我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 亚马逊云科技 Glue 和 亚马逊云科技 Lake Formation 构建多区域和高弹性的现代数据架构
这篇文章解释了如何创建一种设计,自动备份不同区域的
此解决方案仅复制数据目录中的元数据,而不复制实际的基础数据。
解决方案概述
这篇文章介绍如何在同一个账户中将 Lake Formation 权限和 亚马逊云科技 Glue 数据目录从一个区域创建备份到另一个区域。该解决方案不会创建或修改
- 迁移 Lake Formation 数据权限。
- 迁移 亚马逊云科技 Glue 数据库和表。
- 迁移亚马逊 S3 数据。
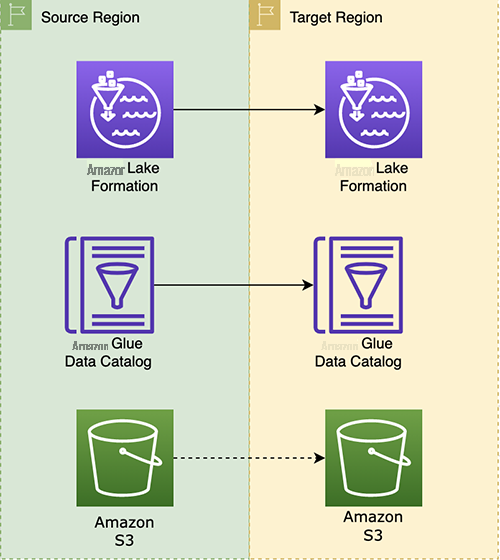
在以下部分中,我们将更详细地介绍每个迁移步骤。
湖泊形成权限
在 Lake Formation 中,有两种类型的权限:元数据访问和数据访问。
元数据访问权限允许用户创建、读取、更新和删除数据目录中的元数据数据库和表。
数据访问权限允许用户在 Amazon S3 中的特定位置读取和写入数据。数据访问权限使用数据位置权限进行管理,该权限允许用户创建和更改指向特定 Amazon S3 位置的元数据数据库和表。
将数据从一个区域迁移到另一个区域时,仅复制元数据访问权限。这意味着,如果将数据从源区域的存储桶移动到目标区域中的另一个存储桶,则需要在目标区域重新应用数据访问权限。
亚马逊云科技 Glue 数据目录
亚马逊云科技 Glue 数据目录是有关存储在数据湖中的数据的元数据的中央存储库。它包含对在 亚马逊云科技 Glue ETL(提取、转换和加载)任务中用作源和目标的数据的引用,并存储有关数据的位置、架构和运行时指标的信息。数据目录以元数据表和数据库的形式组织这些信息。数据目录中的表是表示数据湖中数据的元数据定义,数据库用于组织这些元数据表。
Lake Formation 权限只能应用于目标区域的数据目录中已经存在的对象。因此,为了应用这些权限,基础数据目录数据库和表必须已经存在于目标区域中。为了满足此要求,该实用程序将 亚马逊云科技 Glue 数据库和表从源区域迁移到目标区域。
亚马逊 S3 数据
构成 亚马逊云科技 Glue 表基础的数据可以存储在任何区域的 S3 存储桶中,因此无需复制数据本身。但是,如果数据已经复制到目标区域,则此实用程序可以选择更新表的位置,使其指向目标区域中复制的数据。如果数据位置发生变化,则该实用程序会更新 S3 存储桶名称并保持前缀层次结构的其余部分不变。
此实用程序不包括将数据从源区域迁移到目标区域。
该实用程序有两种复制湖泊形成和数据目录元数据的模式:按需和实时。按需模式是一种批量复制,它在特定时间点拍摄元数据的快照并使用它来同步元数据。实时模式几乎实时地复制了对湖层权限或数据目录所做的更改。
建议使用此实用程序的按需模式来创建现有的 Lake Formation 权限和数据目录,因为它会复制元数据的快照。同步湖泊形成和数据目录后,您可以使用实时模式来复制任何正在进行的更改。这将在目标区域中创建源区域的镜像,并在源区域进行更改时使其保持最新状态。这两种模式可以相互独立使用,并且运算是幂等的。
按需和实时模式的代码可在
按需模式
按需模式用于在特定时间点复制 Lake Formation 权限和数据目录。该代码使用
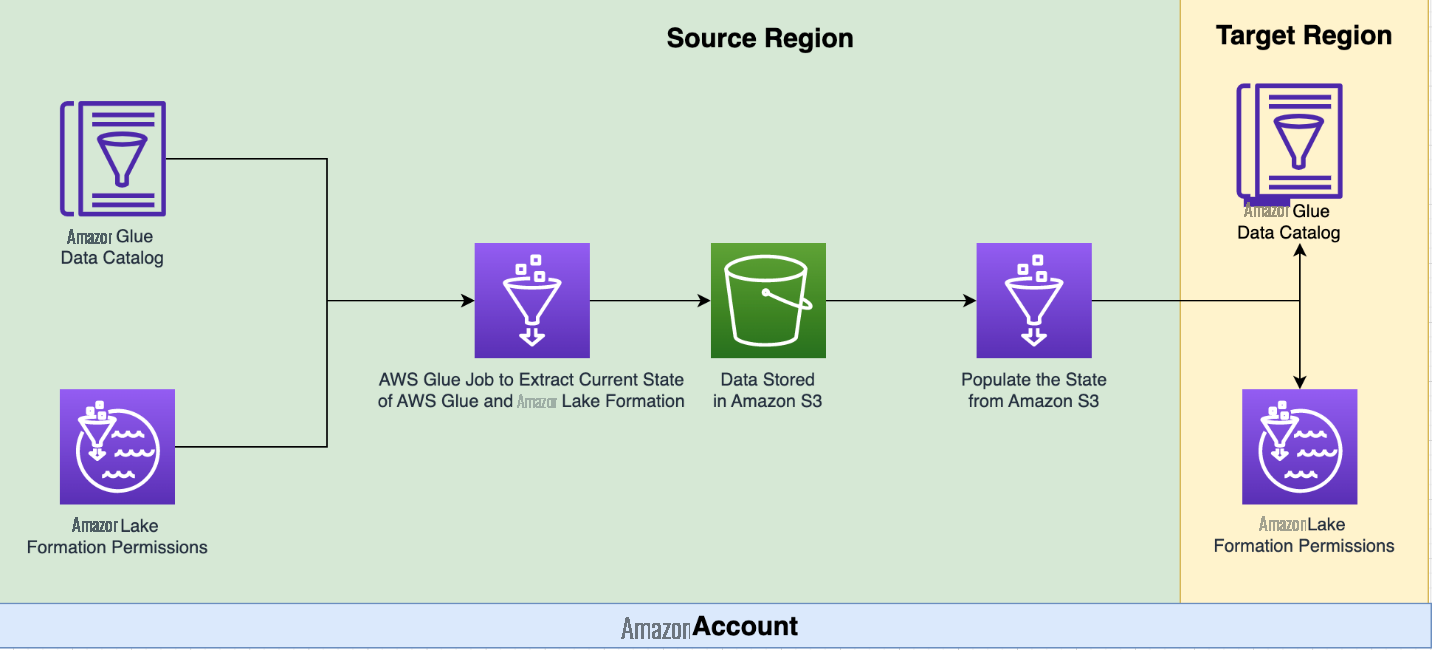
亚马逊云科技 CDK 部署了一个 亚马逊云科技 Glue 任务来执行复制。该任务从存储在 S3 存储桶中的文件中检索配置信息。此文件包括源和目标区域、要复制的数据库的可选列表以及将数据移动到不同 S3 存储桶的选项等详细信息。有关这些选项和部署说明的更多信息,请参阅 G
亚马逊云科技 Glue 任务从源区域检索 Lake Formation 权限和数据目录对象元数据,并将其存储在 S3 存储桶中的 JSON 文件中。然后,同一作业使用此文件在目标区域创建 Lake Formation 权限和数据目录数据库和表。
该工具可以通过运行 亚马逊云科技 Glue 任务按需运行。它将 Lake Formation 权限和数据目录对象元数据从源区域复制到目标区域。如果您在对目标区域进行更改后再次运行该工具,则所做的更改将被来自源区域的最新湖泊形成权限和数据目录所取代。
在将数据目录从源区域复制到目标区域时,此实用程序可以检测对数据目录元数据、数据库、表和列所做的任何更改。如果在源区域检测到更改,则会将最新版本的 亚马逊云科技 Glue 对象应用到目标区域。该实用程序报告其运行期间修改的对象的数量。
Lake Formation 权限从源区域复制到目标区域,因此所有新权限都会复制到目标区域。如果权限已从源区域删除,则不会将其从目标区域删除。
实时模式
实时模式定期复制 Lake Formation 权限和数据目录。默认间隔为 1 分钟,但可以在部署期间进行修改。该代码使用 亚马逊云科技 CDK 进行部署。下图显示了此模式的解决方案架构。
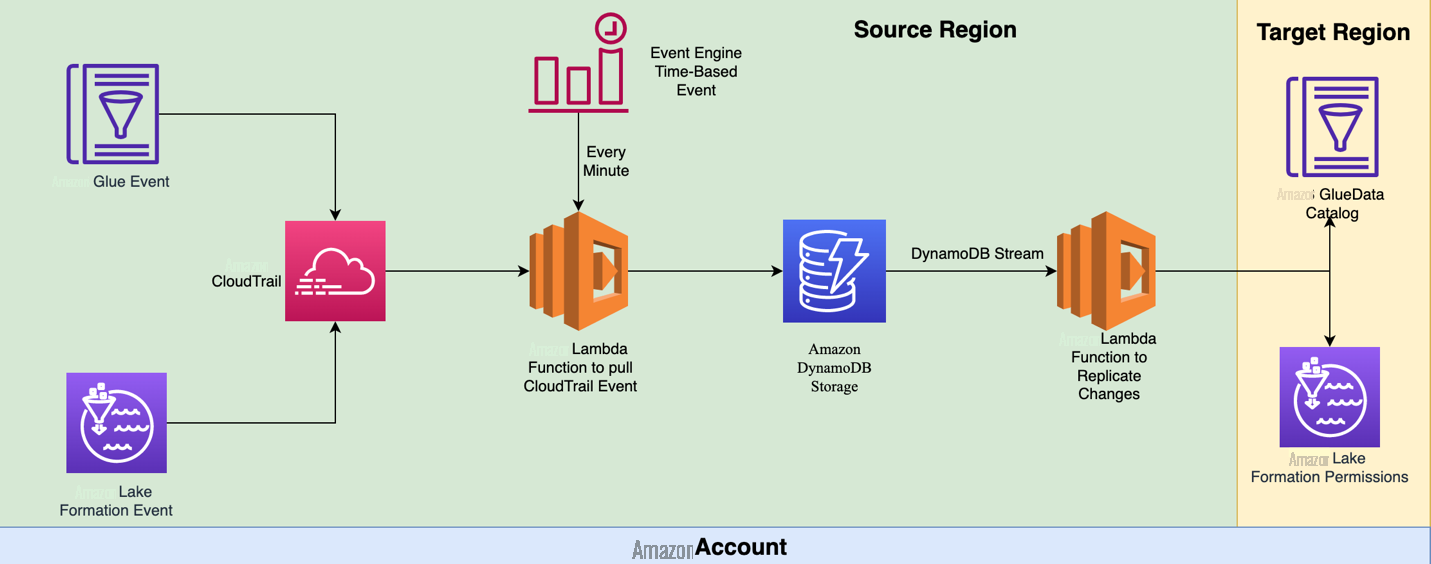
亚马逊云科技 CDK 部署了两个 A
EventBridge 规则以固定间隔触发 Lambda 作业。此作业检索配置信息并查询过去一小时内发生的与数据目录和湖泊形成相关的 CloudTrail 事件(持续时间可配置)。然后,所有相关事件都存储在 DynamoDB 表中。
将事件信息插入到 DynamoDB 表中后,将触发另一个 Lambda 作业。此作业检索配置信息并查询 DynamoDB 表。然后,它将所有更改应用到目标区域。如果在对目标区域进行更改后再次运行该工具,则所做的更改将被来自源区域的最新湖泊形成权限和数据目录所取代。与按需模式不同,此实用程序还会从目标区域移除所有从源区域移除的 Lake Formation 权限。
局限性
此实用程序旨在仅在单个账户内复制权限。按需模式会复制快照并且不删除现有权限,因此它不执行删除操作。该 API 目前不支持复制对行和列权限的更改。
结论
在这篇文章中,我们展示了如何使用此实用程序将 亚马逊云科技 Glue 数据目录和湖泊形成权限从一个区域迁移到另一个区域。如果对数据目录或 Lake Formation 权限进行了任何更改,它还可以使源区域和目标区域保持同步。如果您希望实现全球多元化数据工作负载的最大分离性和完全独立性,那么跨区域(多区域)实施它是一个不错的选择。还要考虑权衡利弊。与其他灾难恢复策略相比,实施和运营此策略,尤其是使用多区域策略,可能更加复杂和昂贵。
要开始使用,请查看
-
亚马逊云科技 Glue -
亚马逊云科技 Lake Formation
作者简介
 Vivek Shrivastava 是 A
WS 专业服务数据湖的首席数据架构师。他是大数据爱好者,拥有 13 个 亚马逊云科技 认证。他热衷于帮助客户在云端构建可扩展的高性能数据分析解决方案。在业余时间,他喜欢阅读并寻找家庭自动化的领域
Vivek Shrivastava 是 A
WS 专业服务数据湖的首席数据架构师。他是大数据爱好者,拥有 13 个 亚马逊云科技 认证。他热衷于帮助客户在云端构建可扩展的高性能数据分析解决方案。在业余时间,他喜欢阅读并寻找家庭自动化的领域


*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。