我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
自动管理 Multus Workers 和 Pod 的 IP 地址
基于电信 5G 和 IMS 容器的工作负载利用
这篇名为《
- Multus 工作节点组:工作节点子网和工作节点的 IP 地址管理,因为每个工作节点 ENI 都需要子网中的 IP 地址。
-
Multus Pod 网络:来自工作节点子网的 Multus Pod IP 管理,以及
亚马逊虚拟私有云 (亚马逊 V PC) 中的容器通信。
在这篇文章中,我将介绍标准的 Multus 节点组部署方法,以及在 Amazon VPC 内将 ipvlan CNI 与 Multus 工作负载一起使用时面临的挑战和管理上述主题的方法。
标准 Multus 节点组部署方法
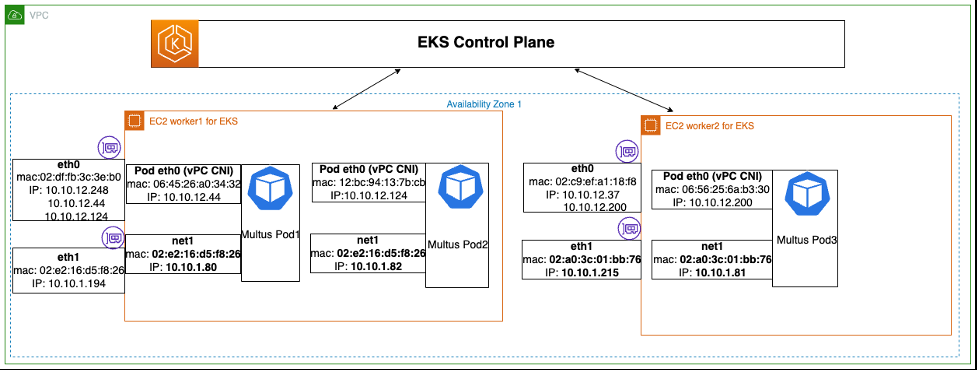
前面的图表代表了使用 IPVLAN CNI 部署 Multus 工作负载的示例,本文将对此进行介绍。在此示例中,我们有一个 Amazon EKS 集群和一个包含两个工作节点的节点组。两个工作节点都连接有两个子网,如下所示:
- eth0 网络:10.10.12.0/24(用于 VPC CNI,即主容器接口)
- eth1 网络:10.10.1.0/24(用于 Multus ipvlan cni,即 pod 辅助接口)
对于之前的示例部署方法,部署从 Amazon EKS 集群部署开始,然后是 Amazon EKS 节点组部署。部署节点组后,您可以部署 Multus CNI 和相关插件来支持您的工作负载。部署插件后,您可以部署工作负载。
在下一节中,我将讨论 Multus 工作节点组和 IP 管理的部署策略。
Multus 工作节点组部署和 IP 管理
多工作节点部署
自行管理的 Multus Node 组,使用自动扩展组,提供弹性(保持最少的工作人员数量)和可扩展性。自动扩缩组利用
如下图所示,部署从自动扩展组使用启动模板创建具有单接口 (eth0) 的工作节点开始。工作线程启动后,自定义 Lambda 会终止单一接口节点。这种缩减会导致 “Autoscaling: ec2_instance_Terminating” 事件,该事件会触发自定义 Lambda,然后耗尽节点/或者不执行任何操作。
此事件完成后,自动扩缩组向外扩展以满足所需的容量,从而导致 “AutoScaling: ec2_instance_Launce_Launce_Launching” 事件。此事件触发自定义 Lambda 函数,该函数添加来自 Multus 子网的辅助接口,其标签为(密钥:node.k8s.amazonaws.com/no_manage” 值:true)。
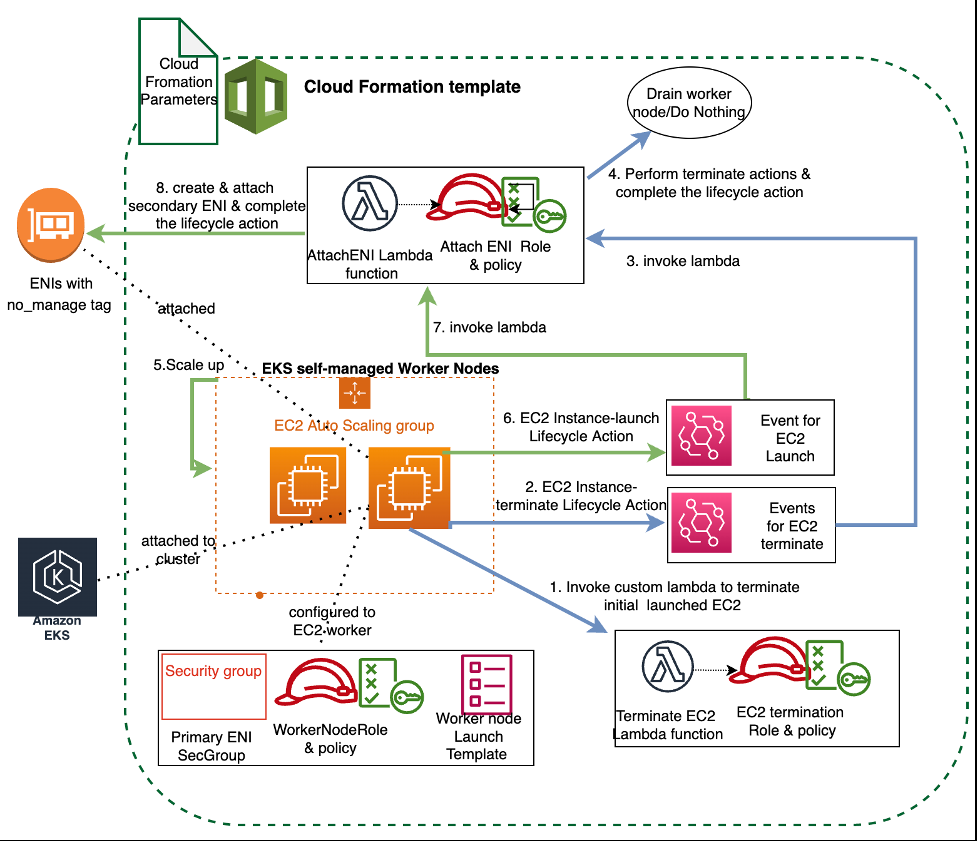
EKS 多节点组创建流程
工作节点 IP 管理挑战
自动扩展组为 Amazon EKS 工作节点组提供弹性和灵活性,并使用 DHCP IP 分配给所有接口来支持同样的配置。另一方面,对于 Multus Pod,非 VPC IPAM CNI(
同一个子网上的两种不同且不连贯的 IP 分配方法(DHCP 和静态)给工作负载部署带来了有趣的挑战。DHCP 的工作节点 IP 分配是随机的,由于它不知道其他静态分配,因此它可以从容器计划的静态 IP 范围中获取任何 IP 地址。Multus IPAM CNI(
解决方案
在以下部分中,我将向您介绍两种可能的方法,以非冲突的方式更好地管理工作节点和Multus工作负载的IP地址。
方法 1:使用自定义 Lambda 静态分配工作人员 IP
这种解决方案方法适用于工作节点和容器之间的逻辑子网共享模型。在这种方法中,工作节点从子网的开头获取未分配的 IP,而 Multus Pod 从子网末端获取未分配的 IP。使用这种分配策略,工作节点接口的 IP 地址分配不是随机的,IP 分配是从子网中第一个可用的 IP 静态开始的。
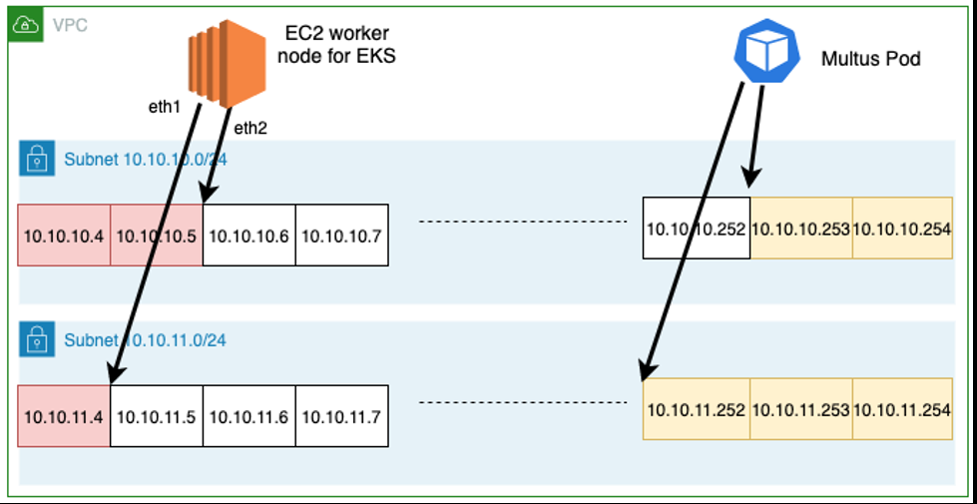
有关详细描述、AW
方法 2:使用 VPC 子网 CIDR 预留(静态)作为 pod 的 IP 地址
这种方法使用
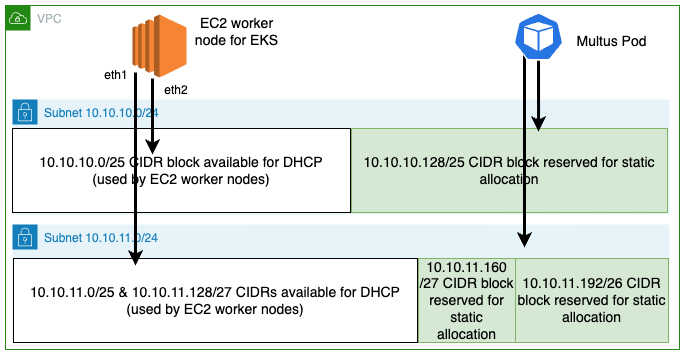
有关详细描述、
自动多舱联网
现在,亚马逊 EKS 集群和 Multus 节点组已使用上述任一方法进行部署,您可以使用 Multus 在 Amazon EKS 上部署工作负载。下一步,你将按照
现在,让我们了解一下 IP 通信在 VPC 中的工作原理、启用路由的方法以及以自动方式为 Multus Pod 分配 IP。
Multus Pod IP 管理和路由挑战
在以下示例中,请注意,当你部署 Multus 容器时,即使安全组 Rules/Nacl 没有阻塞流量,不同工作人员上的 Pod 之间的通信也无法正常工作。但是,同一个工作节点上的 pod 之间的互通可以正常工作。
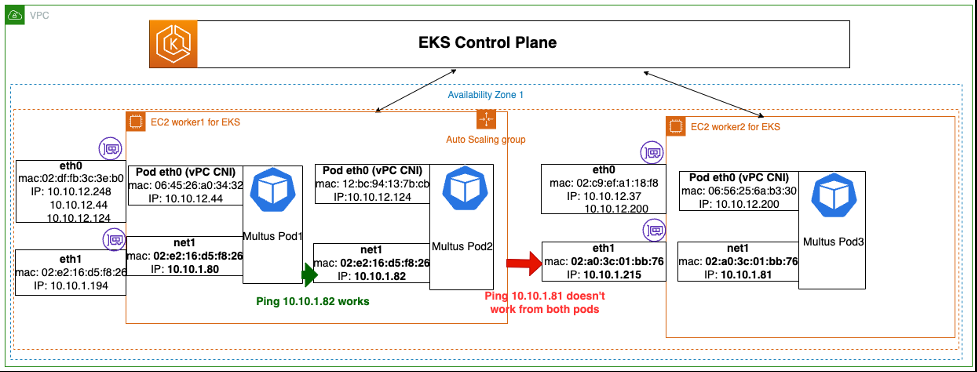
在这里,我将详细解释这种行为。亚马逊 VPC 云为其工作负载提供第 3 层网络。ENI 是包含一个或多个 IP 地址和相应的 MAC 地址的逻辑网络实体。Amazon VPC 根据分配给 ENI 的 IP 地址将流量路由到正确的目的地。连接到 Amazon EC2 工作节点的每个 ENI 都必须为其分配所需的 IP 地址。
对于容器的主接口,亚马逊 VPC CNI 使用 DHCP 为容器 eth0(VPC CNI 托管接口)分配主容器 IP 地址(在前面的示例中为 10.10.12.x),并将这些 IP 分配为工作节点 ENI 上的辅助 IP。非 VPC IPAM CNI(行踪、主机本地、静态等)将 IP 地址分配给 Multus 容器。因此,亚马逊 VPC 不会知道这个 IP 地址的分配。此外,在相应的工作节点 ENI 上,这些 IP 地址未被指定为辅助 IP(在本示例中为 eth1)。
请注意,您可以通过检查 Amazon EC2 控制台上的工作节点 ENI 来进行验证:亚马逊 EC2 控制台 → 实例 → 选择实例(工作节点)→ 操作 → 联网 → 管理 IP 地址。
当将 Pod 假设的 IP 地址分配给相应的工作网卡时,这个问题就解决了。将这些 IP 分配给相应的 ENI(例如:eth1)后,亚马逊 VPC 会更新分配给 ENI 的 IP 的映射,以将流量路由到指定的 Multus IP 地址。
在以下示例中,Multus 容器 IP 地址 10.10.1.80 和 10.10.1.82 被分配为第一个工作节点的 eth1 ENI 上的辅助 IP 地址。同样,10.10.1.81 的辅助 IP 被分配给第二个工作节点 eth1 ENI。
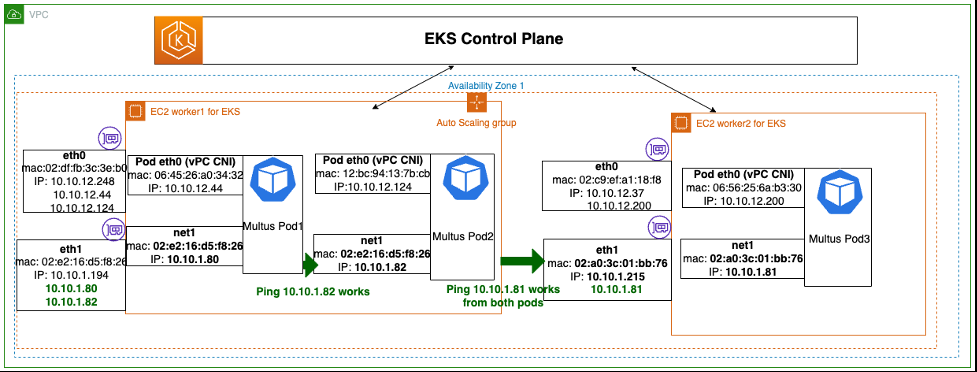
自动化解决方案
Amazon EC2 分配 IP 地址/取消分配 IP 地址 API 调用可以在工作节点 ENI 上自动分配 IP。来自
下文讨论的自动化方法不需要对应用程序映像或源代码进行任何更改。您可以利用这些 Pod 上的自定义 “IP 管理” 容器在相应的工作节点 ENI 上执行 IP 分配的自动化,而不会对应用程序容器或其架构产生任何影响。您可以使用此附加容器增强工作负载容器/部署/状态集的规格。
请参阅
方法 1:基于 InitContainer 的 IP 管理解决方案
此解决方案适用于大多数 ipvlan CNI pod,无需特殊/自定义处理,例如浮动 IP(将在下一个方法中解释)。这种方法不会对工作人员增加额外 CPU/内存要求的限制。
当 POD 处于初始状态时,此 “IP 管理” 容器作为第一个容器执行。此容器检查 Pod 的 IP 地址,并在容器处于初始状态时将 IP 地址分配给 ENI。成功将 Multus IP 地址分配给工作节点 ENI 后,此 InitContainer 将终止,Pod 将退出初始化状态。
要使用此解决方案,请参阅
方法 2:Sidecar IP 管理解决方案
在这种方法中,“IP 管理” 容器作为边车容器运行。此外,与 InitContainer 不同,它会持续监控 Multus 接口上的 pod IP 地址,寻找新的或更改的 IP 地址。这对于对活动/备用容器进行自定义 “浮动 IP” 处理的 pod 很有用,并且根据内部逻辑,“浮动 IP” 会在不中断流量的情况下故障转移到备用 Pod。在这种情况下,sidecar 会持续监控 Pod 的 IP 地址变化,因此每个基于 Multus 的容器的 CPU/内存(最少)会额外使用。
要使用此解决方案,请参阅
正在清理
要
结论
这篇文章概述了客户在亚马逊 VPC 云中分配、管理和分离工作节点和 Multus Pod IP 地址时面临的挑战。此外,它还描述了 Multus Pod 如何在亚马逊 EKS 和亚马逊 VPC 范围内工作,以及如何在 VPC 中路由流量。
此外,这篇文章提供了Amazon EKS节点组的示例自动化方法和Multus Pod的IP管理自动化,软件/映像没有任何变化。
为简单起见,这篇文章仅演示了前面示例中的 IPv4 处理。但是,
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。