我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
亚马逊云科技 Glue 爬虫支持跨账户爬网以支持数据网格架构
数据湖已经走了很长一段路,在这个领域也有了巨大的创新。当今的现代数据湖是云原生的,可处理多种数据类型,并使业务中的不同利益相关者可以轻松访问这些数据。随着时间的推移,数据湖已显著发展,并已演变为数据网格作为一种扩展方式。
数据网倡导去中心化所有权和交付企业数据管理系统,使多个角色受益。数据生产者可以使用数据网格平台创建数据集并在业务团队之间共享这些数据集,以确保各职能和数据主体领域的数据可用性、可靠性和互操作性。现在,数据消费者可以在不影响数据安全性的前提下,通过数据网格和跨业务部门联合实现更好的数据共享。数据治理团队可以支持分布式数据,在分布式数据中,具有适当访问权限的人员可以访问所有数据。使用数据网格,数据不必合并到单个数据湖或账户中,可以保留在不同的数据库和数据湖中。这种数据湖架构所需的一项基本能力是能够持续了解其他各个领域中数据湖的变化并将其提供给数据使用者。如果没有这种能力,就需要手动工作来了解制作者的更新并将其提供给消费者和监管机构。
亚马逊云科技 客户使用
在
在这篇文章中,我们将介绍如何创建简化的数据网格架构,该架构展示了如何使用带有 Lake Formation 的 亚马逊云科技 Glue 爬网程序,在保持集中化治理的同时,自动将变更从数据生产者域转移到数据使用者。
解决方案概述
在数据网格架构中,您有几个拥有 S3 存储桶的生产者账户、几个想要访问共享数据集的消费者账户,以及一个用于管理生产者和消费者之间数据共享的中央治理账户。该中央管理账户不拥有任何 S3 存储桶或实际表。
下图显示了一个简化的数据网格架构,其中包含单个生产者账户、一个集中管理账户和一个消费者账户。数据网格创建者账户托管加密的 S3 存储桶,该存储桶与中央治理账户共享。中央监管账户使用具有 S3 存储桶和 亚马逊云科技
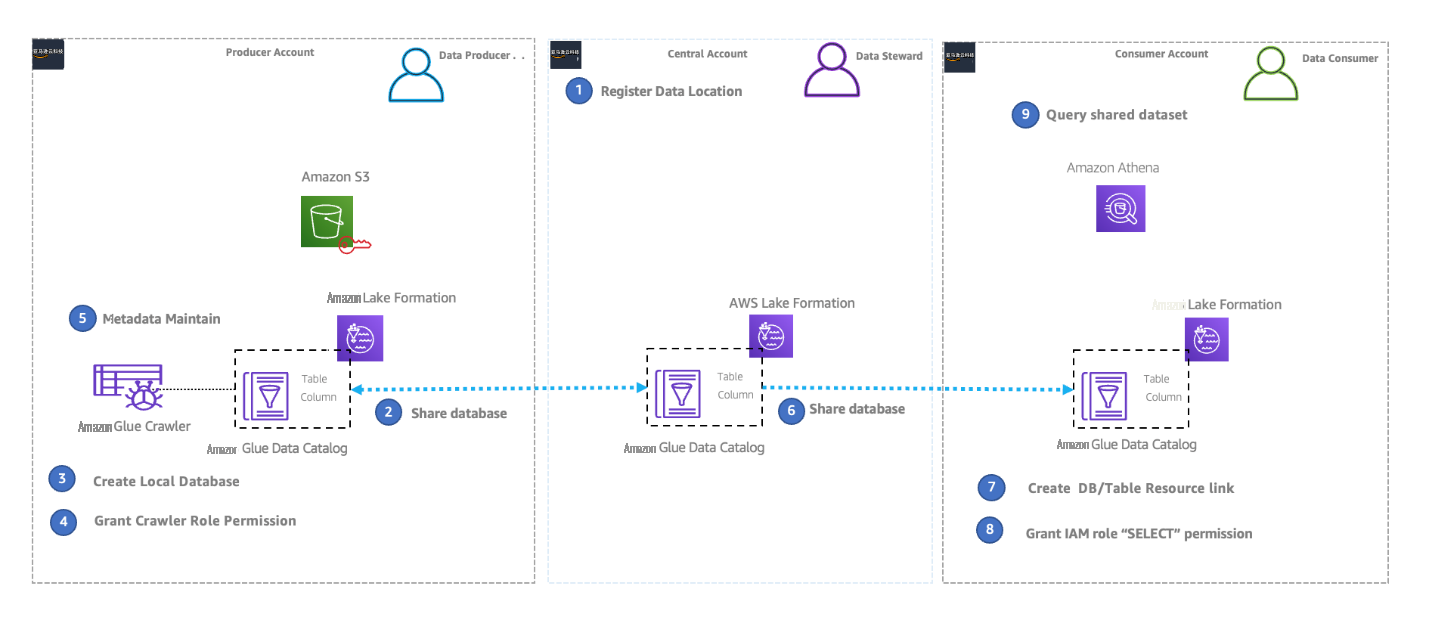
在以下部分中,我们提供了
先决条件
在每个账户(生产者、中央管理和使用者)中完成以下步骤,更新数据目录设置,以使用 Lake Formation 权限来控制目录资源,而不是基于 IAM 的访问控制:
- 以管理员身份登录 Lake Formation 控制台。
-
如果这是第一次访问 Lake Formation 控制台,请将自己添加为数据湖管理员。
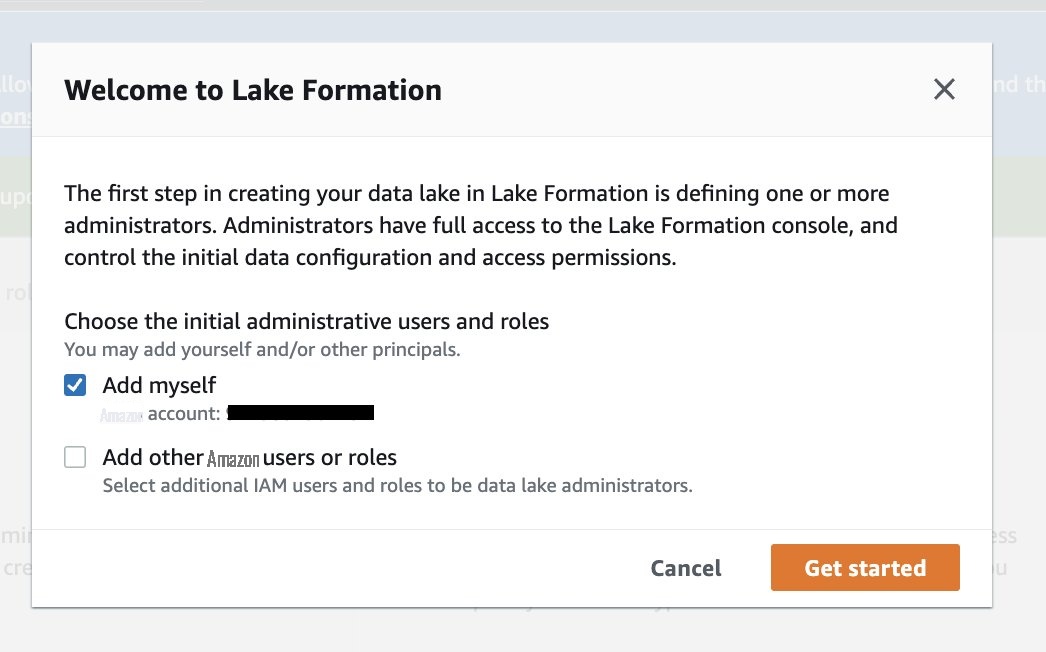
- 在导航窗格中的 “ 数据目录 ” 下 ,选择 “ 设置” 。
- 取消选中 仅对新数据库 使用 IAM 访问控制 。
- 取消选中 “ 仅对新数据库 中的新表 使用 IAM 访问控制 ”。
- 将 版本 3 保留 为当前的跨账户版本。
- 选择 “ 保存” 。
在中央治理账户中设置资源
中央账户的 CloudFormation 模板创建了一个分配为 Lake Formation 管理员的 C
entralDatameShowner 用户
。
中央治理账户中的 CentralDatameShowner
用户执行必要的步骤,与生产者和消费者账户共享中央目录。
CentralDatameShowner
用户还设置了自定义 Lake Formation 服务角色来注册 S3 数据湖位置。完成以下步骤:
- 以 IAM 管理员身份登录中央监管账户控制台。
-
选择
Launch Stack
来部署 CloudFormation 模板:

-
对于 DatameshownerUserName ,请保留默认值(CentralDatameShowner )。 - 对于 ProducerawsAccount ,输入制作人账户 ID。
- 创建堆栈。
- 堆栈启动后,在 亚马逊云科技 CloudFormation 控制台上,导航至堆栈的 资源 选项卡。
-
记下 registerLocationS
erviceRole的值。 -
选择 lfuserSpassWord值导航到 亚马逊云科技 Secrets Manager 控制台 。 - 在 “ 机密值 ” 部分中,选择 “ 检索机密值 ” 。
-
记下 IAM 用户 C
entralDatameShowner 密码的密钥值。
在生产者账户中设置资源
生产者账户的 CloudFormation 模板创建了以下资源:
-
IAM 用户
LobProducersSte -
S3 存储桶 零售数据湖-- - 用于存储桶加密的 KMS 密钥
- 提供对中央监管账户的访问权限所需的 S3 存储桶策略
- 具有必要权限的 亚马逊云科技 Glue 爬虫和爬虫 IAM 角色
完成以下步骤:
- 以 IAM 管理员身份登录生产者账户控制台。
-
选择
Launch Stack
来部署 CloudFormation 模板:
- 对于 CentralAccountID ,输入中央账户 ID。
-
对于 CentralAccountlformation,输入前面提到的 CloudFormation 的 registerL ocationServiceRole 的值。 - 创建堆栈。
- 堆栈完成后,在 亚马逊云科技 CloudFormation 控制台上,导航至堆栈的 资源 选项卡。
-
记下
awsGlueServiceRole 的值。 -
选择
producerStewarduserCredenti als值以导航到密钥管理器控制台。 - 在 “ 机密值 ” 部分中,选择 “ 检索机密值 ” 。
-
记下 IAM 用户 l
obProducersSteward 密码的密钥值。 -
在 Amazon S3 控制台上,检查
零售数据湖的存储桶策略,并确保将其与中央监管账户 IAM 角色共享。
这是在中央账户中向Lake Formation注册存储桶所必需的,以便该账户可以管理数据共享。
- 在 亚马逊云科技 KMS 控制台上,检查存储桶是否使用客户管理的密钥进行了加密,以及密钥是否与中央监管账户共享。
在消费者账户中设置资源
消费者账户的 CloudFormation 模板创建了以下资源:
-
分配给数据湖管理员的 IAM
用户 consumeradminUser -
IAM 用户
lfBusinessAnalyst1 - 用于存放雅典娜输出的 S3 存储桶
- 雅典娜工作组
完成以下步骤:
- 以 IAM 管理员身份登录消费者账户控制台。
-
选择
Launch Stack
来部署 CloudFormation 模板:
- 创建堆栈。
- 堆栈完成后,在 亚马逊云科技 CloudFormation 控制台上,导航至堆栈的 资源 选项卡。
-
选择
AllConsumerUserScredentials值以导航到密钥管理器控制台。 - 在 “ 机密值 ” 部分中,选择 “ 检索机密值 ” 。
-
记下 IAM 用户 cons
umeradminUser 密码的密钥值。
现在,所有账户都已设置完毕,我们在 亚马逊云科技 上使用中央管理账户设置了跨账户共享,以管理生产者和消费者之间的权限共享。
配置中央管理账户以管理与生产者账户的共享
使用前面通过中央治理账户 CloudFor
mation 堆栈注明的密码以 CentralDatameShowner
身份登录中央治理账户。然后完成以下步骤:
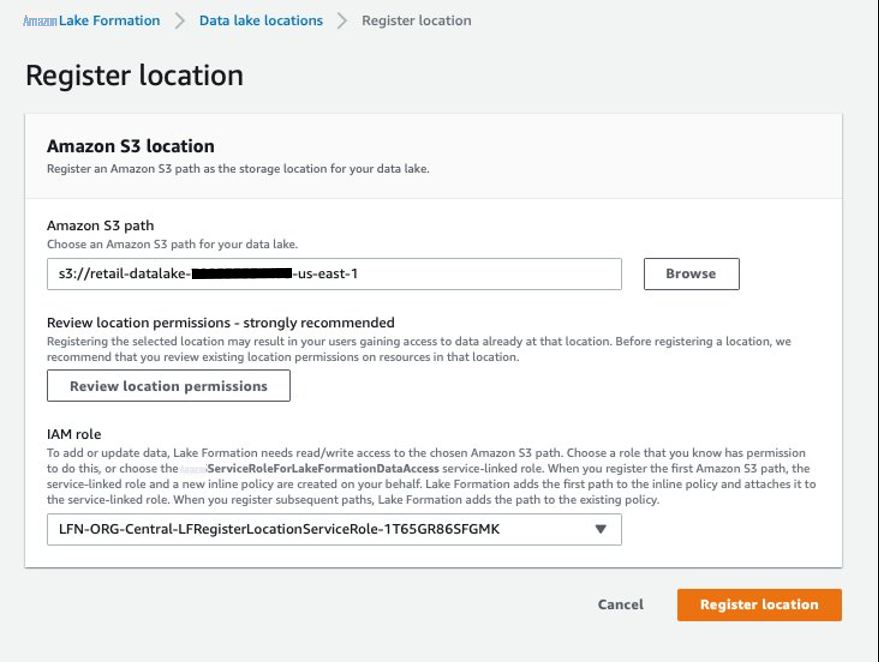
- 在 Lake Formation 控制台上,在导航窗格 中选择 “ 注册并提取 ” 下的 “ 数据湖位置 ”。
-
对于 Amazon S3 路径 ,请提供路径 零售数据湖--。 - 对于 IAM 角色 ,请选择使用 CloudFormation 堆栈创建的 IAM 角色。
此角色有权访问加密的 S3 存储桶及其密钥。请勿选择 亚马逊云科技ServiceRoleformation
DataAccess
角色。
-
选择 “
注册地点
” 。
- 在导航窗格中,选择 数据库 。
- 选择 “ 创建数据库 ” 。
-
对于
数据库名称
,输入
datam eshtestdatabase。 - 选择 “ 创建数据库 ” 。
-
在导航窗格中,选择 “
数据位置
”, 然后选择 “
授予
” 。
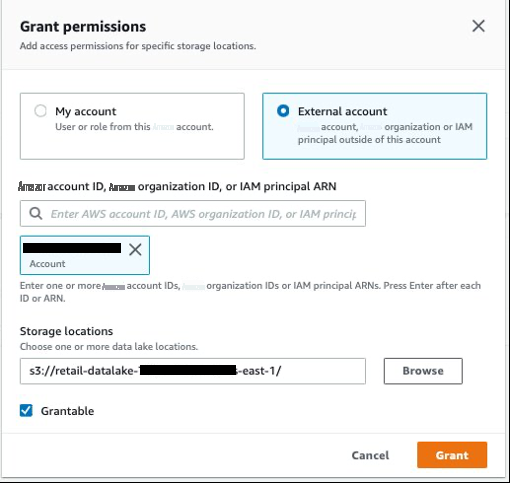
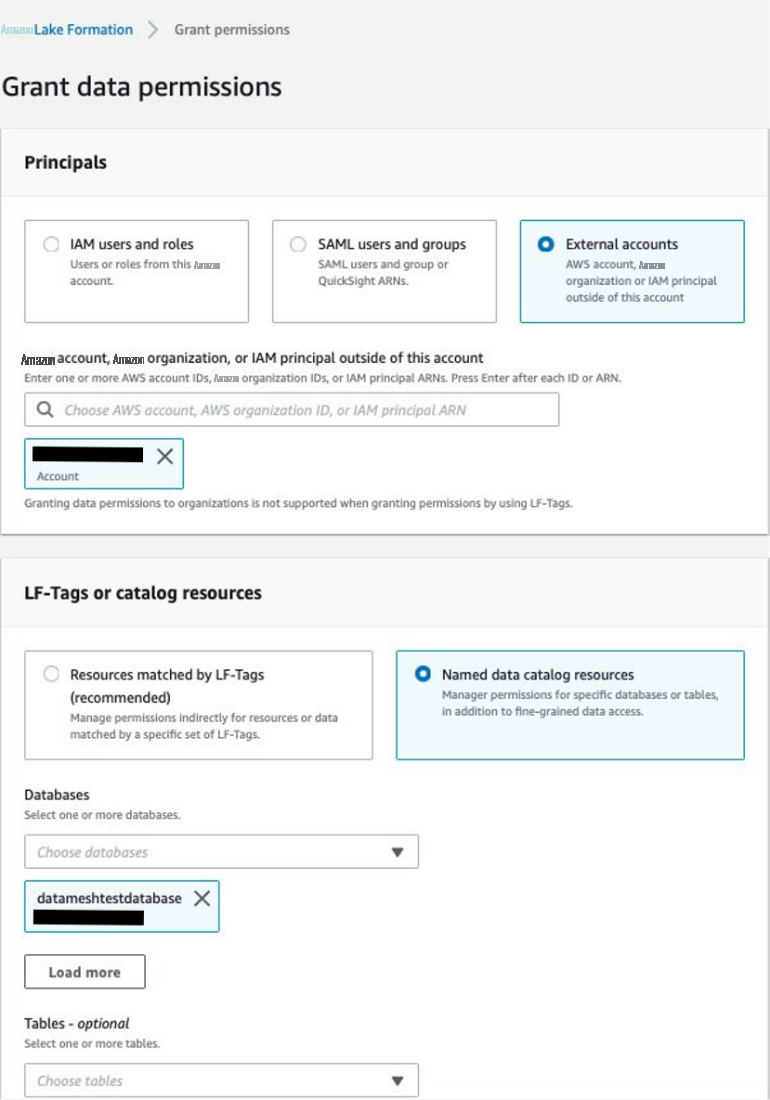
- 选择 外部账户 并提供 亚马逊云科技 账户 ID、亚马逊云科技 组织 ID 或 IAM 委托人 ARN 的生产者账户。
- 对于 存储位置 ,提供数据湖存储桶路径。
- 选择 “ 可授 予” ,然后选择 “ 授予 ”。
- 选择 数据湖权限 ,然后选择 授予 。
- 选择 外部账户 并提供生产者账号。
-
对于
数据库, 选择 datames
htestdatabase。 - 对于 “ 数据库权限 ” 和 “ 可授予权限 ” ,选择 “ 创建表 ” 、“ 更改 ” 和 “ 描述 ”。
-
选择 “
授予
” 。

在生产者账户中配置爬虫以填充架构
使用前面通过生产者账户 CloudFormation 堆栈注明的密码 以 L
obProducersSteward
身份登录生产者账户,然后完成以下步骤:
- 在 亚马逊云科技 RAM 控制台上,接受来自中央账户的待处理资源共享。
- 在 Lake Formation 控制台上,在导航窗格 中选择 “ 数据目录 ” 下的 “ 数据库 ”。
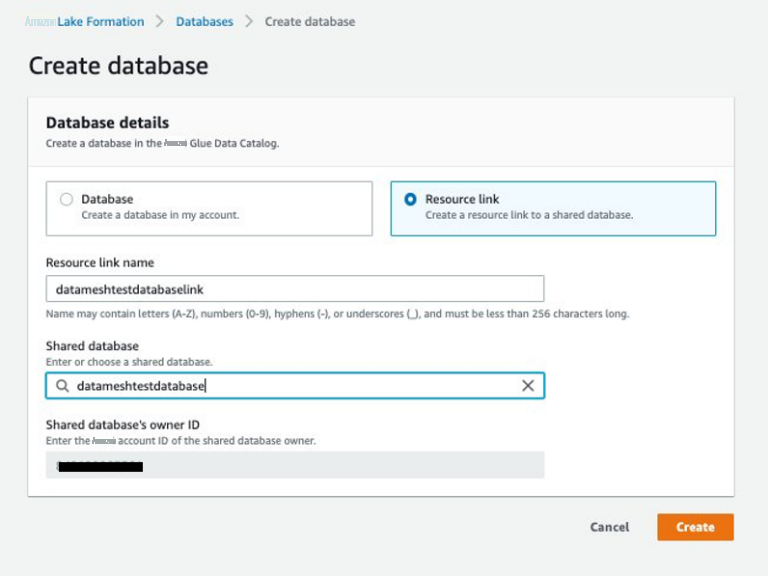
-
选择
datameshtestdatabase,然后在 “ 操作 ” 菜单上选择 “创建资源链接”。 -
在
资源链接名称
中 ,输入
datameshtestdatabaselink。 -
选择 “
创建
” 。
- 在 亚马逊云科技 Glue 控制台上, 在导航窗格中选择 爬虫 。
-
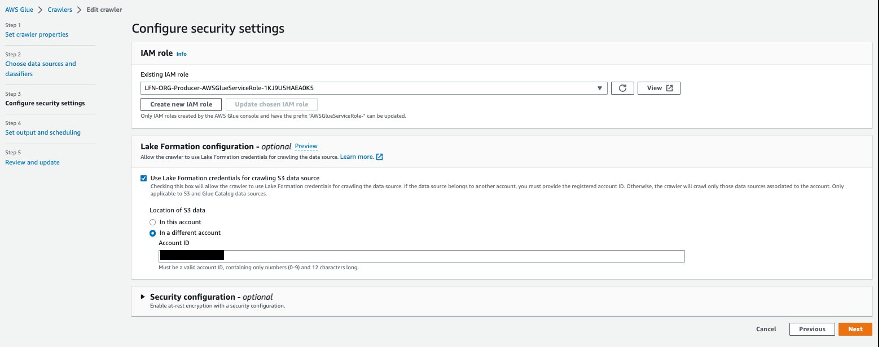
选择搜寻器 crossAccountCrawler-。 - 选择 “编辑” ,然后选择 “ 配置安全设置” 。
- 选择 使用 Lake Formation 凭据来搜索 S3 数据源 。
- 选择 在其他账户 中 并提供中央管理账户的账户 ID。
-
选择 “
下一步
” 。
-
选择
datameshtestdatabaselink 作为数据库,然后选择更新。
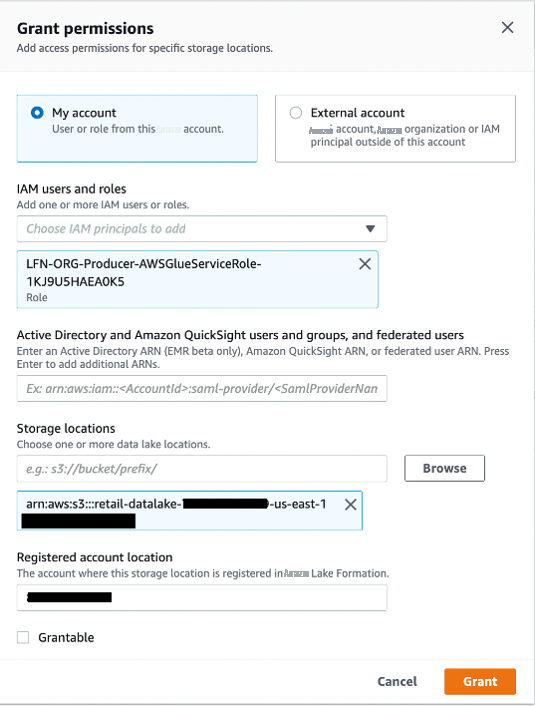
- 在导航窗格中,选择 “ 数据位置 ”, 然后选择 “ 授予 ” 。
- 选择 我的账户 ,然后为 IAM 用户和角色选择爬虫 IAM 角色 。
-
对于 存储位置 ,选择存储分区 零售数据湖--。 - 在 注册账户所在地 中 ,输入中央账户 ID。
-
选择 “
授予
” 。
 或者,您也可以使用 亚马逊云科技 CLI 使用以下命令向爬虫角色授予在中央账户中注册的存储桶上的数据定位权限:aws l
或者,您也可以使用 亚马逊云科技 CLI 使用以下命令向爬虫角色授予在中央账户中注册的存储桶上的数据定位权限:aws l
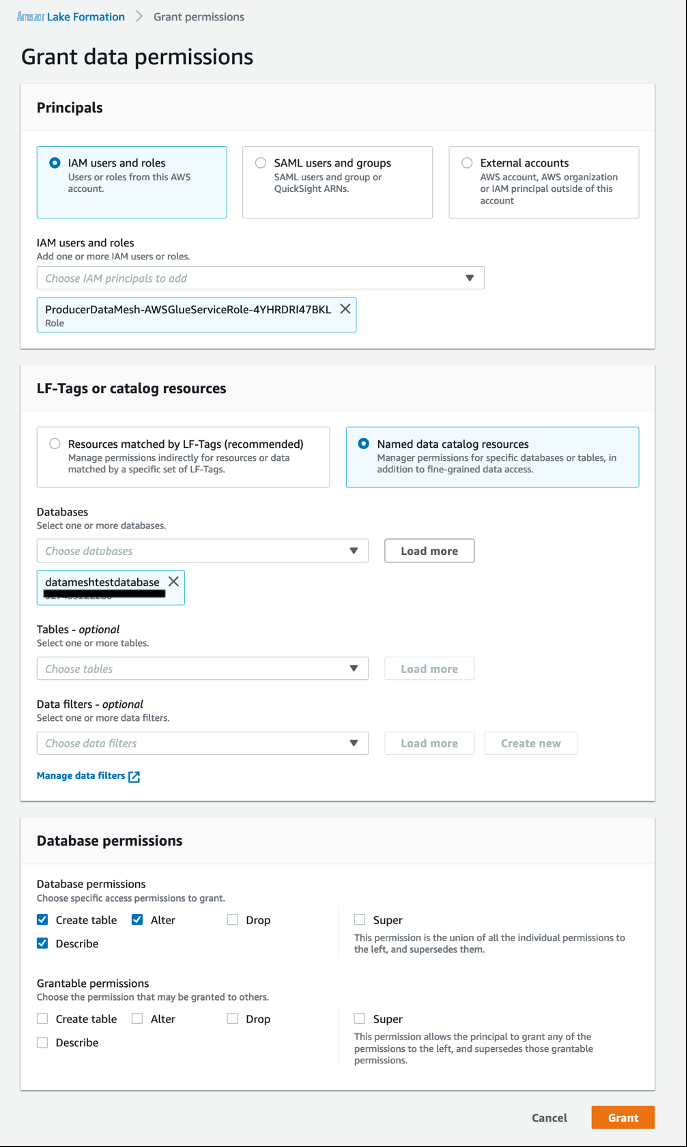
principal DataLakePrincipalIdentifier= ”-权限 “DATA_LOCATION_ACCESS”--resource '{“DataLocation”: { “ResourceArn”:”:”}' 要使用 CLI,请参阅安装或更新最新版本的 AW S CLI。 - 在导航窗格中,选择 数据湖权限 。
- 为主账户选择爬虫 IAM 角色。
-
为
数据库选择 datameshtestdatabase。 - 对于 数据库权限 ,选择 创建 、 描述 和 更改 。
-
选择 “
授予
” 。
- 为主账户选择爬虫 IAM 角色。
-
为数据库选择
datameshtestdatabaselink。 - 对于 资源链接权限 ,选择 描述 。
- 选择 “ 授予 ” 。
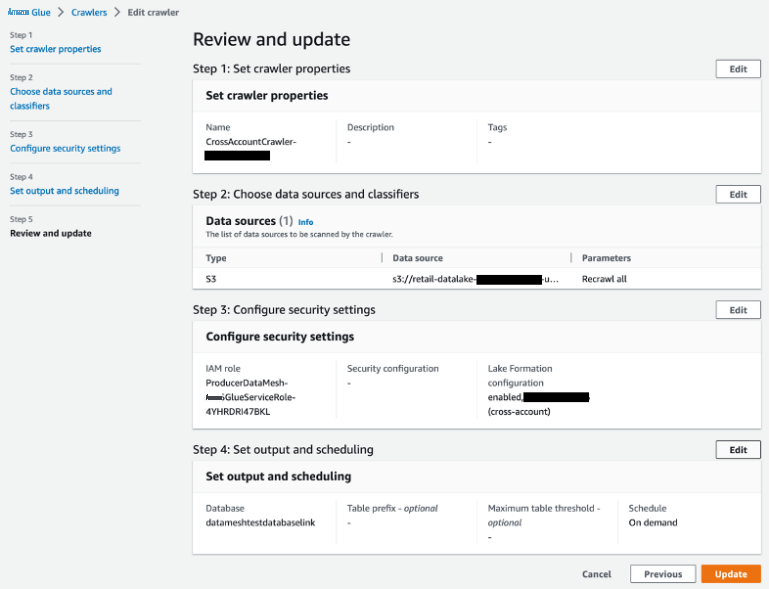
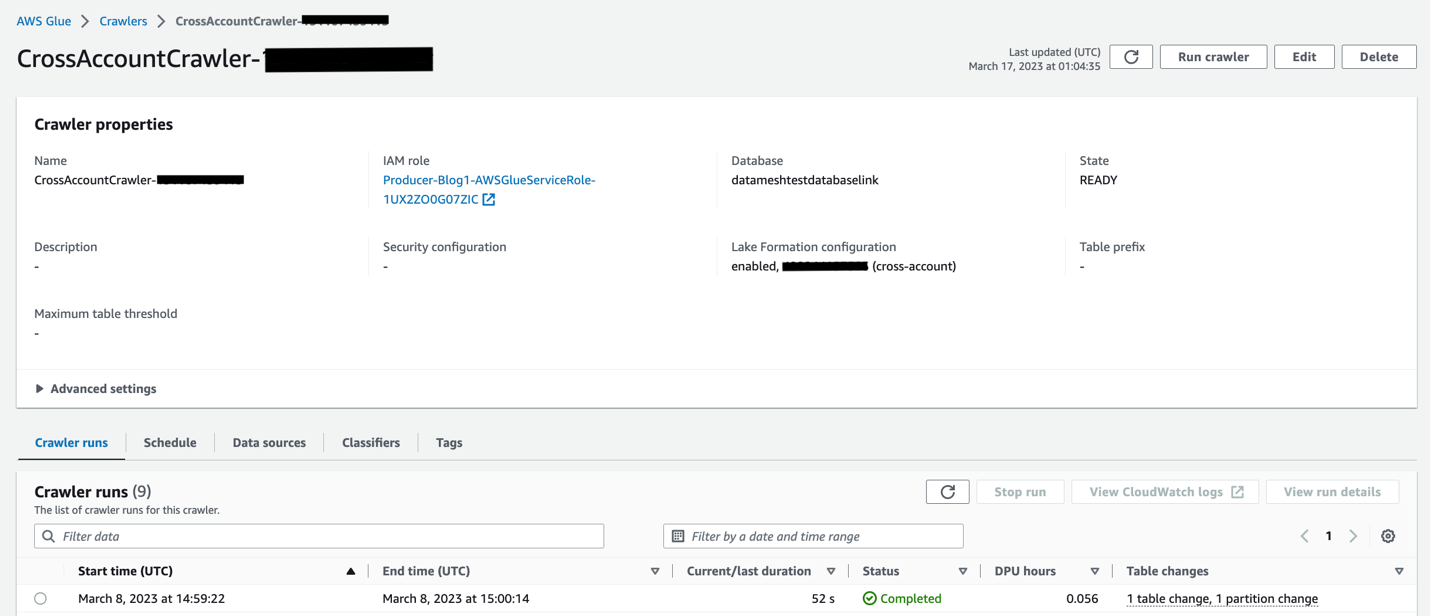
- 运行爬虫。
以下屏幕截图显示了成功运行后的详细信息。
搜寻器完成后,你可以验证在数据库 datameshtest
dat
abaselink 下创建的表。
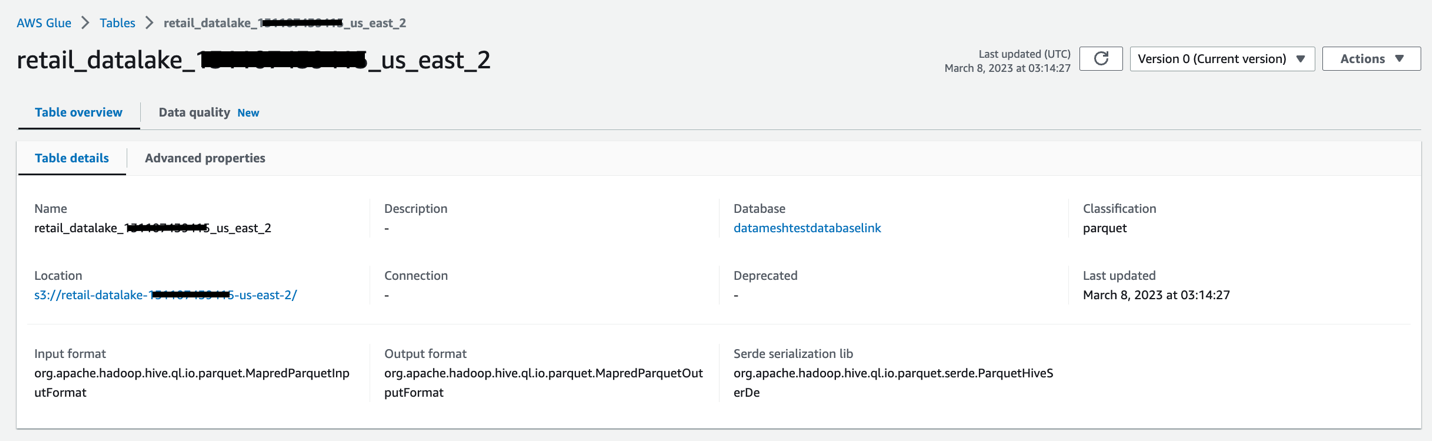
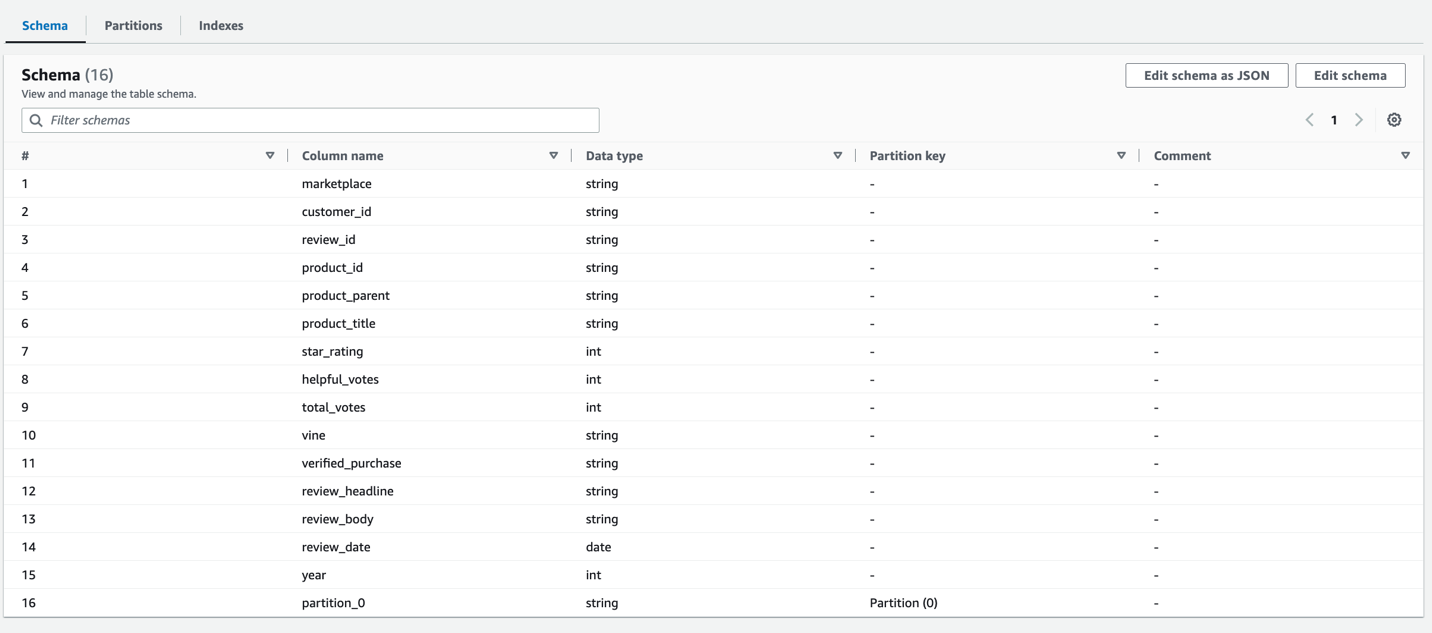
该表归生产者账户所有,可在共享数据库
datam
eshtestdabase 下的中央治理账户中找到。现在,中央治理账户中的数据湖管理员可以与消费者账户共享数据库和填充表。
配置中央管理账户以管理与消费者账户的只读访问权限共享
使用先前通过中央治理账户 CloudFor
mation 堆栈注明的密码 以 CentralDatameShowner
身份登录中央治理账户,然后完成以下步骤:
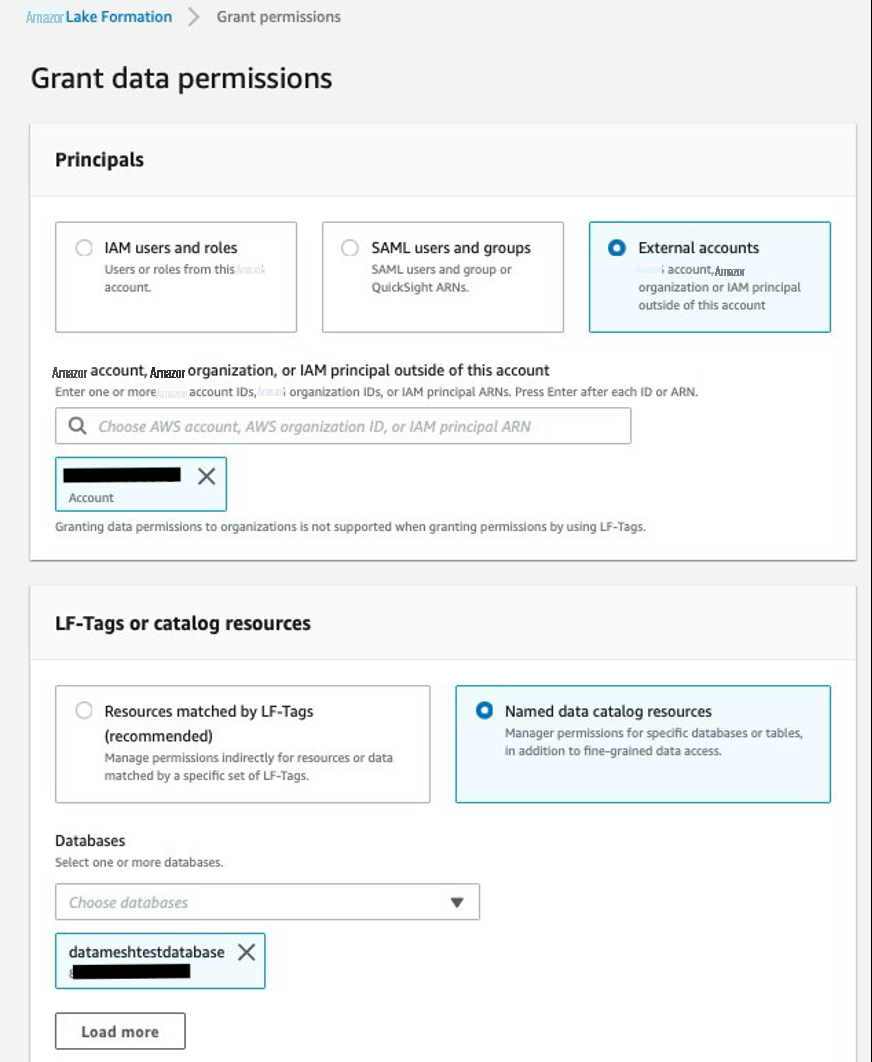
- 向消费者账号授予数据库权限。
-
对于
校长
,请选择外部账户并提供
-
对于 “
数据库
” ,选择
datameshtestdatabase。 - 对于 数据库权限 ,选择 描述 。
- 对于可授 予的权限 ,请选择 描述 。
-
选择 “
授予
” 。
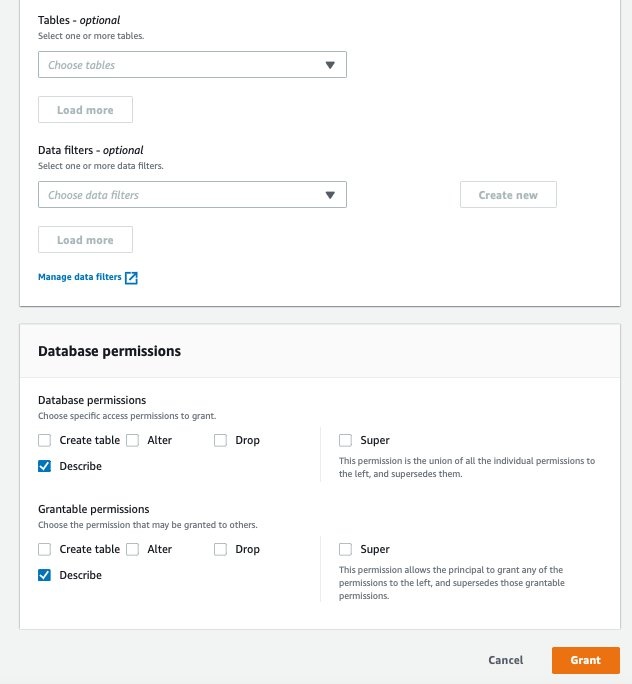
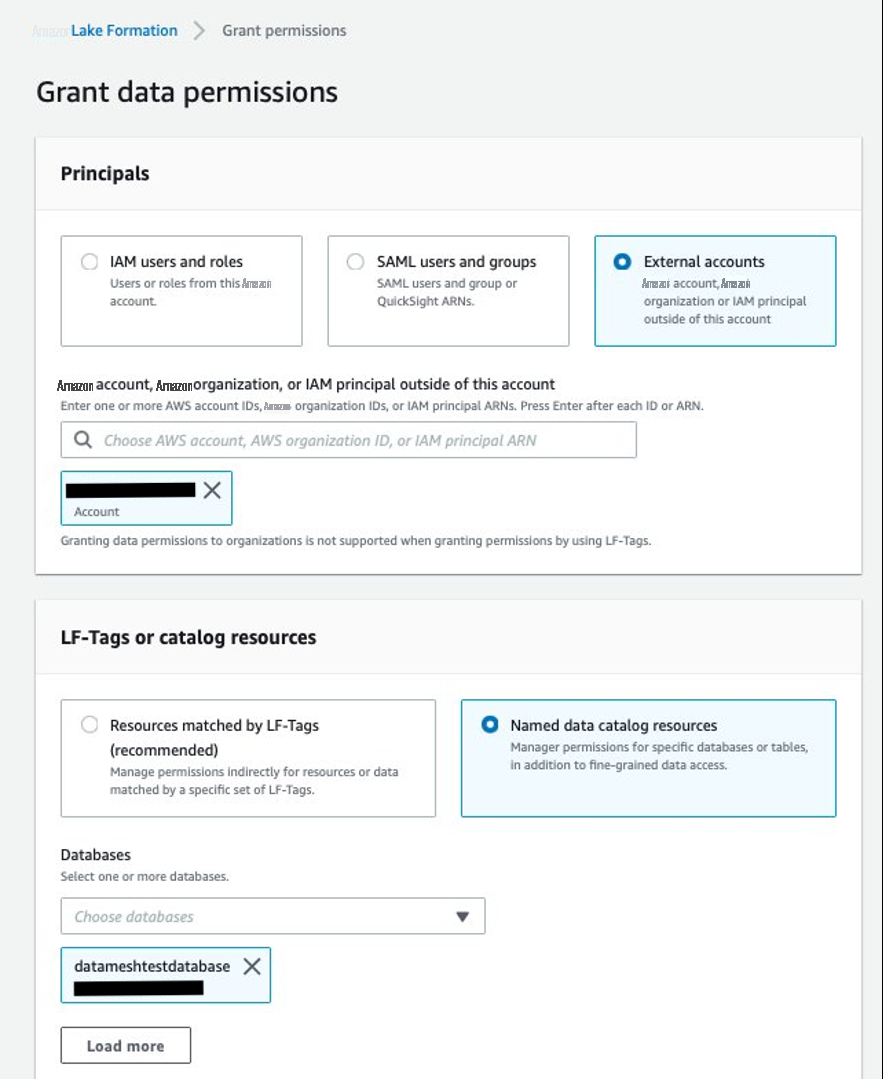
- 向消费者账户授予表格权限。
-
对于 校长 ,选择外部账户并提供 -
对于 “
数据库
” ,选择
datameshtestdatabase。 -
对于 表格 ,选择 零售_数据湖_。 - 对于 “ 表权限 ” ,选择 “选择 并 描述 ” 。
- 对于可授 予的权限 ,请选择 “ 选择 并 描述 ”。
-
选择 “
授予
” 。
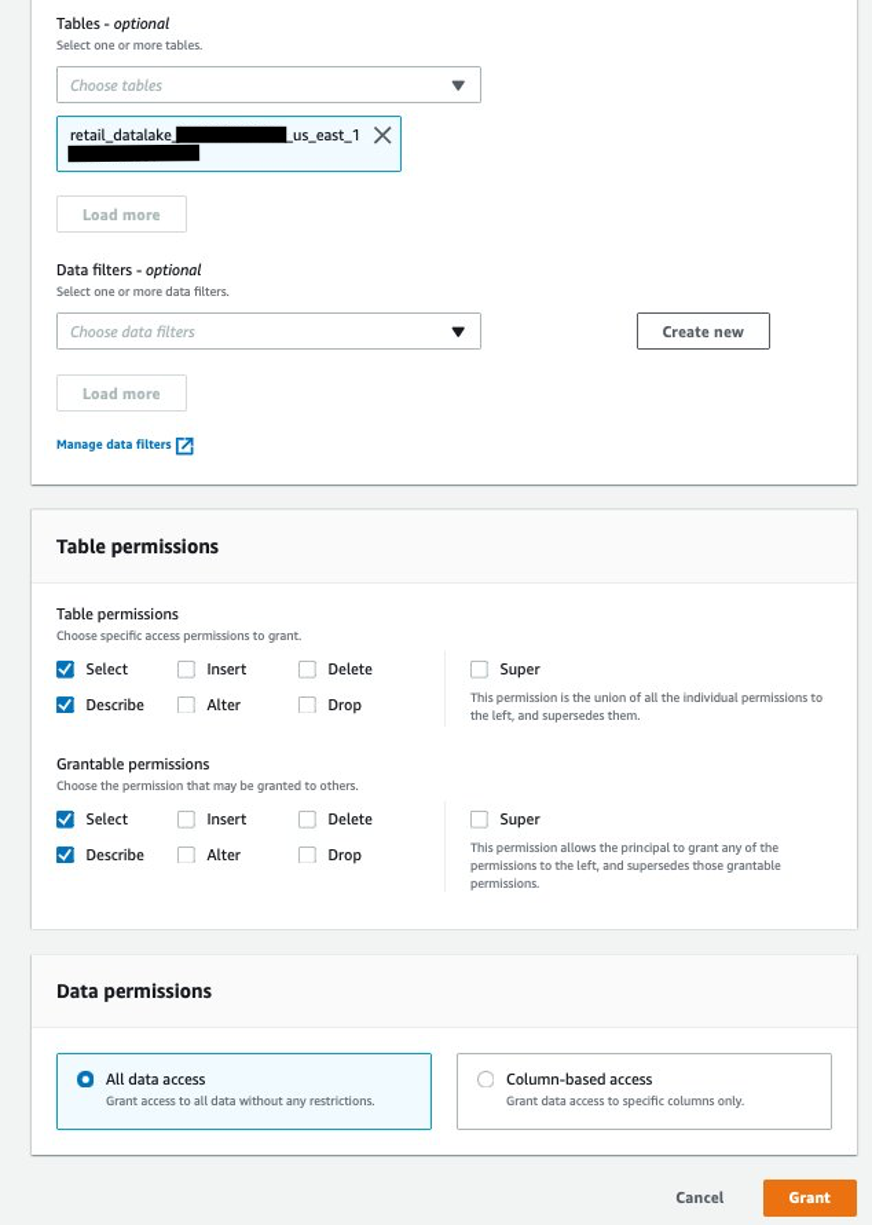
将消费者账户配置为消费者账户数据湖管理员
使用之前通过消费者账户 CloudFormation
堆栈注明的密码, 以 consumerAdminUser
身份登录消费者账户。(请注意,在消费者账户 Lake Formation 配置中,cons
umeradminUser 和 LfBusin
essAnaly
st1 的密码相同。)
- 在 亚马逊云科技 RAM 控制台上,接受来自中央账户的资源共享。
-
在 Lake Formation 控制台上,验证共享数据库
datameshtestdatabaselink 是否可用,然后使用共享数据库创建资源链接datameshtestdatabaselink。
以下屏幕截图显示了创建资源链接后的详细信息。

- 在 Lake Formation 控制台上,选择 Grant 。
- 为 IAM 用户和角色选择 LfBusinessAnalyst1。
-
在 “
命名
数据目录资源” 下 为数据库选择 datameshtestdatabase。 - 为 数据库权限 选择 描述 。
- 在 Lake Formation 控制台上,选择 Grant 。
-
为 IAM 用户和角色选择
LfBusinessAnalyst1。 -
在 “命名
数据目录资源” 下 为数据库选择 datameshtestdatabaselink。 - 为 资源链接权限 选择 描述 。
- 在 Lake Formation 控制台上,选择 Grant 。
-
为 IAM 用户和角色选择
LfBusinessAnalyst1。 -
为命名 数据目录资源下的 表选择 retail_datalake_ _。 - 为 表权限 选择 “选择 和 描述 ” 。
在消费者账户中运行查询
使用之前通过消费者账户 Cloud
Formation 堆栈注明的密码, 以 LfBusinessAnalyst1
身份登录消费者账户控制台,然后完成以下步骤:
-
在 Athena 控制台上,选择
lfconsumer-workgroup 作为 Athena 工作组。 - 运行以下查询来验证访问权限:
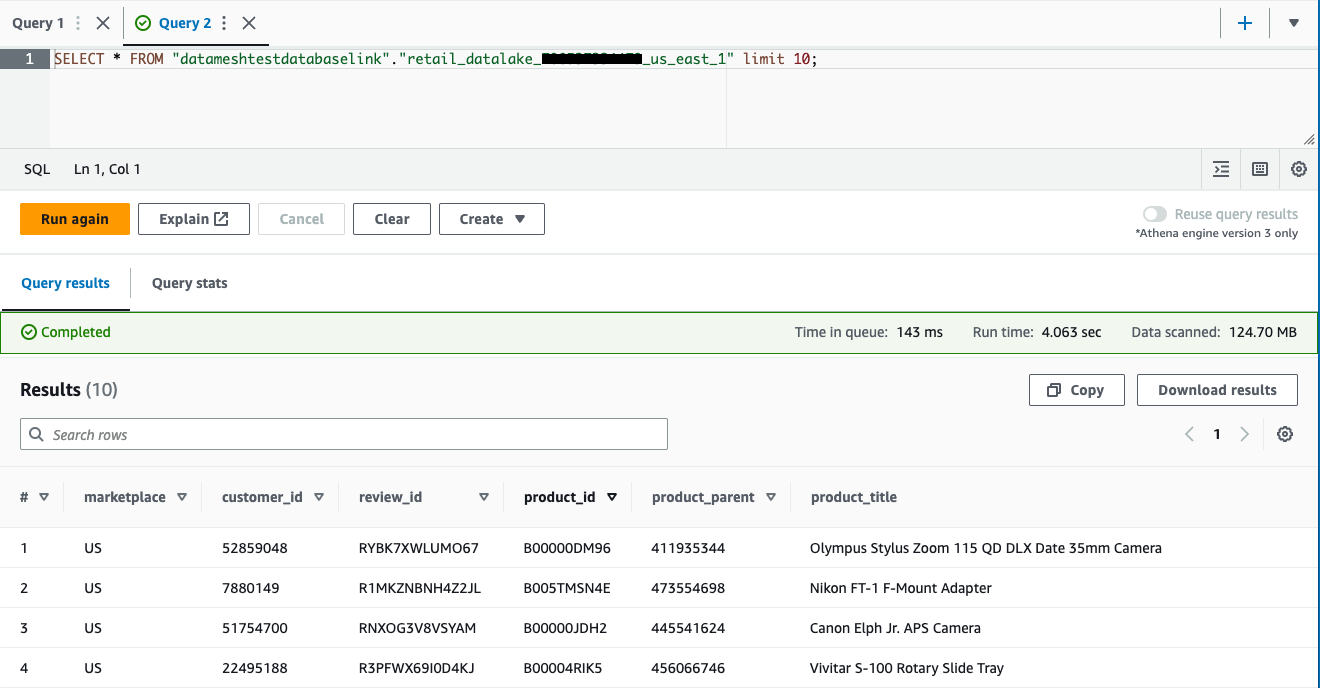
我们已成功注册数据集并在中央管理账户中创建了数据目录。我们使用生产者账户中的 Lake Formation 权限爬取了在中央治理账户注册的数据湖,并填充了架构。我们向消费者用户授予了中央账户对数据库和表格的Lake Formation权限,并使用雅典娜验证了消费者用户对数据的访问权限。
清理
为避免向您的 亚马逊云科技 账户收取不必要的费用,请删除 亚马逊云科技 资源:
- 以用于在所有三个账户中创建 CloudFormation 堆栈的 IAM 管理员身份登录到 CloudFormation 控制台。
- 删除您创建的堆栈。
结论
在这篇文章中,我们展示了如何使用具有全新 亚马逊云科技 Glue 爬虫功能 Lake Formation 集成功能的中央管理账户来设置跨账户爬网。此功能允许数据创建者在自己的域中设置爬网功能,以便数据治理和数据使用者可以无缝地获得更改。使用 亚马逊云科技 Glue 爬虫、Lake Formation、Athena 和其他分析服务实现数据网格为集成、准备和提供数据提供了一种广为人知、高性能、可扩展且经济实惠的解决方案。
如果您有任何问题或建议,请在评论部分提交。
有关更多资源,请参阅以下内容:
-
使用 亚马逊云科技 Lake Formation 和 亚马逊云科技 Glue 设计数据网格架构 -
介绍使用 亚马逊云科技 Lake Formation 权限管理的 亚马逊云科技 Glue 爬虫
作者简介
 桑迪普·阿德万卡
是 亚马逊云科技 的高级技术产品经理。他常驻加利福尼亚湾区,与全球客户合作,将业务和技术要求转化为产品,使客户能够改善管理、保护和访问数据的方式。
桑迪普·阿德万卡
是 亚马逊云科技 的高级技术产品经理。他常驻加利福尼亚湾区,与全球客户合作,将业务和技术要求转化为产品,使客户能够改善管理、保护和访问数据的方式。
 Srividya Parthasarathy
是 亚马逊云科技 Lake Formation 团队的高级大数据架构师。她喜欢构建数据网格解决方案并与社区共享。
Srividya Parthasarathy
是 亚马逊云科技 Lake Formation 团队的高级大数据架构师。她喜欢构建数据网格解决方案并与社区共享。
 Piyali Kamra
是一位经验丰富的企业架构师和亲身实践的技术专家,他认为构建大规模企业系统不是一门精确的科学,而更像是一门艺术,在这门艺术中,必须根据团队的文化、优势、劣势和风险精心选择工具和技术,同时要对未来几年如何塑造产品抱有未来的愿景。
Piyali Kamra
是一位经验丰富的企业架构师和亲身实践的技术专家,他认为构建大规模企业系统不是一门精确的科学,而更像是一门艺术,在这门艺术中,必须根据团队的文化、优势、劣势和风险精心选择工具和技术,同时要对未来几年如何塑造产品抱有未来的愿景。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。