我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
自动将卫星图像转换为经过云优化的 GeoTiffs,以便在 Amazon S3 中托管
长期以来,卫星图像的庞大尺寸给寻求动态渲染这些图像的客户软件带来了沉重负担。通常,客户必须将影像从中央存储库复制到本地计算机。下载大图像可能需要几分钟。下载图像时,处理速度也很慢。
在这篇文章中,我们演示了如何使用无服务器技术来处理和存储卫星图像。具体而言,这些图像被转换为高效的 COG 并存储在
云端优化的 GeoTIFF (COG)
COG 是普通的 GeoTIFF,但其内部组织可以实现更高效的云端工作流程。用户只能流式传输所需的 COG 部分,从而加快数据传输和处理速度。此外,COG 可减少数据重复。用户无需在本地复制和缓存数据即可访问 COG 数据。以下各节中描述的无服务器架构允许组织自动将其数据转换为 COG。
解决方案概述
为此,我们介绍了以下步骤:
-
如何在预装了 Python 库 rio-cogeo 的情况下构建容器化 的
亚马逊云科技 Lambda 函数,用于将图像转换为 COG。亚马逊云科技 Lambda 将能够翻译大小小于 10GB 的图像。 - 创建云基础架构,用于自动处理新图像、对其进行转换和存储输出。当 S3 存储桶收到上传的卫星图像时,S3 存储桶会触发翻译 Lambda 函数。
- 如何将客户端应用程序连接到 Amazon S3 中这些新创建的 COG 文件的示例。
先决条件
在继续执行以下步骤之前,需要满足以下先决条件:
- 创建 Amazon S3 存储桶的 IAM 权限
- 亚马逊云科技 Lambda 具有读取和写入 S3 存储桶的权限
- 创建 ECR 存储库并将 Docker 映像推送到该存储库的 IAM 权限
-
安装了
Docker -
亚马逊云科技 命令行界面 已安装 -
QGIS 软件已安装
草率排练
在较高的级别上,您将执行以下步骤:
- 创建 Amazon S3 输入/输出存储桶。
- 创建 亚马逊云科技 Lambda 容器镜像并推送到 ECR。
- 使用 ECR 映像部署 亚马逊云科技 Lambda 函数并设置 S3 触发器。
- 将 COG 与 QGIS 软件配合使用。
1。创建亚马逊 S3 存储桶
大多数 GeoTiff 已经不是 COG 了。为了方便地将这些图像转换为 COG,这篇文章部署了两个 S3 存储桶和一个 Lambda 函数。最终,用户可以将其图像上传到输入 S3 存储桶,该存储桶会触发 Lambda 函数将图像转换为 COG 并将结果上传到输出 S3 存储桶。
首先使用
2。创建 Lambda 容器镜像
接下来,我们将介绍如何构建负责将输入图像转换为 COG 的 Lambda 函数。按如下方式创建 handler.py、Dockerfile 和 requirements.txt,然后存储在 /lambda 等目录中。
# handler.py
import json
import boto3
import os
import rio_cogeo
from rio_cogeo.cogeo import cog_translate
from rio_cogeo.profiles import cog_profiles
def noncog_to_cog_tiff(input_img, output_img):
if rio_cogeo.cog_info(input_img).COG:
print('The input img is already a COG!')
else:
print('The input img is not a COG, starting conversion of input img to COG!')
cog_translate(input_img, output_img, cog_profiles.get("lzw"))
if rio_cogeo.cog_info(output_img).COG:
print(f'finished converting input img to COG! The output img is saved to {output_img}')
def handler(event, context):
print('start')
os.mkdir('/tmp/output')
bucket_name = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
obj_name = key.split('/')[-1]
full_path = f's3://{bucket_name}/{key}'
s3 = boto3.resource('s3')
s3.Bucket(bucket_name).download_file(key, f'/tmp/{obj_name}')
print(obj_name)
noncog_to_cog_tiff(f'/tmp/{obj_name}', f'/tmp/output/{obj_name}')
s3 = boto3.client('s3')
s3.upload_file(f'/tmp/output/{obj_name}', bucket_name+'-output', 'cog_'+key)
return {
'statusCode': 200,
'body': json.dumps(f'conversion_to_cog_finished')
}# Dockerfile
FROM public.ecr.aws/lambda/python:3.9
COPY requirements.txt /tmp/requirements.txt
RUN pip install -r /tmp/requirements.txt
COPY handler.py ${LAMBDA_TASK_ROOT}
CMD ["handler.handler"]
# requirements.txt awslambdaric boto3 rio-cogeo
在终端中,导航到该目录并执行
docker build-t lambda-cog-blog: latest。
构建 docker 镜像后,你可以使用 docker ru
n-p 9000:8080 lambda-cog-bl o
g: latest 命令在本地对其进行测试。
接下来,docker 镜像被推送到
-
docker tag blog-test: latest .dkr。ecr.us-east-1.amazonaws.com /lambda-cog-blog: latest
-
aws ecr get-login-password--region us-east-1 | docker 登录--用户名 亚马逊云科技--password-stdin .dkr。ecr.us-east-1.amazonaws.com
-
aws ecr create-repository-name lambda-cog-blog--image-scanning-cannPush=True--image-tag-mutability 可变性
-
docker push .dkr。ecr.us-east-1.amazonaws.com /lambda-cog-blog: latest
3。从亚马逊 ECR 映像部署 Lambda
最后,可以使用存储在 Amazon ECR 中的映像来部署 Lambda 函数。在控制台中打开 Lambda。选择 创建函数 ,然后选择 容器镜像 类别。选择 浏览图片 ,然后选择已推送到亚马逊 ECR 的 Lambda 图像。为 Lambda 函数命名,然后选择 创建 函数。
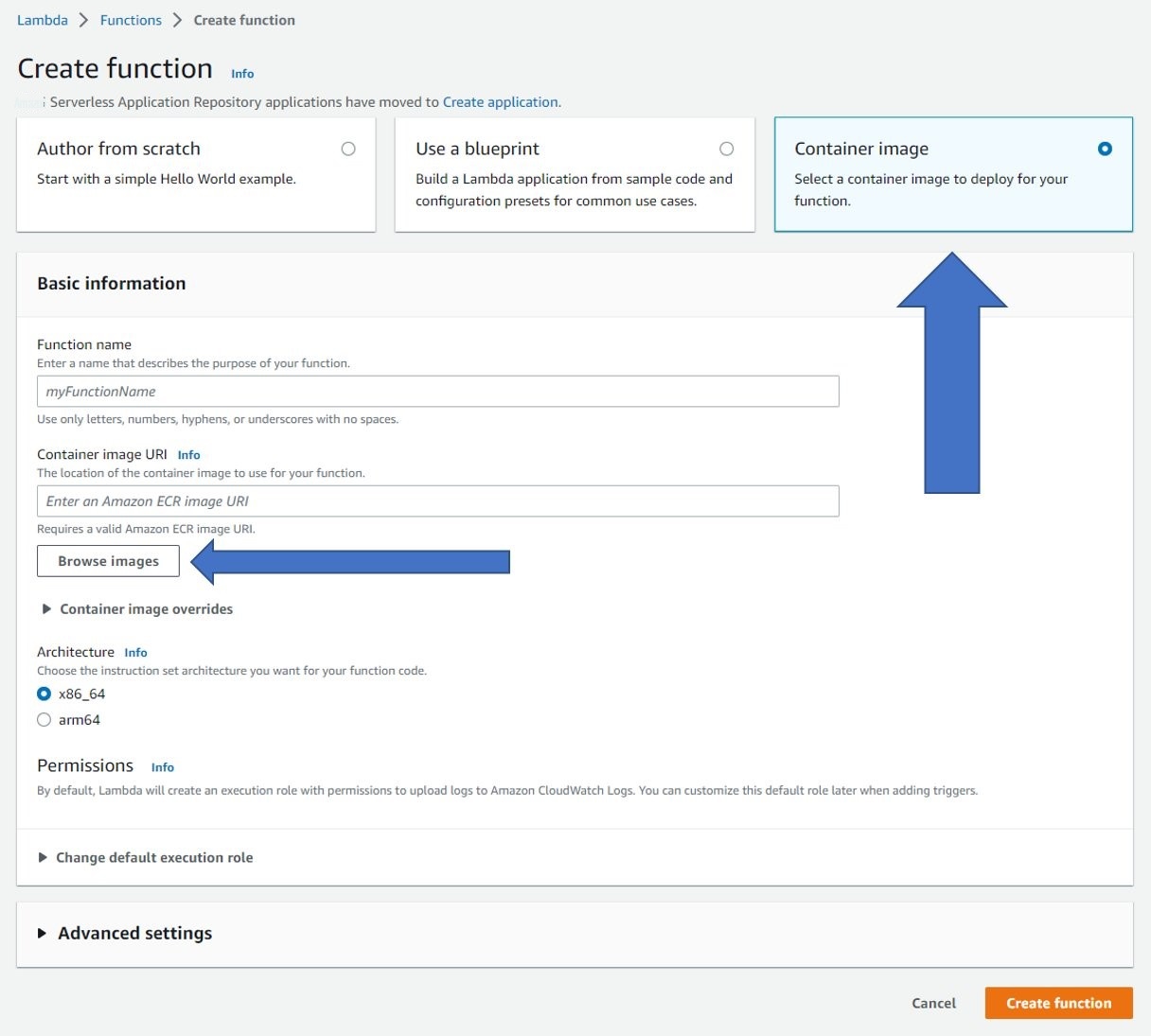
创建函数后,必须设置 Amazon S3 触发器。首先选择 添加触发器 并使用 Amazon S3 作为来源。选择您的存储桶作为事件源,然后选择底 部的 添加 。此外,打开配置选项卡,在 “权限” 下为 Amazon S3 的函数角色授予读写 权限 。根据输入图像可能的大小,您还可以在 “常规配置” 下增加 Lambda 函数的内存(10 GB 限制)、磁盘(10 GB 限制)和超时(15 分钟限制)。
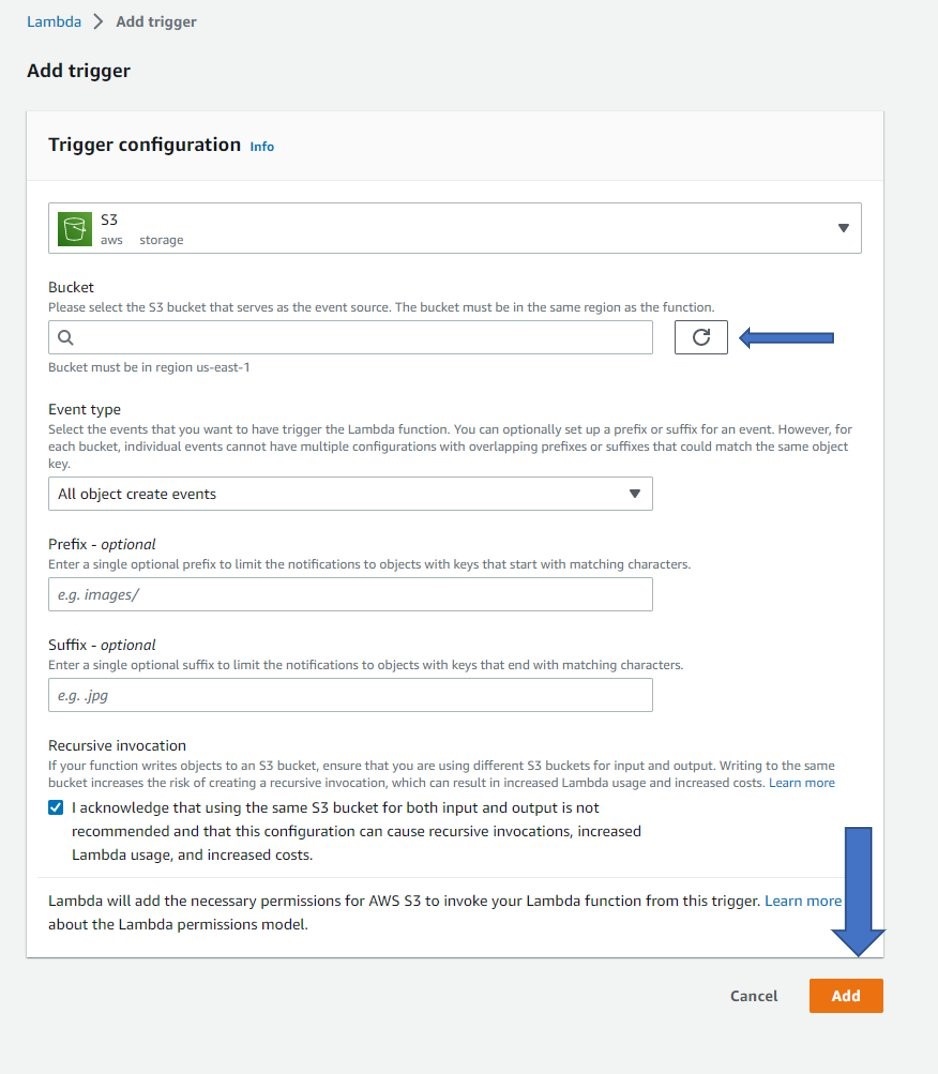
这样就完成了必要的架构。用户可以将图像输入到输入 S3 存储桶,此处称为 “geotiff-to-cog” 存储桶。这将触发 Lambda 函数,该函数下载图像并将其转换为 COG。Lambda 函数将 COG 输出输入到输出 S3 存储桶,此处称为 “geotiff to-cog-output”。
4。使用 QGIS 软件访问 COG
“geotiff-to-cog-output” S3 存储桶中的图像已准备就绪,可以使用地理空间分析软件进行高效访问。这篇文章演示了如何 使用之前创建的存储桶的公共版本通过
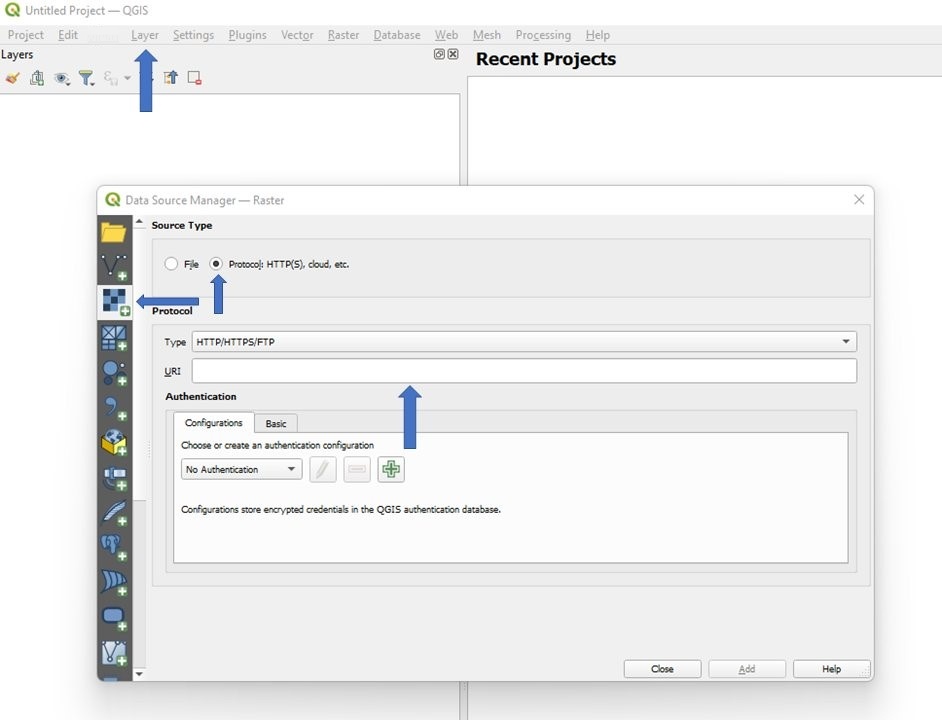
在存储桶中,复制您想要在 QGIS 中分析的任何 COG 图像的 Amazon S3 网址。

打开 QGIS => 图层 => 数据源映射器 。在 数据源映射器 中 ,选择 添加栅格图层 选项卡。在 源类型 下 ,选择 协议:HTTP (S)、云等 , 然后将 Amazon S3 URL 粘贴到 协议 下的 URI 输入框中 。选择 “ 添加 ” 并关闭 “ 数据源映射器 ”。来自亚马逊 S3 的 COG 图像已在 5-10 秒内加载到 QGIS 中,可供用户分析。如果您更喜欢使用非公有 S3 存储桶,则 QGIS 可以选择输入 亚马逊云科技 证书,以允许 QGIS 访问非公共存储桶内的图像。
远程使用 COG 需要权衡取舍。使用 COG 时,扫描图像所需的渲染时间略长于已完全下载并在 QGIS 中在本地打开的图像。但是,与必须下载整个非 COG 图像然后将其加载到 QGIS 中相比,COG 能够仅使用 URL 在用户的地理空间软件中快速显示具有明显的速度优势。
正在清理
以下说明用于删除本文中创建的资源:
删除输入/输出 S3 存储桶
- 登录 亚马逊云科技 管理控制台并打开 Amazon S3 控制台。
- 在 存储桶 列表中,选择您创建的输入存储分区名称旁边的选项,然后 在页面顶部选择 删除 。如果存储桶不为空,则在 删除存储桶之前,您必须选择 清空 并在输入字段中提交 “ 永久 删除 ”。
- 在 删除存储桶 页面上,通过在文本字段中输入存储桶名称来确认您要删除存储桶,然后选择 删除存储桶 。
- 对输出存储桶重复上述说明。
删除 亚马逊云科技 Lambda 函数
- 登录 亚马逊云科技 管理控制台并打开 亚马逊云科技 Lambda 控制台。
- 在导航侧栏 中选择 “ 函数 ”。
- 在 函数 列表中,选择您创建的函数名称旁边的选项,然后 在页面顶部选择 操作 。在下拉菜单 中单击 “ 删除 ”。
- 在输入框中输入 “删除”,然后点击 底部的 删除 。
删除 ECR 存储库
- 登录 亚马逊云科技 管理控制台并打开 Amazon ECR 控制台。
- 在导航侧栏中选择 存储库 。
- 在 私有存储库 列表中,选择您创建的存储库名称旁边的选项,然后 在页面顶部选择 删除 。
- 在输入框中输入 “删除”,然后点击 底部的 删除 。
结论
在这篇文章中,我们演示了一种解决方案,可帮助您
通过使用 COG,用户不再需要复制数据。用户可以立即访问大型卫星图像,而不必在本地下载,这可能需要几分钟。用户还可以流式传输他们需要的部分图像,而不是使用整张图像,从而加快处理速度。更快地访问和处理数据的能力可以提高用户的效率和生产力。
感谢您阅读这篇文章。如果您有任何意见或问题,请将其留在评论部分。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。