我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
捕获和调整适用于 SQL Server 的亚马逊 RDS 的资源利用率指标
捕获数据库资源利用率可帮助您了解数据库工作负载特征和使用趋势。这些数据可作为参考点,可以与以后的测量结果进行比较,以识别和研究性能问题。偏差可能表明存在需要性能优化、数据库维护或配置更改的关注领域。
资源利用率通常捕获影响数据库性能的指标,例如操作系统和数据库使用情况、数据库等待事件和查询处理时间。在正常业务过程中定期收集这些数据可以让您深入了解数据库实例的运行状况。
Amazon RDS 提供以下监控工具来帮助了解您的 RDS 实例的资源利用率:
-
亚马逊 RDS 增强监控 -
亚马逊 RDS 性能洞察
在这篇文章中,我们演示了如何在
亚马逊 RDS 增强监控
增强监控为您的数据库实例运行的操作系统提供实时指标。这些指标可以精确到 1 秒,并且可以通过 Amazon RDS 控制台或 API 进行访问。增强监控从数据库实例上的代理收集指标,而 CloudWatch 则在虚拟机管理程序层收集指标。要了解更多信息,请单击以下有关
您可能想知道要捕获性能指标多长时间。理想情况下,您希望在重要周期(例如高峰工作时间、正常运营以及每月作业处理等定期事件)中捕获足够的信息。默认情况下,增强监控指标在 CloudWatch 日志中存储 30 天,但您可以延长此期限。
以下是一些关键指标:
- CPU 利用率 -监控 CPU 利用率可帮助您确定性能问题是否由 CPU 压力引起。例如,如果您发现 CPU 利用率在出现性能问题时为 80%,而上周同一时间 CPU 利用率相似,没有报告任何问题,那么 CPU 很可能不是瓶颈。
-
磁盘
-您可以使用读取、写入 IOPS 等指标来跟踪 I/O 和存储使用模式,以确定趋势。这也有助于在存储容量规划期间从
gp2 和io 1 磁盘等可用卷类型中进行选择。 - 内存 -许多性能问题可能与内存瓶颈有关。借助增强监控,您可以跟踪系统(总内存和可用内存)和 SQL Server(SQL Server 总内存)内存使用情况和模式,以识别瓶颈。
- 网络 -增强监控收集的网络性能指标(网络读取 Kb/s 和网络写入 Kb/s)可用于跟踪通过网络传输的数据量。
通过这些指标,您可以很好地了解业务流程中重要的日子和时刻的资源利用率。这些值可以提供资源利用率的整体视图,当需要进行比较以确定潜在的瓶颈时,这可能会派上用场。
您可以在 CloudWatch 中创建控制面板,以便集中查看所讨论的这些性能指标。以下屏幕截图显示了包含来自 CloudWatch 和增强监控数据的合并控制面板。
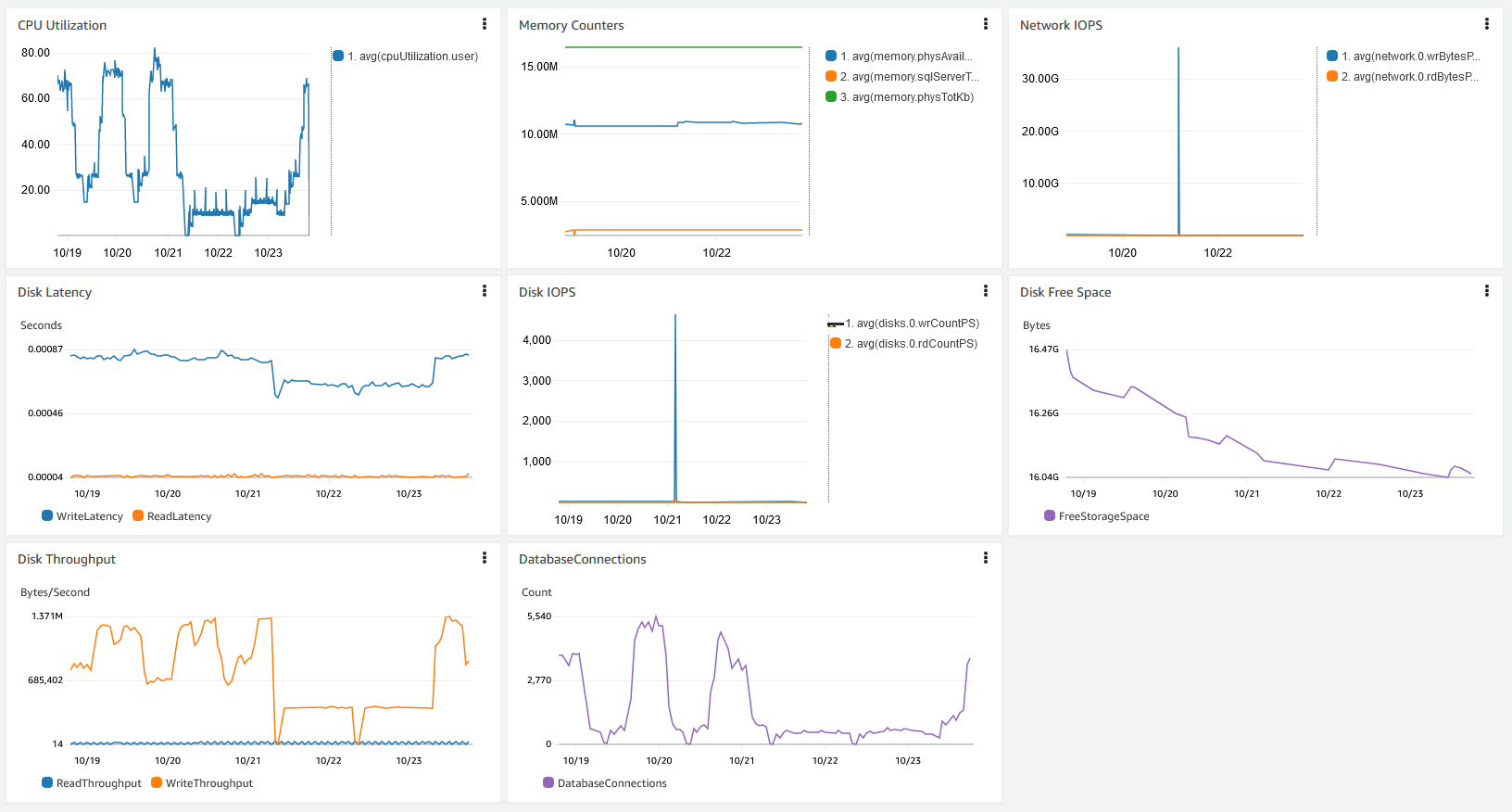
亚马逊 RDS 性能洞察
性能洞察是一种监控工具,可深入了解 RDS 数据库性能。性能洞察的免费套餐每秒从 RDS 数据库收集数据,并保留 7 天。对于长期业绩趋势,您可以将滚动绩效数据历史记录延长至两年。对于每个 RDS 数据库引擎,性能洞察根据引擎的原生性能指标显示的信息略有不同。借助 Performance Insights,您可以收集一段时间内的数据库负载、最长等待类型和热门 SQL 查询的趋势。您可以使用此信息与当前数据进行比较,以找出潜在的根本原因。
大多数 SQL Server 数据库管理员都熟悉用于诊断和调试 SQL Server 问题的动态管理视图 (DMV)。使用 DMV 可以按原样收集数据,因此您需要开发机制来了解利用率趋势。这就是 Performance Insights 通过自动收集和保留数据来提供帮助的地方。
以下是一些关键指标:
-
访问方法-页面拆分
-这可能会导致 I/O 瓶颈,较高的数字可能表示需要进行维护活动,例如重建索引并可能重新访问
填充 系数设置。 - 块和锁 -锁定争用可能会导致 SQL Server 出现性能问题,因此跟踪这些信息非常重要,这不仅是为了进行趋势分析,也是为了发现需要调整以提高数据库性能的 SQL。您可以跟踪已阻止的进程和死锁的数量。
- 内存管理器 — 待处理的内存授权可以帮助跟踪一段时间内的内存瓶颈。
- SQL 统计信息 — 性能洞察中提供了各种 SQL 统计信息,可帮助您了解导致正常数据库负载的任务,例如批量请求、SQL 编译和 SQL 重新编译。
- 缓冲区管理器 -页面预期寿命和缓冲区缓存命中率可以帮助您检测内存压力。Pages Read vs Pages Writes 可以为优化路径提供指导,例如,是否需要审查索引。
这些指标提供了对 SQL Server 性能的见解。您可以深入研究操作系统和数据库指标,包括性能指标,以了解问题的根本原因。以下屏幕截图显示了这些指标的示例。
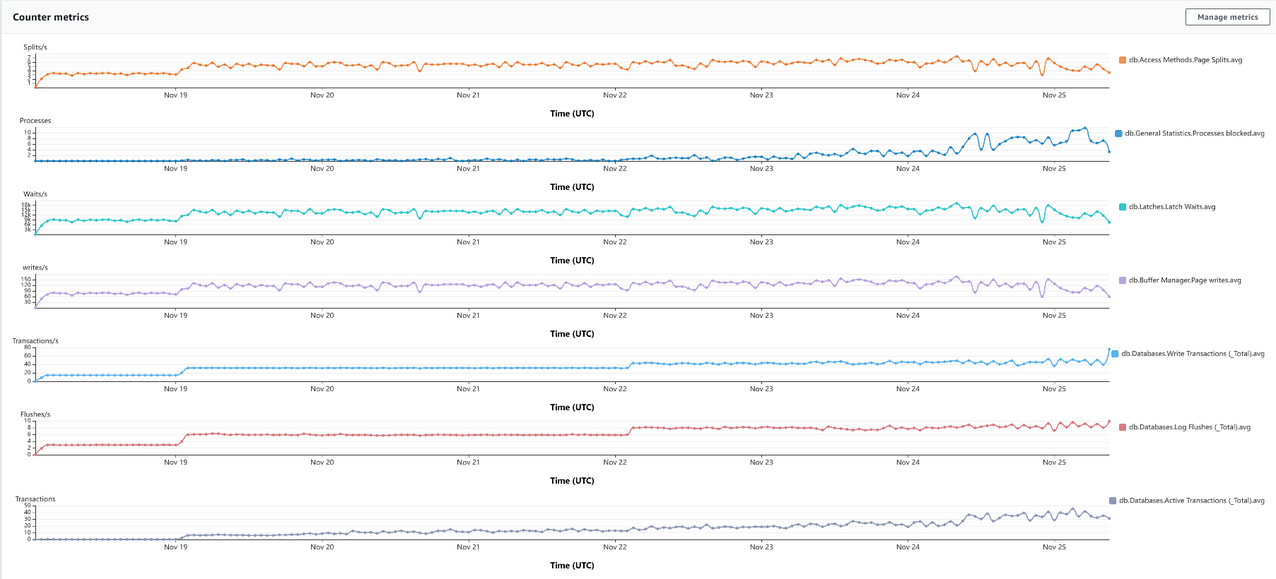
DMV 和查询存储
发现异常后,可以使用 DMV 深入调试性能问题。有关更多信息,请参阅
从 SQL Server 2016 开始,适用于 SQL Server 的亚马逊 RDS 还支持查询存储,您可以使用查询存储来跟踪和管理 SQL 语句的查询计划。有关更多信息,请参阅适用于
诊断和调试问题:CPU 利用率
让我们来看一个常见的场景,即直到昨天,应用程序的性能一直处于最佳状态,而现在却遇到了性能下降的情况。在此用例中,您是通过 CloudWatch 警报或用户投诉了解到的。
您可以通过调查指标开始诊断问题。使用 CloudWatch,您可以看到 CPU 利用率指标很高,可能超过 90%。您想知道 SQL Server 进程是否是造成高百分比的原因。您可以通过 Amazon RDS 控制台的 “ 监控 ” 选项卡上的 “ 进程列表 ” 下执行此操作 。
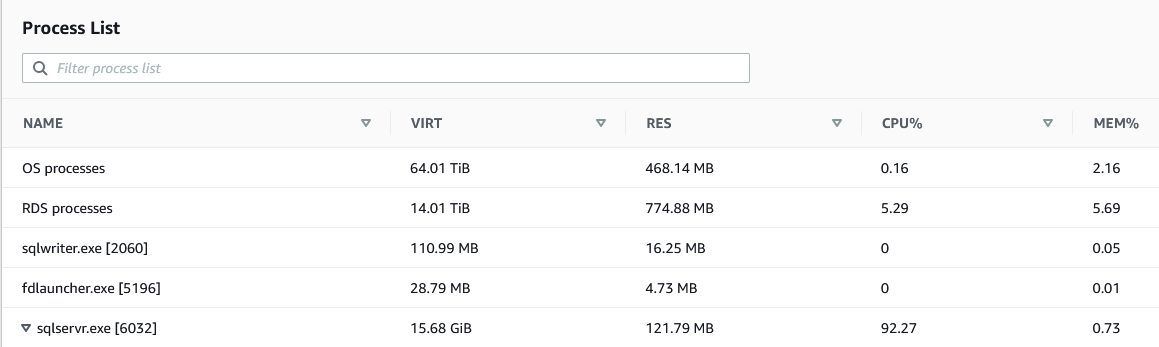
这是跟踪 RDS 实例的资源利用率可以提供帮助的地方。通过捕获的数据,可以高效地识别随时间推移的 CPU 使用率趋势。使用增强监控,您可以绘制过去 30 天内实例的 CPU 使用率趋势图,这可能会告诉您这是否正常。
下一步是使用性能洞察中捕获的数据来识别造成 CPU 负载的查询。以下屏幕截图显示了一段时间内累积的数据的图表。
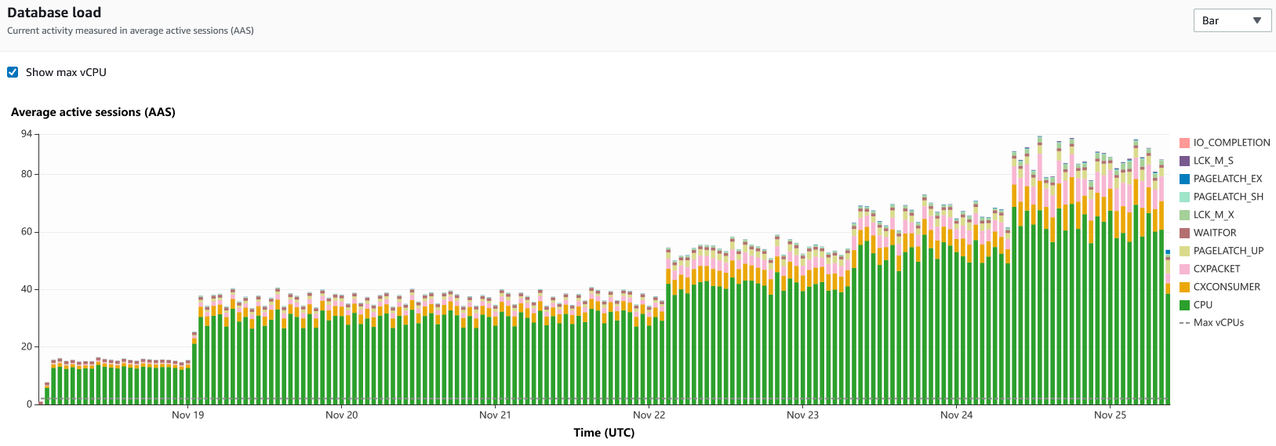
根据图表,我们可以看到 CPU 是实例上最大的等待类型,并且它在一段时间内有所增长。该趋势还提供了容量规划所需的数据。
您可以缩小到感兴趣的时间范围,查看按 CPU 利用率排列的前 T-SQL 查询列表。您可以从 DMV 获取运行计划和有关查询的更多详细信息。
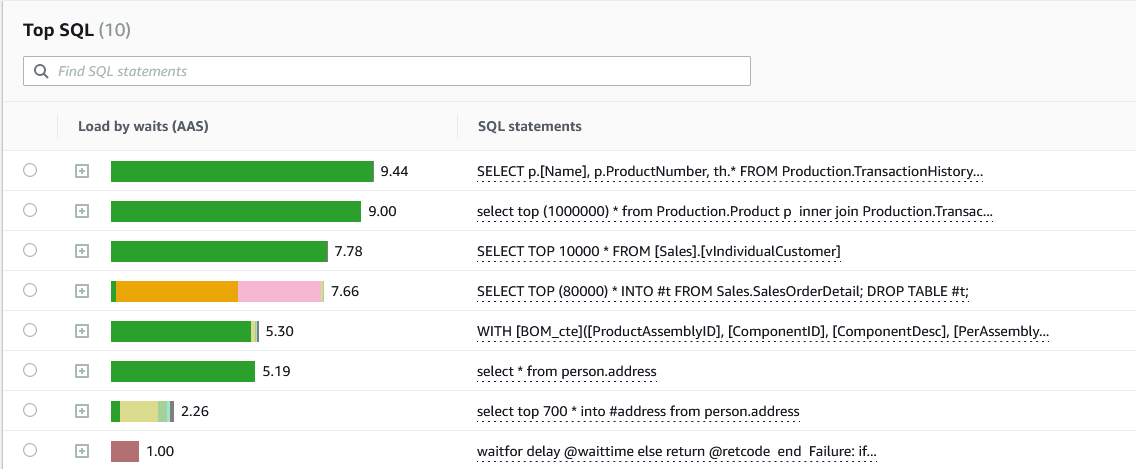
我们设法确定了导致高 CPU 负载的前三个查询。除了查询本身,您还可以识别运行查询的顶级主机和顶级用户,以进一步缩小故障排除范围。
我们以第一个查询为例。要通过 SQL Server 管理工作室 (SSMS) 获取查询运行统计数据和运行计划,您首先需要知道查询的指纹。你可以从绩效洞察中获得这些信息。
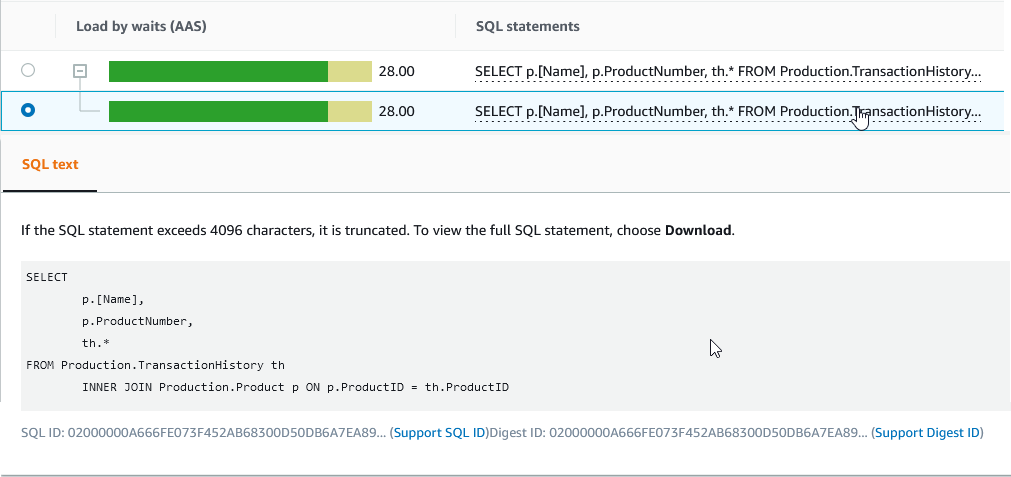
SQL ID 是您提供给 DMV 以获取统计数据和运行计划的值。您需要在 SQL ID 前面加上 0x,如以下屏幕截图所示。
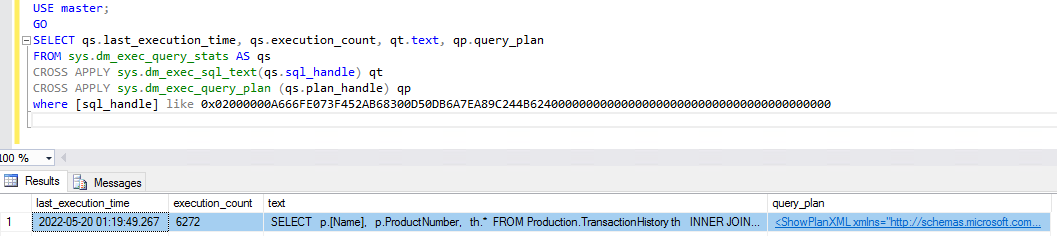
制定查询计划后,下一步是使用已知的查询优化
结论
在这篇文章中,我们了解了 Amazon RDS for SQL Server 的增强监控和性能洞察,它为你提供了一种捕获和分析实例运行状况和使用模式的好方法。获得这些信息可以帮助您优化和解决性能问题。你可以使用这篇文章中的方法来帮助你提高实例的性能。
如果您有任何意见或问题,请将其留在评论部分。
作者简介
 Barry Ooi
是 亚马逊云科技 的高级数据库专家解决方案架构师。他的专长是使用云原生服务为客户设计、构建和实施数据平台,这是他们使用 亚马逊云科技 之旅的一部分。他感兴趣的领域包括数据分析和可视化。在业余时间,他喜欢音乐和户外活动。
Barry Ooi
是 亚马逊云科技 的高级数据库专家解决方案架构师。他的专长是使用云原生服务为客户设计、构建和实施数据平台,这是他们使用 亚马逊云科技 之旅的一部分。他感兴趣的领域包括数据分析和可视化。在业余时间,他喜欢音乐和户外活动。
 丽塔·拉达
是亚马逊网络服务的微软专家高级解决方案架构师,在许多微软技术领域拥有20多年的经验。她擅长在 SQL Server 和其他数据库中设计数据库解决方案。她为客户提供架构指导,帮助他们将 Microsoft 工作负载迁移到 亚马逊云科技 并使其现代化。
丽塔·拉达
是亚马逊网络服务的微软专家高级解决方案架构师,在许多微软技术领域拥有20多年的经验。她擅长在 SQL Server 和其他数据库中设计数据库解决方案。她为客户提供架构指导,帮助他们将 Microsoft 工作负载迁移到 亚马逊云科技 并使其现代化。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。