我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
亚马逊 SageMaker HyperPod 任务管理最佳实践
在亚马逊云科技re: Invent 2024上,我们在亚马逊弹性Kubernetes Service(亚马逊 EKS)上推出了亚马逊SageMaker HyperPod的一项新创新,它使您能够在共享的加速计算资源上高效地运行生成式人工智能开发任务,并将成本降低多达40%。管理员可以使用 SageMaker HyperPod 任务管理来管理对团队和项目的加速计算分配,并执行确定不同类型任务优先级的策略。由此产生的计算资源利用率的提高使组织能够专注于加快生成式 AI 创新和缩短上市时间,而不是花时间协调资源分配和持续重新规划其生成式 AI 开发任务。
在这篇文章中,我们提供了优秀实践,以最大限度地发挥 SageMaker HyperPod 任务治理的价值,并提供无缝的管理和数据科学体验。我们还讨论了管理和运行生成式 AI 开发任务时的常见治理方案。
先决条件
要开始在由亚马逊 EKS 编排的现有 SageMaker HyperPod 集群上使用 SageMaker HyperPod 任务管理,请务必卸载所有现有 Kueue 安装的设备,并让 Kubernetes 集群运行 1.30+ 版本。
管理经验
管理员是第一个与 SageMaker HyperPod 任务管理互动的角色。他们负责根据组织的优先事项和目标管理集群计算分配。
管理计算
管理跨团队容量的第一步是设置计算分配。设置计算分配时,请记住以下注意事项:
- 该团队通常执行什么类型的任务?
- 这个团队是否经常执行任务并需要预留容量?
- 与其他球队相比,这支球队的优先级是什么?
在设置计算分配时,管理员会设置团队的公平份额权重,这提供了与其他团队在争夺相同空闲计算时相比的相对优先级。更高的权重使团队能够更快地访问共享容量内的未利用资源。优秀做法是,为需要比其他团队更快获得容量的团队设置更高的公平份额权重。
设定公平份额权重后,管理员随后设置配额和借款策略。配额决定了集群实例组中每个实例类型的分配。借款策略决定了团队是共享还是保留分配的容量。为了强制进行适当的配额管理,总预留配额不应超过集群对该资源的可用容量。例如,如果集群包含 20 个 ml.c5.2xlarge 实例,则分配给团队的累计配额应保持在 20 以下。
如果团队的计算分配允许 “借出” 或 “借出”,则空闲容量将由这些团队共享。例如,如果团队 A 的配额为 6,但仅使用 2 个用于其任务,而小组 B 的配额为 5 且使用 4 个用于其任务,而提交给团队 B 的任务需要 4 个资源,则将根据其 “借出和借用” 设置从团队 A 借用 3 个。如果任何团队的计算分配设置为 “不借出”,则该团队将无法借用超出其预留容量的任何额外容量。
为了维护所有团队都可以借用的资源池或一组资源,用户可以建立一个专门的团队,其资源可以弥合其他团队的分配与集群总容量之间的差距。确保此累积资源分配包括相应的实例类型,且不超过集群总容量。为确保这些资源可以在团队之间共享,请允许参与团队将该公共资源池的计算分配设置为 “借出并借用” 或 “借出”。此外,每次引入新团队、更改配额分配或集群容量发生任何变化时,都要重新审视所有团队的配额分配,以确保累积配额保持在或低于集群容量。
设置计算分配后,管理员还需要设置集群策略,该策略由两个部分组成:任务优先级和空闲计算分配。管理员将设置任务优先级,该优先级确定集群中运行的任务的优先级。接下来,管理员将空闲计算分配设置设置为 “先到先得”(不优先考虑任务)或 “公平分配分配”,即根据团队的公平份额权重将空闲计算分配给团队。
可观测性
要开始使用可观测性,请安装选中 Kueue 指标的 Amazon CloudWatch 可观测性插件。SageMaker HyperPod 任务管理仪表板为各团队的集群利用率提供了单一窗格视图。目前,你可以查看为 PyTorch、TensorFlow 和 MPI 任务运行的任务。管理员可以分析仪表板中的图表,以了解资源共享和资源利用率的公平性。
要查看资源利用率,用户可以看到以下显示 GPU 和 vCPU 利用率的仪表板。这些图表告知管理员,团队可以在哪些方面进一步最大限度地提高 GPU 利用率。在此示例中,管理员观察到 GPU 利用率约为 52%
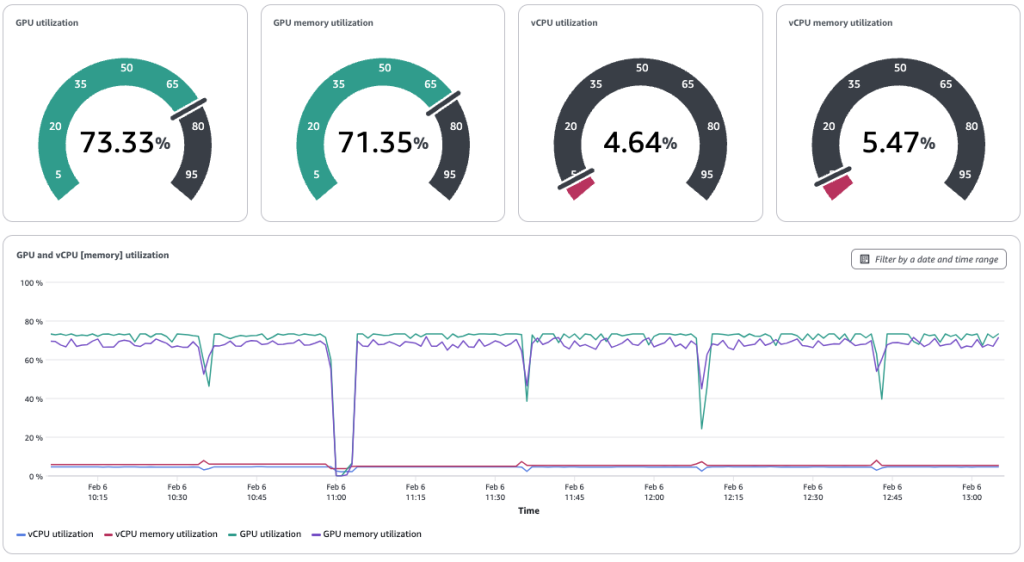
管理员可以实时查看任务正在运行或在抢占期间移至待处理状态时的实例利用率。在此示例中,机器学习工程团队借用 5 个 GPU 来完成训练任务

使用 SageMaker HyperPod,你还可以设置自己选择的可观测性工具。在我们的公开研讨会上,我们将介绍如何设置亚马逊托管的 Prometheus 和 Grafana 控制面板。
数据科学家的经验
数据科学家是第二个与 SageMaker HyperPod 集群互动的角色。数据科学家负责在加速计算实例上训练、微调和部署模型。确保数据科学家在与 GPU 集群交互时拥有必要的容量和权限非常重要。
访问控制
在使用SageMaker HyperPod任务管理时,数据科学家将承担其特定角色。每个数据科学团队都需要在集群上拥有自己的角色和相关的基于角色的访问控制 (RBAC)。RBAC 防止数据科学家向他们不属于的团队提交任务。有关数据科学角色权限的更多信息,请参阅 SageMaker HyperPod 的 Amazon Identity and Access Management。作为优秀实践,管理员应根据最小权限原则限制数据科学家。设置角色和访问条目后,数据科学家可以代入其关联的 Amazon Identity and Access Management (IAM) 角色,向相应的命名空间提交任务。请务必注意,与控制台仪表板交互但未创建关联 EKS 集群的用户需要将其角色添加到 EKS 集群的 AccessEntry 列表中。
提交任务
有两种方法可以在亚马逊 EKS 精心编排的 SageMaker HyperPod 集群上提交任务:kubectl 和 SageMaker HyperPod CLI。在这两个选项中,数据科学家将需要在任务配置文件中引用其团队的命名空间和任务优先级类,以便按适当的优先级使用分配的配额。如果用户没有指定优先级,那么 SageMaker HyperPod 任务管理将自动采用最低优先级。
在以下代码片段中,我们显示了研究人员命名空间的 kubectl 清单文件中需要的推理优先级标签。优先级类将在群集策略中设置的名称后附加-priority。有关向 SageMaker HyperPod 任务管理提交任务的更多指导,请访问此处的文档。
metadata:
name: job-name
namespace: hyperpod-ns-researchers
labels:
kueue.x-k8s.io/queue-name: hyperpod-ns-researchers-localqueue
kueue.x-k8s.io/priority-class: inference-priorityHyperPod
HyperPod CLI 的创建是为了抽象使用 kubectl 的复杂性,让使用 SageMaker HyperPod 的开发人员能够更快地使用自定义命令进行迭代。HyperPod CLI v2.0.0 引入了新的默认调度器类型,具有自动填充命令、自动发现命名空间、改进了集群和任务管理功能,并增强了对任务优先级和加速器配额分配的可见性。数据科学家可以使用新的 HyperPod CLI 在其生成式 AI 开发生命周期中快速提交任务、进行迭代和实验。
命令示例
以下是与 SageMaker HyperPod 任务管理交互时的有用命令的简短参考指南:
- 使用亚马逊云科技CLI 描述集群策略 — 此亚马逊云科技命令行接口 (亚马逊云科技CLI) 命令可用于查看集群的集群策略设置。
- 使用亚马逊云科技CLI 列出计算配额分配 — 此亚马逊云科技CLI 命令可用于查看不同的团队、设置任务监管及其各自的配额分配设置。
- HyperPod CLI — HyperPod CLI 抽象了用于与 SageMaker HyperPod 集群交互的常用 kubectl 命令,例如提交、列出和取消任务。有关命令的完整列表,请参阅。
- kubectl — 您还可以使用 kubectl 通过以下示例命令与任务治理进行交互:
kubectl get pytorchjobs -n hyperpod-ns-<team-name>此命令向您显示在指定团队命名空间中运行的 PyTorch 任务。kubectl get workloads -n hyperpod-ns-<team-name>/kubectl describe workload <workload-name> -n hyperpod-ns-<team-name>— 这些命令显示每个命名空间在集群中运行的工作负载,并提供有关 Kueue 准入的详细理由。您可以使用这些命令来回答诸如 “为什么我的任务被抢占了?” 之类的问题或者 “为什么我的任务被录取了?”
常见场景
SageMaker HyperPod 任务管理支持向团队分配计算配额,提高计算资源利用率,降低成本,按优先级加快等待任务,进而缩短上市时间。为了将这些价值主张与实际工作场景联系起来,我们将讨论企业和初创企业的情况。
企业有不同的团队努力实现不同的业务目标,每个团队的预算都会限制其计算访问权限。为了在预算限制内最大限度地提高资源利用率,SageMaker HyperPod 任务治理允许企业为团队分配计算配额,以执行人工智能和机器学习 (AI/ML) 任务。当团队用尽分配的资源时,他们可以访问其他团队的闲置计算以加快等待的任务,从而在整个组织内提供优秀的资源利用率。
初创公司的目标是最大限度地提高计算资源利用率,同时实现对高优先级任务的及时分配。SageMaker HyperPod 任务管理的优先级功能允许您为不同的任务类型分配优先级,例如将推理优先于训练。这可确保高优先级任务在优先级较低的任务之前获得必要的计算资源,从而优化整体资源分配。
现在,我们将向您介绍用户与SageMaker HyperPod任务治理进行交互的两种常见场景。
场景 1:企业
在第一种情况下,我们有一家企业公司想要管理计算分配以优化成本。该公司有五个团队共享 80 个 GPU,配置如下:
- 第 1 组 — 计算分配:20;策略:不要借
- 第 2 组 — 计算分配:20;策略:不要借
- 第 3 组 — 计算分配:5;策略:以 150% 的比例借出;公平份额权重:100
- 第 4 组 — 计算分配:10;策略:按百分之百的贷款和借款;公平份额权重:75
- 第 5 组 — 计算分配:25;策略:按照 50% 的比例借出;公平份额权重:50
此示例配置为将持续使用实例执行高优先级任务的团队保留了容量。此外,一些团队可以选择借出和借用其他团队的空闲计算——这样可以根据需要预留容量并允许使用优先级排列的可用空闲计算来运行不一致的工作负载,从而改善成本优化。
场景 2:启动
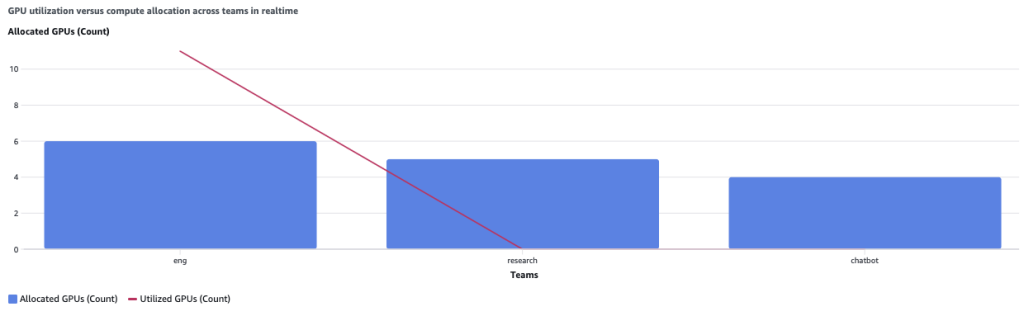
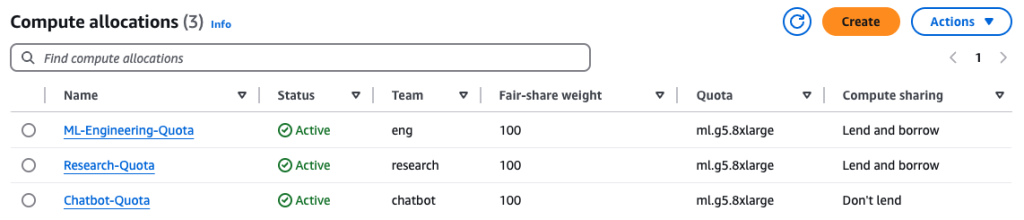
在第二种情况下,我们有一位初创客户希望为其工程和研究团队的成员提供公平的计算分配。该公司有三个团队共享 15 个 GPU:
- 第 1 组(机器学习工程)— 计算分配:6;策略:按照 50% 进行借款;公平份额权重:100
- 第 2 小组(研究人员)— 计算分配:5;策略:按50%进行借款;公平份额权重:100
- 第 3 小组(实时聊天机器人)— 计算分配:4;策略:不借;公平份额权重:100
此示例配置促进了整个公司的公平计算分配,因为所有团队都有相同的公平份额权重,并且能够抢占优先级较低的任务。
结论
在这篇文章中,我们讨论了有效使用SageMaker HyperPod任务治理的优秀实践。我们还提供了某些模式供您在管理生成式 AI 任务时采用,无论您的目标是优化成本,还是进行优化以实现公平的计算分配。要开始使用 SageMaker HyperPod 任务治理,请参阅亚马逊 SageMaker HyperPod 研讨会中的亚马逊 EKS 支持和 SageMaker HyperPod 任务治理。
作者简介
 Nisha Nadkarni 是亚马逊云科技的 GenAI 高级专家解决方案架构师,她指导公司在亚马逊云科技上部署大规模分布式训练和推理时采用优秀实践。在担任现任职务之前,她在亚马逊云科技工作了几年,专注于帮助新兴的GenAI初创公司开发从构思到生产的模型。
Nisha Nadkarni 是亚马逊云科技的 GenAI 高级专家解决方案架构师,她指导公司在亚马逊云科技上部署大规模分布式训练和推理时采用优秀实践。在担任现任职务之前,她在亚马逊云科技工作了几年,专注于帮助新兴的GenAI初创公司开发从构思到生产的模型。
 Chaitanya Hazarey 领导亚马逊SageMaker HyperPod任务治理的软件开发,带来了全栈工程、机器学习/人工智能和数据科学方面的丰富专业知识。作为负责任的人工智能开发的热情倡导者,他将技术领导力与提高人工智能能力的坚定承诺相结合,同时保持道德考量。他对现代产品开发的全面理解推动了机器学习基础设施的创新。
Chaitanya Hazarey 领导亚马逊SageMaker HyperPod任务治理的软件开发,带来了全栈工程、机器学习/人工智能和数据科学方面的丰富专业知识。作为负责任的人工智能开发的热情倡导者,他将技术领导力与提高人工智能能力的坚定承诺相结合,同时保持道德考量。他对现代产品开发的全面理解推动了机器学习基础设施的创新。
 贾里姆·赛义德·穆罕默德是亚马逊云科技的产品经理。他专注于计算优化和成本治理。在此之前,他在亚马逊 QuickSight 负责嵌入式分析和开发人员体验。除了 QuickSight 之外,他还曾在 Amazon Marketplace 和 Amazon Retail 担任产品经理。Kareem 的职业生涯始于呼叫中心技术开发人员、Expedia 的本地专家和广告以及麦肯锡的管理顾问。
贾里姆·赛义德·穆罕默德是亚马逊云科技的产品经理。他专注于计算优化和成本治理。在此之前,他在亚马逊 QuickSight 负责嵌入式分析和开发人员体验。除了 QuickSight 之外,他还曾在 Amazon Marketplace 和 Amazon Retail 担任产品经理。Kareem 的职业生涯始于呼叫中心技术开发人员、Expedia 的本地专家和广告以及麦肯锡的管理顾问。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。