我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 Amazon Kinesis Data Streams 构建高度可用的数据流
由于对实时见解、低延迟响应时间以及适应最终用户不断变化的需求的能力的需求,许多用例正在转向实时数据策略。对于此类工作负载,您可以使用
Kinesis Data Streams 在单个 亚马逊云科技 区域提供 99.9% 的可用性。为了获得更高的可用性,在流媒体层内有几种策略可供探索。这篇文章比较并对比了在主要运营区域出现服务中断、延迟或中断的情况下创建高度可用的 Kinesis 数据流的不同策略。
高可用性的注意事项
在我们深入研究示例用例之前,在设计与特定管道的业务需求相关的高可用性 Kinesis Data Streams 工作负载时,需要记住几个注意事项:
- 恢复时间目标 (RTO) 由组织定义。RTO 是服务中断和服务恢复之间的最大可接受延迟。这决定了当服务不可用时,什么时间段被视为可接受的时间窗口。
- 恢复点目标 (RPO) 由组织定义。RPO 是自上一个数据恢复点以来的最大可接受时间量。这决定了从最后一个恢复点到服务中断之间的可接受的数据丢失。
一般而言,您的 RPO 和 RTO 值越低,整体解决方案的成本就越高。这是因为该解决方案需要在多个区域启动并运行多个服务实例,从而最大限度地减少数据丢失和服务不可用性。这就是为什么高可用性的重要部分是复制流经工作负载的数据。在我们的例子中,数据是在 Kinesis 数据流区域之间复制的。相反,RPO 和 RTO 值越高,您在故障转移机制中引入的复杂性就越大。这是因为,如果不在多个区域建立多个实例,则节省的成本被停机时启动这些实例所需的协调所抵消。
在这篇文章中,我们仅介绍 Kinesis 数据流的故障转移。在需要提高整个数据管道可用性的用例中,强烈建议为每个组件(
实现高可用性的最简单方法是在检测到服务不可用后,在新区域启动新的生产者、消费者和数据流实例。这里的好处主要是成本,但您的RPO和RTO值将因此更高。
我们介绍了高可用性 Kinesis 数据流的以下策略:
- 热备用 — 一种将数据从区域 A 的 Kinesis 数据流主动复制到区域 B 的架构。数据流的消费者始终在两个区域中运行。推荐用于在复制延迟之后无法承受长时间的停机时间的用例。
- 冷备用 -将数据从区域 A 中的数据流主动复制到区域 B,但是当检测到区域 A 的中断时,区域 B 中数据流的使用者会启动。推荐用于在次要区域基础架构启动时能够承受一些停机的用例。在这种情况下,RPO 将与热备用策略类似;但是,RTO 将增加。
出于高可用性目的,这些用例需要跨区域复制数据,使数据流的使用者和生产者能够在检测到服务不可用时快速进行故障转移并使用辅助区域的数据流。让我们举一个架构示例来进一步解释这些灾难恢复策略。我们使用 API Gateway 和 Lambda 向 Kinesis 数据流发布股票行情信息。
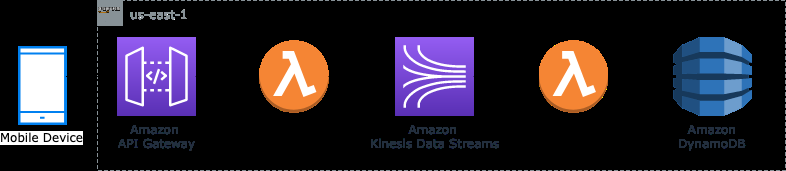
我们在此架构中使用了一个示例用例,该用例要求在区域中断时流式工作负载保持高度可用。客户可以在停机期间承受 15 分钟的 RTO,因为他们每隔 15 分钟刷新一次最终用户的仪表板。客户对停机和数据丢失很敏感,因为他们的数据将用于历史审计目的、运营指标和最终用户的仪表板。对于该客户而言,停机意味着数据无法从其流媒体层保存到其数据库中,因此任何消费应用程序都无法使用数据。对于此用例,我们的 Lambda 函数最多可以重试数据 5 分钟,然后再故障转移到新区域。当直播不可用时,消费者被视为不可用,他们可以在辅助区域扩大规模以应对任何积压的事件。
我们如何才能让 Kinesis 数据流对这个用例高度可用?
温暖的待机模式
以下架构图说明了 Kinesis 数据流的热待机高可用性模式。
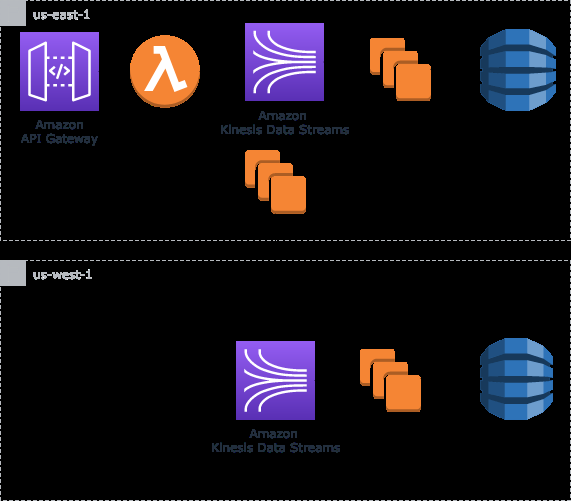
热备用架构模式包括在主区域和次要区域运行 Kinesis 数据流,同时复制主区域流媒体层的消费者和下游目的地。源配置为在第一个区域出现服务不可用时自动故障转移到辅助区域。我们将在本文的客户端故障转移部分详细介绍如何实现这一目标。数据跨区域从主区域的数据流复制到辅助区域。这样做而不是将源代码发布到两个区域,以避免两个区域中的流之间出现任何一致性问题。
尽管这种架构模式提供了非常高的可用性,但它也是最昂贵的选择,因为我们几乎要跨两个区域复制整个流媒体层。对于无法承受长时间数据丢失或无法承受停机的业务用例,这可能是他们的最佳选择。从 RTO 的角度来看,这种架构模式可确保不会出现停机。RPO 指标有一些细微差别,因为它在很大程度上取决于复制延迟。如果主流不可用,则任何尚未复制的数据都可能在辅助区域不可用。这些数据不会被视为丢失,但在主流恢复可用之前,可能无法使用。此方法还可能导致事件失序。
对于无法容忍这种记录不可用程度的业务需求,可以考虑在生产者上保留数据,以便在可用时将其发布到可用流,或者如果可能的话,针对生产者的来源倒带,以便在故障转移时可以将滞留在主区域的数据重新发送到辅助流。我们将在本文的客户端故障转移部分介绍这一注意事项。
冷待机模式
以下架构图说明了 Kinesis 数据流的冷备用高可用性模式。
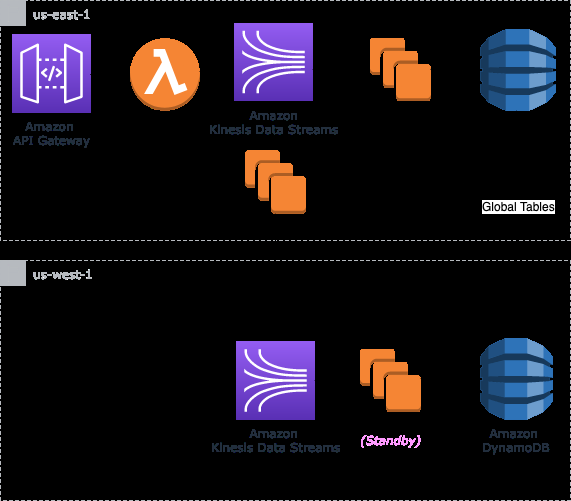
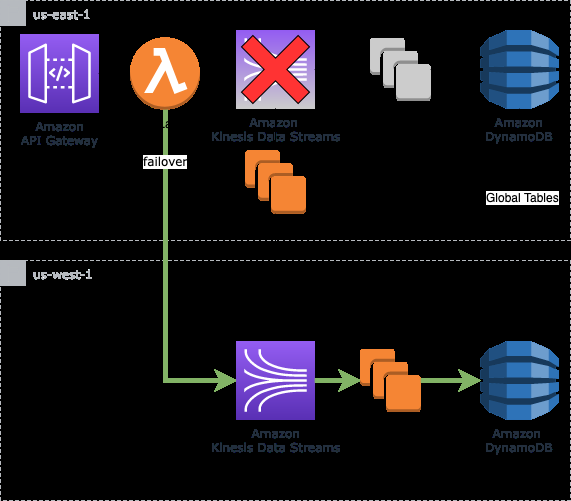
冷备用架构模式包括在主区域和辅助区域运行数据流,以及在检测到服务中断时启动下游资源,例如流的使用者和流的目的地,即被动模式。就像热备用模式一样,源配置为在第一个区域出现服务不可用时自动故障转移到辅助区域。同样,数据会跨区域从主区域的数据流复制到辅助区域。
这种架构模式提供的主要好处是成本效益。与热待机模式相比,由于不让消费者始终处于运行状态,因此可以显著降低成本。但是,在配置辅助区域基础设施时,这种模式可能会给下游系统带来一些数据不可用。此外,根据复制延迟,某些记录可能不可用,如热备用模式中所述。应该注意的是,根据启动资源所需的时间,消费者可能需要一些时间来重新处理辅助区域中的数据,故障转移时可能会出现延迟。我们的实现假设复制延迟最小,并且下游系统能够重新处理可配置的数据量以赶上数据流的尽头。我们将在客户故障转移部分讨论调用这些资源的方法,但一种可能的方法是使用
对于能够容忍一定程度的数据不可用性并且可以在辅助区域的新基础架构启动时接受中断的业务需求,无论是从成本角度还是从RPO/RTO的角度来看,这都是一个值得考虑的选项。整体解决方案的较低成本抵消了在检测到服务不可用时调配资源的复杂性。
哪种模式对我们的用例有意义?
让我们重新审视前面描述的用例,以确定哪种策略最符合我们的需求。我们可以从客户的问题陈述中提取一些信息,以确定他们需要具有以下特点的高可用性架构:
- 无法承受大量的数据丢失
- 必须在发现服务中断后的 15 分钟内恢复运营
这个标准告诉我们,他们的 RPO 接近于零,他们的 RTO 是 15 分钟。由此,我们可以确定具有数据复制功能的冷备用架构为我们提供了有限的数据丢失,而最长停机时间将由在辅助区域配置消费者和下游目的地所需的时间决定。
让我们更深入地了解高可用性每个核心阶段的实现细节,包括我们的用例的实施指南。
启动 亚马逊云科技 CloudFormation 资源
如果您想按照我们的代码示例进行操作,可以启动以下 CloudFormation 堆栈并按照说明进行操作,以模拟本文中提到的冷备用架构。
![]()
就Kinesis Data Streams高可用性设置演示而言,我们使用
us-west-2
作为主要区域,使用us-e
ast-
2作为故障转移区域。在您自己的账户中部署此解决方案时,您可以选择自己的主区域和故障转移区域。
-
在故障转移区域 us-east-2 中部署提供的 CloudFormation 模板。
确保在 CloudFormation 模板中将
us-east-2
指定 为 Fa
iloverRegion 参数
的值。
-
在主要区域 us-west-2 部署提供的 CloudFormation 模板。
确保在 CloudFormation 模板中将
us-east-2
指定 为 Fa
iloverRegion 参数
的值。
在步骤 1 和步骤 2 中,我们在主区域和故障转移区域部署了以下资源:
- kds-ha-Stream — 亚马逊云科技:: Kinesis:: Stream(主区域和故障转移区域)
- kds-ha-ProducerLambda — 亚马逊云科技:: Lambda :: Function(主要区域)
- kds-ha-consumerLambda — 亚马逊云科技:: Lambda :: Function(主区域和故障转移区域)
- kds-ha-ReplicationAgentLambda — 亚马逊云科技:: Lambda:: Funct ion(主区域)
- kds-ha-FailoverLambda — 亚马逊云科技:: Lambda :: Function(主区域)
- 股票价格 — 亚马逊云科技:: DynamoDB:: GlobalTable(主 区域和故障转移区域)
KDS-HA-Stream K inesis 数据流
已部署在这两个区域。主区域中 Kds-ha-Strea
m 流 kds-ha-
ReplicationAgentLambda 的增强型扇出使用者负责将消息复制到故障转移区域中的数据流。
kds-ha-consumerLambda 是一个 Lambda 函数,用于消耗 Kd
s-ha-Stream 流中的消息,并在预处理后将数据保存到 Dynam
o
DB 表中。
您可以在
主区域和故障转移区域中查看股票价格
DynamoDB 表的内容。请注意,
last_updated_region 属性将
。
us-west-2 显示为其值, 因为它是主要
区域
复制
在决定如何将数据从区域 A 的数据流复制到区域 B 的数据流时,有几种策略涉及消费者从主流读取数据,然后跨区域将数据发送到辅助数据流。这将充当复制器服务,负责在两个流之间复制数据,保持相对较低的复制延迟,并确保在复制过程中数据不会丢失。
由于复制共享吞吐量数据流可能会影响生产工作负载中的数据流,因此我们建议使用 Kinesis Data Streams 使用者的
这篇文章中实现的复制策略以异步复制为特色,这意味着复制过程不会阻塞主流中的任何标准数据流。同步复制是保证复制和避免数据丢失的一种更安全的方法;但是,如果没有服务端的实现,这是不可能的。
下图显示了冷备用架构的数据流时间表,数据一发布就会被复制。
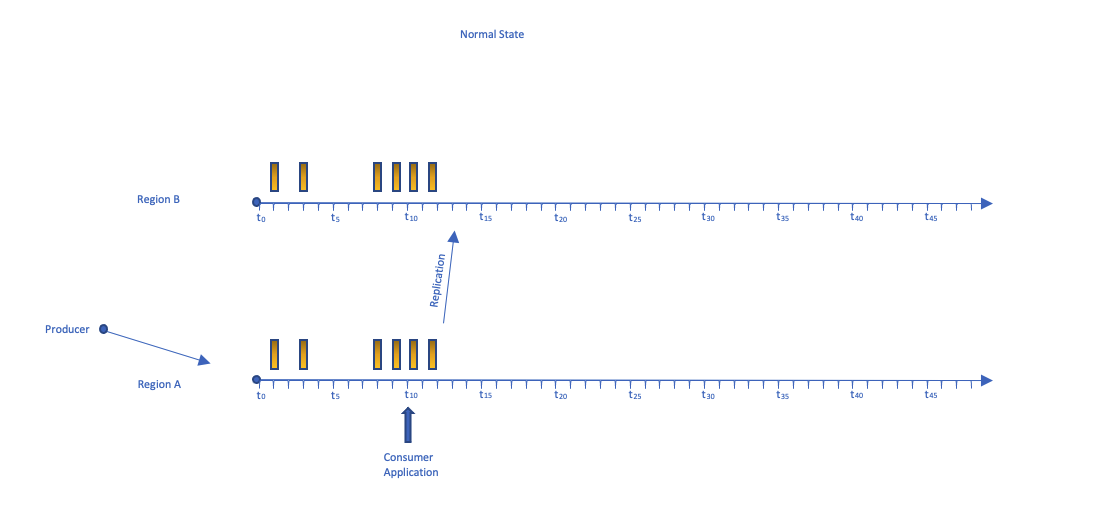
Lambda 复制
Lambda 可以将
这个 Lambda 函数是架构中实现高可用性的关键;它仅负责跨区域发送数据,还具有监控复制进度的最佳功能。监控 Lambda 复制的重要指标包括 I
teratorAge
,它表示批次中最后一条记录在完成处理时的使用年限。较高的 I
teratorAge
值表示 Lambda 函数落后了,因此无法跟上用于复制目的的数据摄取速度。当发生被动故障转移时,高 I
teratorAge
会 导致更高的 RPO 和更高的数据不可用的可能性。
我们在 CloudFormation 模板中使用以下示例 Lambda 函数来跨区域复制数据:
import json
import boto3
import random
import os
import base64
def lambda_handler(event, context):
client = boto3.client("kinesis", region_name=os.environ["FAILOVER_REGION"])
records = []
for record in event["Records"]:
records.append(
{
"PartitionKey": record["kinesis"]["partitionKey"],
"Data": base64.b64decode(record["kinesis"]["data"]).decode("utf-8"),
}
)
response = client.put_records(Records=records, StreamName="KDS-HA-Stream")
if response["FailedRecordCount"] > 0:
print("Failed replicating data: " + json.dumps(response))
raise Exception("Failed replicating data!")
CloudFormation 模板中的 Lambda 复制器配置为从主区域的数据流中读取。
以下代码包含 Lambda 必需
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Principal:
Service:
- lambda.amazonaws.com
Action:
- 'sts:AssumeRole'
Path: /
Policies:
- PolicyName: root
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- 'kinesis:DescribeStream'
- 'kinesis:DescribeStreamSummary'
- 'kinesis:GetRecords'
- 'kinesis:GetShardIterator'
- 'kinesis:ListShards'
- 'kinesis:ListStreams'
- 'kinesis:SubscribeToShard'
- 'kinesis:PutRecords'
Resource:
- 'arn:aws:kinesis:*:*:stream/KDS-HA-Stream'
- 'arn:aws:kinesis:*:*:stream/KDS-HA-Stream/consumer/KDS-HA-Stream-EFO-Consumer:*'
ManagedPolicyArns:
- 'arn:aws:iam::aws:policy/CloudWatchLogsFullAccess' 健康检查
确定何时将数据流视为不可用的通用策略涉及使用
生成数据流时,错误可能会显示为从数据流 返回的以下响应之一:
putRecord 或 Put
R
ecords 返回 AmazonKinesisException 500 或
tion 503 错误。
AmazonkinesisExce
p
从数据流中消费时,错误可能会显示为从数据流 返回的以下响应之一:Subscibet
oShard.Succ
inesisException 503 。
ess 或 getRecor
ds 返回 AmazonkinesisException 500 或 AmazonK
我们可以基于
例如,在 5 分钟的时间段内,平均错误率为 1% 或更高,可能表明数据流存在问题,我们可能希望进行故障转移。在 CloudFormation 模板中,此错误率阈值和时间窗口是可配置的,但默认情况下,我们会在过去 5 分钟内检查错误率是否为 1%,以触发客户机故障转移。
putRecord.Success 和 getRecord.Success
来计算我们的有效错误率。
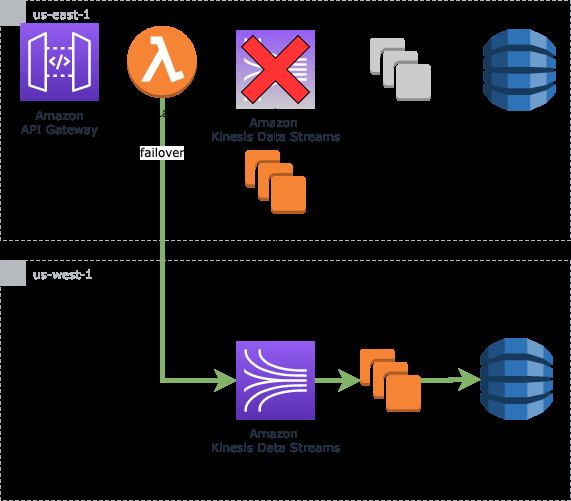
客户机故障转移
当数据流被认为无法访问时,我们现在必须采取行动,确保我们的系统在交互的两端均可供客户访问和访问。这意味着对于遵循冷备用高可用性架构的生产者来说,我们会更改生产者写入的目标流。如果给定用例不要求数据生产者和使用者的高可用性和故障转移,则更适合使用不同的架构。
在故障转移之前,生产者可能一直在向区域 A 中的流传输数据,但我们现在自动将目标更新为区域 B 中的流。对于不同的客户,更新生产器的方法会有所不同,但是对于我们来说,我们将生产者的活动目标存储在 亚马逊云科技 CloudFormation 的 Lambda 环境变量中,并在运行状况检查失败的情况下动态更新 Lambda 函数。
对于我们的用例,我们使用最大使用者延迟时间 (I
teratorAge
) 加上一些缓冲区来影响故障转移使用者的起始位置。这使我们能够确保次要区域的消费者不会跳过原始地区尚未处理的记录,但可能会出现一些数据重叠。请注意,可能会在下游系统中引入一些重复项,为了避免与重复相关的问题,必须实现一个等效的接收器或某种处理重复项的方法。
如果数据成功写入数据流但无法从数据流中使用,则数据将无法复制,因此在第二个区域不可用。数据将持久地存储在主数据流中,直到它恢复在线状态并可以从中读取。请注意,如果数据流不可用的时间长于您在数据流上的总数据保留期,则这些数据将丢失。Kinesis 数据流的数据保留期可以追溯性地延长至 1 年。
对于冷备用架构中的使用者,在检测到故障时,消费者将被禁用或关闭,相同的消费者实例将在辅助区域中启动,以从辅助数据流中使用。在消费者方面,我们假设消费者应用程序在我们提供的解决方案中是无状态的。如果您的应用程序需要状态,您可以通过
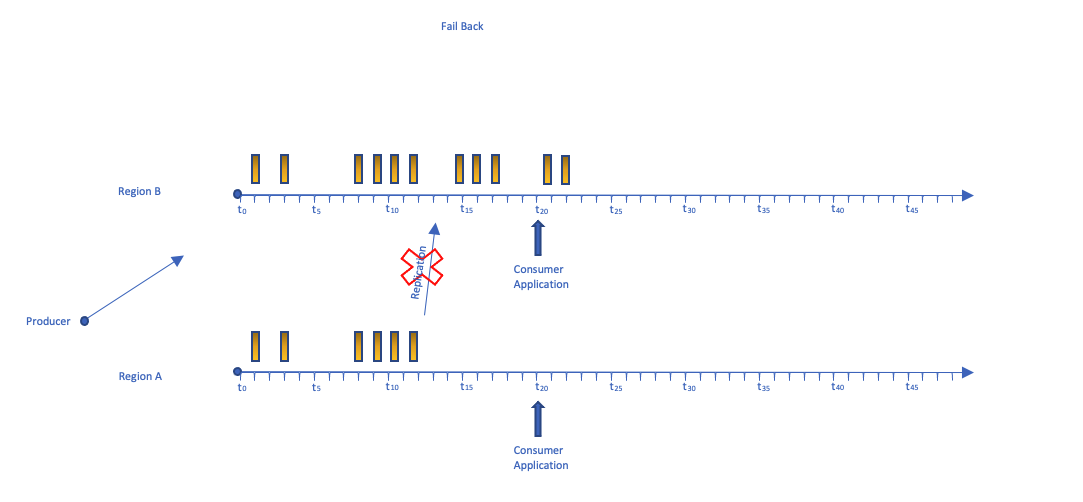
在接下来的时间轴中,我们可以看到,在某个时候,A区的直播被视为无法访问。
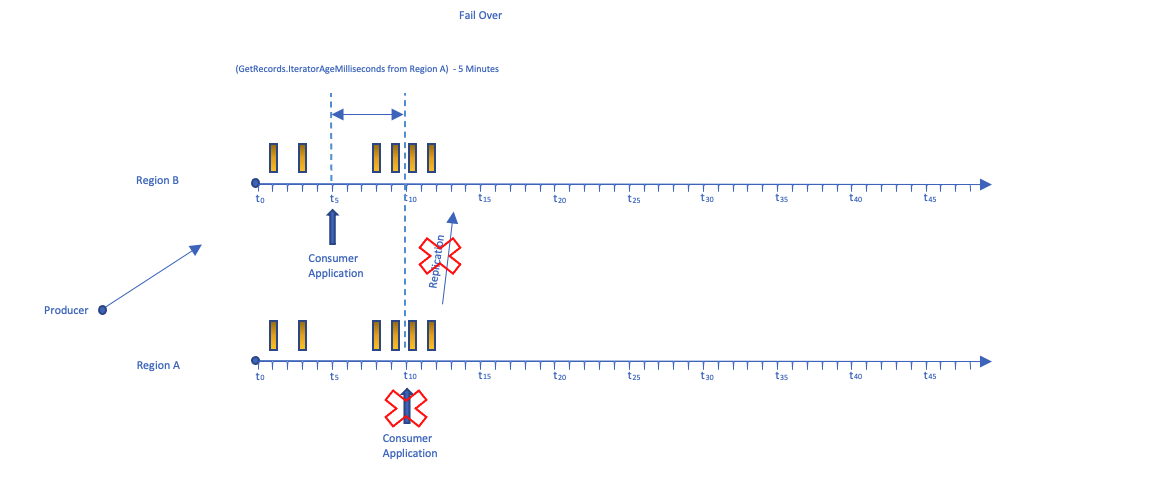
区域 A 中的使用者应用程序正在读取时间 t10 的数据,当它故障转移到辅助区域 (B) 时,它从 t5 开始读取(当前 I
ter
atorageMilliseConds 之前 5 分钟)。这可确保消费者应用程序不会跳过数据。请记住,下游目的地的记录可能存在一些重叠之处。
在提供的冷备用 亚马逊云科技 CloudFormation 示例中,我们可以使用
us-east-2
:
aws lambda invoke --function-name KDS-HA-FailoverLambda --cli-binary-format raw-in-base64-out --payload '{}' response.json --region us-west-2
几分钟后,您可以检查
主区域和故障转移区域中股票价格
DynamoDB 表的内容。
请注意,
last_updated_region 属性将 us-east
。
-2 显示 为其值,因为它已故障转移到 us-east-2
区域
故障恢复
在中断或服务不可用被视为已解决之后,下一个合乎逻辑的步骤是将您的客户重新定向到其原始运营区域。尽管自动执行此过程可能很诱人,但在非工作时间采用手动故障恢复方法更合理,因为生产中断最少。
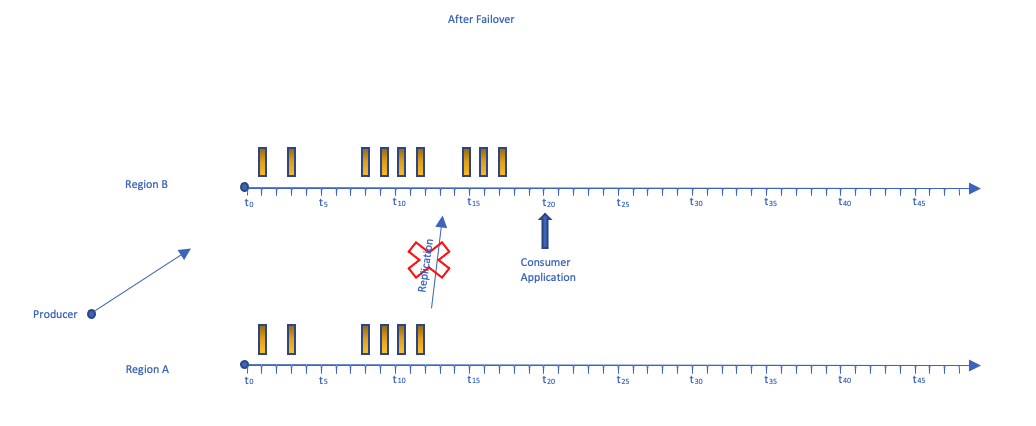
在下图中,我们可以直观地看到消费者应用程序故障回原始区域的时间表。
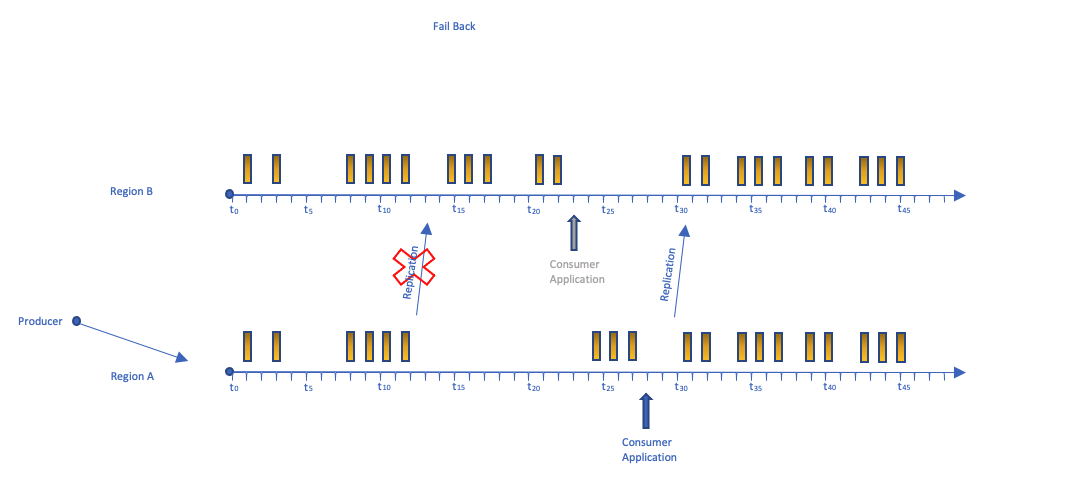
生产者切换回原始区域,我们等待区域 B 的消费者达到 0 延迟。此时,区域 B 中的消费者应用程序已禁用,向区域 B 的复制已恢复。我们现在已经恢复了处理消息的正常状态,如本文的复制部分所示。
在我们的 亚马逊云科技 CloudFormation 设置中,我们通过以下步骤执行故障恢复:
- 重新启用事件源映射,然后从最新位置开始使用来自主区域的消息:
aws lambda create-event-source-mapping --function-name KDS-HA-ConsumerLambda --batch-size 100 --event-source-arn arn:aws:kinesis:us-west-2:{{accountId}}:stream/KDS-HA-Stream --starting-position LATEST --region us-west-2- 将生产者切换回主区域:
aws lambda update-function-configuration --function-name KDS-HA-ProducerLambda --environment "Variables={INPUT_STREAM=KDS-HA-Stream,PRODUCING_TO_REGION=us-west-2}" --region us-west-2-
在故障转移区域(
us-east-2)中,等待您的数据流的getRecords 最大迭代器寿命(以毫秒为单位)CloudWatch 指标将 0 报告为一个值。我们正在等待消费者 Lambda 函数赶上所有生成的消息。 - 停止使用来自故障转移区域的消息。
-
运行以下 亚马逊云科技 CLI 命令并从响应中获取 UUID,我们使用它来删除现有的事件源映射。
一定要为 Lambda 函数 kds-ha-consumerLambda 选择事件源映射。
aws lambda list-event-source-mappings --region us-east-2
aws lambda delete-event-source-mapping --uuid {{UUID}} --region us-east-2
- 在主区域重新启动复制代理。
- 运行以下 亚马逊云科技 CLI 命令,然后从响应中捕获 consumeRN:
aws kinesis list-stream-consumers --stream-arn arn:aws:kinesis:us-west-2:{{accountId}}:stream/KDS-HA-Stream --region us-west-2
aws lambda create-event-source-mapping --function-name KDS-HA-ReplicationAgentLambda --batch-size 100 --event-source-arn {{ConsumerARN}} --starting-position LATEST --region us-west-2
完成后,您可以观察到相同的数据流指标——每秒传入和传出的记录数、使用者延迟指标和错误数(如本文的运行状况检查部分所述),以确保每个组件都恢复了对原始区域中的数据的处理。我们还可以记下数据登录 DynamoDB,它会显示从哪个区域更新数据,以确定我们的故障恢复过程是否成功。
我们建议任何无法承受长时间数据丢失或停机时间的流式传输工作负载在极少数情况下实现某种形式的跨区域高可用性,以防出现服务不可用情况。这些建议可以帮助您确定哪种模式适合您的用例。
清理
为避免将来产生费用,请完成以下步骤:
-
从主区域 us-west-2 中删除 CloudFormation 堆栈。 -
从故障转移区域 us-east-2 中删除 CloudFormation 堆栈。 -
使用 aws lambda list-event-source-mappings--region的 UUID。us-west-2 命令列出主区域 us-west-2 中的所有事件源映射,并记下 与 kds-ha-consumerLambda 和 kds-ha-ReplicationAgentLambda 函数关联的事件源映射 -
使用 aws lambda delete-event-source-mapping--uuid {{UUID}}--region us-west-2 命令和 uuID 删除与 kds-ha-consumerLambda 和 kds-ha-ReplicationAgentLambda 函数关联的事件源映射。
结论
跨多个区域构建高度可用的 Kinesis 数据流是多方面的,需要仔细考虑 RPO、RTO 和运营成本的各个方面。本文中讨论的代码和架构是您可以为工作负载选择的许多不同架构模式之一,因此请务必根据您的特定要求的标准选择合适的架构。
要了解有关 Kinesis 数据流的更多信息,我们有
作者简介
 J eremy Ber
在遥测数据领域工作了 7 年,担任软件工程师、机器学习工程师,最近还是一名数据工程师。过去,Jeremy 支持并构建了每天以太字节为单位的数据流并实时处理复杂的机器学习算法的系统。在 亚马逊云科技,他是一名高级流媒体专家解决方案架构师,为亚马逊 MSK 和亚马逊 Kinesis 提供支持。
J eremy Ber
在遥测数据领域工作了 7 年,担任软件工程师、机器学习工程师,最近还是一名数据工程师。过去,Jeremy 支持并构建了每天以太字节为单位的数据流并实时处理复杂的机器学习算法的系统。在 亚马逊云科技,他是一名高级流媒体专家解决方案架构师,为亚马逊 MSK 和亚马逊 Kinesis 提供支持。
 Pratik Patel
是一位高级技术客户经理和流媒体分析专家。他与 亚马逊云科技 客户合作,提供持续的支持和技术指导,以帮助使用最佳实践规划和构建解决方案,并积极帮助客户的 亚马逊云科技 环境保持运行健康。
Pratik Patel
是一位高级技术客户经理和流媒体分析专家。他与 亚马逊云科技 客户合作,提供持续的支持和技术指导,以帮助使用最佳实践规划和构建解决方案,并积极帮助客户的 亚马逊云科技 环境保持运行健康。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。