我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
构建端到端 mLOps 管道,用于边缘的视觉质量检测 — 第 3 部分
这是我们系列的第 3 部分,我们在其中设计和实现 mLOps 管道,用于边缘的视觉质量检测。在这篇文章中,我们重点介绍如何自动化端到端 mLOPs 管道的边缘部署部分。我们将向您展示如何使用
解决方案概述
在本系列 的
本系列使用的示例用例是视觉质量检测解决方案,可以检测金属标签上的缺陷,您可以将其作为制造过程的一部分进行部署。下图显示了我们在本系列开头定义的 mLOPS 流水线的高级架构。如果你还没有读过,我们建议你看看
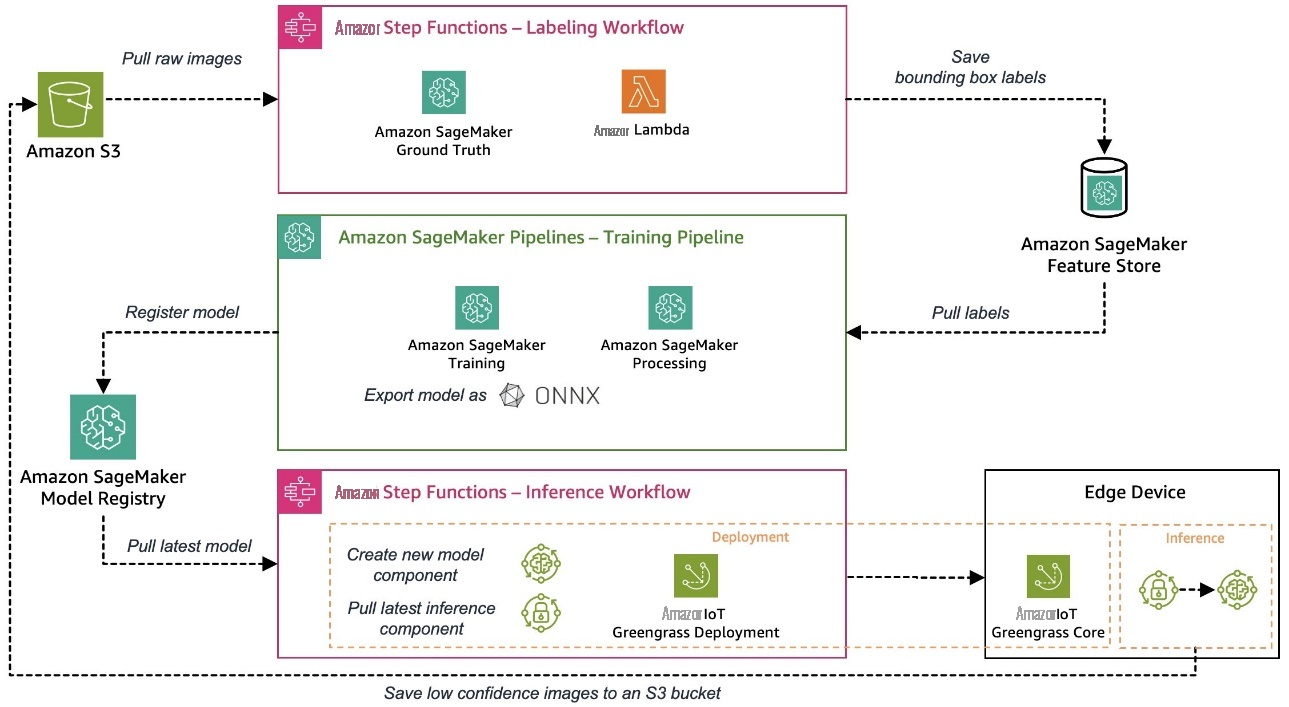
自动部署 ML 模型的边缘部署
机器学习模型经过训练和评估后,需要将其部署到生产系统,通过对传入数据进行预测来创造业务价值。在边缘环境中,这个过程很快就会变得复杂,因为模型需要在设备上部署和运行,而这些设备通常远离训练模型的云环境。以下是边缘机器学习所独有的一些挑战:
- 由于边缘设备的资源限制,机器学习模型通常需要优化
- 边缘设备无法像云端服务器那样重新部署甚至更换,因此您需要强大的模型部署和设备管理流程
- 设备与云之间的通信需要高效和安全,因为它经常穿越不可信的低带宽网络
让我们看看除了以 ONNX 格式导出模型外,如何使用 亚马逊云科技 服务应对这些挑战,例如,这使我们能够应用量化等优化来减小约束设备的模型大小。ONNX 还为最常见的边缘硬件平台提供优化的运行时间。
分解边缘部署流程,我们需要两个组件:
- 模型交付的部署机制,包括模型本身以及一些用于管理和与模型交互的业务逻辑
- 一个工作流程引擎,可以协调整个流程,使其变得强大且可重复
在此示例中,我们使用不同的 亚马逊云科技 服务来构建自动边缘部署机制,该机制集成了我们讨论的所有必需组件。
首先,我们模拟边缘设备。为了便于您轻松完成端到端工作流程,我们使用
在生产环境中,通常使用工业相机传送图像,机器学习模型应该对这些图像进行预测。在我们的设置中,我们通过将图像预设上传到边缘设备上的特定目录来模拟此图像输入。然后,我们使用这些图像作为模型的推理输入。
我们将整个部署和推理过程分为三个连续步骤,将经过云训练的机器学习模型部署到边缘环境并使用它进行预测:
- 准备 — 打包经过训练的边缘部署模型。
- 部署 -将模型和推理组件从云端转移到边缘设备。
- 推断 -加载模型并运行推理代码进行图像预测。
以下架构图显示了这个三步流程的详细信息以及我们如何使用 亚马逊云科技 服务实施该流程。
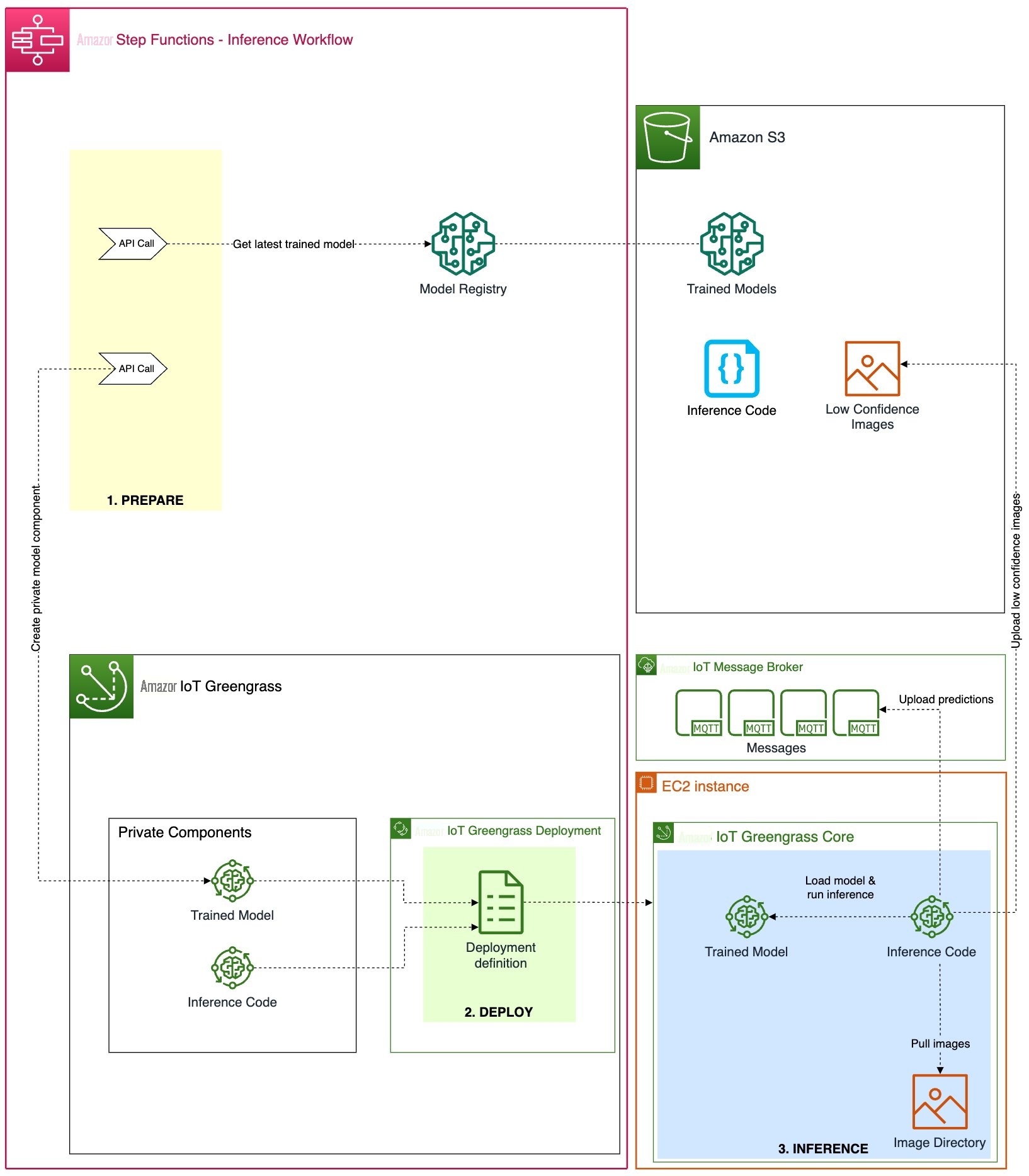
在以下部分中,我们将讨论每个步骤的详细信息,并展示如何将此流程嵌入到机器学习模型和相应推理代码的自动化且可重复的编排和 CI/CD 工作流程中。
准备
与强大 CPU 和 GPU 可以轻松运行机器学习模型的云环境相比,边缘设备的计算和内存通常有限。不同的模型优化技术允许您为特定的软件或硬件平台定制模型,以在不损失准确性的情况下提高预测速度。
部署
将模型从云端部署到边缘设备时,安全可靠的部署机制是关键。由于 亚马逊云科技 IoT Greengrass 已经集成了强大而安全的边缘部署系统,因此我们将其用于部署目的。在详细了解部署过程之前,让我们简要回顾一下 亚马逊云科技 IoT Greengrass 部署的工作原理。亚马逊云科技 IoT Greengrass 部署
我们创建了以下两个 Greengrass 组件,然后通过部署过程将其部署到边缘设备:
- 打包模型(私有组件) — 此组件包含 ONNX 格式的训练模型和 ML 模型。
-
推理代码(私有组件)
— 除了机器学习模型本身,我们还需要实现一些应用程序逻辑来处理诸如数据准备、与模型进行推理通信以及推理结果的后处理等任务。在我们的示例中,我们开发了一个基于 Python 的私有组件来处理以下任务:
- 安装所需的运行时组件,例如 Ultralytics YOLOv8 Python 包。
- 我们不是从摄像机直播中拍摄图像,而是通过从特定目录加载准备好的图像并根据模型输入要求准备图像数据来进行模拟。
- 使用准备好的图像数据对加载的模型进行推理调用。
- 检查预测并将推断结果上传回云端。
如果你想更深入地了解我们构建的推理代码,请参阅
推断
上述组件的部署完成后,边缘设备上的模型推断过程会自动启动。自定义推理组件使用本地目录中的图像定期运行 ML 模型。从模型返回的每张图像的推理结果是具有以下内容的张量:
- 置信度分数 -模型对检测结果的信心程度
- 物体坐标 — 模型在图像中检测到的划痕对象坐标(x、y、宽度、高度)
在我们的例子中,推理组件负责将推理结果发送到 亚马逊云科技 IoT 上的特定 MQTT 主题,在那里可以读取该结果以进行进一步处理。可以通过 亚马逊云科技 IoT 控制台上的 MQTT 测试客户端查看这些消息以进行调试。在生产设置中,您可以决定自动通知另一个负责从生产线上移除有缺陷的金属标签的系统。
管弦乐编曲
如前几节所示,准备机器学习模型、相应的推理代码以及所需的运行时或代理并将其部署到边缘设备需要多个步骤。Step Functions 是一项完全托管的服务,允许您协调这些专用步骤并以状态机的形式设计工作流程。该服务的无服务器性质和 亚马逊云科技 服务 API 集成等原生步骤函数功能允许您快速设置此工作流程。重试或日志记录等内置功能是构建强大编排的重要组成部分。有关状态机定义本身的更多详细信息,请在账户中部署此示例后,请参阅
基础设施部署和集成到 CI/CD
用于集成和构建所有必需的基础架构组件的 CI/CD 管道遵循本系列第

学习
有多种方法可以为自动化、强大和安全的机器学习模型边缘部署系统构建架构,这些方法通常在很大程度上取决于用例和其他要求。但是,以下是我们想与您分享的一些经验教训:
-
提前评估额外
亚马逊云科技 IoT Greengrass 计算 资源要求是否符合您的情况,尤其是在边缘设备 受限的情况下。 - 在边缘设备上运行之前,建立一种部署机制,该机制集成了已部署工件的验证步骤,以确保在传输过程中不会发生任何篡改。
- 最好将 亚马逊云科技 IoT Greengrass 上的部署组件尽可能保持模块化和独立性,以便能够独立部署。例如,如果你的推理代码模块相对较小,但机器学习模型的大小较大,那么只要推理代码发生了变化,你并不总是希望同时部署这两个模块。当您的带宽有限或边缘设备连接成本高时,这一点尤其重要。
结论
我们关于构建用于边缘视觉质量检测的端到端 mLOPs 管道的三部分系列到此结束。我们研究了在边缘部署机器学习模型所带来的其他挑战,例如模型打包或复杂的部署协调。我们以全自动化的方式实施了管道,因此我们可以以强大、安全、可重复和可追溯的方式将模型投入生产。您可以随意使用本系列中开发的架构和实现作为下一个支持 ML 的项目的起点。如果您对如何为您的环境架构和构建这样的系统有任何疑问,
作者简介



*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。