们的 SageMaker 域上的 rStudio。
- 在 SageMaker 控制台上, 在导航窗格中选择 域名 。
-
选择域名
选择 rstudio域名。 -
在 “
环境
” 选项卡上,选择 “
附加图像”。
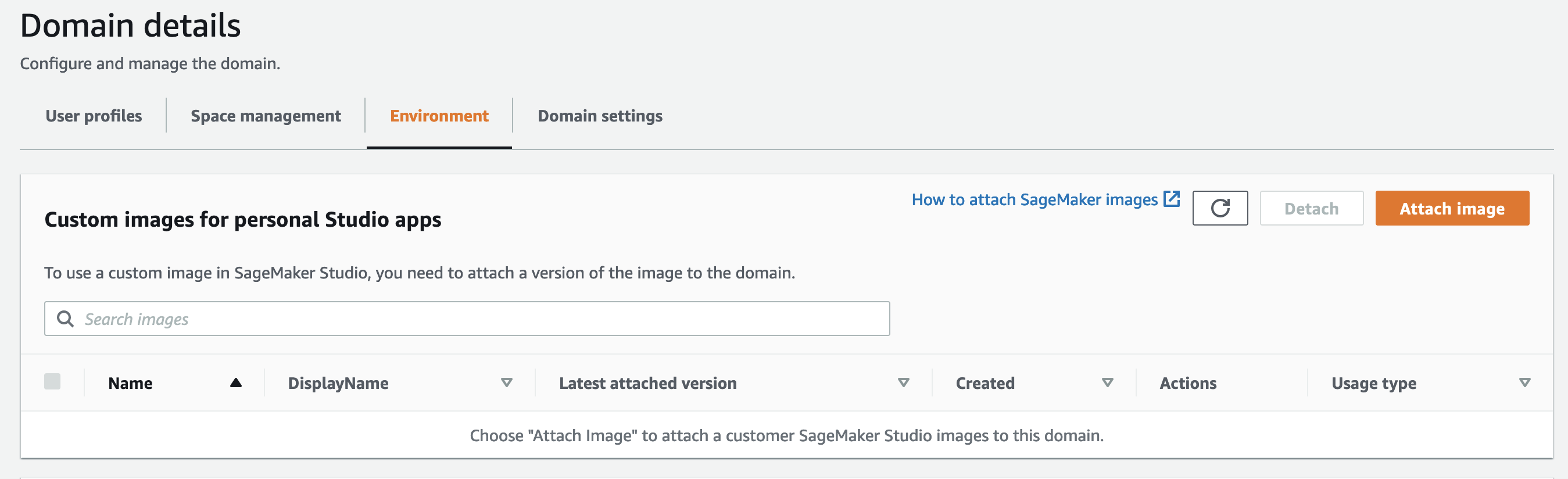
现在,我们将之前创建的 sparklyr 图像附加到域中。 - 对于 “选择图像源 ” ,选择 “ 现有图像 ” 。
-
选择我们构建的 sparklyr 图像。
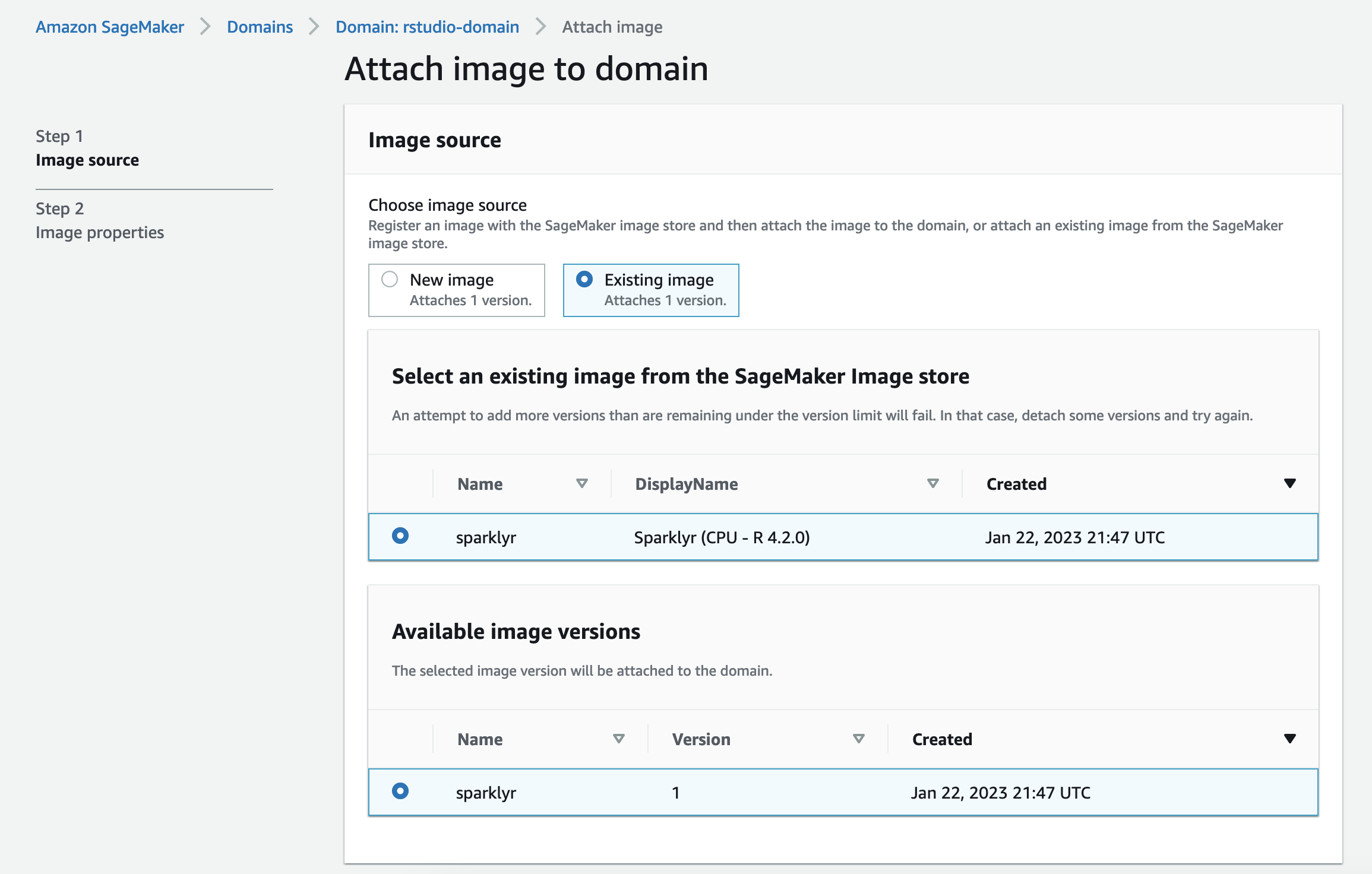
- 对于 图像属性 ,将选项保留为默认值。
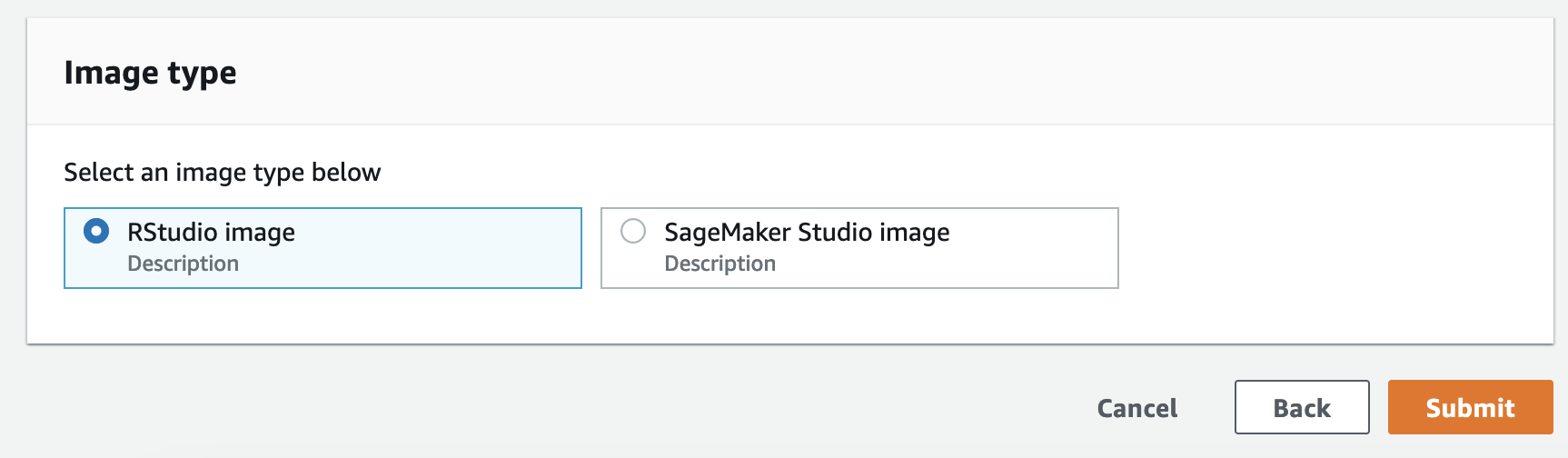
- 对于 “ 图像类型 ” ,选择 rStudio 图像 。
-
选择 “
提交
” 。
验证图像已添加到域中。图像可能需要几分钟才能完全附上。
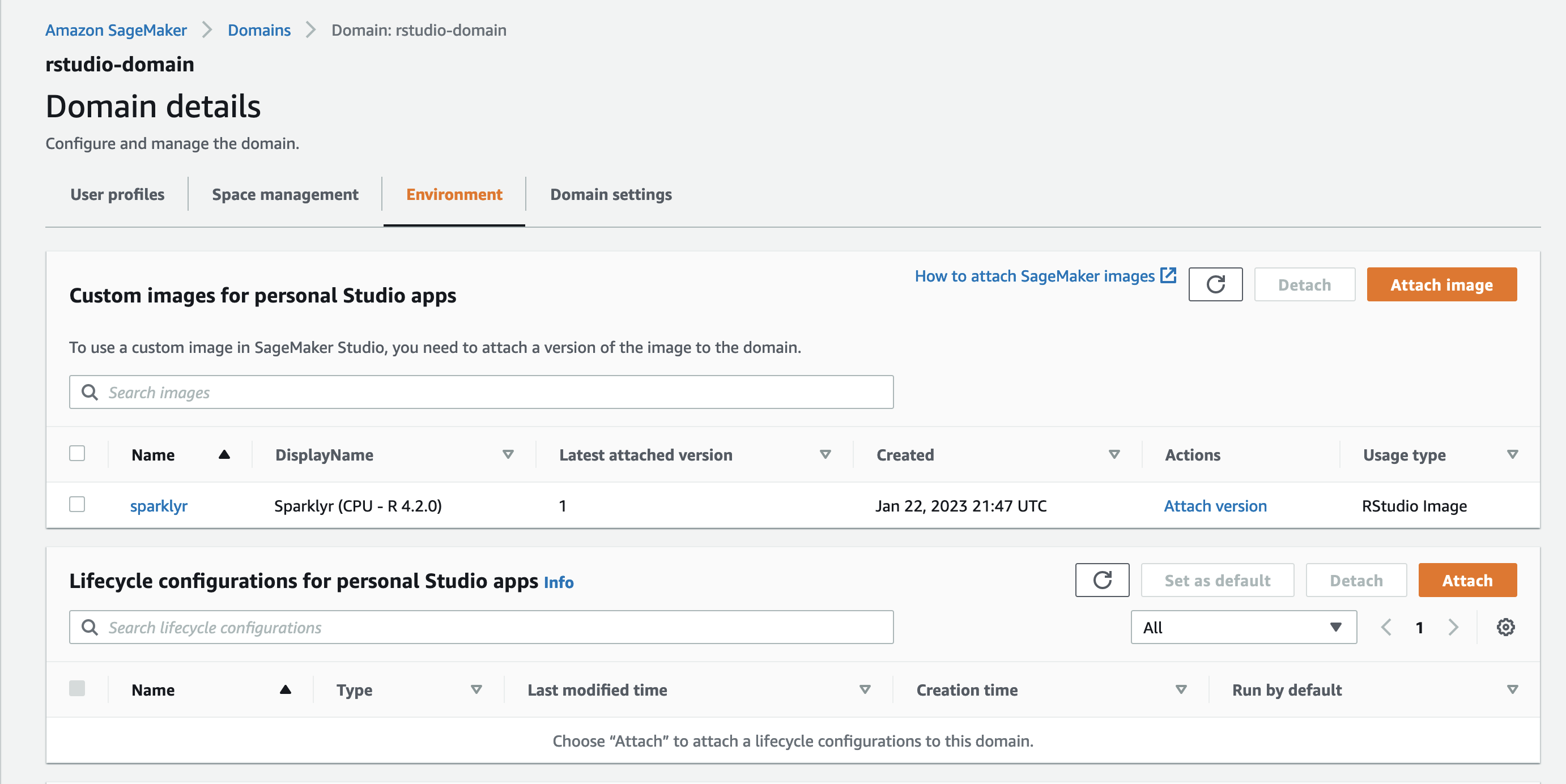
-
当它可用时,使用创建的 rstudio 用户配置文件登录到 SageMaker 控制台上的
rStudio。 -
从这里开始,使用我们之前创建的 sparklyr 图像创建一个会话。
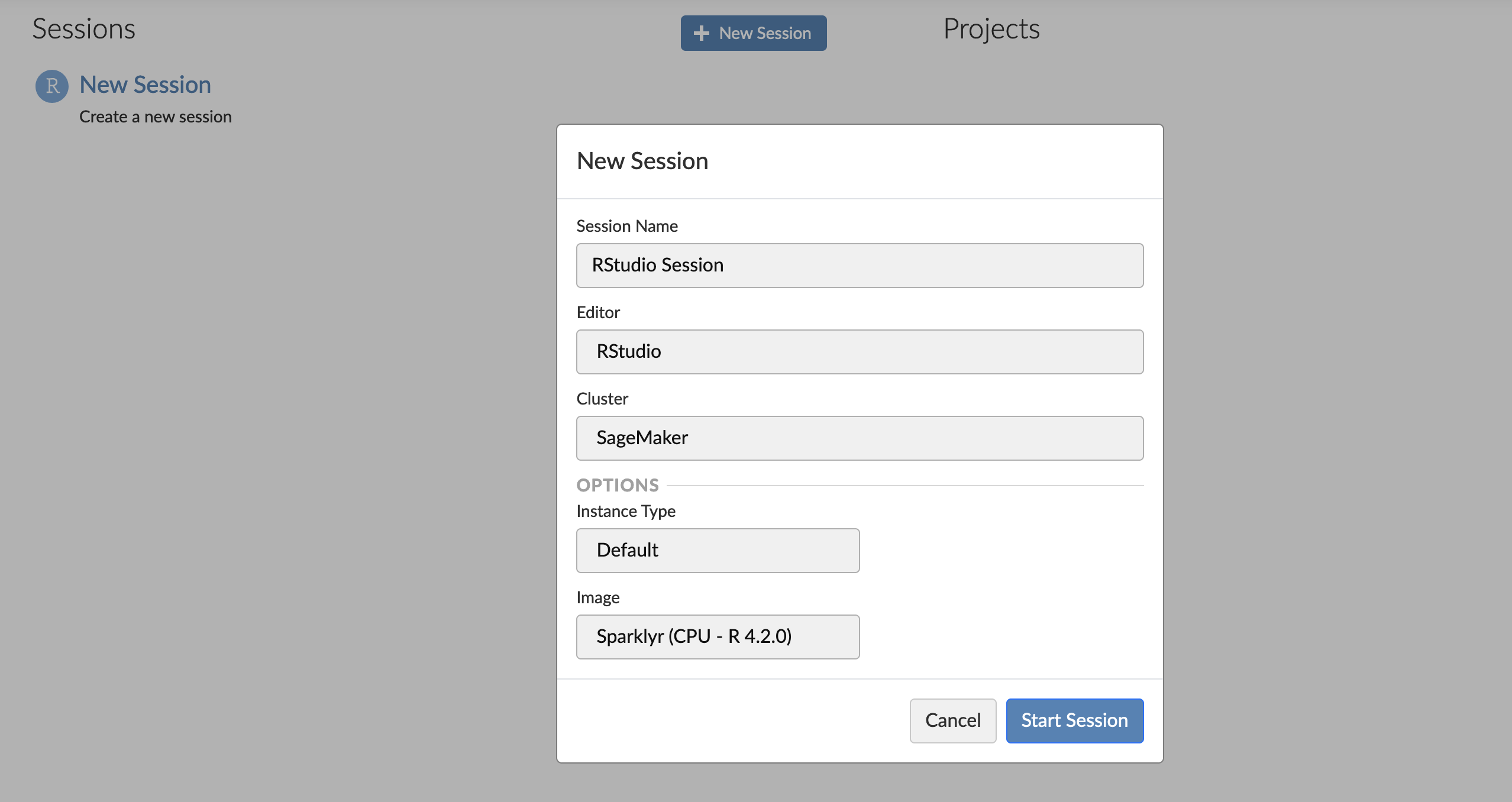
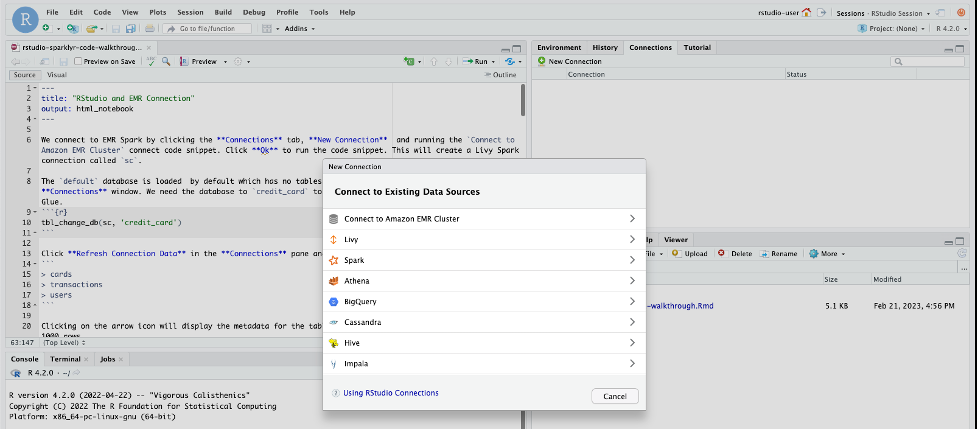
首先,我们必须连接到我们的 EMR 集群。 - 在 “连接” 窗格中,选择 “ 新建连接 ” 。
-
选择 EMR 集群连接代码片段,然后选择
连接到 Amazon EM
R 集群。
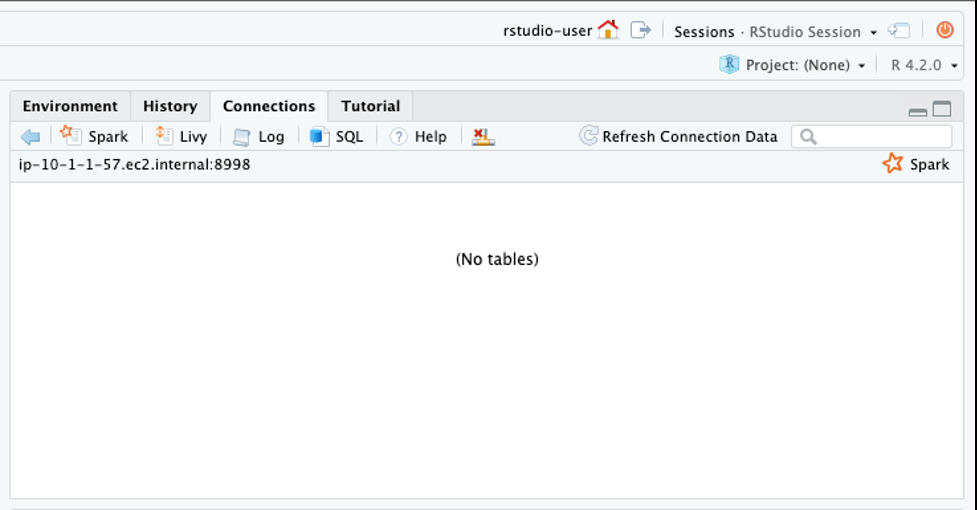
连接代码运行后,你会看到通过 Livy 进行的 Spark 连接,但看不到表。
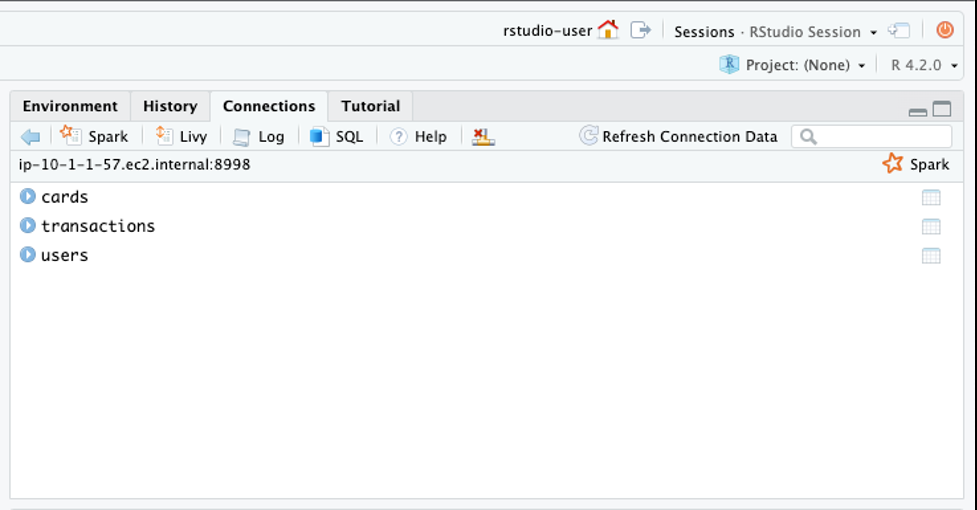
-
将数据库更改为
credit_card : tbl_
change_db (sc,“credit_card”) -
选择 “
刷新连接数据
” 。
你现在可以看到表格了。
-
现在导航到 rstudio-sparkly
r-code-walkthroughrough.md 文件。
它有一组 Spark 转换,我们可以在信用卡数据集上使用,为建模做好准备。以下代码是摘录:
让我们来
计算 ()
交易表中有 多少笔交易。但首先我们需要缓存使用
tbl ()
函数。
让我们计算一下每个表的行数。
现在,让我们将表注册为 Spark 数据帧并将它们拉入集群范围的内存缓存中以提高性能。我们还将筛选每个表放在第一行的标题。
要查看命令的完整列表,请参阅 rstudio-sparkly
r-code-walkthrough.md 文件
。
清理
要清理任何资源以避免产生经常性费用,请删除根 CloudFormation 模板。还要删除所有已创建的
结论
SageMaker 上的 rStudio 与亚马逊 EMR 的集成为云端数据分析和建模任务提供了强大的解决方案。通过在 SageMaker 上连接 RStudio 并在 EMR 上建立 Livy 与 Spark 的连接,您可以利用这两个平台的计算资源来高效处理大型数据集。rStudio 是用于数据分析的最广泛使用的 IDE 之一,它允许您利用 SageMaker 的完全托管的基础架构、访问控制、网络和安全功能。同时,在 Amazon EMR 上与 Spark 的 Livy 连接提供了一种执行分布式处理和扩展数据处理任务的方法。
如果你有兴趣进一步了解如何一起使用这些工具,这篇文章可以作为起点。欲了解更多信息,请参阅
作者简介

瑞安·加纳 是 亚马逊云科技 专业服务的数据科学家。他热衷于帮助 亚马逊云科技 客户使用 R 来解决他们的数据科学和机器学习问题。

 Saiteja Pudi
是总部位于德克萨斯州达拉斯的 亚马逊云科技 的解决方案架构师。他在 亚马逊云科技 工作了 3 年多,通过成为客户值得信赖的顾问,帮助他们发挥 亚马逊云科技 的真正潜力。他来自应用程序开发背景,对数据科学和机器学习感兴趣。
Saiteja Pudi
是总部位于德克萨斯州达拉斯的 亚马逊云科技 的解决方案架构师。他在 亚马逊云科技 工作了 3 年多,通过成为客户值得信赖的顾问,帮助他们发挥 亚马逊云科技 的真正潜力。他来自应用程序开发背景,对数据科学和机器学习感兴趣。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。