我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
创建高可用工作负载的最佳实践

许多迁移到云端的公共部门组织经常误解亚马逊网络服务 (亚马逊云科技) 区域和可用区的架构从根本上改变了他们对灾难恢复和弹性的看法。在加入 亚马逊云科技 之前,我花了很多年时间帮助组织了解和制定灾难恢复计划。现在在 亚马逊云科技,我与公共部门各种规模的客户合作,构建具有成本效益和弹性的工作负载。在这篇博客文章中,我分享了一些最佳实践,以回答有关构建高可用性工作负载的常见问题,并分享一些考虑 亚马逊云科技 中高可用性、灾难恢复和应用程序灵活性的方法。
我需要在多个区域部署我的工作负载吗?
当组织问 “我需要进入多区域来支持我的灾难恢复需求吗?”我的第一个问题是询问工作负载的恢复时间目标 (RTO),即你可以容忍的停机时间,以及恢复点目标 (RPO),即你可以承受丢失多少数据。
我看到许多组织犯的主要错误是在开始讨论灾难恢复之前没有明确定义的 RTO 和 RPO 目标。每个组织都希望零停机时间和零数据丢失,但现实是系统出现故障。甚至亚马逊首席技术官(CTO)沃格尔斯(Werner Vogels)也表示:“
在本地世界中,跨多个数据中心运行工作负载(大多数组织认为这是 “灾难恢复”)对于许多 RTO/RPO 目标来说是必要的,因为数据中心是单点故障。但是,将工作负载迁移到 亚马逊云科技 时,最佳做法是在多个
每个组织和工作负载都不同。一些公共部门组织的工作负载可能可以承受更高的 RTO 目标(例如,更长的恢复时间)。例如,非营利组织的筹款申请可能只需要将RTO/RPO设定为工时目标即可。相反,非营利性医疗保健组织可能面临生命所依赖的关键工作量,因此RTO/RPO目标是几分钟甚至是实时。尽管没有哪个组织希望停机,但请记住,随着 RTO/RPO 目标的降低(例如,更快的恢复速度和更少的数据丢失),成本和复杂性可能会急剧增加(图 1)。
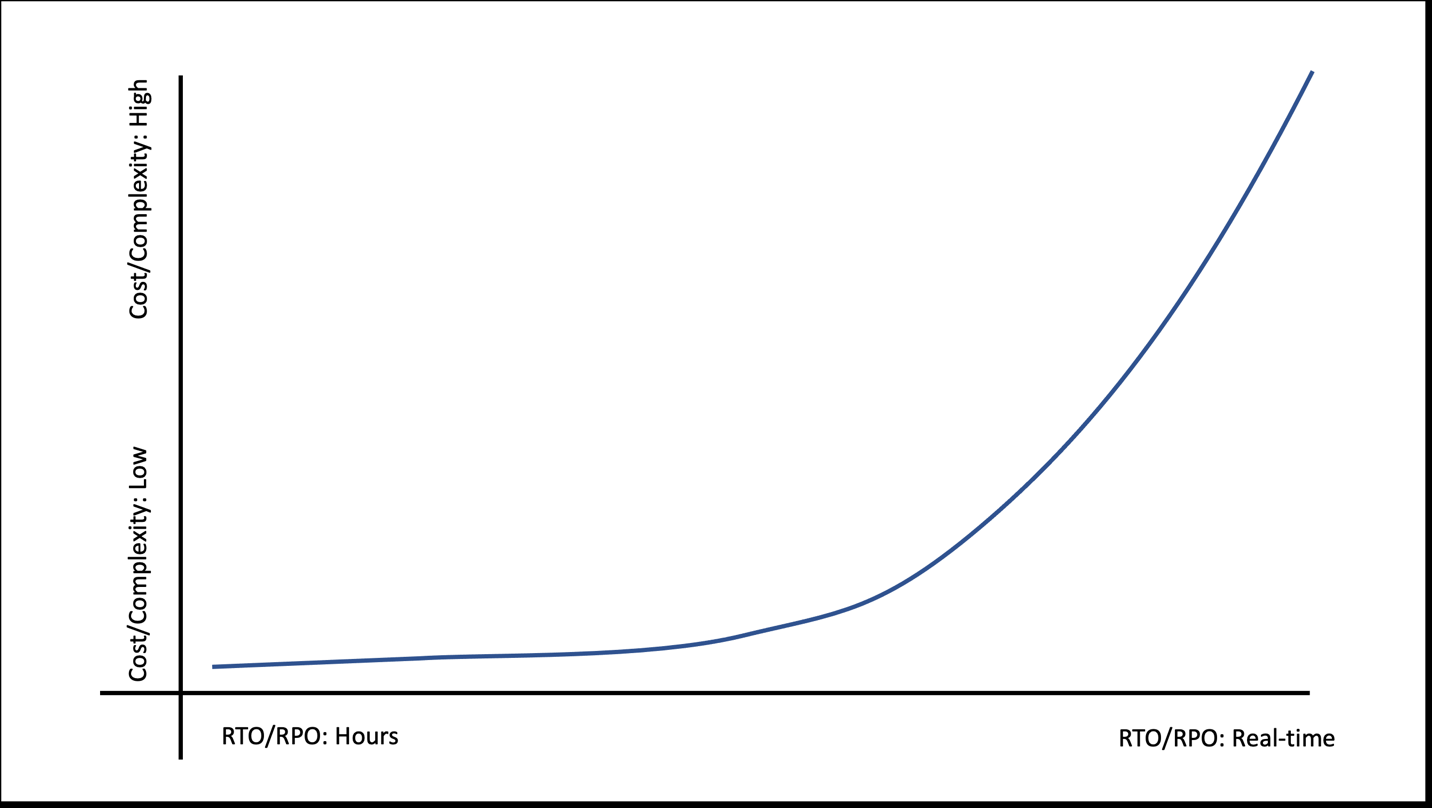
图 1。随着 RTO/RPO 的减少,比如减少停机时间和潜在的数据丢失量,成本可能会大幅增加。
也就是说,亚马逊云科技为许多
如何使我的工作负载尽可能具有弹性?
尽管组织可能不需要在多个区域同时部署工作负载(例如作为多区域主动/主动灾难恢复策略的一部分),但他们仍然希望确保最大限度地减少中断并且工作负载尽可能具有弹性。
亚马逊云科技 在 AW
考虑控制平面和数据平面
在 亚马逊云科技,我们经常谈论
实现静态稳定性以支持可用性
另一种常见模式是
例如,如果工作负载在 Amazon EC2 上运行 Amazon EC
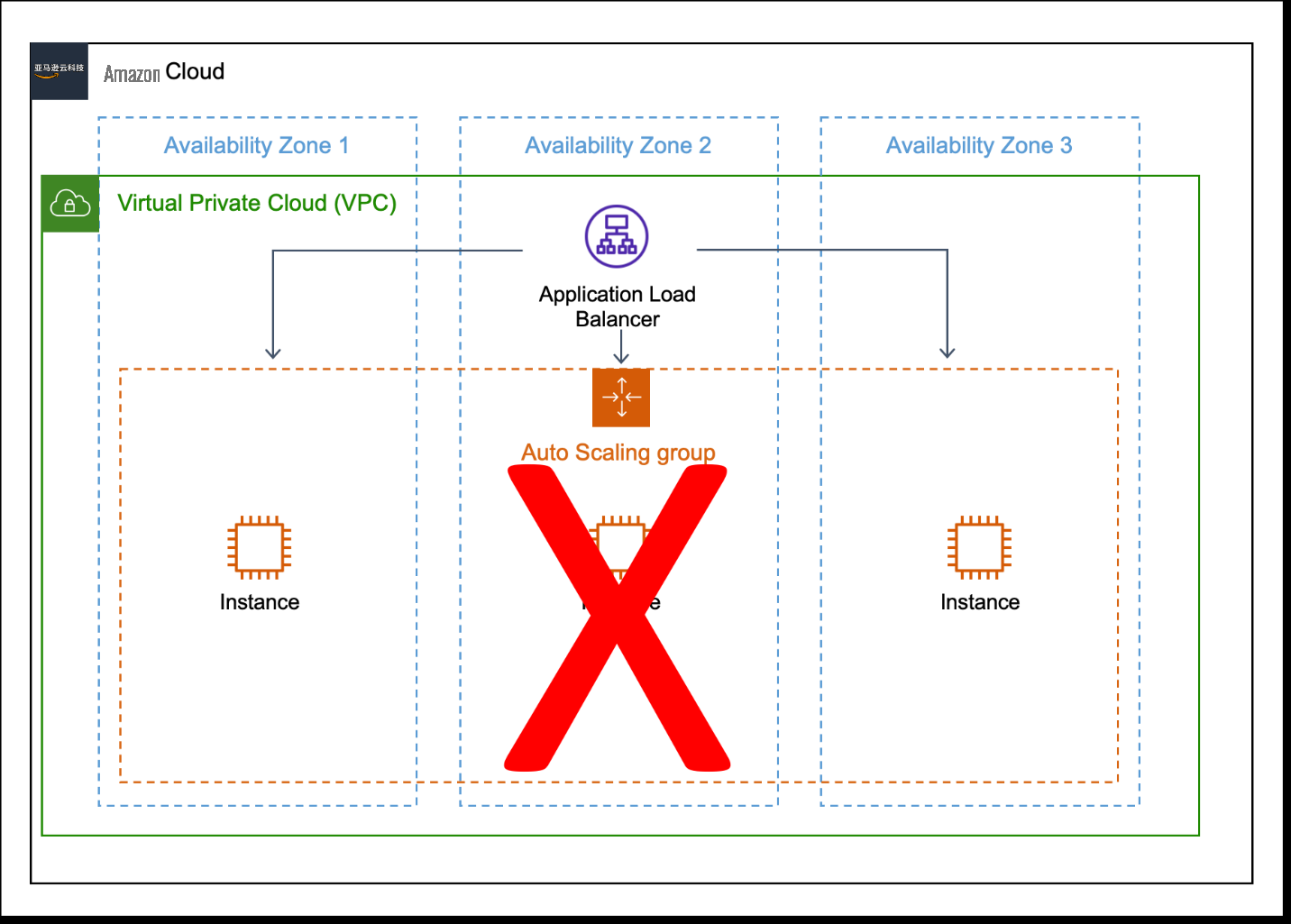
图 2。未表现出静态稳定性的工作负载。该工作负载需要三个 Amazon EC2 实例,但在可用区 2 经历停机后只有两个。
即使在服务中断期间,静态稳定性也意味着工作负载仍然可以满足性能标准。为了在本示例中实现静态稳定性,工作负载应在每个可用区运行两个 Amazon EC2 实例。即使失去可用区并影响自动扩展服务,工作负载仍可以继续达到性能目标(图 3)。
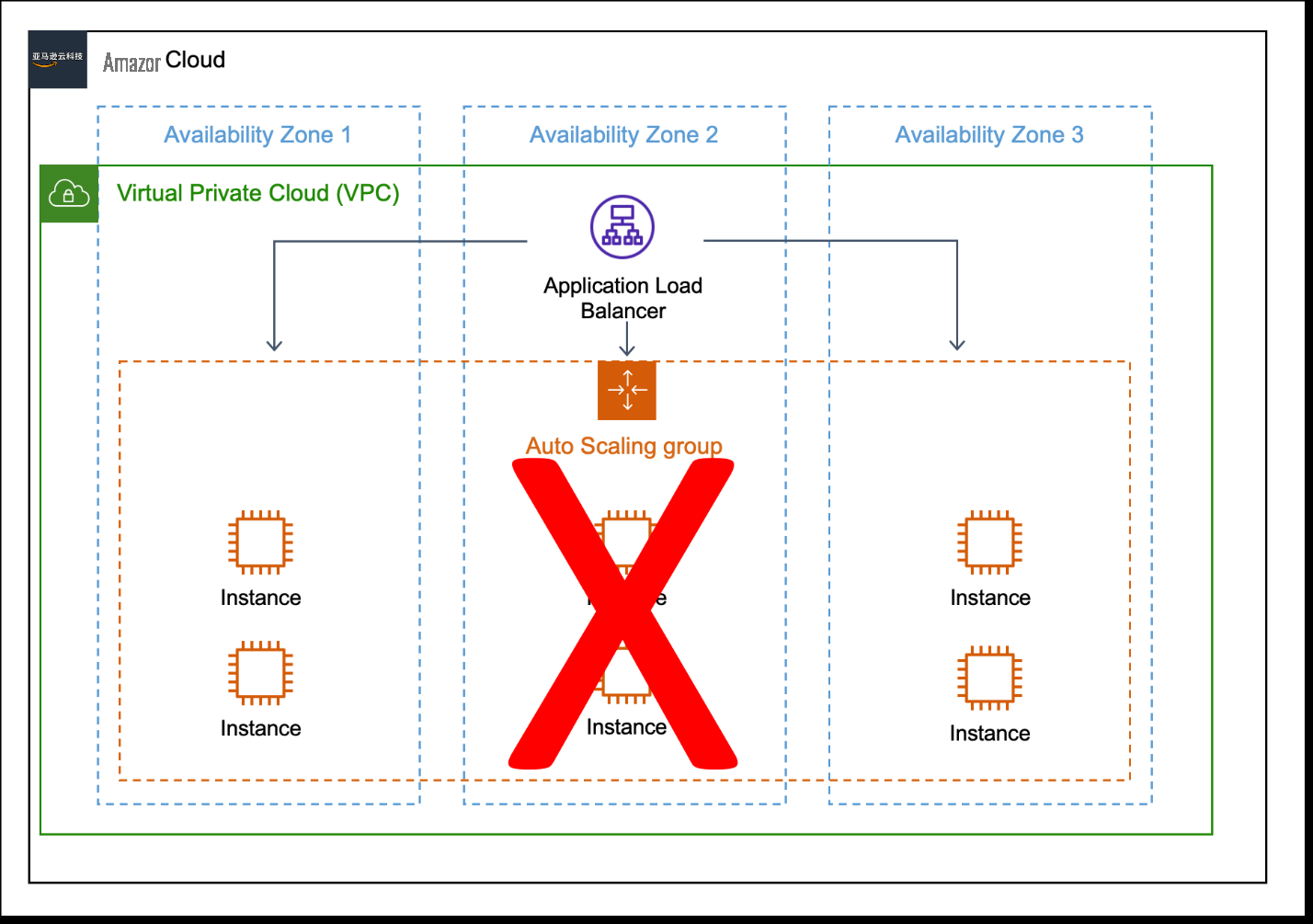
图 3。表现出静态稳定性的工作负载。此工作负载需要三个 Amazon EC2 实例,并且有四个,即使可用区 2 出现停机也是如此。
静态稳定性是 亚马逊云科技 努力实现的工作负载属性。保持此属性可能意味着您的工作负载略有超额配置,但它更能抵御意外故障。
使用自动化进行构建以节省时间并支持可扩展性
最后一种模式是自动化。与我合作的许多组织都没有足够的人力或资金,无法按照他们想要的方式推进使命。自动化是技术支持任务的一种方式,而不是阻碍任务或分散注意力。
组织通常使用源代码控制工具来保护和版本源代码。为什么云基础设施应该有所不同?
楼宇自动化确实需要更多的前期时间,这就是为什么一些组织决定跳过它的原因——短期内牺牲了长期收益。但是,成功的组织花时间来自动化部署,并将其基础架构视为代码。这种做法可以在未来获得回报,当您的组织决定扩展时,您可以轻松地将架构和工作负载重新部署到多个 亚马逊云科技 账户。自动化还可以帮助在多个 亚马逊云科技 区域之间简单地部署工作负载,从而支持灾难恢复目标。由于实现了自动化,与我合作的一位公共部门客户每周能够对其工作负载进行超过 6,000 次的更改。
结论和创建高可用工作负载的后续步骤
在这篇博客文章中,我讨论了制定灾难恢复计划的注意事项。组织的灾难恢复计划应基于每个相关工作负载的恢复时间和恢复点目标。考虑到成本和其他资源方面的考虑,这些目标将帮助组织确定哪种类型的灾难恢复解决方案最合适。
关键工作负载模式可以帮助组织实施更具弹性的工作负载。这些模式包括缩小工作负载的爆炸半径,因此如果出现故障,影响是有限的,不会对整个工作负载产生负面影响;静态稳定性,即使面临负面影响,也能让工作负载继续为面向客户的请求提供服务;以及自动化,它可以帮助任何规模的团队扩展到原本无法做到的范围。
下一步,检查您的工作负载并确定 RTO/RPO 目标是什么。查看您的现有架构,确定能否消除瓶颈或其他单点故障。您是否将控制平面功能与数据平面功能混合在一起?你能重构这段代码以提供更好的弹性吗?团队成员是否将时间花在
在
阅读有关 亚马逊云科技 在公共部门实现弹性的更多信息:
-
用于灾难恢复、业务连续性规划和灾难准备的 Goldilocks 区域 -
使用新的《亚马逊云科技 上的政府 IT 连续性》解决方案指南保护关键服务 -
建立数字能力以抵御未来的挑战,从网络攻击到恶劣天气事件 -
利文斯顿教区如何通过提高云端弹性来为自然灾害做准备 -
罗克代尔县如何利用云改善运营和安全性
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。