我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
Babelfish 获得 Aurora PostgreSQL 性能测试结果
在这篇博客文章中,我将分享使用
这篇博客文章最后总结了你可能期望从 Babelfish 获得的性能值。我想强调的是,该分析并未将Babelfish与其他RDBMS进行比较,而是侧重于Babelfish本身的性能特征。
1。为什么我们需要 Babelfish 性能测试
适用于 Aurora PostgreSQL 的 Babelfish 是亚马逊 Aurora PostgreSQL 兼容版的一项功能,它使 Aurora 能够理解为微软 SQL Server 编写的应用程序中的命令。通过允许Aurora PostgreSQL理解
随着 Babelfish 的成熟,可以提供更多的特性和功能,越来越多的 SQL Server 工作负载可以迁移到 Babelfish。因此,许多 亚马逊云科技 客户
除了兼容 Babelfish 之外,这些客户还有兴趣了解他们可能期望 Babelfish 获得什么样的性能,以及他们应该如何设置 Aurora 集群以节省成本并优化其在 Babelfish 上的工作负载的性价比。为了回答这些问题,我按照博客文章为 A
2。选择 Babelfish 基准测试场景
2.1。设置用于基准测试的数据库
我将使用 HammerDB 4.4
对于 OLTP 工作负载,我尝试涵盖各种场景,因此我使用 8, 000、30,000 和 75, 00 0 个 仓库生成了三个 HammerDB 数据库 ,结果生成了大约 0.87 、 3.3 和 8.2 太字节的测试数据库。 这些数据库代表了范围广泛的相对较小到相当大的工作负载。
2.2。选择实例类型
我在测试中包含的第一个实例类是 db.r5 。此类中的实例是经过内存优化、基于 Nitro 的实例,非常适合内存密集型应用程序,例如高性能数据库。
2022 年 7 月 15 日,亚马逊 Aurora PostgreSQL 兼容版
考虑到测试数据库的大小相对较大,我选择了每个类中的大型实例进行测试。最终选择进行测试的阵容如表 1 所示:
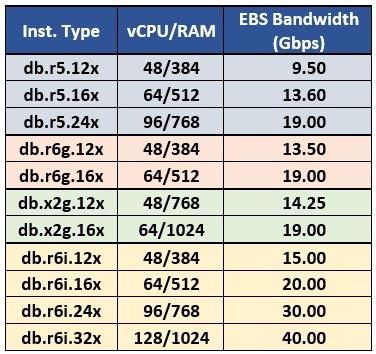 表 1.用于 Babelfish 性能测试的实例类型阵容。
表 1.用于 Babelfish 性能测试的实例类型阵容。
2.3。选择用于基准测试的虚拟用户数量
HammerDB
虚拟用户
是对数据库进行压力测试的模拟用户。要估计系统的最大性能,最好从相对较少的虚拟用户开始,然后逐渐增加他们的数量,直到数据库达到其最高性能水平。当我们增加虚拟用户数量(代表系统负载)时,性能指标
当数据库接近饱和点时,性能变化变得越来越慢。因此,对于 HammerDB 基准测试,一系列测试的虚拟用户数量通常按几何级数设置。 我为每个环境选择了以下一组虚拟用户: 256 、 362 、 512 、 724 和 1024 。
通常,
2.4。选择绩效指标
HammerDB 报告了
基于这些因素,我选择了NOPM作为报告Babelfish性能测试运行的指标。
2.5。确定每种测试配置的性能
为了获得统计上稳定的结果,对于每组数据库(参见第 2.1 节)和每个 Aurora 集群配置(参见第 2.2 节),我使用第 2.3 节中定义的虚拟用户数量在不同的工作负载级别下进行了一系列性能测试。我重复了每项测试 3 次,并得出了相同工作量水平下的平均结果。
对于每个 Aurora 集群配置和每个数据库大小,我将 Babelfish 性能定义为相应配置达到的最大性能。例如,图 1 显示了 Babelfish 在配置有 d b.r5.12xlarge 实例的 Aurora 集群上进行性能测试的结果。此图表上的每个点都是 3 次测试运行的平均值。
在这种情况下,Babelfish 在三个数据库分别为 724 个 虚拟用户的负载级别上都达到了最佳性能,因此我接受每种数据库大小的 724 个 虚拟用户的 NOPM 值作为该集群对相应数据库的 Babelfish 性能。在为集群使用更强大的实例时,Babelfish 在对应于 1,024 个 虚拟用户的负载级别上达到了最高性能。
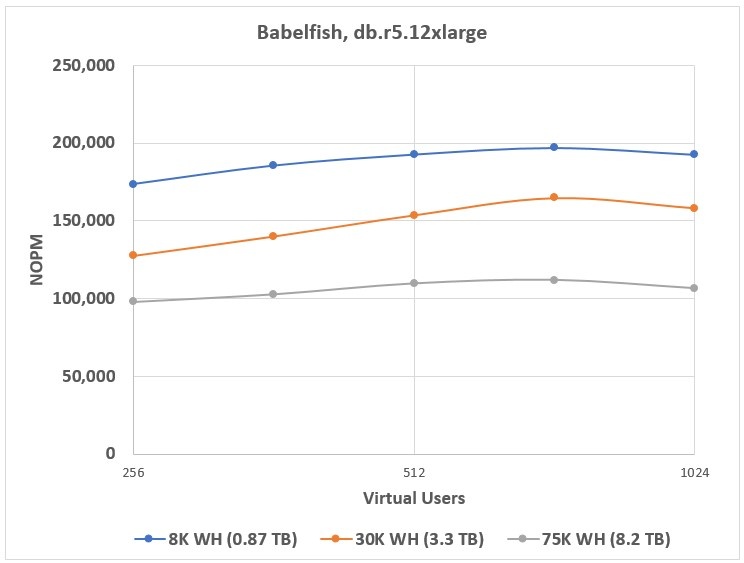 图 1。
基于 db.r5.12xlarge 的 Babelfish 集群基准测试结果。
图 1。
基于 db.r5.12xlarge 的 Babelfish 集群基准测试结果。
3。分析性能结果
表 2 列出了我选择对三个数据库进行测试的所有 Babelfish Aurora 集群的基准测试结果。我还使用
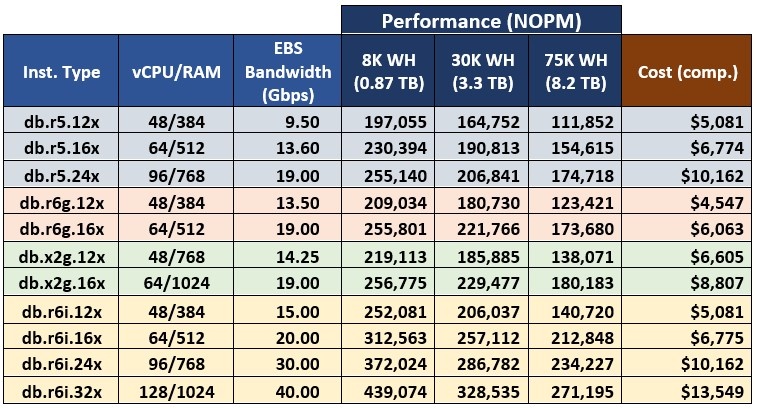 表 2.Babelfish 基准测试结果。
表 2.Babelfish 基准测试结果。
3.1。 比较 db.r5 和 db.r6i 实例类 的 结果
让我们首先重点比较 db.r5 和 db.r6i 类 的结果。 这两个类中的所有实例都经过内存优化且基于 Intel。 它们提供相同的实例大小,只是 db.r6i 类提供了 db.r6 i. 32xlarge 实例,而 db.r5 类 中没有可 比实例。 为了便于比较,表 3 显示了这两个类别的可比实例的 Babelfish 基准测试结果。
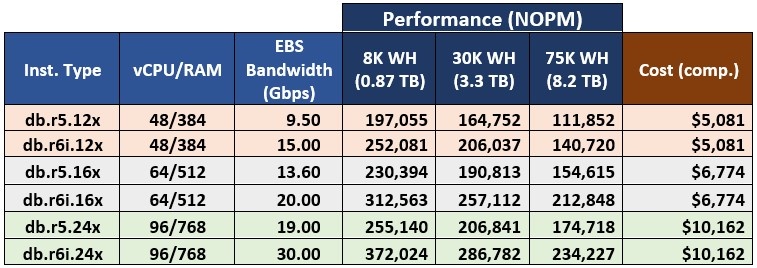 表 3.
可比
db.r5 和 db.r
6i 实例的基准测试结果。
表 3.
可比
db.r5 和 db.r
6i 实例的基准测试结果。
如表 3 所示,可比的 db.r5 和 db.r 6i 实例为 Aurora 集群提供相同的成本,但提供的性能点却大不相同,在所有实例和数据库大小上,db.r6i 都超过了 db.r 5。 我总结了 db.r6i 实例与各种数据库的同类 db.r5 实例相比的性能增益,并在图 2 中给出了这些结果。
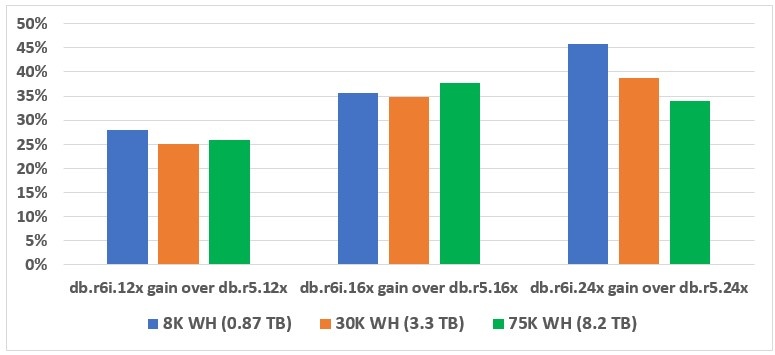 图 2。 在不同的数据库大小下,
db.r6i
实例的性能比同类的
db.r
5 实例有所提高。
图 2。 在不同的数据库大小下,
db.r6i
实例的性能比同类的
db.r
5 实例有所提高。
如图 2 所示,根据数据库的实例大小和大小,
db.r6i
实例提供的性能提升介于 25% 到 45% 之间 。
为了解释这种性能差异,我采集了在 db.r
5.24xlarge 和 db.r6i.24xlarge 上运行的测试的
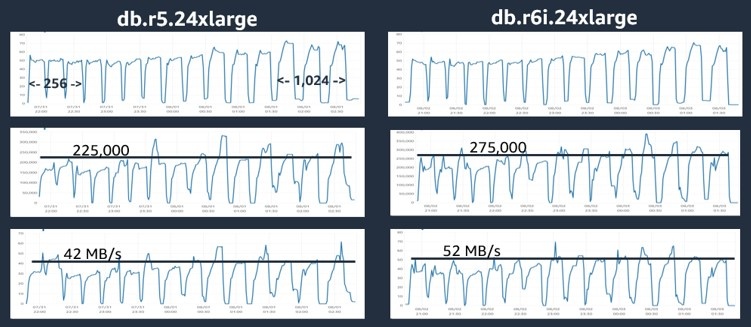 图 3。亚马逊 CloudWatch 指标快照。
图 3。亚马逊 CloudWatch 指标快照。
图 3 中的第一张图表表示 CPU 利用率。图表上的每个 “峰值” 对应一系列 3 次运行中的一次测试,从左边的 256 个虚拟用户发展到右边的 1,024 个虚拟用户。对于每个实例系列,CPU 利用率从50%左右开始,随着负载的增加达到70%左右。
但是,我们对
回顾表 3,可比的
db.r6i
实例提供的
考虑到基于相同大小的 db.r5 和 db.r 6i 实例的 Aurora PostgreSQL 集群的成本相同,以及 db.r 6i 系列的性能优势,考虑将 db.r 5 用于新的 Babelfish 部署毫无意义。 对于现有的 Babelfish 部署,将集群升级到 db.r6i 系列并通过在不牺牲性能的情况下缩小到较小的实例大小来节省成本是有意义的。因此,我将把 db.r5 实例类排除在进一步考虑之外。
3.2。分析各种实例类别的价格/性能
不包括 db.r5 实例,我们只有 8 个实例。表 4 显示了按性能级别分组(低端、中端和高端)的实例的测试结果。对于每个性能组,我还提供了每 1,000 NOPM 的计算成本,这为比较不同实例类型提供了良好的基础。
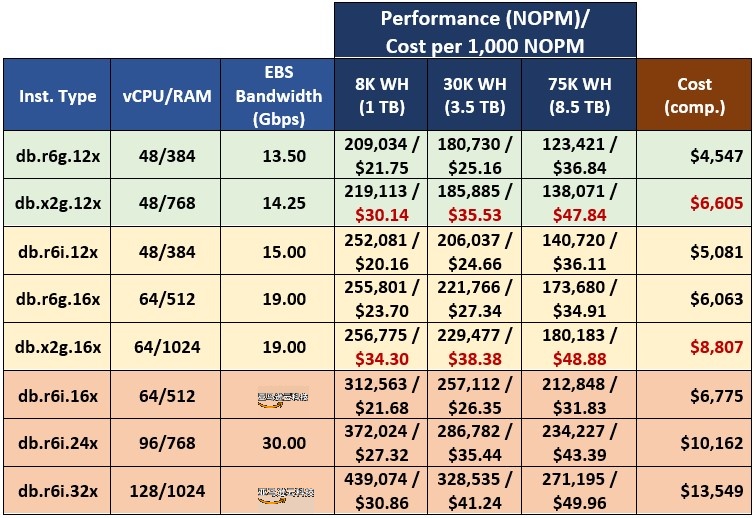 表 4.每 1,000 NOPM 的性能和成本。
表 4.每 1,000 NOPM 的性能和成本。
db.x2g 系列的实例无法提供有竞争力的性能。内存的扩展导致该系列中实例的价格上涨,这意味着 Babelfish 性能略高,而产生的额外成本是不合理的。
表 5 总结了本次基准测试中 Babelfish OLTP 工作负载的最佳选项,即选定的数据库大小和虚拟用户范围。我按照 Aurora 集群的价格区间对表中的实例进行了分组。
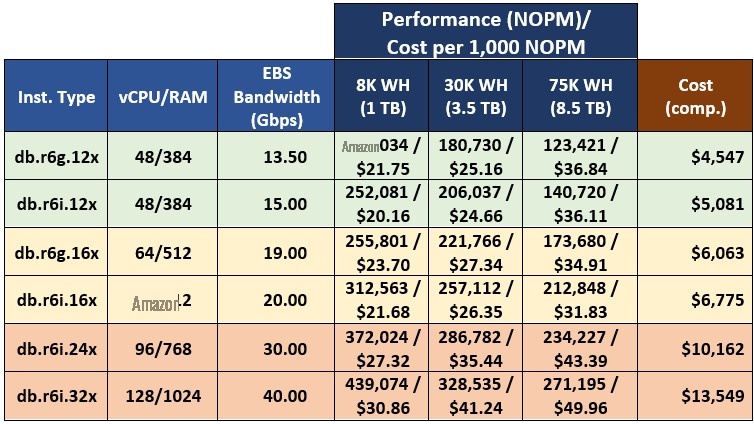 表 5.Babelfish OLTP 工作负载的推荐实例系列。
表 5.Babelfish OLTP 工作负载的推荐实例系列。
在较低的价格区间中, db.r6g.12xlarge 实例尽管性能较低,但总体成本较低,因此在所有测试的数据库大小 中,每 1,000 NOPM 的成本相当,但略高。 中间括 号中的 db.r6g.16xlarge 和 db.r6i.16xl arge 实例之间也有类似的关系 。 排在第一位, db.r6i 高端实例性能最高,但价格更高。
3.3。性能是数据库大小的函数
另一个有趣的观点是分析 Babelfish 性能如何取决于各种集群配置的数据库大小。我在图 4 的图表上绘制了相关数据。低端实例,如 db.r6g.12xlarge 和 db.r6i.12xl arge,随着数据库大小的增加 ,性能呈 均匀线性下降。
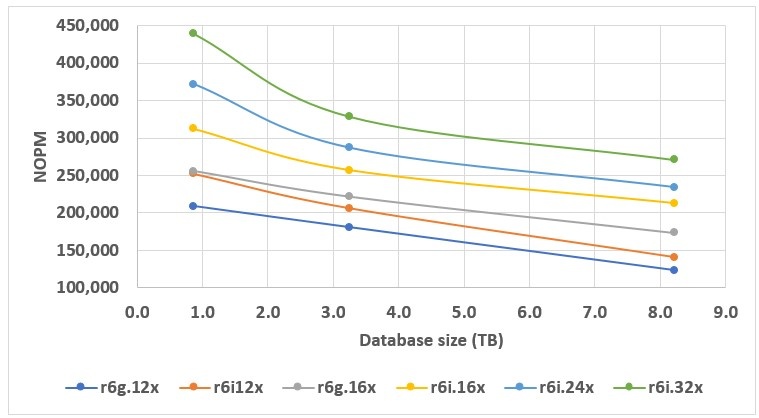 图 4。性能与数据库大小。
图 4。性能与数据库大小。
我们用于 Babelfish 集群的实例越大,它对数据库大小的初始变化就越敏感,但随后随着数据库规模的进一步增长,性能的下降就会停止。
对于较小的实例,即使是最小的数据库也会大大超过可用 RAM 的数量。因此,从一开始,相应的 Babelfish 性能就由底层实例的 EBS 吞吐量定义。
对于较大的实例,有很大一部分(如果不是整个 0.87 TB 的数据库)可以存入 RAM。因此,从大小低于 1 TB 的数据库过渡到 3.3 TB 意味着从主要适合 RAM 的数据库过渡到大大超过可用 RAM 量的数据库。这就是开始时大幅下降的原因,后来由于Babelfish的性能越来越依赖于实例的EBS吞吐量,下降幅度逐渐趋于平稳。
4 结论
如果你的 SQL Server 数据库与 Babelfish 兼容,或者你可以让它兼容一些更改,那么 Babelfish 是简化 SQL Server 工作负载向亚马逊 Aurora 平台迁移的可靠工具。考虑将
考虑使用基于 Graviton2 的实例部署 Babelfish 集群,因为它们比基于英特尔的同类实例便宜,尽管性能水平略低。为 Babelfish 集群选择特定实例类型时,请检查您的数据库大小和所需的性能级别。
认识到需要对数据库运行负载测试以确定适用于您的工作负载的最佳 Aurora 集群配置。
亚马逊云科技 可以帮助您评估贵公司如何充分利用云计算。加入数百万信任我们在云端迁移和现代化他们最重要的应用程序的 亚马逊云科技 客户的行列。要了解有关对 Windows 服务器或 SQL Server 进行现代化的更多信息,请访问
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。