我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用亚马逊 SageMaker 构建垃圾邮件检测器
垃圾邮件,也称为垃圾邮件,一次发送给大量用户,通常包含诈骗、网络钓鱼内容或隐秘消息。垃圾邮件有时由人类手动发送,但大多数情况下是使用机器人发送的。垃圾邮件的示例包括虚假广告、连锁电子邮件和冒充尝试。存在一封伪装得特别好的垃圾邮件进入你的收件箱的风险,如果点击,可能会很危险。请务必采取额外的预防措施来保护您的设备和敏感信息。
随着技术的进步,由于垃圾邮件的性质不断变化,检测垃圾邮件成为一项艰巨的任务。垃圾邮件与其他类型的安全威胁有很大不同。起初它可能看起来像是一条烦人的消息,而不是 威胁 ,但它会立即产生影响。此外,垃圾邮件发送者经常采用新技术。提供电子邮件服务的组织希望尽可能减少垃圾邮件,以避免对最终客户造成任何损害。
在这篇文章中,我们将展示使用
解决方案概述
这篇文章演示了如何使用 SageMaker 设置垃圾邮件检测器和筛选垃圾邮件。让我们看看垃圾邮件检测器通常是如何工作的,如下图所示。
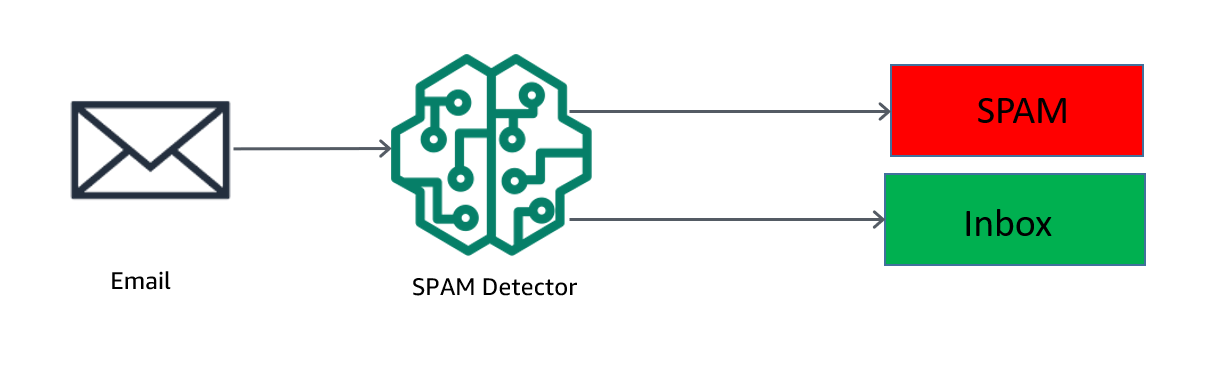
电子邮件通过垃圾邮件检测器发送。如果垃圾邮件检测器将电子邮件检测为垃圾邮件,则会将其发送到垃圾邮件文件夹。否则,它会发送到客户的收件箱。
我们将引导您完成以下步骤来设置我们的垃圾邮件检测器模型:
- 从 GitHub 存储库下载示例数据集。
-
将数据加载到
亚马逊 Sage Maker Studio 笔记本电脑中。 - 为模型准备数据。
- 训练、部署和测试模型。
先决条件
在深入研究此用例之前,请完成以下先决条件:
-
设置一个
亚马逊云科技 账户 。 -
设置
SageMaker 域名 。 -
创建
亚马逊 Simple Storage Servic e (Amazon S3) 存储桶。有关说明,请参阅创建您的第一个 S3 存储桶 。
下载数据集
从
BlazingText 算法需要一个带有空格分隔标记的预处理文本文件。文件中的每一行都应包含一个句子。如果您需要对多个文本文件进行训练,请将它们连接成一个文件,然后将文件上传到相应的频道中。
在 SageMaker Studio 中加载数据
要执行数据加载,请完成以下步骤:
-
从 GitHub 下载 spam_detector.ipynb文件并将该文件上传到 SageMaker Stu dio。 -
在你的 Studio 笔记本电脑中,打开
spam_detector.ipynb 笔记本电脑。 - 如果系统提示你选择内核,请选择 Python 3(数据科学 3.0)内核, 然后选择 “选择” 。如果没有,请验证是否已自动选择正确的内核。
- 导入所需的 Python 库并设置角色和 S3 存储桶。指定您上传 email_dataset.csv 的 S3 存储桶和前缀。

- 在笔记本中运行数据加载步骤。
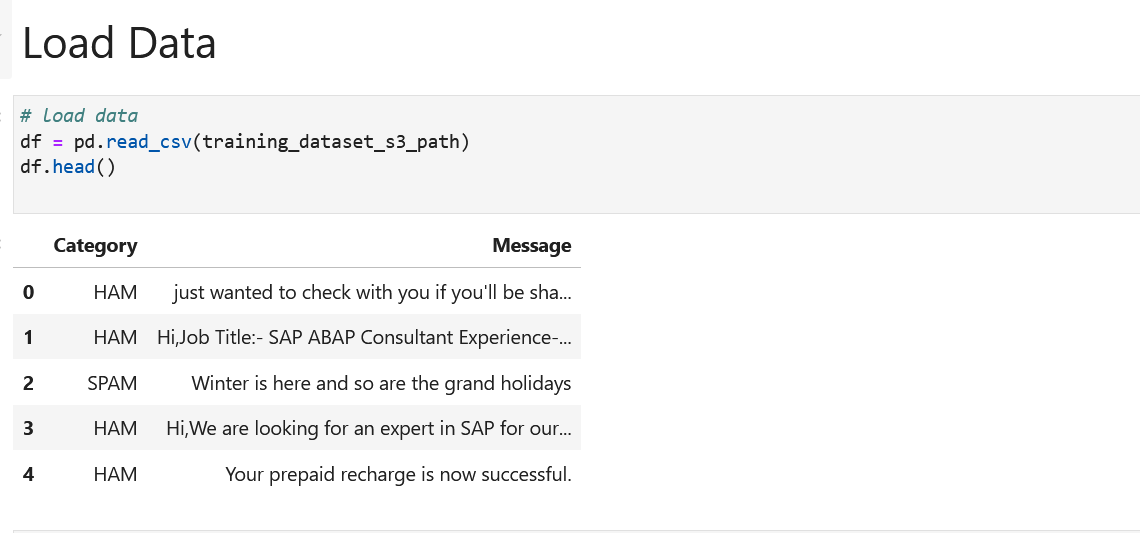
- 根据类别标签检查数据集是否平衡。

我们可以看到我们的数据集是平衡的。
准备数据
BlazingText 算法期望数据采用以下格式:
下面是一个例子:
检查
现在,您在笔记本中运行数据准备步骤。
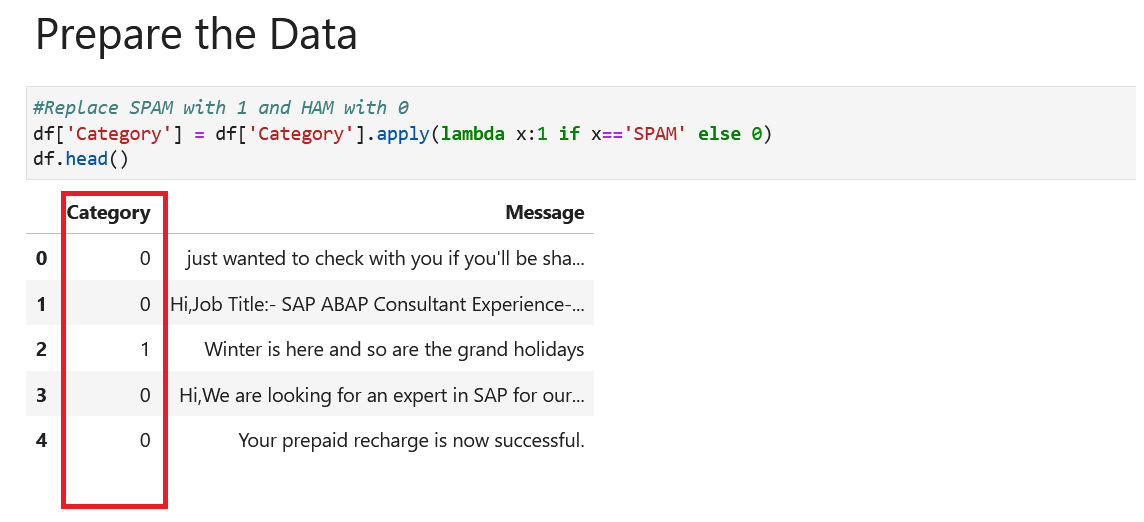
- 首先,你需要将类别列转换为整数。以下单元格将 SPAM 值替换为 1,将 HAM 值替换为 0。
-
下一个单元格将前缀
__label__添加到每个类别值中,并对消息列进行标记化。
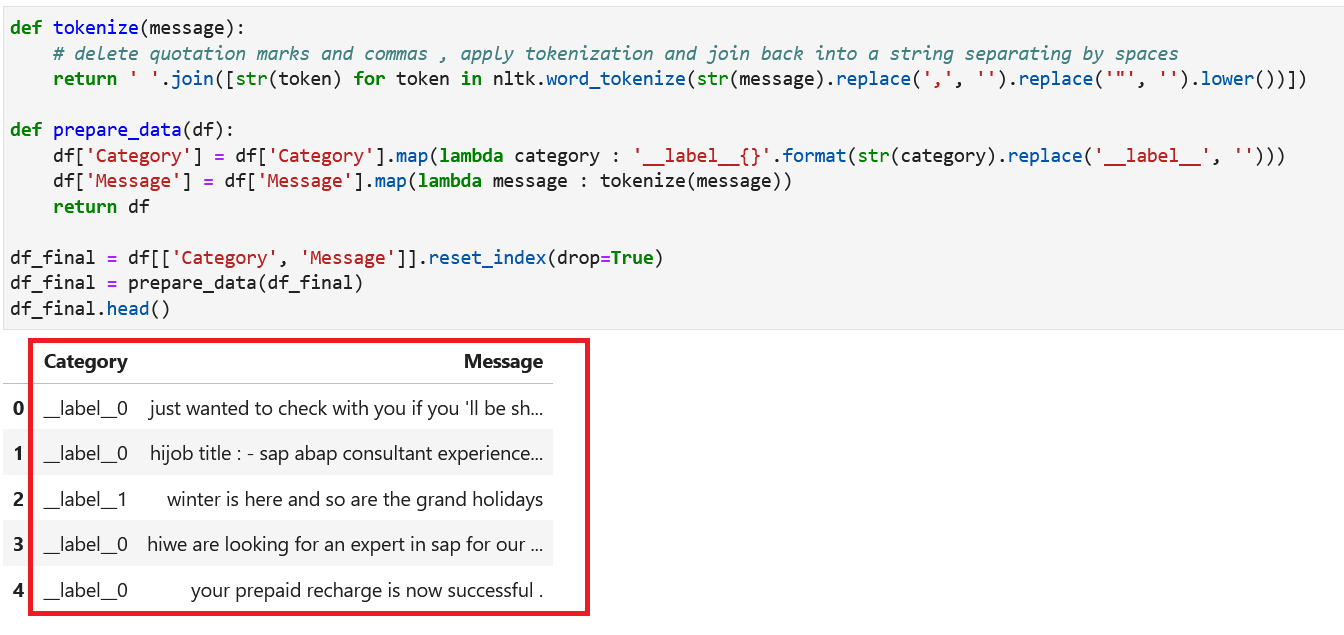
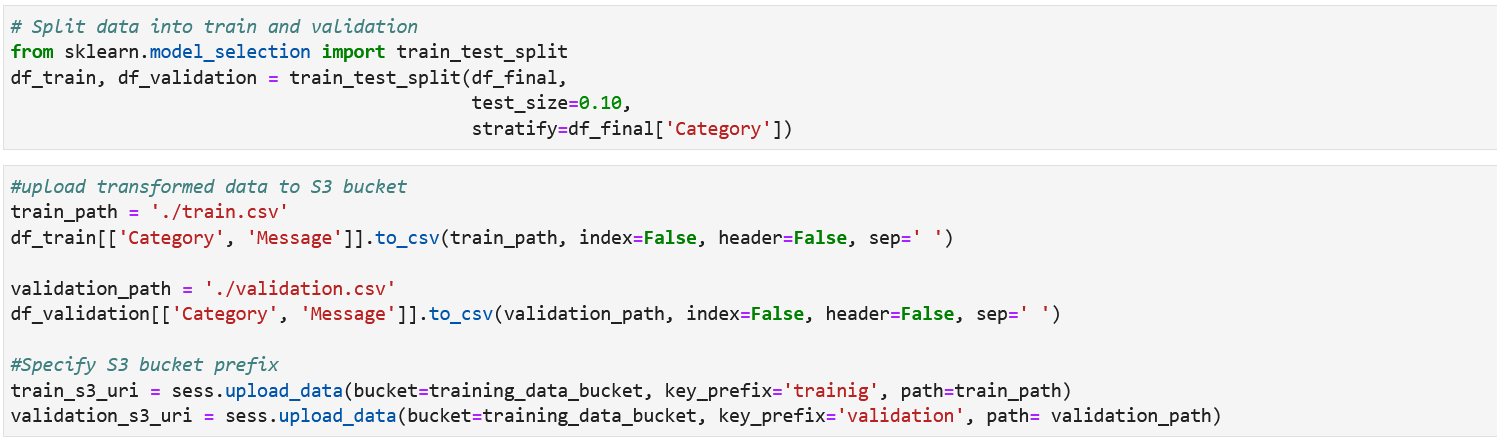
- 下一步是将数据集拆分为训练和验证数据集,并将文件上传到 S3 存储桶。
训练模型
要训练模型,请在笔记本中完成以下步骤:
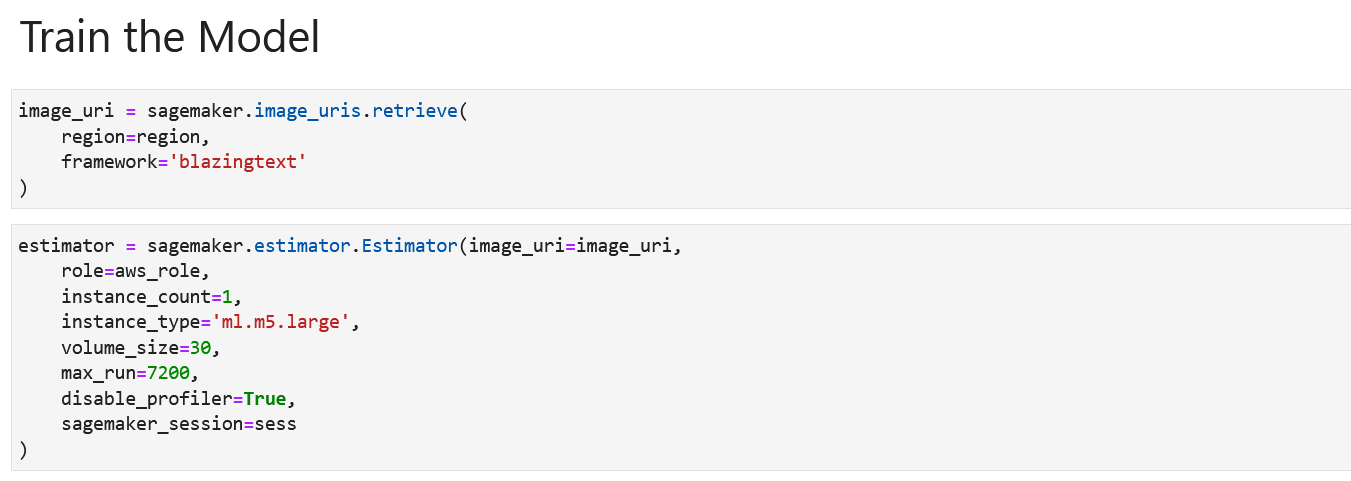
- 设置 BlazingText 估算器并创建一个传递容器图像的估算器实例。
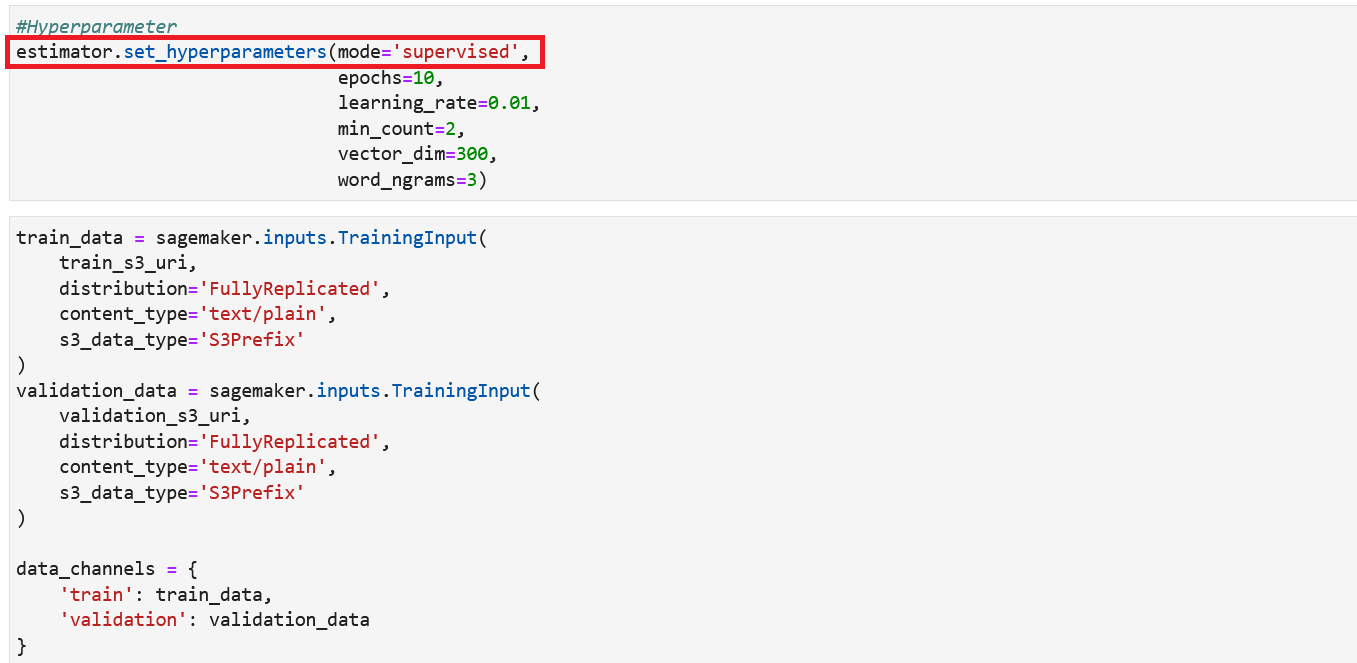
- 将学习模式超参数设置为监督。
BlazingText 既有无监督学习模式,也有监督学习模式。我们的用例是文本分类,即监督学习。
- 创建训练和验证数据通道。
- 开始训练模型。
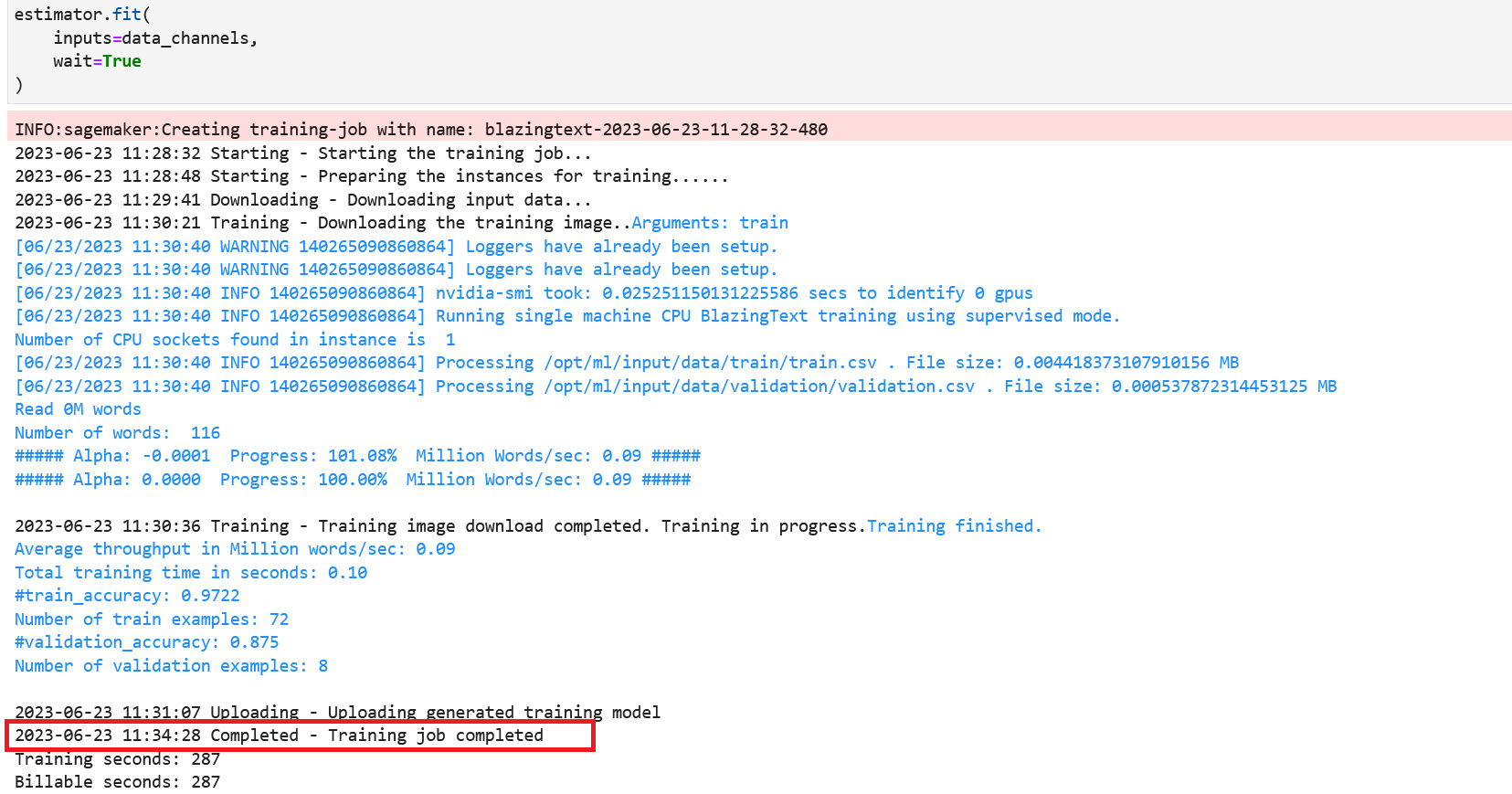
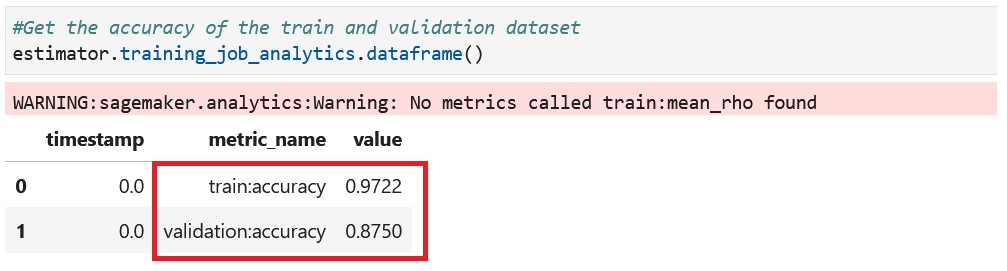
- 获取训练和验证数据集的准确性。
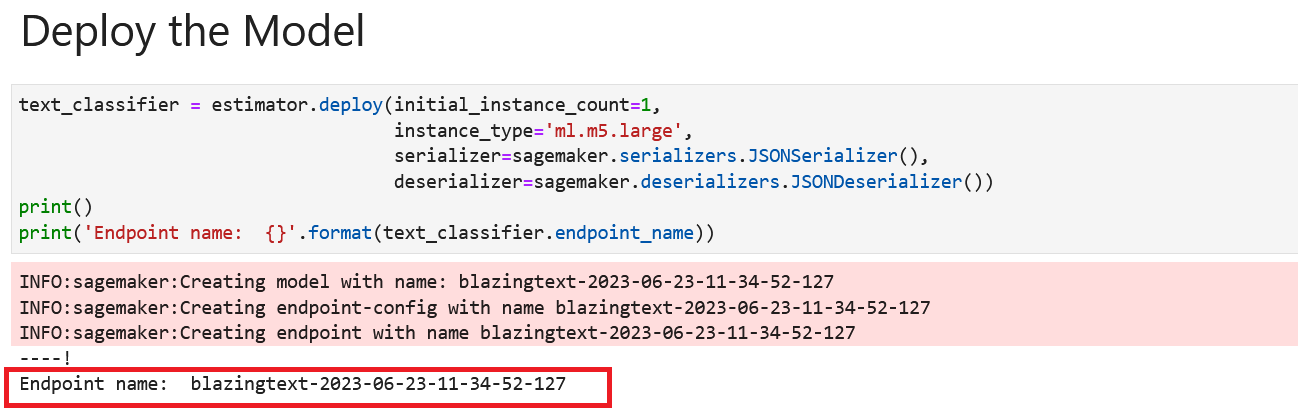
部署模型
在此步骤中,我们将训练后的模型部署为端点。选择您的首选实例
测试模型
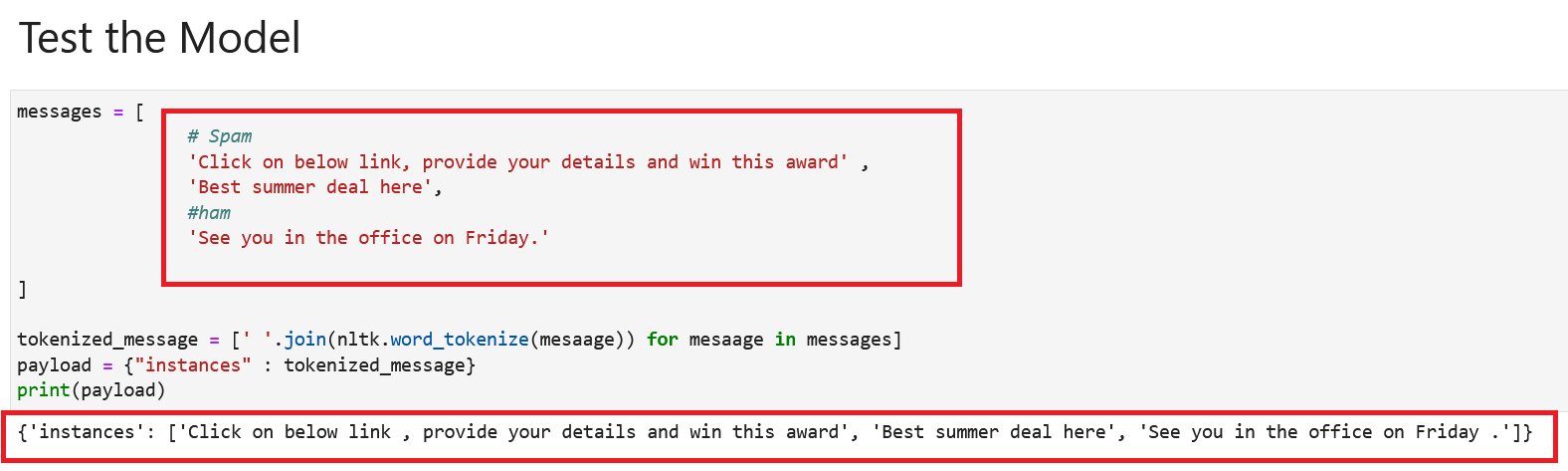
让我们举一个我们想要预测的三封电子邮件的示例:
- 点击下面的链接,提供您的详细信息并赢取此奖项
- 这里最优惠的夏季优惠
- 星期五在办公室见。
对电子邮件进行标记化并指定调用 REST API 时要使用的负载。
现在我们可以预测每封电子邮件的电子邮件分类。调用文本分类器的预测方法,将分词化的句子实例(有效负载)传递到数据参数中。
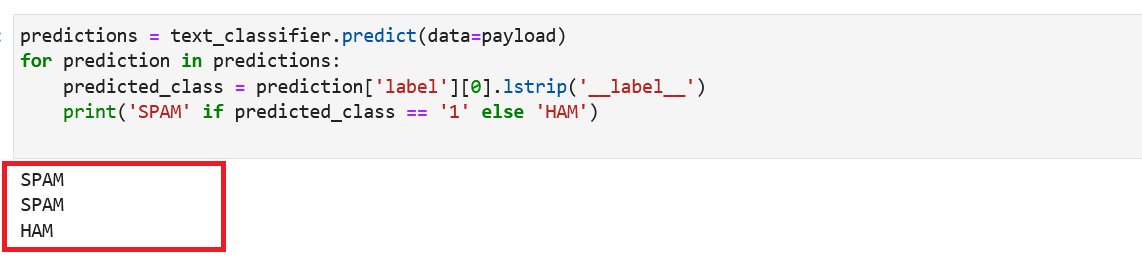
清理
最后,您可以删除端点以避免任何意外费用。

此外,
结论
在这篇文章中,我们向您介绍了使用
作者简介

Dhiraj Thakur 是亚马逊网络 服务的解决方案架构师。他与 亚马逊云科技 客户和合作伙伴合作,提供有关企业云采用、迁移和战略的指导。他对技术充满热情,喜欢在分析和人工智能/机器学习领域进行构建和试验。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。