我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
自动更新已恢复的 Amazon DynamoDB 表上的表格设置
定期备份是设计关键业务应用程序的关键组成部分,以便在出现任何故障情况时保持弹性。它们提供了许多好处,其中最重要的是数据保护、在出现中断时更有效地恢复数据、遵守组织和法律要求以及简化维护。
DynamoDB
尽管 PITR 允许您使用 DynamoDB 控制台或 亚马逊云科技 命令行接口 (亚马逊云科技 CLI) 将表恢复到某个时间点,但某些源表级别的设置不会自动应用到新创建的表。其中包括自动扩展、
解决方案概述
该解决方案主要由以下 亚马逊云科技 服务组成:
-
亚马逊云科技 CloudFormation -
亚马逊 DynamoDB -
亚马逊 EventBridge -
亚马逊云科技 Lambda -
亚马逊简单队列服务 (亚马逊 SQS) -
亚马逊云科技 无服务器应用程序模型
需要注意 的关键要点 :
- 该解决方案使用由 亚马逊云科技 CloudTrail 记录的时间点恢复 DynamoDB API 调用,为了提高可读性,在本博客文章中将其称为 “PITR API 调用”。
-
本文中描述的解决方案作为 亚马逊云科技 无服务器应用程序模型应用程序堆栈进行部署。有关 亚马逊云科技 SAM 应用程序的更多信息,请参阅
什么是 亚马逊云科技 无服务器应用程序模型 (亚马逊云科技 SAM)? 。
我们创建了一
- 资源组包含对 PITR API 调用做出反应的 Amazon EventBridge 规则。
- 资源组,使用指数退避和抖动(用图 1 中的红色虚线标记)重试来自 Amazon SQS 队列的 PITR API 调用。
以下是解决方案架构的高级演练:
- 使用控制台或 亚马逊云科技 CLI 通过 Amazon DynamoDB PITR 流程恢复表。
- 亚马逊 EventBridge 对 PITR API 调用做出了反应
- EventBridge 规则将 DynamoDB PITR API 调用路由到亚马逊 SQS 队列
- 该事件由 Lambda 表同步函数进行轮询。
- Lambda 函数检查目标 DynamoDB 表是否处于活动状态。
- 如果目标表未处于 ACTIVE 状态,则该事件将被推回死信队列 (DLQ)。
- 该进程使用指数退避策略进行重试,直到目标表变为活动状态或超过特定的重试次数。
- 如果超过重试次数,则进程会正常停止并发送到辅助 DLQ,这表示目标表不是出于未知原因创建的(需要进一步进行故障排除)。
- 如果目标表达到活动状态,Lambda 表同步函数将部署 CloudFormation 堆栈来导入目标表。
- 表同步功能为要为目标表配置的每项设置创建并运行 CloudFormation 更改集。
下面的图 1 说明了解决方案架构。
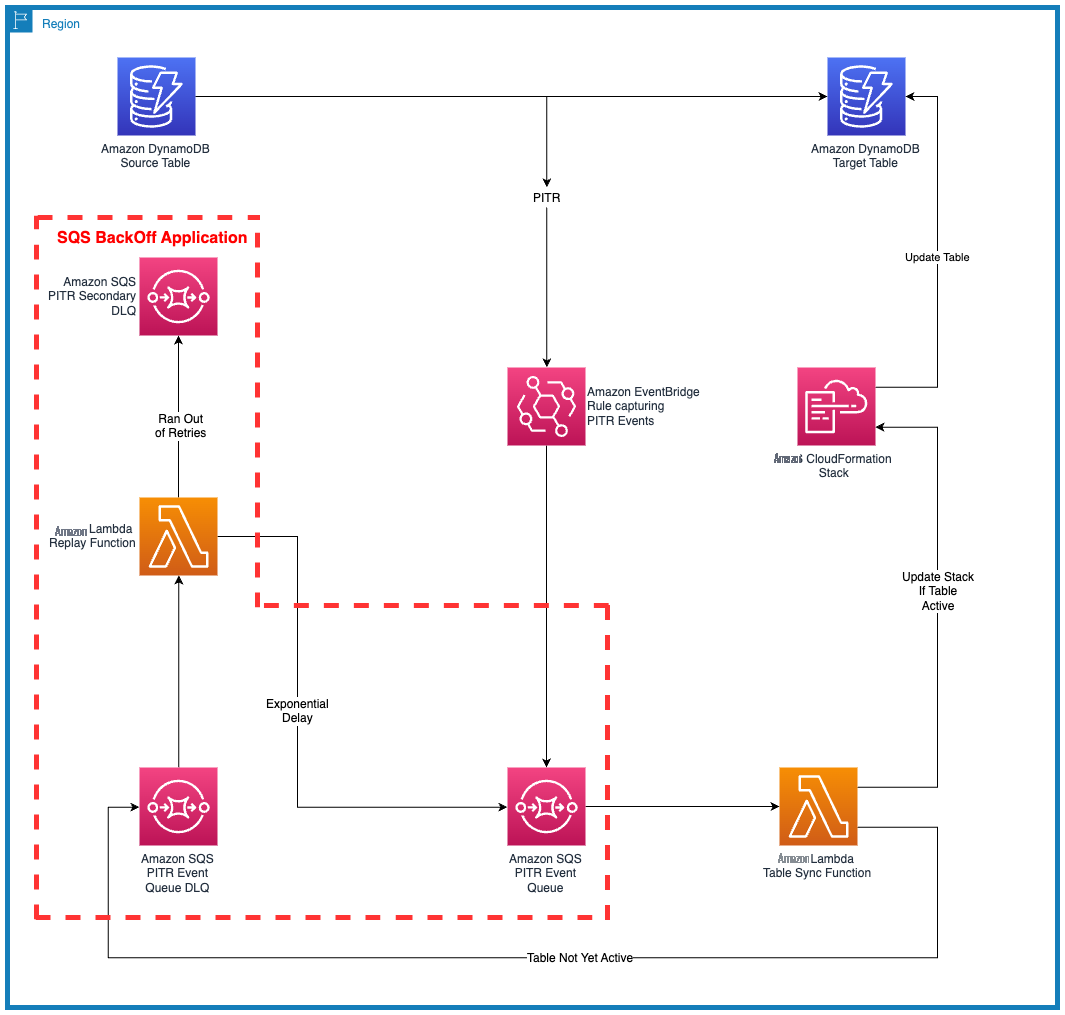
图 1:显示组件和流程的解决方案架构
你可以在
先决条件
要完成本演练,您必须具备以下先决条件:
-
一个活跃的 亚马逊云科技 账户。要注册,请参阅
设置 亚马逊云科技 账户和创建用户 。 -
在本地计算机上克隆和配置的
GitHub 存储库。 -
亚马逊云科技 CLI
已安装 。 -
已
安装 适用于您的主机环境的 亚马逊云科技 SAM CLI 。 -
安装了 Python(Python 3.7) 。 -
GIT 命令行界 面已安装 。 -
您选择的可视化编辑器,例如
Visual Studio 代码 。 -
网络浏览器,例如
Chrome 或火狐 浏览器。 - 创建 亚马逊云科技 资源的权限。
-
启用了
PITR 并 启用了其他表设置(例如亚马逊 Kinesis Data Streams 、TTL 和标签)的 Dyn amoDB 表。
部署 PITR 亚马逊云科技 SAM 应用程序堆栈
使用可视化编辑器设置新的工作区,然后在 shell 或终端窗口中运行以下命令来构建和部署本文中使用的示例应用程序:
这些命令进入项目目录并克隆
- sam build 命令用于构建应用程序的源代码。
- sam deploy — guideploy 命令打包并将应用程序部署到 亚马逊云科技,并附带一系列提示:
- 堆栈名称 — 要部署到 CloudFormation 的堆栈的名称。这应该是你的账户和地区所独有的;一个好的起点是你在这个项目中使用的名称。
- 亚马逊云科技 区域 — 您要将应用程序部署到的区域。
- 部署前确认更改 -如果设置为 “是”,则运行前会显示所有更改集供您查看。如果设置为 “否”,则 亚马逊云科技 SAM CLI 会自动部署应用程序更改。
-
允许创建 SAM CLI IAM 角色
— 许多 亚马逊云科技 SAM 模板,包括此示例,都会创建 L ambda 函数
访问 亚马逊云科技 服务所需的 亚马逊云科技 身份和访问管理 (IAM) A ccess Management 角色。默认情况下,这些权限范围缩小到所需的最低权限。要部署创建或修改 IAM 角色的 CloudFormation 堆栈,您必须为这些功能提供 CAPABILITY_IAM 值。如果未通过此提示提供权限,则必须将 —cabilitions CAPABILITY_IAM 明确传递给同一个部署命令才能部署此示例。 - 将参数保存到 samconfig.toml — 如果设置为 “是”,则您的选择将保存到项目内的配置文件中,以便将来您可以在没有参数的情况下重新运行 sam deploy 来部署对应用程序的更改。
要验证部署命令是否成功,请打开 CloudFormation 控制台,选择您的堆栈名称,导航到事件选项卡,然后验证 CloudFormation 堆栈是否已创建,其状态是否为 CREATE_COMPLETE(对于新堆栈)或 UPDATE_COMPLETE(对于更新的堆栈)。如图 2 所示,如下所示。

图 2:验证部署命令是否成功
验证源表上是否启用了 PITR
运行以下 亚马逊云科技 CLI 命令( 使用先决条件中的
表名称替换 sourceTableWithKDS
),验证源 DynamoDB 表上是否启用了 PITR:
前面的命令应显示以下 JSON:
验证源表上的设置
您可以在控制台上或通过运行
例如,要通过 亚马逊云科技 CLI 验证源表上的 Kinesis 数据流设置,请使用以下代码:
该命令应显示以下 JSON,这表明源表上已启用 Kinesis 数据流:
将亚马逊 DynamoDB 表恢复到某个时间点
在控制台上或通过 亚马逊云科技 CLI 命令将您的 DynamoDB 表恢复到某个时间点。有关恢复表格的步骤,请参阅
sourceTableWithKDS 和 TargettableWithkd
sRestore 分别替换为源表名和目标
表名:
此命令使用名为 TargetTableWithkdsRestore 的新表名启动 PITR 进程。
命令中的参数(例如,表名和还原日期时间)可能会因您的用例而有所不同。此外,从备份中恢复 DynamoDB 表的时间可能会有所不同,具体取决于表的大小以及是否存在全局二级索引 (GSI) 等因素。
验证目标表上的表设置
在控制台上或使用 亚马逊云科技 CLI 命令验证目标(已恢复)表中的设置。
例如,在 亚马逊云科技 CLI 中使用以下代码验证目标表上的 Kinesis 数据流设置:
您应该得到以下结果,该结果显示 Kinesis 数据流已在目标表上自动启用:
你可以使用同样的方法来验证和验证其他表格设置。
您可以使用控制台查看模板的 CloudFormation
事件
选项卡,进一步验证解决方案的部署。状态应为
UPDATE_COM
PLETE ,如下面的图 3 所示。
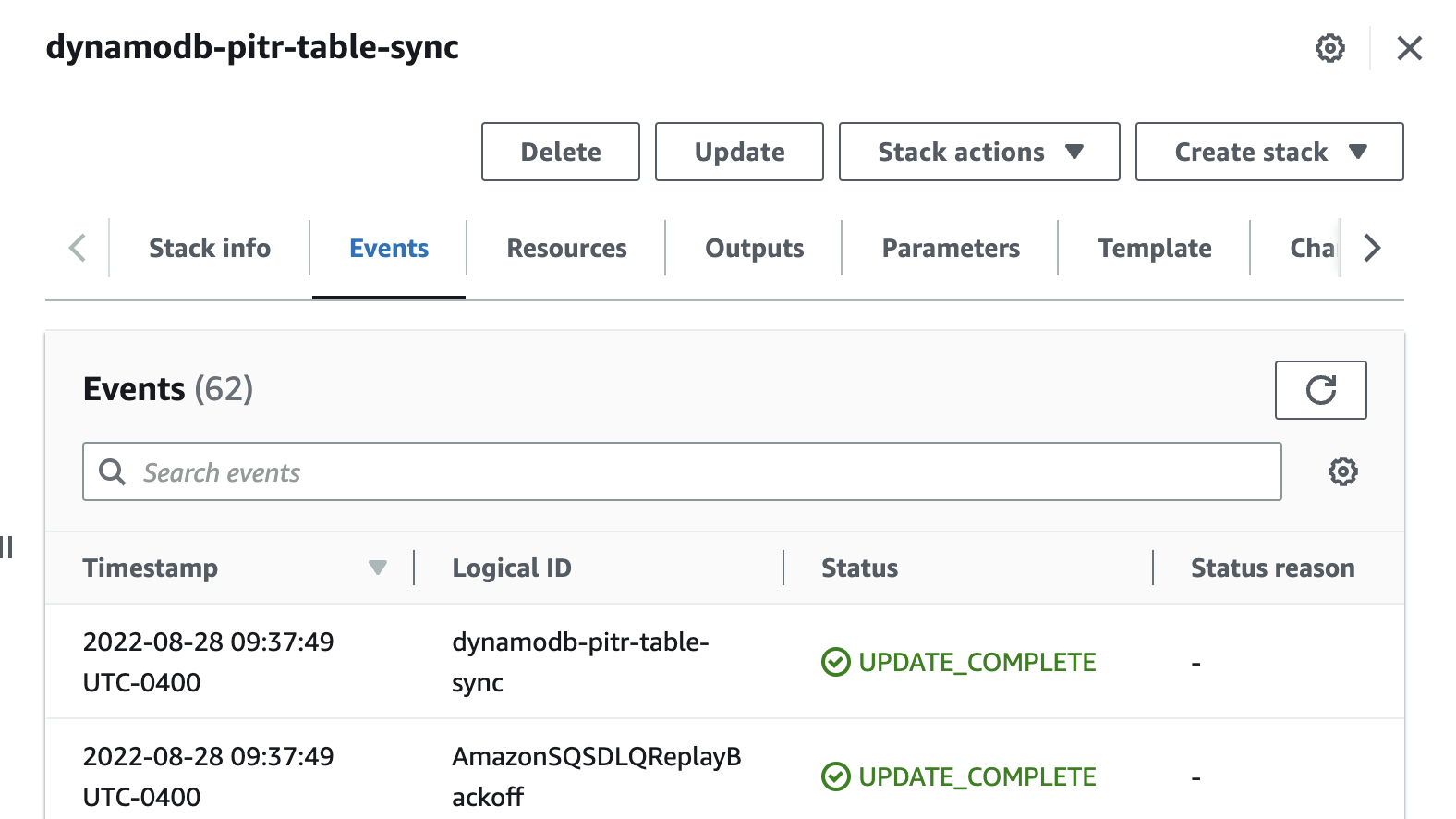
图 3:验证 CloudFormation 事件是否成功更新
清理
为避免持续产生费用,请删除您使用 亚马逊云科技 SAM CLI 创建的示例应用程序。你可以运行以下命令,将堆栈名称替换为项目名称(如果不同):
除非其他项目需要,否则您可以删除先决条件中提到的创建的源 DynamoDB 表。
局限性
本文中部署的无服务器应用程序将 DynamoDB 源表设置的子集克隆到目标表。
除了在表还原期间由 DynamoDB 自动复制的设置外,源表中的以下表设置也会自动复制到目标表:
- 标签
- Kinesis 数据流设置
-
亚马逊 DynamoDB Stream s 设置以及触发器 - PITR 设置
- 表和索引的自动扩展策略
- TTL 设置
源表中的以下表设置不会自动复制到目标表,但您可以将它们作为扩展添加到代码库中:
-
亚马逊 CloudWatch 指标 - 云观警报
其他需要注意的事项:
- 在设置 亚马逊云科技 SAM 应用程序时,您可以选择要从源表克隆到目标表的设置。
- 在设置 亚马逊云科技 SAM 应用程序时选择的设置将应用于 亚马逊云科技 账户中发生的所有亚马逊 DynamoDB 时间点恢复 (PITR) API 调用。这种自动化目前不提供任何在单个 PITR API 调用级别上对此进行控制的功能。
需要考虑的事情
以下是您在实施 PITR 时可能遇到的一些问题。
亚马逊 SQS 退避能否保证亚马逊 DynamoDB 时间点恢复 (PITR) 事件的处理?
亚马逊 SQS 回退并不能保证亚马逊 DynamoDB 时间点恢复 (PITR) API 调用处理。但是,如果表未转换为 ACTIVE 状态,它可以保留 API 调用。
重试 Amazon SQS 中事件的指数回退可使用 亚马逊云科技 SAM 模板的参数进行配置。该解决方案中的参数设置为 50 次重试,耗尽所有重试所花费的时间在 90—120 分钟之间,因为每次重试之前的每一次延迟都是使用指数退避和抖动计算的。
如果表很大(例如 100 TB),则在用尽重试次数之前可能无法完全恢复。为避免这种情况,您可以更新参数以通过更改
maxAttempts 来增加重试次
数 ,通过更改退避率来增加重试之间的延迟,或者两者兼而有之。这将延迟应用程序重试的用尽时间,直到恢复 DynamoDB 表。
我必须使用 Amazon SQS 退避应用程序轮询 DynamoDB 表状态吗?
在撰写本文时,当表的状态发生变化时,DynamoDB 不会发出事件。因此,您必须依赖 亚马逊云科技 CloudTrail 记录的 PITR API 调用并轮询表状态,直到表处于活动状态。
我可以选择要克隆哪些设置吗?
是的。部署应用程序时,亚马逊云科技 SAM 模板会提示您选择 true 或 false,以便在表之间克隆设置。
这种自动化会将设置应用到给定 亚马逊云科技 账户经过 PITR 恢复过程的所有 DynamoDB 表。
如何处理辅助 DLQ 中的事件?
配置 DLQ 时,可以保留任何未成功传送的消息。您可以解决导致事件交付失败的问题,并在以后处理这些事件。
在此设计中,进入辅助 DLQ 的消息必须通过手动干预进行处理。尽管使用了所有重试和错误处理机制,但这些消息还是进入了辅助 DLQ。因此,需要对这些消息进行调查,以找出处理失败的根本原因。
例如,通知 Lambda 函数可以从辅助 DLQ 读取消息,并将其发布到
这是否意味着我恢复表格时不必更改任何设置?
最好删除不需要的 GSI 和本地二级索引 (LSI),因为它们会增加恢复表所需的时间。此外,恢复表后无法删除 LSI。恢复表后,可以更改其余设置(LSI 和表名除外)。
结论
在这篇文章中,您学习了如何使用具有基于事件的机制的 CloudFormation 模板将 DynamoDB 表的设置自动克隆到恢复的表中。我们鼓励您使用这篇文章和相关代码作为起点来克隆 DynamoDB 表的设置。
作者简介
 Julia DeFilippis
是 亚马逊云科技 的高级参与经理。她与客户和利益相关者合作,确保实现业务成果,并确保 亚马逊云科技 团队取得成果。她喜欢与客户建立关系,并通过向后研究客户的需求和问题陈述来赢得信任。请参阅 Julia 的
Julia DeFilippis
是 亚马逊云科技 的高级参与经理。她与客户和利益相关者合作,确保实现业务成果,并确保 亚马逊云科技 团队取得成果。她喜欢与客户建立关系,并通过向后研究客户的需求和问题陈述来赢得信任。请参阅 Julia 的
 Priyadharshini Selvaraj
是 亚马逊云科技 专业服务的数据架构师。她与企业客户密切合作,在 亚马逊云科技 上构建数据和分析解决方案。在业余时间,她自愿加入一家为当地社区服务的非营利组织,喜欢装饰蛋糕、阅读传记和为孩子们教钢琴课。
Priyadharshini Selvaraj
是 亚马逊云科技 专业服务的数据架构师。她与企业客户密切合作,在 亚马逊云科技 上构建数据和分析解决方案。在业余时间,她自愿加入一家为当地社区服务的非营利组织,喜欢装饰蛋糕、阅读传记和为孩子们教钢琴课。
 纳雷什·拉贾拉姆
是亚马逊网络服务的云基础设施架构师。他帮助客户解决复杂的技术挑战,使他们能够实现业务需求。在业余时间,他喜欢与朋友和家人共度时光。请查看 Naresh 的
纳雷什·拉贾拉姆
是亚马逊网络服务的云基础设施架构师。他帮助客户解决复杂的技术挑战,使他们能够实现业务需求。在业余时间,他喜欢与朋友和家人共度时光。请查看 Naresh 的
 Paritosh Walvekar
是 亚马逊云科技 专业服务的云应用程序架构师,他在那里帮助客户构建云原生应用程序。他拥有布法罗大学的计算机科学硕士学位。在业余时间,他喜欢看电影,正在学习弹钢琴。
Paritosh Walvekar
是 亚马逊云科技 专业服务的云应用程序架构师,他在那里帮助客户构建云原生应用程序。他拥有布法罗大学的计算机科学硕士学位。在业余时间,他喜欢看电影,正在学习弹钢琴。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。