我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 Starburst 和 Amazon S3 表构建托管的 Apache Iceberg 数据湖
长期以来,管理跨不同数据源的大规模数据分析一直是企业面临的挑战。数据团队经常为复杂的数据湖配置、性能瓶颈以及在实现广泛访问分析功能的同时保持一致的数据治理的需求而苦苦挣扎。
今天,Starburst 宣布通过扩展其 Apache Iceberg 连接器集成来支持 Amazon S3 表,为这些挑战提供强有力的解决方案。Starburst 的 Iceberg 连接器现在可与 S3 表格无缝集成。这可以帮助客户为他们选择的数据湖架构获得更多选择。
在这篇文章中,我们将探讨这种集成如何解决关键的企业数据挑战,它对你现有的 Iceberg 实施意味着什么,并提供了在 Starburst Enterprise 中使用这些新功能的分步指南。
关于 Starburst 和 Iceberg
Apache Iceberg 是 Starburst Icehouse 架构的基础。在生产中,Starburst 集群使用 Iceberg 连接器来访问 Iceberg 中的数据。这包括在 Amazon S3 上存储 Iceberg 元数据和数据文件,以及与各种元存储集成以包括 Iceberg REST 目录。
关于 Starburst 与 S3 表的集成
Starburst 使用 Amazon SageMaker Lakehouse 提供的 Iceberg REST 端点与 S3 表集成。这种集成允许您查询和修改这些 Iceberg 表,并使用连接器将其内容与任何其他数据源联合。此外,S3 Tables 还提供开箱即用的表维护操作,例如压缩、快照到期和删除未引用的文件。
现在,让我们来看一个简单的设置,让你开始使用 Starburst Enterprise 开发 S3 表。
Starburst Enterprise 上的 S3 表格入门
在这篇文章中,我们使用 Amazon Glue Iceberg REST 终端节点将 Starburst 企业集群连接到表存储桶。连接集群后,我们将使用 Starburst Enterprise 查询编辑器创建架构,该架构映射到 S3 表中的命名空间。然后,我们使用此编辑器创建表,加载示例 TPC 基准 H (TPC-H) 区域数据并进行查询。
先决条件
要关注这篇文章,你需要进行以下设置:
- Starburst Enterprise 集群。
- 启用亚马逊云科技分析服务集成的 S3 表存储桶。
第 1 步:在亚马逊云科技上设置表存储桶和相关权限
记下您之前从 S3 控制台创建的存储桶的表存储桶 ARN。ARN 看起来像:
arn:aws:s3tables:{REGION}:{ACCOUNT_ID}:bucket/{S3_BUCKET_NAME}
现在,您为 Starburst 创建一个 IAM 角色来访问 S3 表,并在 Amazon Lake Formation 中向该角色授予访问这些表所需的权限。有关此过程的详细分步演练,请参阅文档。
通过这一步,我们现在可以将表存储桶连接到 Starburst 了。
第 2 步:在 Starburst Enterprise 中创建新的 Iceberg REST 目录连接
接下来,打开 Starburst Enterprise 查询编辑器并准备创建新目录。
该目录将使用 Iceberg REST 目录来访问亚马逊云科技表。为此,我们将目录类型设置为 REST iceberg.catalog.type=rest。此设置将目录配置为使用 Iceberg REST 目录,该目录为元数据管理提供了标准协议。这允许新的查询引擎通过单一实现来支持任何目录。
Iceberg 连接器从 Amazon SageMaker Lakehouse Iceberg REST 端点检索元数据位置,然后访问表存储以读取或写入文件。
以下示例使用带有访问密钥和私有密钥的静态亚马逊云科技证书。此外,Starburst 正在努力增加对凭证出售和基于 IAM 角色的身份验证的支持,以提高安全性。
该 ${asm:path} 语法使用了 Amazon Secrets Manager。你可以在 Starburst Enterprise 文档中找到所有支持的密钥管理器的列表。
- 在 Starburst Enterprise 中,打开查询编辑器。
- 插入以下代码块。
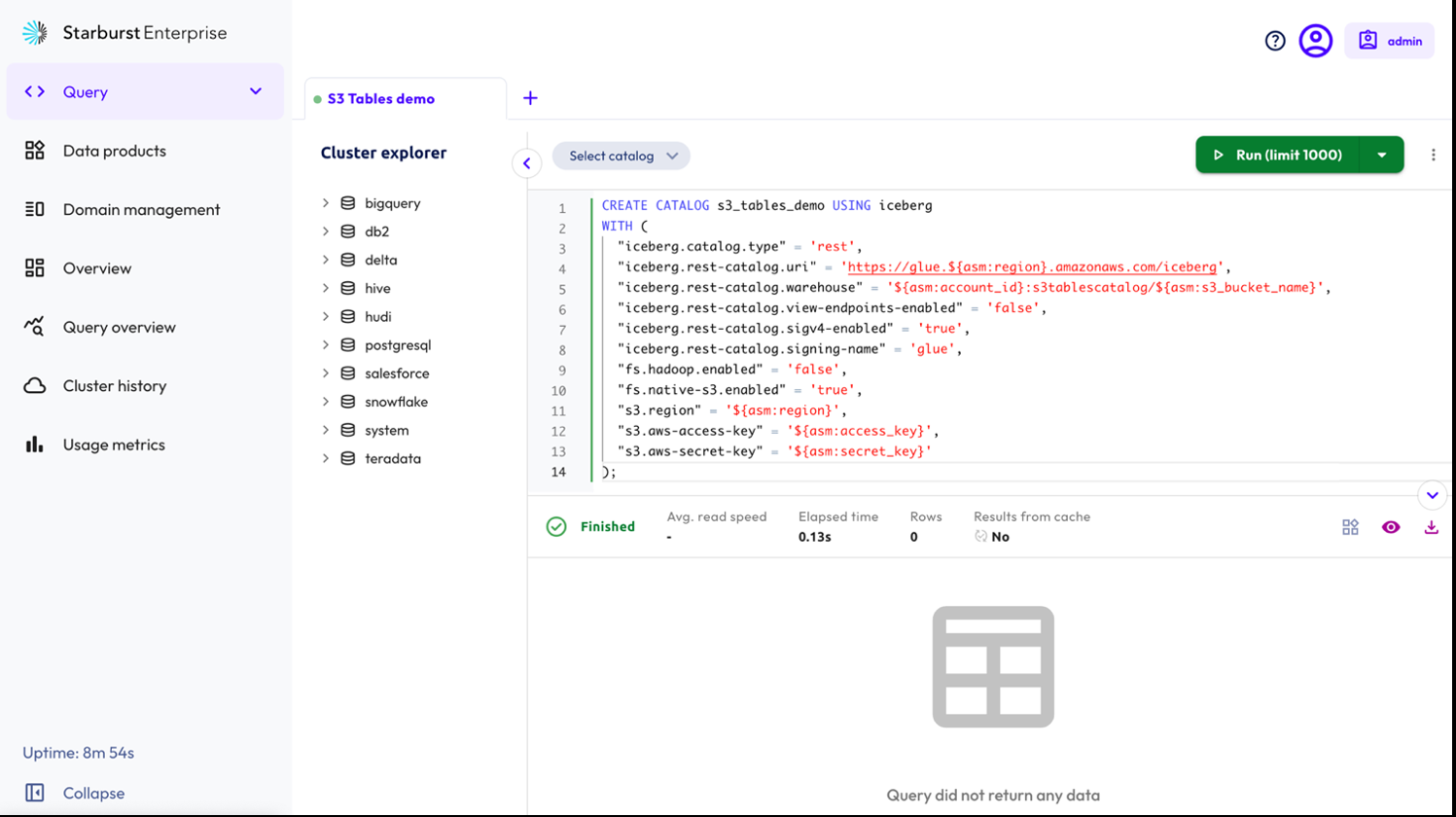
CREATE CATALOG s3_tables_demo USING iceberg
WITH (
"iceberg.catalog.type" = 'rest',
"iceberg.rest-catalog.uri" = 'https://glue.${asm:region}.amazonaws.com/iceberg',
"iceberg.rest-catalog.warehouse" = '${asm:account_id}:s3tablescatalog/${asm:s3_bucket_name}',
"iceberg.rest-catalog.view-endpoints-enabled" = 'false',
"iceberg.rest-catalog.sigv4-enabled" = 'true',
"iceberg.rest-catalog.signing-name" = 'glue',
"fs.hadoop.enabled" = 'false',
"fs.native-s3.enabled" = 'true',
"s3.region" = '${asm:region}',
"s3.aws-access-key" = '${asm:access_key}',
"s3.aws-secret-key" = '${asm:secret_key}'
);
第 3 步:定义架构
在 Starburst 中,架构等同于表存储桶中的命名空间。在这篇文章中,我们从查询编辑器中创建了一个名为"示例"的架构。
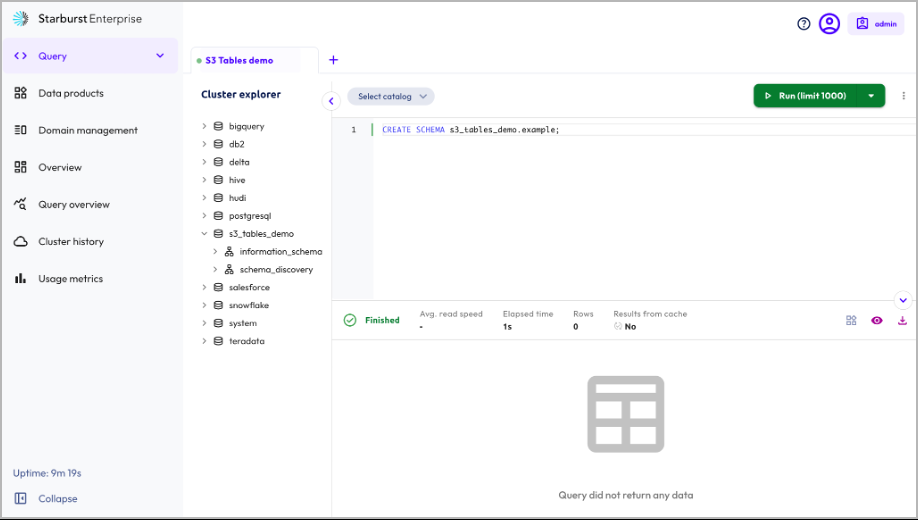
第 4 步:使用 TPC-H 区域数据创建新表
现在,我们使用示例 TPC-H 区域数据创建一个表。
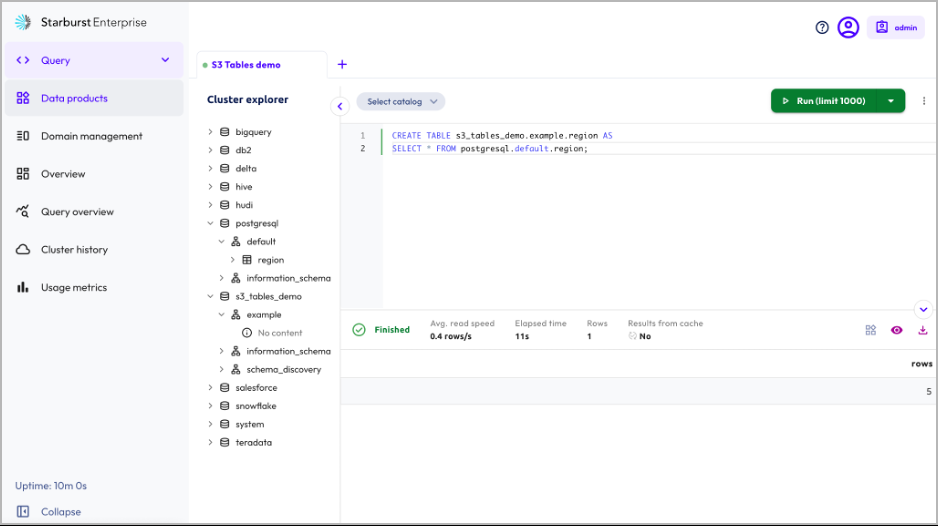
第 5 步:从 S3 表中读取数据
加载数据后,您可以在编辑器中查询数据。
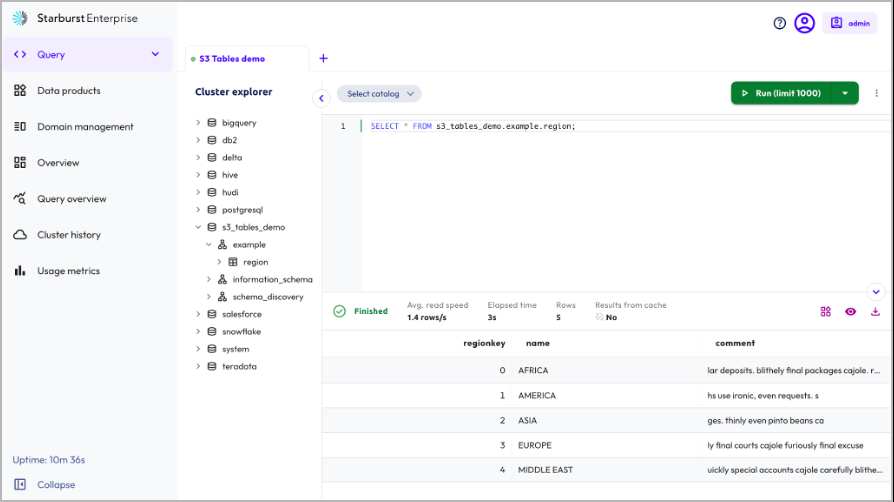
注意:Starburst 与 S3 表的集成支持 Iceberg 连接器功能,例如时空旅行、架构演变等。但是,在发布本文时,此集成不支持 S3 Tables 提供的开箱即用维护操作。您可以直接在表存储桶上配置这些操作。
结论
在这篇文章中,我们展示了在 Starburst 和 Amazon S3 上构建数据湖的情况。该集成建立在 Starburst 长期以来对 Apache Iceberg 的关注以及 Amazon S3 Tables 自动表格维护任务的好处之上。Starburst 是亚马逊云科技数据、分析和金融服务能力合作伙伴,可通过 Amazon Marketplace 获得。

海老原悠也
Ebihara Yuya 是 Starburst 连接器团队的一名高级软件工程师。他是开源 Trino 的维护者,负责开发 Iceberg 连接器。在业余时间,他喜欢和他的猫咪 Towa 一起玩。

阿里特拉·古普塔
阿里特拉·古普塔是亚马逊云科技 Amazon S3 团队的高级技术产品经理。他帮助客户建立和扩展数据湖。居住在西雅图的他喜欢在业余时间下象棋和打羽毛球。

安东尼·普拉萨德·特瓦拉杰
安东尼·普拉萨德·特瓦拉杰是亚马逊云科技数据和分析领域的高级合作伙伴解决方案架构师。他拥有超过 10 年的大数据工程师经验,曾为各个业务部门构建复杂的 ETL 和 ELT 管道。他帮助合作伙伴使用亚马逊云科技服务构建联合解决方案。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。