我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用原生控件在 Amazon S3 上构建多写器应用程序
管理数据湖的组织通常需要额外的基础架构来支持来自多个应用程序的并发写入。传统方法需要外部系统进行协调,从而增加了基础架构开销、成本和潜在的性能瓶颈。开发人员通常使用数据库或专用的锁定服务来实现客户端锁定机制,从而产生复杂的多步骤工作流程。
Amazon S3 无需外部协调系统即可提供应对这些并发写入挑战的功能。通过条件写入及其存储桶级策略实施,组织可以直接在其存储层内实施数据一致性验证。覆盖保护是此功能的核心。ETag 反映了对象内容的变化,使其成为跟踪对象状态的理想之选。使用原生方法,例如使用 ETag 进行条件写入,无需单独的数据库或协调系统,同时保持可靠的数据一致性。
在这篇文章中,我们将探讨如何使用 S3 条件写入操作和存储分区级策略实施来构建多写入器应用程序。我们将演示如何防止意外重写、实现乐观的锁定模式和强制执行一致性要求,所有这些都无需单独的数据库或协调系统。通过实施这些模式,您可以简化架构、降低成本并提高可扩展性,同时保持数据完整性。
解决方案概述
在典型的数据湖场景中,您可以管理数据集及其元数据。例如,您的存储桶可能具有以下结构:
mybucket/
datasets/
customer_profiles/
year=2024/month=01/day=01/profile_data_001.parquet
location_events/
year=2024/month=01/day=01/location_events_001.parquet
metastore/
dataset_registry.json
该结构为包含两个关键数据集的数据分析平台提供服务:
- 该
/datasets/前缀存储实际的实木复合地板文件以及客户和位置数据。/customer_profiles/存储客户信息,例如 ID、姓名、电子邮件地址、注册日期和活动数据。/location_events/使用客户 ID、坐标和时间戳捕获地理数据点。
/metastore/前缀包含跟踪有关所有数据集的元数据的dataset_registry.json文件,例如文件位置、分区信息、记录数、架构版本和上次更新时间戳。
我们可以研究传统上如何在数据湖环境中管理数据一致性。在较早的 Hive 风格的实现中,存在两个关键的一致性要求:
/datasets/:当数据管道进程从多个来源提取信息时,您需要防止重复上传同一个数据文件。如果没有适当的控制,这些过程可能会无意中覆盖数据文件。/metastore/:每当更新数据集时,都必须更新注册表中的相应元数据以反映这种变化。多个应用程序必须能够更新注册表,同时确保每个应用程序都能看到一致的视图。如果没有适当的控制,一个应用程序可能会覆盖另一个应用程序所做的更改,从而导致注册表与实际数据文件不同步。
保持数据集及其元数据之间的这种同步关系对于数据完整性至关重要,并且需要外部系统协调访问,这会增加延迟和运营成本。例如,考虑以下流程,如图 1 所示:
- 客户端尝试通过外部服务获取锁。
- 如果成功,则客户端将从 S3 读取当前状态。
- 客户机执行修改。
- 客户端写回 S3。
- 客户端解除外部服务中的锁。
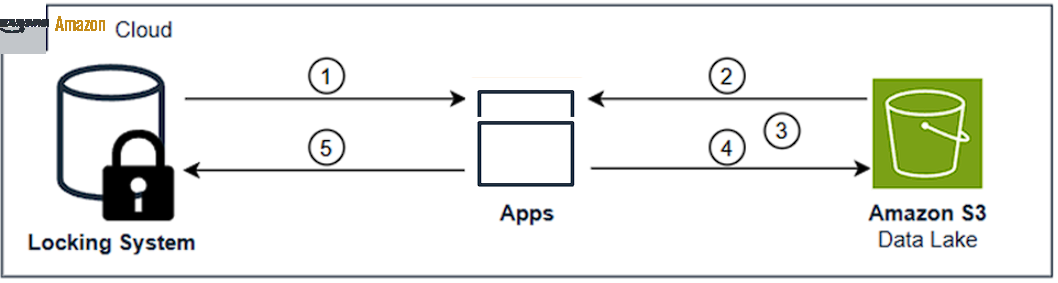
图 1:传统上数据湖中如何管理数据的一致性,锁定系统、应用程序和 S3 数据湖之间的数据流动
S3 条件写入允许您直接在存储层中满足两个不同的一致性要求,从而在数据集文件及其注册表条目之间创建协调的工作流程:
对于数据集文件(工作流程的第一步):
- 应用程序使用 If-None-Match 条件防止重复上传。这会创建一次写入语义,即如果相同的数据文件已经存在,则尝试上传该文件会失败。数据管道进程可以安全地重试操作,而无需创建重复项。
对于元数据仓中的注册表文件(工作流程的第二步):
- 成功上传数据集文件后,应用程序必须更新注册表以反映此更改。应用程序使用带有 ETag 的 If-Match 来实现比较和交换操作,只有当注册表的 ETag 与应用程序最初读取的内容相匹配时,注册表更新才会成功。多个应用程序无需外部协调即可安全地更新注册表。
这两个操作作为一个逻辑单元协同工作。首先,他们确保数据集文件只写入一次,其次,他们确保注册表准确反映所有数据集文件的当前状态。这种协调至关重要,因为注册表是所有访问数据湖的应用程序的真实来源。如果没有这种协调,应用程序可能会看到不一致的可用数据视图,或者完全错过新添加的数据集。这些一致性要求可以通过存储桶和前缀级别的存储桶策略强制执行。现在,可以使用原生 S3 控件通过简化的流程完成相同的注册表更新:
- 直接从 S3 检索注册表。
- 对注册表内容进行必要的修改。
- 使用 If-Match 条件上传修改后的注册表,以维持原子比较和交换操作。
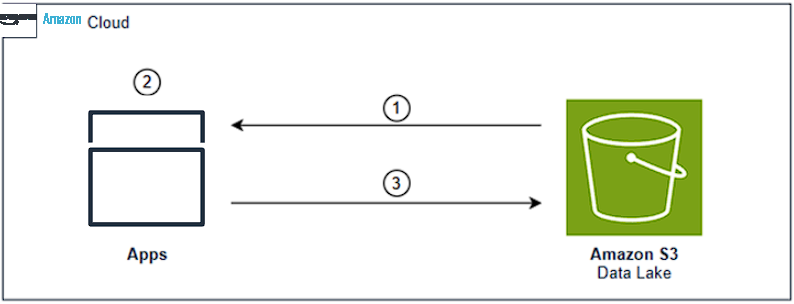
图 2:数据湖环境中的 Amazon S3 条件请求
数据湖环境中的实现模式
在本节中,我们将深入演示如何在数据湖环境中实现这些模式。我们探讨了三种展示条件写入能力的常见场景:
- 强制执行条件写入的存储桶策略:通过根据预定义的策略验证写入操作来保持数据的完整性。
- 使用 If-None-Match 创建对象:管理分区边界,同时防止重复条目。
- 使用 If-Match 进行并行元数据更新:安全地处理多个客户端同时更新共享元数据。
要查看这些模式的实际运行情况,请访问演示模拟数据湖环境的 GitHub 存储库。该演示显示了多个客户端使用条件写入与共享数据集和元数据进行交互的示例。
场景 1:强制执行存储桶策略
在执行并发写入操作之前,我们会制定存储桶策略来强制执行条件写入要求。存储桶策略强制执行条件写入要求,这对于共享环境的一致性至关重要。混合使用条件请求和非条件请求时会出现关键挑战——当多个请求同时针对同一个对象时,非条件操作可以绕过条件逻辑。如果不强制执行,一个应用程序的条件方法可能会被另一个应用程序的无条件写入所破坏。真正的并发控制要求所有请求都遵循相同的规则。
条件写入可以在您的存储桶或 IAM 策略中的存储桶或前缀级别强制执行,要求所有 PutObject 操作都包含特定的标头(If-None-Match 或 If-Match)。这样可以防止无条件请求,同时通过在没有外部机制的情况下对所有编写者强制执行一致的做法来简化应用程序开发。
以下存储桶策略可用于单一账户方案(存储桶和写入器位于同一亚马逊云科技账户中),以拒绝向特定前缀上传对象的请求,前提是这些请求不包含 If-None-Match 和 If-Match 条件。
- 对于
/datasets/前缀,我们需要 If-None-Match 条件来防止重复上传。 - 对于
/metastore/前缀,我们需要使用 If-Match 条件来进行原子更新。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "BlockNonConditionalObjectCreationOnDatasetsPrefix",
"Effect": "Deny",
"Principal": {
"AWS": "arn:aws:iam::111111111111:role/role1"
},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::my-bucket/datasets/*",
"Condition": {
"Null": {
"s3:if-none-match": "true"
},
"Bool": {
"s3:ObjectCreationOperation": "true"
}
}
},
{
"Sid": "BlockNonConditionalObjectCreationOnMetastorePrefix",
"Effect": "Deny",
"Principal": {
"AWS": "arn:aws:iam::111111111111:role/role1"
},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::my-bucket/metastore/*",
"Condition": {
"Null": {
"s3:if-match": "true"
},
"Bool": {
"s3:ObjectCreationOperation": "true"
}
}
}
]
}此示例存储桶策略假设 Amazon Identity and Access Management (IAM) 实体包含一个 IAM 策略,该策略允许对存储桶执行 s3: getObject 和 s3: PutObject 操作。
在模拟中,我们观察到存储桶策略有效地防止了对/datasets/和/metastore/前缀的未经授权的写入。任何没有必要条件(数据集为 If-None-Match,元数据库为 If-Match)的写入尝试均被拒绝,并返回 403 AccessDenied 响应。
场景 2:防止重复上传(使用 If-None-Match 检查对象是否存在)
If-None-Match 条件实现了 "一次写入" 模式,可防止覆盖现有对象。当您在 PutObject 请求中包含if-none-match:*标头时,如果存储桶中尚不存在该对象,则可以预期写入成功。这在多个应用程序正在写入共享存储且您需要验证每个对象只写入一次的情况下特别有用。在数据湖环境中,创建对象时,我们可以使用 If-None-Match 只允许一个线程成功创建标记。例如,在仿真中,我们观察到以下情况:
- 尝试该操作的第一个线程成功创建分区标记。
- 所有其他并发线程都会收到 PreconditionFailed 错误:
- S3 响应码:412
- S3 响应:前提条件失败
- S3 消息:您指定的前提条件中至少有一个不成立。
- S3 密钥:
datasets/customer_profiles/year=2024/month=01/day=01/profile_data_002.parquet.
尝试创建对象的线程会出现 PreconditionFailed 错误,因为该对象已经存在,从而防止了重复。这允许仅创建一次对象,从而保持数据一致性。遇到 PreconditionFailed 的线程会导致脚本停止重试请求,因为此响应表明该对象已经存在。使用 If-None-Match 成功创建对象后,S3 将在响应中返回 ETag。应用程序可以存储此 ETag 以备将来参考或验证。但是,对于对象创建等一次性写入场景,仅通过 PreconditionFailed 响应即可确认对象的存在。
场景 3:使用多个写入器进行元数据更新(乐观锁定并与 If-Match 进行比较和交换)
在这种情况下,我们对注册表进行并行更新。在模拟中,有三个并发线程正在尝试更新dataset_registry.json文件。每个线程都尝试使用 If-Match 条件读取当前状态、进行修改并上传更新的注册表。
注意 S3 条件写入是如何处理并发更新的:
- 一个线程在初次尝试时会立即成功,因为它是第一个写入的线程:
- 使用当前的 ETag 进行初次尝试
- 结果:成功
- 由于注册表的 ETag 已更改,其余线程会遇到先决条件故障:
- S3 响应码:412
- S3 响应:前提条件失败
- S3 响应消息:您指定的前提条件中至少有一个不成立。
- 条件详情:请求中的 ETag 与当前 S3 对象 ETag 不匹配。
- 遇到错误的线程被配置为使用重试策略重试请求,该策略获取最新的 ETag 并使用更新 ETag 重试请求。
- 解决策略:
- 获取当前注册表以获取最新的 ETag。
- 使用更新后的 ETag 重试。
- 解决策略:
当多个线程尝试更新注册表时,只有一个线程可以成功,而其他线程通常会收到 412 preconditionFailed 响应。之所以发生这种情况,是因为当对象的 ETag 自上次读取以来发生变化时,If-Match 条件失败。使用 If-Match 条件意味着当对象与预期状态匹配时,只有一个线程可以成功更新注册表,从而保持更新之间的一致性。最初失败的线程会使用更新的 ETag 重试并重新驱动操作。通过来自 S3 的反馈循环,所有线程最终都成功地使用重试策略更新了注册表。
优秀实践
在实施条件写入和存储桶级强制执行时,有几个重要的注意事项。
- 并行操作:这是指多个请求同时针对同一个对象时的时间方面。无论它们是否使用条件标头,这些并发操作都会创建竞争条件,在这种条件下,最后处理的请求通常获胜。当非条件请求在条件请求之前处理时,这可能会导致意想不到的结果。在对相同对象进行高频写入的环境中,这种风险显著增加。要缓解这种情况,请使用前面描述的存储桶策略机制对访问存储桶的所有应用程序强制执行条件写入。
- 混合请求类型:这是指不同应用程序间的方法不一致。在允许条件和非条件请求的场景中,即使操作不是并发的,也存在数据不一致的风险。例如,如果应用程序 A 使用 If-Match 进行更新,而应用程序 B 不使用条件标头,则应用程序 B 会在不检查对象当前状态的情况下覆盖更改。这造成了无条件请求可以绕过一致性控制的空白。在多个应用程序访问相同数据的环境中,这尤其成问题。为了缓解这种情况,您可以实施存储桶策略,明确拒绝任何不包含条件标头(If-None-Match 和/或 If-Match)的 PutObject 操作,从而强制所有应用程序遵循相同的一致性规则。
- 分段上传:分段上传需要特别考虑,因为它们涉及多个请求。为了缓解这种情况,存储桶策略应考虑直接的 PutObject 操作和 CompleteMultiPartUpload 请求,以保持一致性。
对于并发操作和混合请求类型,在数据一致性对应用程序功能至关重要的共享环境中,强制执行条件写入要求变得至关重要。
错误处理
错误处理需要仔细考虑,特别是对于多写入器场景中的 409 冲突和 412 前提条件失败响应。当多个写入者尝试同时修改同一个对象时,就会发生 409 冲突,而 412 前提条件失败表示请求中指定的前提条件未得到满足。例如,在 If-None-Match 请求中,该对象已经存在,而在 If-Match 请求中,该对象的状态已更改。在竞争条件下,您可能会在第一次尝试时收到 409,重试时可能会收到 412,因为另一位作者修改了该对象。应用程序需要根据错误代码实施适当的策略:
| 错误码 | 错误名称 | 场景 | 推荐的策略 |
|---|---|---|---|
| 409 | 条件请求冲突 | 多次同步更新。
对于 If-Match 条件,这表示并发操作正在争夺相同的资源。 |
重启:获取最新状态并构造新请求。在竞争条件下,您可能会在第一次尝试时收到 409,重试时可能会收到 412,因为另一位作者修改了该对象。应用程序需要根据错误代码实现重试或重试策略。 |
| 412 | 前提条件失败 | 对于 If-Match:对象自读取以来已被修改。
对于 If-None-Match:对象已经存在。 |
|
应用程序需要实施适当的重试或重启策略:
- 重试策略:使用指数退避自动再次尝试相同的操作。这对于时间冲突是暂时性的、原始请求仍然有效的操作非常有效。
- 重启策略:首先使用 HeadObject 或 GetObject API 获取当前状态以获取最新的 ETag,然后根据当前对象状态构造和提交新请求。当原始请求的条件由于对象更改而不再有效时,这是必要的。
对于分段上传,在 "完成多段上传" 操作期间会进行条件写入验证。当 CompleteMultiPartUpload 请求包含 If-Match 条件时,S3 将在完成时验证 ETag。如果条件失败,则必须实施以下重启策略:
- 获取当前对象状态。
- 确定是否结束现有的分段上传。
- 可能会在更新条件下启动新的上传。
import os
import boto3
import requests
from math import ceil
from botocore.exceptions import ClientError
import time
import xml.etree.ElementTree as ET
def generate_presigned_url(s3_client, operation_name, params, expires_in=3600):
try:
url = s3_client.generate_presigned_url(
ClientMethod=operation_name,
Params=params,
ExpiresIn=expires_in
)
return url
except Exception as e:
print(f"Error generating presigned URL for {operation_name}: {e}")
raise e
def upload_part(s3_client, file_path, bucket_name, object_name, upload_id, part_number, chunk):
try:
# Generate presigned URL for upload_part
url = generate_presigned_url(
s3_client,
'upload_part',
{
'Bucket': bucket_name,
'Key': object_name,
'PartNumber': part_number,
'UploadId': upload_id
}
)
# Upload the part using the presigned URL
headers = {'Content-Type': 'application/octet-stream'}
response = requests.put(url, data=chunk, headers=headers)
response.raise_for_status()
return {
'PartNumber': part_number,
'ETag': response.headers['ETag'],
'ChecksumSHA256': response.headers.get('x-amz-checksum-sha256')
}
except Exception as e:
print(f"Error uploading part {part_number}: {e}")
raise e
def get_object_etag(s3_client, bucket_name, object_name):
try:
url = generate_presigned_url(
s3_client,
'head_object',
{
'Bucket': bucket_name,
'Key': object_name
}
)
response = requests.head(url)
if response.status_code == 404:
return None
response.raise_for_status()
return response.headers['ETag']
except requests.exceptions.RequestException as e:
if e.response is not None and e.response.status_code == 404:
return None
raise e
def parse_upload_id_from_xml(xml_content):
root = ET.fromstring(xml_content)
# Define the namespace
namespace = {'s3': 'http://s3.amazonaws.com/doc/2006-03-01/'}
# Find the UploadId element
upload_id = root.find('.//s3:UploadId', namespace)
if upload_id is not None:
return upload_id.text
raise Exception("Failed to parse UploadId from response")
def multipart_upload_to_s3(file_path, bucket_name, object_name, max_retries=3, chunk_size=5 * 1024 * 1024):
s3_client = boto3.client('s3')
retry_count = 0
while retry_count <= max_retries:
try:
# Get current ETag before starting upload
existing_etag = get_object_etag(s3_client, bucket_name, object_name)
# Generate presigned URL for create_multipart_upload
create_mpu_url = generate_presigned_url(
s3_client,
'create_multipart_upload',
{
'Bucket': bucket_name,
'Key': object_name
}
)
# Initiate multipart upload
response = requests.post(create_mpu_url)
response.raise_for_status()
# Parse the XML response to get the upload ID
upload_id = parse_upload_id_from_xml(response.content)
print(f"Initiated multipart upload with ID: {upload_id}")
# Upload parts
parts = []
file_size = os.path.getsize(file_path)
num_parts = ceil(file_size / chunk_size)
with open(file_path, 'rb') as f:
for part_number in range(1, num_parts + 1):
chunk = f.read(chunk_size)
part = upload_part(
s3_client,
file_path,
bucket_name,
object_name,
upload_id,
part_number,
chunk
)
parts.append(part)
print(f"Uploaded part {part_number}/{num_parts}")
# Generate presigned URL for complete_multipart_upload
complete_url = generate_presigned_url(
s3_client,
'complete_multipart_upload',
{
'Bucket': bucket_name,
'Key': object_name,
'UploadId': upload_id
}
)
# Prepare completion XML
completion_xml = '<CompleteMultipartUpload>'
for part in parts:
completion_xml += f'<Part><PartNumber>{part["PartNumber"]}</PartNumber><ETag>{part["ETag"]}</ETag></Part>'
completion_xml += '</CompleteMultipartUpload>'
# Complete multipart upload with If-Match header
headers = {
'Content-Type': 'application/xml',
'If-Match': existing_etag
}
response = requests.post(complete_url, data=completion_xml, headers=headers)
response.raise_for_status()
# Parse the completion response XML to get the ETag
def parse_complete_multipart_upload_response(xml_content):
root = ET.fromstring(xml_content)
namespace = {'s3': 'http://s3.amazonaws.com/doc/2006-03-01/'}
etag = root.find('.//s3:ETag', namespace)
return etag.text if etag is not None else 'N/A'
final_etag = parse_complete_multipart_upload_response(response.content)
print(f"File uploaded successfully.")
print(f"Final ETag from S3: {final_etag}")
return {'ETag': final_etag}
except requests.exceptions.RequestException as e:
if e.response is not None and e.response.status_code == 412: # PreconditionFailed
retry_count += 1
print(f"ETag mismatch detected (Attempt {retry_count} of {max_retries})")
# Generate presigned URL for abort_multipart_upload
if 'upload_id' in locals():
abort_url = generate_presigned_url(
s3_client,
'abort_multipart_upload',
{
'Bucket': bucket_name,
'Key': object_name,
'UploadId': upload_id
}
)
requests.delete(abort_url)
if retry_count <= max_retries:
print("Object was modified during upload. Retrying with updated ETag...")
time.sleep(2 * retry_count)
continue
else:
print("Max retries exceeded")
raise Exception("Failed to upload file after maximum retries")
else:
raise e
except Exception as e:
print(f"Error during multipart upload: {e}")
if 'upload_id' in locals():
abort_url = generate_presigned_url(
s3_client,
'abort_multipart_upload',
{
'Bucket': bucket_name,
'Key': object_name,
'UploadId': upload_id
}
)
requests.delete(abort_url)
raise e
if __name__ == "__main__":
file_path = "/tmp/large_file"
bucket_name = "my-bucket"
object_name = "large_file"
try:
multipart_upload_to_s3(file_path, bucket_name, object_name)
except Exception as e:
print(f"Upload failed: {e}")
}使用版本控制存储桶时,还会考虑其他注意事项,例如删除标记和特定版本的 ETag 的处理。应用程序在设计时需要意识到这些行为,尤其是在实现版本感知工作流程或维护对象修改的审计记录时。我们建议在各种并发访问模式和错误条件下测试应用程序的行为。这包括模拟多个作者尝试并行修改,测试不同错误场景的重试和重试策略,验证分段上传冲突的处理是否正确,以及验证版本控制存储桶中特定版本的 ETag 处理。
正在清理
要清理本文中使用的资源,请导航到 S3 控制台,选择您创建的存储桶,选择 Empty 以删除所有对象。清空后,再次选择该存储桶,然后选择 "删除" 将其永久删除。
结论
在这篇文章中,我们演示了 S3 的原生功能如何在没有外部协调系统的情况下应对多写入器挑战。我们探讨了三种关键的实现模式:执行存储桶策略以控制写入操作,If-None-Match 条件写入以防止重复数据集上传,以及 If-Match 的乐观锁定功能,可在共享注册表中实现安全的并发元数据更新。
S3 条件写入和存储分区级强制可在没有外部协调系统的多写入器环境中提供强大的数据一致性。这些原生功能消除了对外部数据库和自定义并发控制的需求,提供了五个关键优势:
- 架构简化:移除复杂的协调系统,实现更清晰的架构。
- 增强数据完整性:通过原子比较和交换操作防止竞争条件。
- 提高运营效率:在 ETL 工作流程中启用并行处理。
- 成本优化:减少基础设施组件和运营开销。
- 更好的性能:在保持一致性的同时消除数据库查询。
无论是实现 If-Match 以实现乐观锁定,还是实现 If-None-Match 以防止重复,这些功能都通过直接、高效的架构保持数据一致性。
要立即开始实现这些功能,请访问 S3 用户指南和我们的 GitHub 存储库获取代码示例。

Neil Mehta
尼尔·梅塔是企业绿地团队的亚马逊云科技解决方案架构师。他热衷于帮助客户构建根据其特定需求量身定制的可扩展解决方案。在业余时间,尼尔喜欢与家人共度时光,为华盛顿特区当地的运动队加油。

Harsha Battapady
哈莎·巴塔帕迪是亚马逊云科技 Amazon S3 团队的高级技术产品经理。她对所有数据都充满热情,喜欢听取客户关于他们如何扩展业务以及 S3 如何帮助他们的意见。Harsha 居住在西雅图,喜欢与家人和朋友共度时光,阅读和海滩度假。

Pichaimani Rajesh Kumar
Pichaimani Rajesh Kumar 是亚马逊云科技的解决方案架构师。他将技术知识和商业头脑相结合,帮助客户使用云解决方案解决难题。在加入亚马逊云科技之前,Pichaimani Rajesh 是 Infosys 的技术架构师,在那里他领导了一个为谷歌云客户提供网络支持的团队。Pichaimani Rajesh 居住在德克萨斯州(美国),拥有圣塔克拉拉大学工程管理硕士学位。

Suchindra Agarwal
苏钦德拉·阿加瓦尔是亚马逊云科技的高级软件工程师。他目前的重点是为 Amazon S3(简单存储服务)开发条件 API。此前,Suchindra 为实现 S3 的强一致性功能做出了贡献,并开发了各种内部协议以提高 S3 的可用性和吞吐量。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。