我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 Renate 自动重新训练神经网络
今天我们宣布
通过开源 Renate,我们希望创建一个聚集在现实世界机器学习系统的从业者和有兴趣推动自动机器学习、持续学习和终身学习最新技术的研究人员聚集在一起的场所。我们相信,这两个社区之间的协同作用将在机器学习研究界产生新的想法,并对现实世界的应用产生切实的积极影响。
模型再训练和灾难性遗忘
逐步训练神经网络并不是一件容易的事。实际上,在不同时间点提供的数据通常是从不同的分布中抽样的。例如,在问答系统中,问题中主题的分布可能会随着时间的推移而发生显著变化。在分类系统中,在世界各地收集数据时,可能需要增加新的类别。在这种情况下,使用新数据对先前训练的模型进行微调将导致一种被称为 “灾难性遗忘” 的现象。最新的例子会有不错的表现,但是对过去收集的数据所做的预测的质量将大大降低。此外,当定期进行再训练操作时(例如,每天或每周),性能下降将更加严重。
如果可以存储一小块数据,则在再训练期间基于重复使用旧数据的方法可以部分缓解灾难性的遗忘问题。根据这个想法,已经开发了几种方法。其中一些仅存储原始数据,而更高级的还会保存额外的元数据(例如,内存中数据点的中间表示形式)。存储少量数据(例如,数千个数据点)并谨慎使用它们可以实现下图所示的卓越性能。
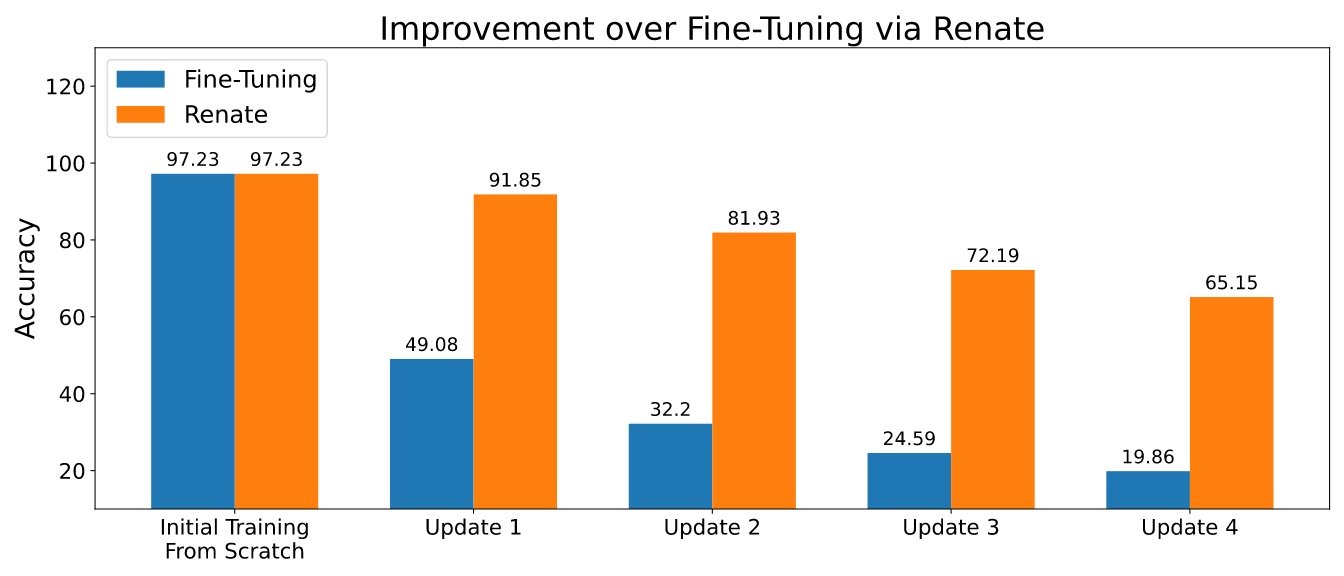
自带模型和数据集
训练神经网络模型时,可能需要更改网络结构、数据转换和其他重要细节。尽管代码更改是有限的,但当这些模型成为大型软件库的一部分时,它可能会成为一项复杂的任务。为了避免这些不便之处,Renate 让客户能够在预定义的 Python 函数中将其模型和数据集定义为配置文件的一部分。这样做的好处是可以将客户的代码与库的其余部分明确分开,并允许对Renate内部结构一无所知的客户有效地使用该库。
此外,包括模型定义在内的所有功能都非常灵活。
有关如何编写配置文件的教程可在
超参数优化的好处
与机器学习中经常出现的情况一样,持续学习算法带有许多超参数。它的设置可以对整体性能产生重要影响,仔细调整可以对预测性能产生积极影响。训练新模型时,Renate 可以使用 ASHA 等最先进算法启用超参数优化 (HPO),从而利用在亚马逊 SageMaker 上运行多个并行作业的功能。结果示例如下图所示。
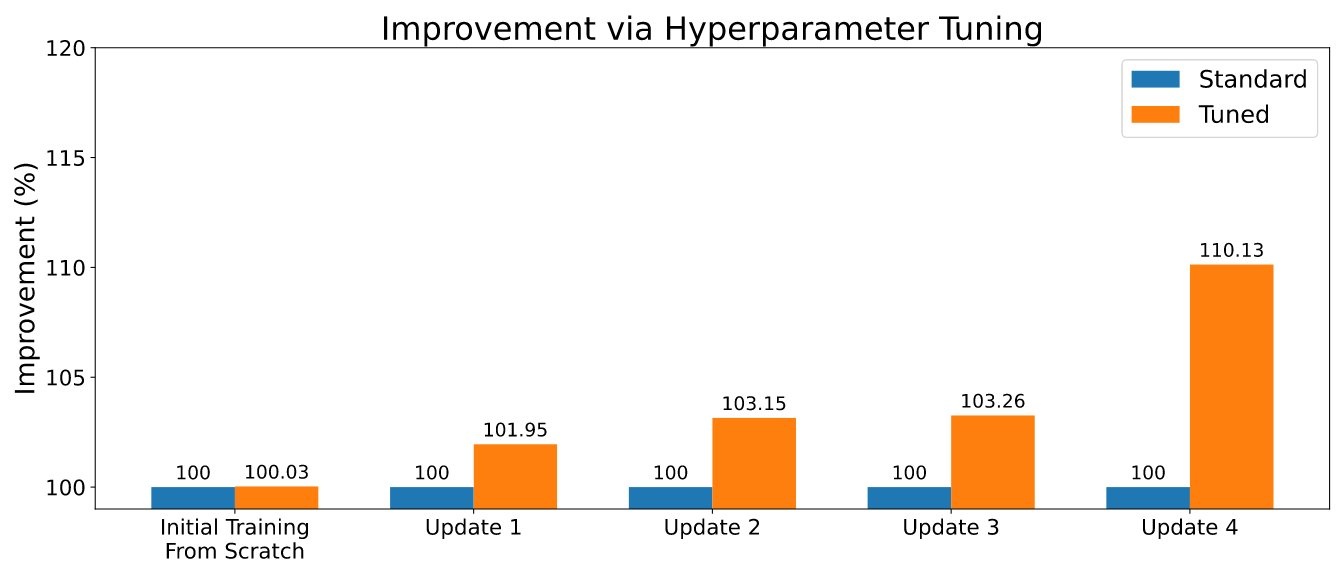
为了启用 HPO,用户需要定义搜索空间或使用库提供的默认搜索空间之一。请参阅 “
在云端运行
Renate 允许用户从用于实验的本地计算机上的训练模型快速过渡到使用 SageMaker 训练大规模神经网络。实际上,在本地计算机上运行训练作业相当不寻常,尤其是在训练大型模型时。同时,能够在本地验证细节和测试代码可能非常有用。为了满足这种需求,Renate 允许在本地计算机和 SageMaker 服务之间快速切换,只需更改配置文件中的一个简单标志即可。
例如,启动调优作业时,可以在本地运行
execute_tuning_job (..., backend='local') 并快速切换到 SageMaker,
按如下方式更改代码:
运行脚本后,可以从 SageMaker Web 界面看到正在运行的作业:

还可以在 CloudWatch 中监控训练作业和读取日志:
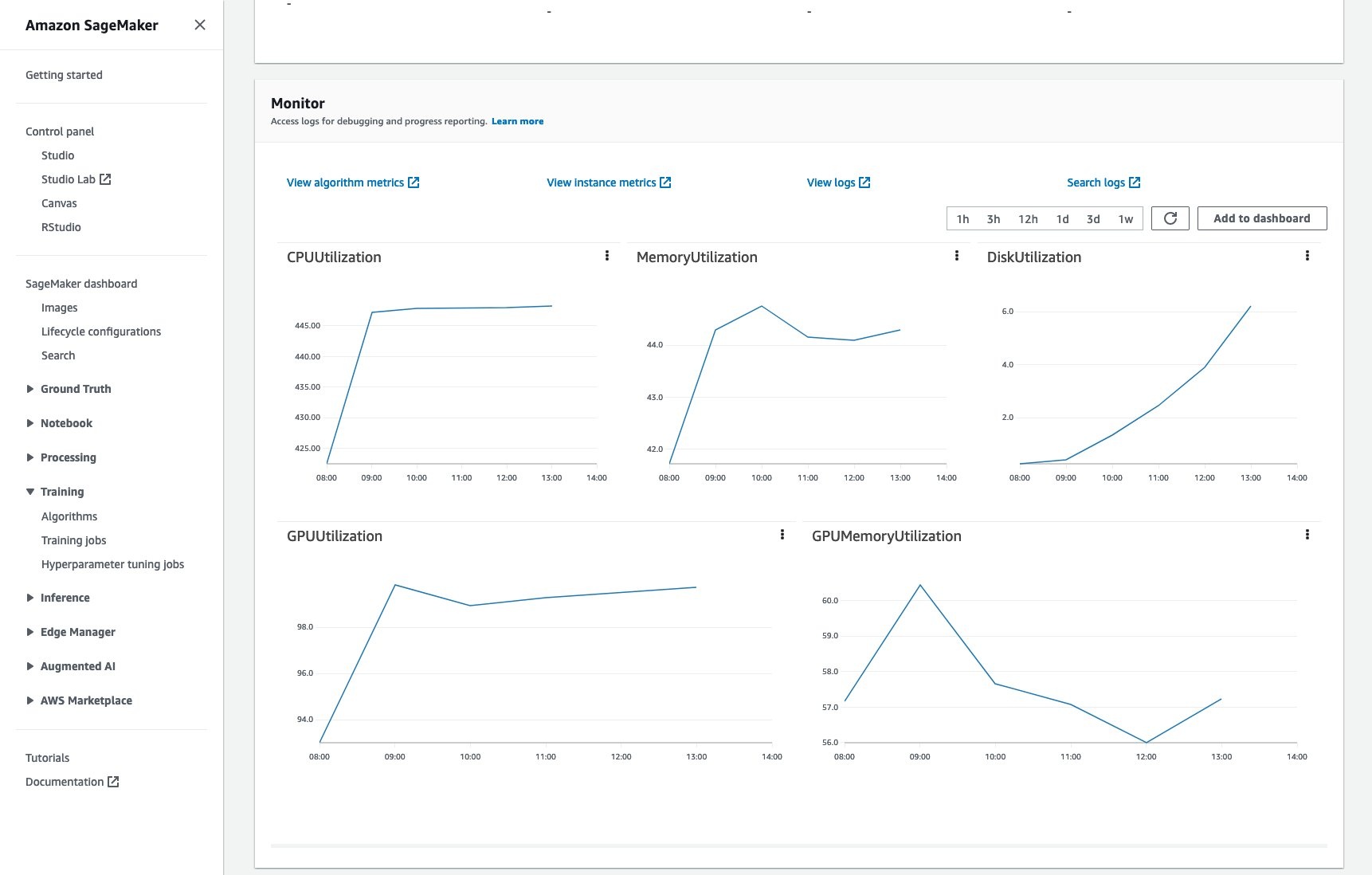
所有这些都无需任何额外的代码或精力。
有关在云端运行训练作业的完整示例,请参阅 “
结论
在这篇文章中,我们描述了与再训练神经网络相关的问题以及 Renate 库在此过程中的主要优点。要了解有关该库的更多信息,请查看
我们期待您的
作者简介
 Giovanni Zappella
是一位高级应用科学家,在 亚马逊云科技 Sagemaker 从事长期科学工作。他目前从事持续学习、模型监控和 AutoML 方面的工作。在此之前,他曾在亚马逊音乐公司为大型推荐系统开发多臂强盗的应用程序。
Giovanni Zappella
是一位高级应用科学家,在 亚马逊云科技 Sagemaker 从事长期科学工作。他目前从事持续学习、模型监控和 AutoML 方面的工作。在此之前,他曾在亚马逊音乐公司为大型推荐系统开发多臂强盗的应用程序。
 马丁·维斯图巴 是 A
WS Sagemaker 长期科学团队的应用科学家。他的研究重点是自动机器学习。
马丁·维斯图巴 是 A
WS Sagemaker 长期科学团队的应用科学家。他的研究重点是自动机器学习。
 卢卡斯·巴尔斯 是 亚马逊云科技
的应用科学家。他致力于持续学习和与模型监控相关的主题。
卢卡斯·巴尔斯 是 亚马逊云科技
的应用科学家。他致力于持续学习和与模型监控相关的主题。
 塞德里克·阿尚博
是 亚马逊云科技 的首席应用科学家,也是欧洲学习与智能系统实验室的研究员。
塞德里克·阿尚博
是 亚马逊云科技 的首席应用科学家,也是欧洲学习与智能系统实验室的研究员。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。