我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
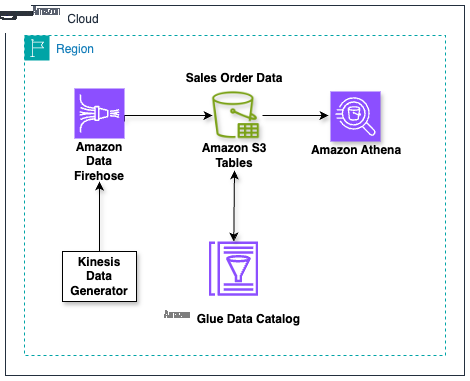
使用 Amazon S3 Tables 和 Amazon Data Firehose 构建用于流式传输数据的数据湖
企业越来越多地采用实时数据处理来保持领先于用户的期望和市场变化。零售、金融、制造业和智慧城市等行业正在将流数据用于从优化供应链到检测欺诈和改善城市规划等方方面面。在生成数据时使用数据的能力已成为企业的关键竞争优势,推动了对用于存储和管理流数据的可扩展数据湖架构的需求。最近,用户越来越多地使用 Apache Iceberg 在数据湖中组织流数据,以使用其类似数据库的功能,例如架构演变、时空旅行和 ACID 交易。
Amazon S3 Tables 提供专门构建的存储,以简单、高性能且经济实惠的方式存储和查询 Apache Iceberg 表。S3 Tables 持续优化存储,以最大限度地提高查询性能并最大限度地降低成本,对于希望在不进一步设置基础架构的情况下简化数据湖操作的企业来说,这是一个绝佳的选择。通过将表存储桶与 Amazon Glue Data Catalog 和 Amazon Lake Formation 集成在一起,企业可以通过 Amazon Data Firehose 和 Amazon Athena 等亚马逊云科技分析服务来流式传输和查询 S3 表存储桶中的表。S3 Tables 与亚马逊云科技表存储桶分析服务的集成处于预览阶段。Firehose 是一项完全托管的无服务器服务,可将来自各种来源的数据传输到数据湖、数据仓库和分析数据存储。借助对 Iceberg 的内置支持,Firehose 可以将来自多个来源的实时数据传输到 Amazon S3 中的 Iceberg 表,无需预置更多资源或在非使用时间为空闲数据付费。它通过在流记录到达时对其进行处理来简化数据摄取,并消除了以原始格式写入流数据并将其转换为 Apache Iceberg 格式所涉及的多步流程。
在这篇文章中,我们将介绍如何使用 Firehose 和 S3 Tables 构建一个完全托管的数据湖,以存储和分析实时流数据。我们使用自定义流源将数据传输到 S3 表存储桶中的表中,但对于本 Amazon Data Firehose 用户指南中列出的受 Firehose 支持的其他来源,也可以遵循相同的工作流程。
解决方案概述
在本解决方案中,我们演示了一个示例,在该示例中,用户将来自来源的流式数据直接提取到 S3 表存储桶中的表中。我们首先创建 S3 表存储桶,然后通过 Amazon Glue 数据目录和 Amazon Lake Formation 将其与亚马逊云科技分析服务集成。然后,我们使用亚马逊 Kinesis 数据生成器模拟实时数据流并将其发布到 Firehose,并使用 Athena 在表存储桶中查看流式传输到表中的数据。
先决条件
要继续操作,你需要进行以下设置:
- 可以访问以下亚马逊云科技服务的亚马逊云科技账户:
- Amazon Glue
- Amazon Identity and Access Management (IAM)
- Amazon S3
- Amazon Data Firehose
- Amazon Athena
- 确保安装和配置了最新版本的亚马逊云科技命令行接口 (亚马逊云科技 CLI)。
- 熟悉亚马逊云科技管理控制台。
操作步骤
以下步骤将引导您完成此解决方案。
- 创建 S3 表存储桶并与亚马逊云科技分析服务集成
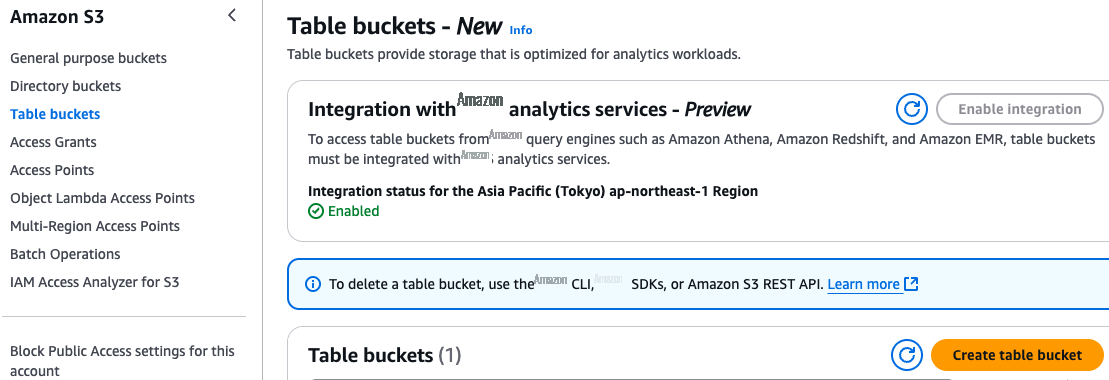
在控制台中导航到 Amazon S3。如果尚未启用与亚马逊云科技 Analytics 服务的集成,请选择表格存储桶,然后选择启用集成,如下图所示。这种集成允许用户在 Amazon Glue Data Catalog 和 Amazon Lake Formation 中发现在该亚马逊云科技区域和该账户中创建的所有表,并通过 Firehose、Athena、Amazon Redshift 和亚马逊 EMR 等亚马逊云科技服务访问这些表。集成完成后,所有现有和未来的表存储桶将自动添加为子目录,命名空间组织为数据库,这些命名空间中的表将作为表填充 Amazon Glue 数据目录中。要了解有关此集成的更多信息,请参阅将 Amazon S3 与分析服务结合使用。
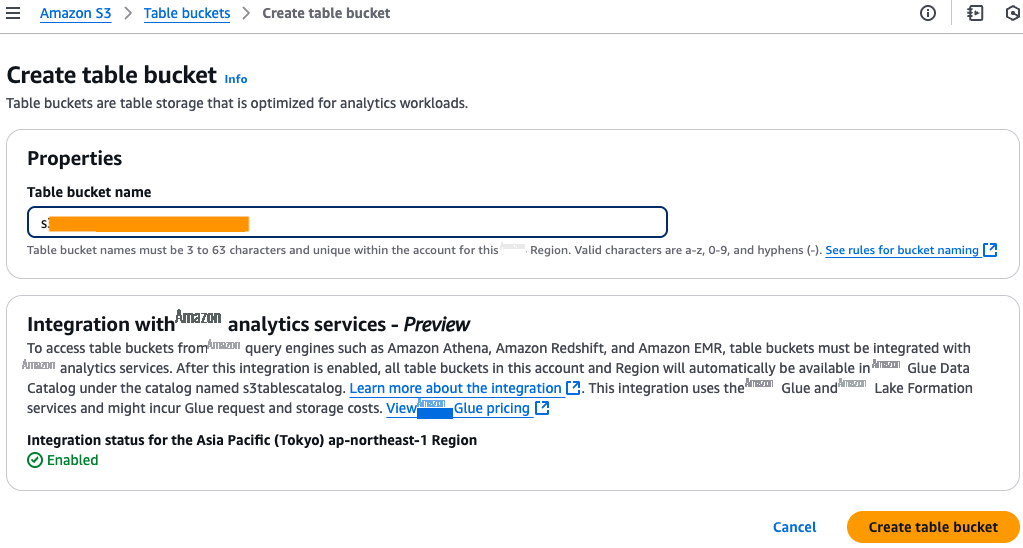
为您的表存储桶指定一个名称,然后继续创建表存储桶,如下图所示。
 2. 在表桶中创建命名空间
2. 在表桶中创建命名空间
使用亚马逊云科技 CLI 在之前创建的表存储桶中创建命名空间 s3tables_demo_namespace,如下所示。命名空间是逻辑结构,可帮助您以可扩展的方式组织表。
aws s3tables create-namespace \ --table-bucket-arn arn:aws:s3tables:<region>:<account-id>:bucket/<s3tablebucket>\ --namespace s3tables_demo_namespace

3. 在表桶中创建表
使用亚马逊云科技 CLI 在表存储桶的现有命名空间中创建一个名为 s3tables_demo_table 的表。创建表时,还可以为该表定义架构。在这篇文章中,我们创建了一个表,其架构由三个字段组成:ID、名称和值。
aws s3tables create-table --cli-input-json file://mytabledefinition.json
以下是用于设置表架构的 mytabledefinition.json 示例。
{
"tableBucketARN": "arn:aws:s3tables:ap-northeast-1:<account-id>:bucket/<s3tablebucket>",
"namespace": "s3tables_demo_namespace",
"name": "s3tables_demo_table",
"format": "ICEBERG",
"metadata": {
"iceberg": {
"schema": {
"fields": [
{"name": "id", "type": "int","required": true},
{"name": "name", "type": "string"},
{"name": "value", "type": "int"}
]
}
}
}
}下图显示了该命令的输出示例:

4. 创建指向命名空间的资源链接
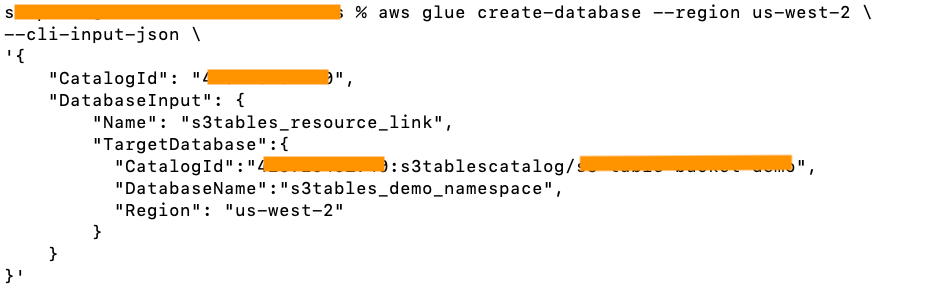
Firehose 将数据传输到在 Amazon Glue 数据目录默认目录中注册的数据库中的表。要将数据流式传输到 S3 表存储桶中的表,请在默认目录中创建指向表存储桶中命名空间的资源链接。资源链接是一个数据目录对象,它充当指向其他数据目录资源(例如数据库或表)的别名或指针。要使用亚马逊云科技 CLI 创建资源链接,请提供您在步骤 2 中为 DatabaseName 创建的命名空间,并在运行命令之前将<region>和<account-id>替换为您的值。
aws glue create-database --region <region> \
--cli-input-json \
'{
"CatalogId": "<account-id>",
"DatabaseInput": {
"Name": "s3tables_resource_link",
"TargetDatabase":{
"CatalogId":"<account-id>:s3tablescatalog/<s3tablebucket>",
"DatabaseName":"s3tables_demo_namespace",
"Region": "<region>"
}
}
}'下图显示了该命令的输出示例。
5. 为 Firehose 创建 IAM 角色
创建一个 IAM 角色,向 Firehose 授予权限,允许其对默认 Amazon Glue 数据目录中的表执行操作,在流式传输到通用 S3 存储桶期间备份失败的记录,以及与 Kinesis 数据流进行交互。此外,根据您的 Firehose 配置,您可以选择为亚马逊 CloudWatch 日志和 Amazon Lambda 函数操作授予额外权限。要进行配置,请在控制台中导航到 IAM,然后使用本 Amazon S3 表格用户指南中提及的权限策略创建 IAM 角色。跟踪您创建的角色,因为以后需要它来授予 Amazon Lake Formation 权限。
6. 配置 Amazon Lake Formation 权限
Amazon Lake Formation 管理对您的表格资源的访问。Lake Formation 使用自己的权限模型,可以对数据目录资源进行精细的访问控制。为了让 Firehose 将数据摄入到表存储桶中,Firehose 角色(在步骤 5 中创建)需要对资源链接(在步骤 4 中创建)的 DESCRIBE 权限,才能通过资源链接发现 S3 表命名空间,以及对基础表的读/写权限。
要在资源链接上添加描述权限,请在控制台中导航到 Lake Formation。在左侧菜单上选择"数据库",然后选择您在步骤 4 中创建的资源链接。选择"操作",选择"授予",然后为 Firehose 角色授予描述权限,如下图所示。在此示例中,Firehose 角色名为 S3FirehoseRole。
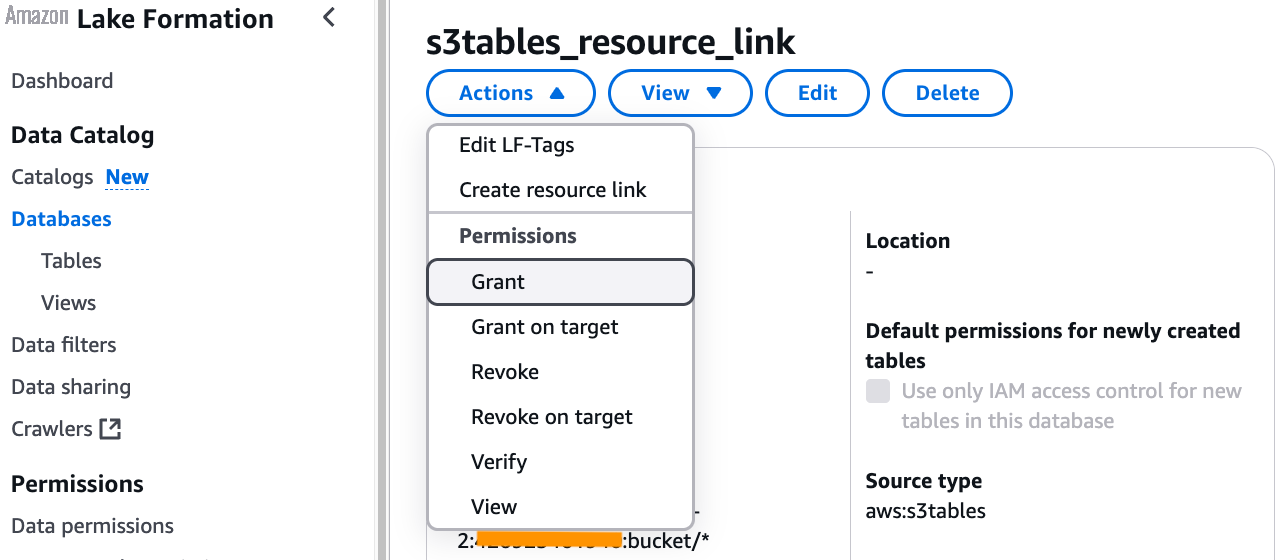
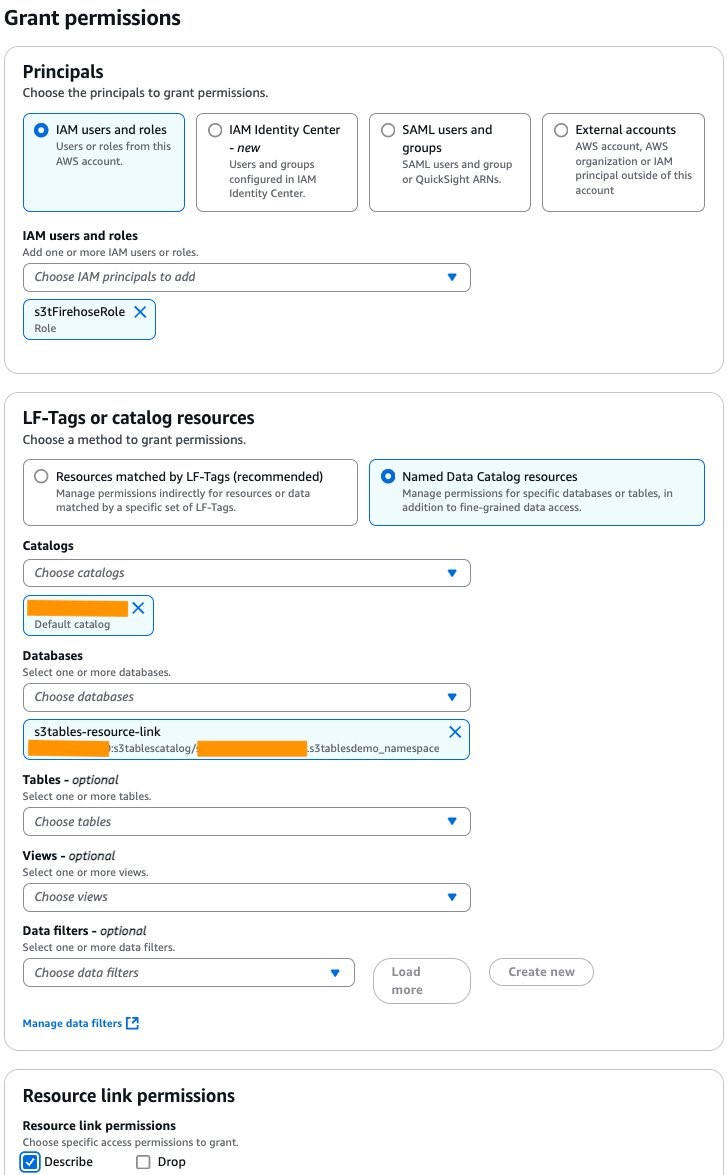
要提供对特定表的读写权限,请返回并在左侧菜单中选择数据库,然后选择您在步骤 4 中创建的资源链接。首先,选择操作,然后选择在目标上授予。选择 Firehose 角色、数据库和表,然后为 Firehose 角色授予超级权限,如下图所示。
7. 设置 Firehose 直播
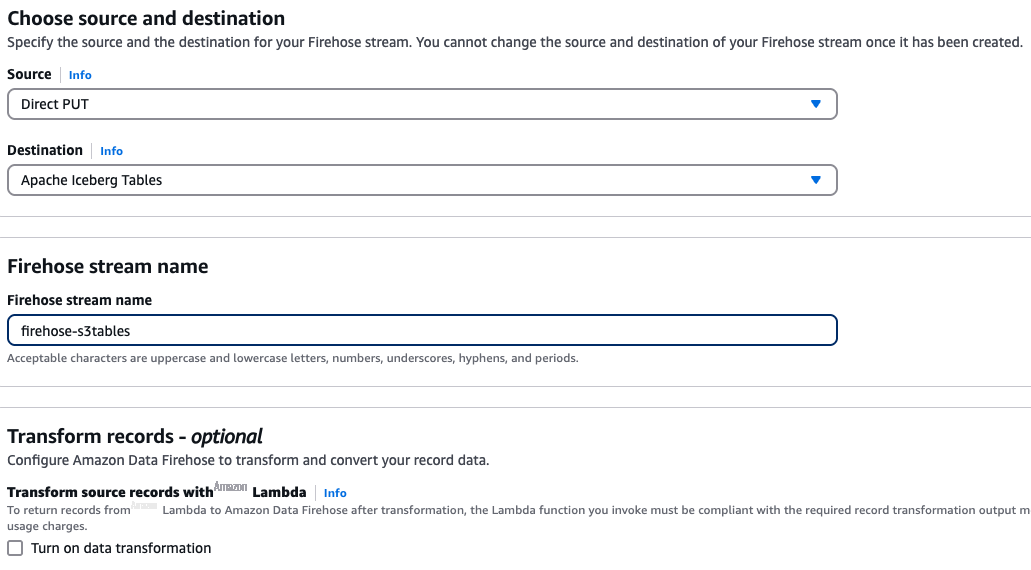
要创建 Firehose 直播,请在控制台中打开 Firehose 并选择 Create Firehose Stream。选择 Direct PUT 作为源,选择 Apache Iceberg Tables 作为目标。然后,按照界面中显示的命名规范,为您的 Firehose 直播选择一个名称,如下图所示。
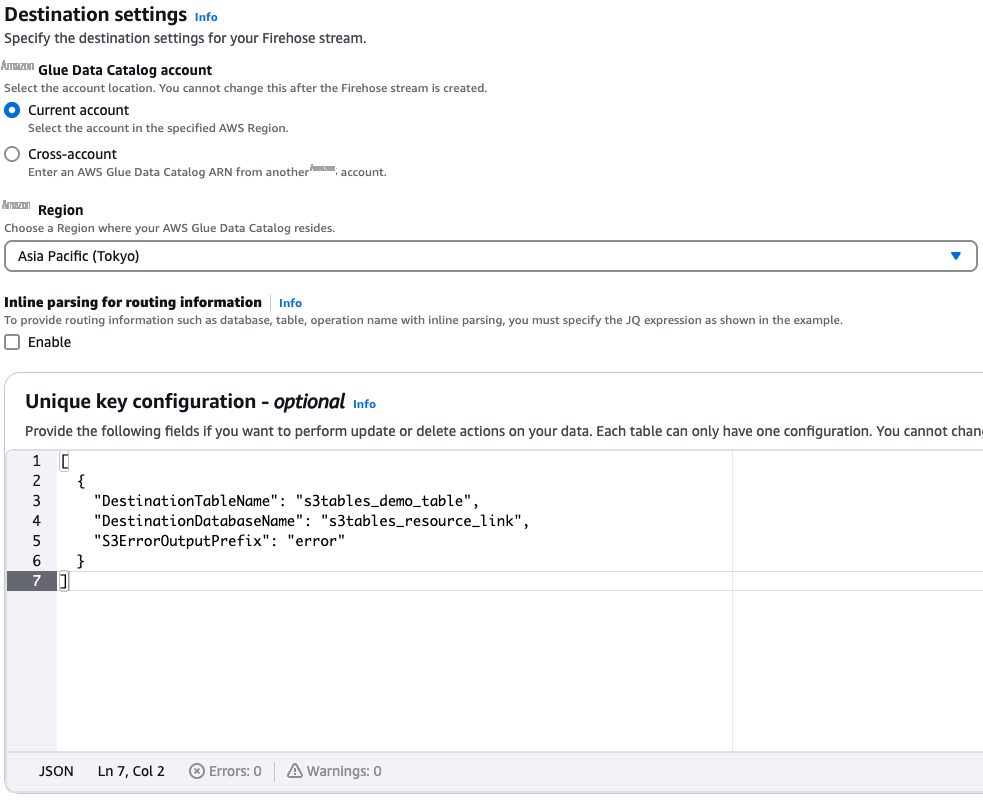
要为您的表存储桶配置目标设置,您需要配置 Firehose 应写入的数据库和表名称。如果您希望 Firehose 直播只写入一个表,则可以配置"唯一密钥配置"部分。要配置此部分,请选择您在步骤 4 中创建的资源链接 (s3tables_resource_link) 作为数据库名称,选择您在步骤 3 中创建的表 (s3tables_demo_table) 作为表名,如下图所示。如果 Firehose 未能传送到配置表,则将其交付给 S3ErrorOutputPrefix。
指定 Amazon S3 通用存储桶来存储未能传输到您的 S3 表存储桶的记录,如下图所示。

在 IAM 角色下,选择您之前在步骤 5 中为 Firehose 创建的角色,然后选择创建 Firehose 直播来创建您的 Firehose 直播,如下图所示。
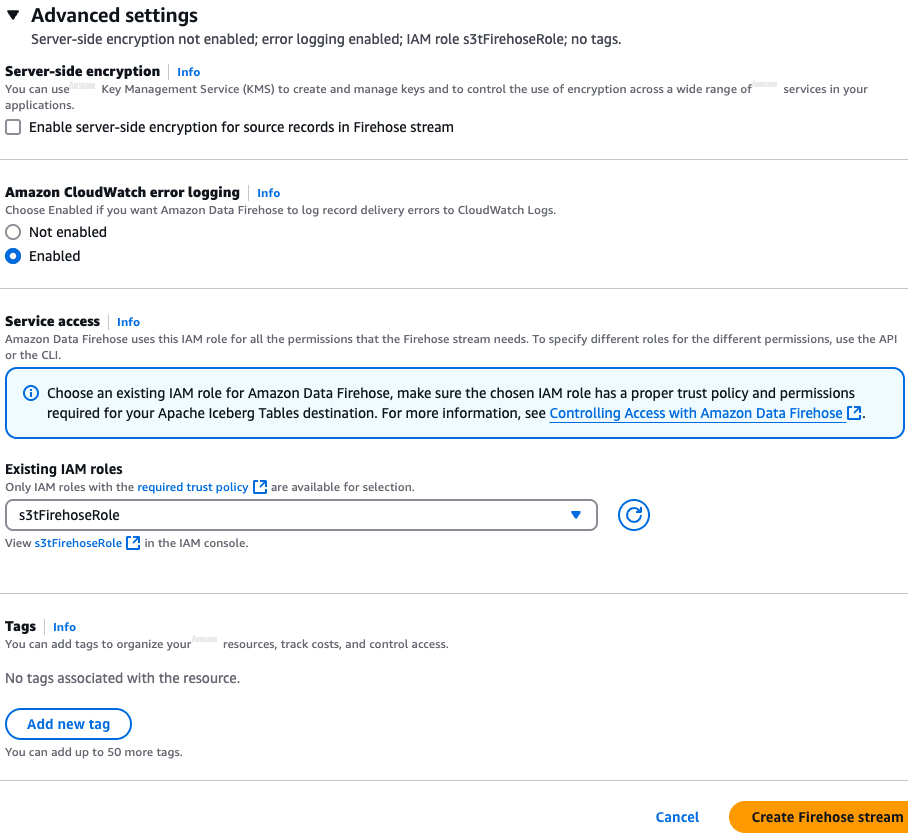
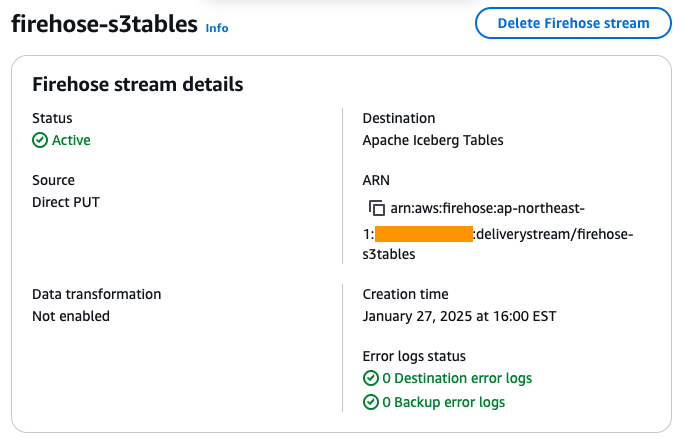
创建直播时,监控 Firehose 传输流的状态,直到其变为 Active,如下图所示
8. 使用 Kinesis 数据生成器发送流媒体数据
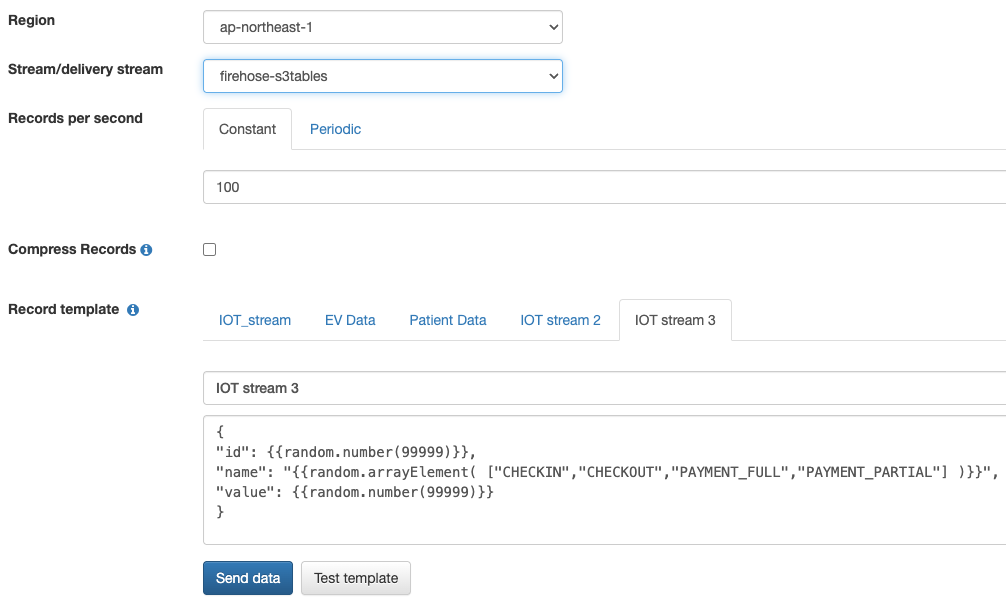
Kinesis 数据生成器是一款允许您将流式数据发送到 Firehose 的应用程序。首先,为您的账户配置 Kinesis 数据生成器。然后,将区域设置为与您的 Firehose 相匹配,并选择在步骤 7 中创建的 Firehose 直播。使用与步骤 3 中定义的表架构相匹配的以下模板,如下图所示。根据创建 Firehose 直播时设置的缓冲间隔,数据最多可能需要 900 秒才能显示在表中。对于这篇文章,我们将其保留为默认值 300 秒。
{
"id": {{random.number(99999)}},
"name": "{{random.arrayElement( ["CHECKIN","CHECKOUT","PAYMENT_FULL","PAYMENT_PARTIAL"] )}}",
"value": {{random.number(99999)}}
}
9. 使用 Athena 验证和查询数据
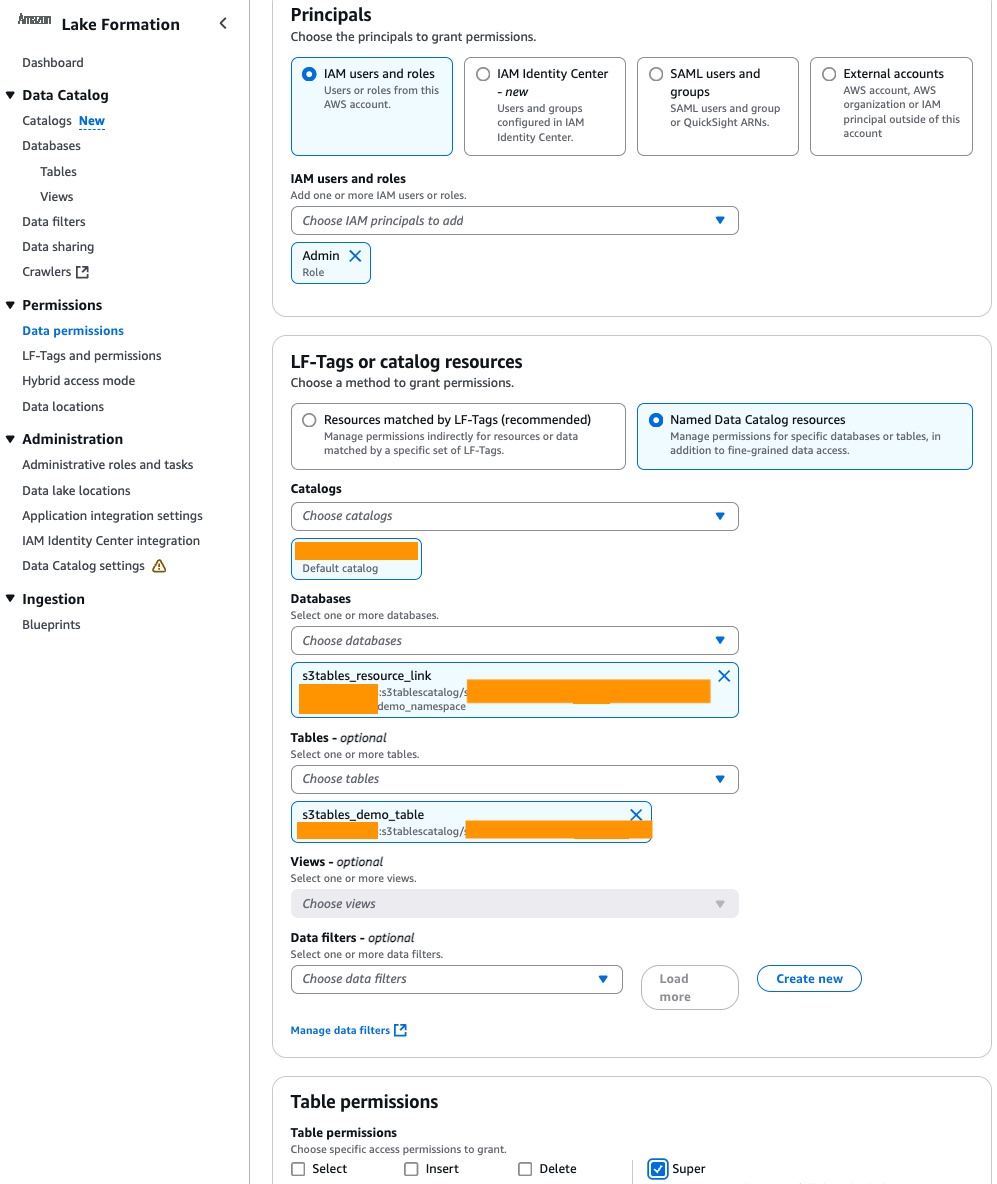
要使用 Athena 查询数据,必须向计划用于 Athena 查询的用户或角色授予 Amazon Lake Formation 对 S3 表的权限。在 Lake Formation 控制台的左侧导航窗格中,选择数据权限并选择授予,然后在"主要用户"下选择您将用于访问 Athena 的用户/角色。在 LF-Tags 或 Catalog 资源中,选择命名数据目录资源、默认目录以及与您的 S3 表存储桶关联的资源链接。然后选择 S3 表并在表下授予 Super 权限,如下图所示。
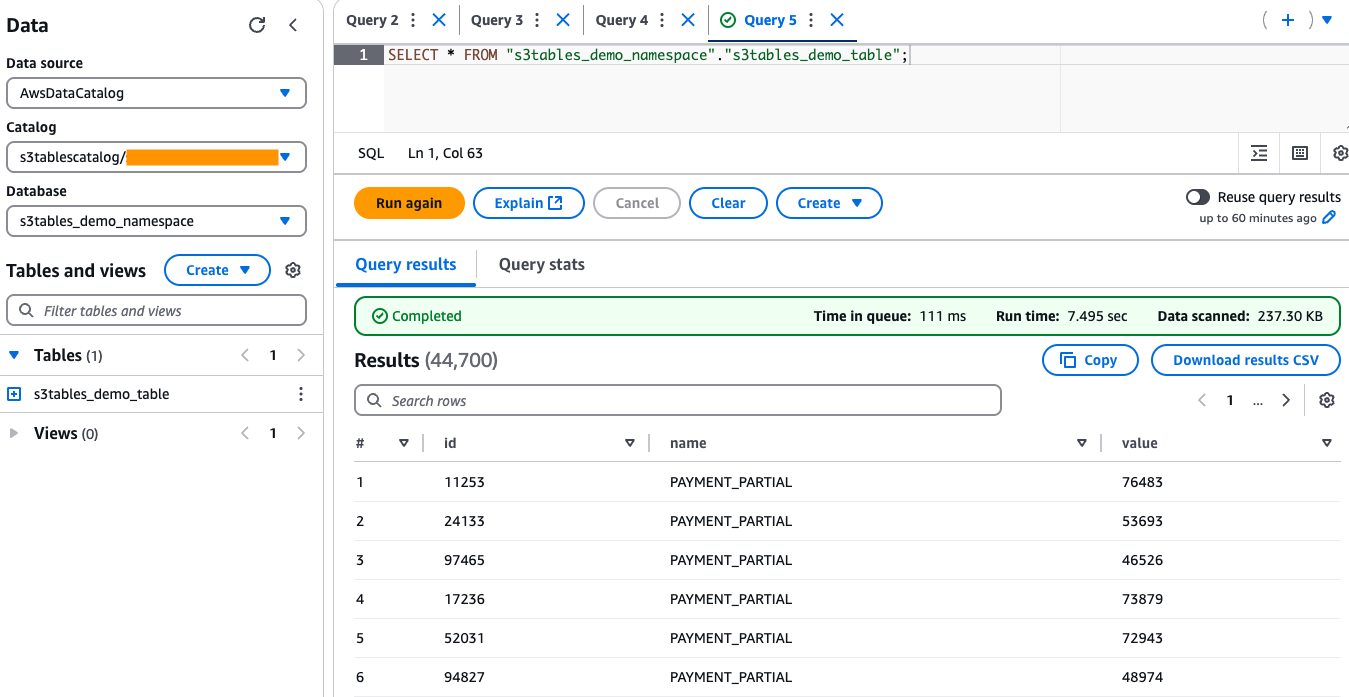
要查询和验证从 Firehose 摄取的数据,请在 Athena 中运行 SELECT 命令,如下图所示。只要从 Kinesis Data Generator 流式传输数据,您就应该继续看到此表中的行数增加,从而确认数据摄取成功。
清理资源
为避免将来产生费用,请删除您在亚马逊 S3 表格和 Firehose 中创建的资源。
注意事项和限制
在将 Firehose 与 Apache Iceberg 一起使用之前,你应该了解注意事项和限制。有关更多信息,请参阅注意事项和限制。
结论
在这篇文章中,我们向您展示了如何使用亚马逊 Data Firehose 和 Amazon S3 表从流数据源构建托管数据湖。我们还展示了如何使用 Amazon Athena 从 S3 表存储桶中查询这些表。这种集成使企业无需管理复杂的基础架构即可自动捕获、存储和分析流数据,从而加快数据驱动的决策制定。

Swapna Bandla
Swapna Bandla 是亚马逊云科技流媒体专家 SA 团队的高级流媒体解决方案架构师。Swapna 热衷于了解客户的数据和分析需求,并帮助他们开发基于云的、架构良好的解决方案。工作之余,她喜欢与家人共度时光。

Anupriti Warade
阿努普里蒂·瓦拉德是亚马逊云科技亚马逊 S3 团队的高级技术产品经理。她热衷于帮助客户创新和构建解决问题的解决方案。Anupriti 总部位于华盛顿州西雅图,喜欢与家人和朋友共度时光、烹饪和创作 DIY 工艺品。

Phaneendra Vuliyaragoli
Phaneendra Vuliyaragoli 是亚马逊云科技亚马逊 Data Firehose 的产品管理主管。在此职位上,Phaneendra 负责领导亚马逊 Data Firehose 的产品和市场进入战略。

普拉尚特·辛格
Prashant Singh 是一名软件开发工程师,在数据库和数据仓库引擎方面拥有专业知识。他曾致力于优化 Apache Iceberg 性能及其在亚马逊 EMR(Apache Spark)、亚马逊 Redshift 和亚马逊数据 Firehose 等服务之间的集成。Prashant 还是包括 Apache Spark 和 Apache Iceberg 在内的开源项目的积极贡献者。工作之余,他喜欢探索新地方、滑雪和徒步旅行。

拉克什·戈达萨拉
拉克什·戈达萨拉是亚马逊云科技汽车制造领域的解决方案架构师。他帮助客户进行应用程序现代化和云迁移。他的核心专业知识是数据分析和云架构。工作之余,他喜欢打乒乓球、看电视以及和女儿们一起玩。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。