我们使用机器学习技术将英文博客翻译为简体中文。您可以点击导航栏中的“中文(简体)”切换到英文版本。
使用 CloudWatch 警报自动回滚亚马逊 ECS 滚动部署
简介
背景
默认情况下,当服务中的任务无法达到正常状态时,调度程序会应用
即使服务中的任务处于正常状态,也可能需要回滚部署的原因有很多。该服务可能对其代码或配置进行了更改,从而导致其性能低于给定环境中的既定基准。这可以通过使用 Amazon CloudWatch 监控从该服务收集的一组指标来检测。这些可能是系统指标,例如 CPU、内存利用率,或自定义服务指标,例如平均响应延迟。
使用
它是如何工作的?
当客户使用 JSON 字符串使用 Amazon ECS API 创建或更新服务时,他们可以在
部署
配置 字段中配置一个或多个 Amazon CloudWatch 指标警报,如下所示:
"deploymentConfiguration":{
"deploymentCircuitBreaker":{
"enable":true,
"rollback":true
},
"maximumPercent":200,
"minimumHealthyPercent":50,
"alarms":{
"alarmNames":[
"HighResponseLatencyAlarm"
],
"enable":true,
"rollback":true
}
}
上面的命令行界面 (CLI) 等效项,即
--deployment-con figuration
参数,如下所示:
--deployment-configuration "maximumPercent=200,minimumHealthyPercent=50,deploymentCircuitBreaker={enable=true,rollback=true},alarms={alarmNames=[HighResponseLatencyAlarm],enable=true,rollback=true}"
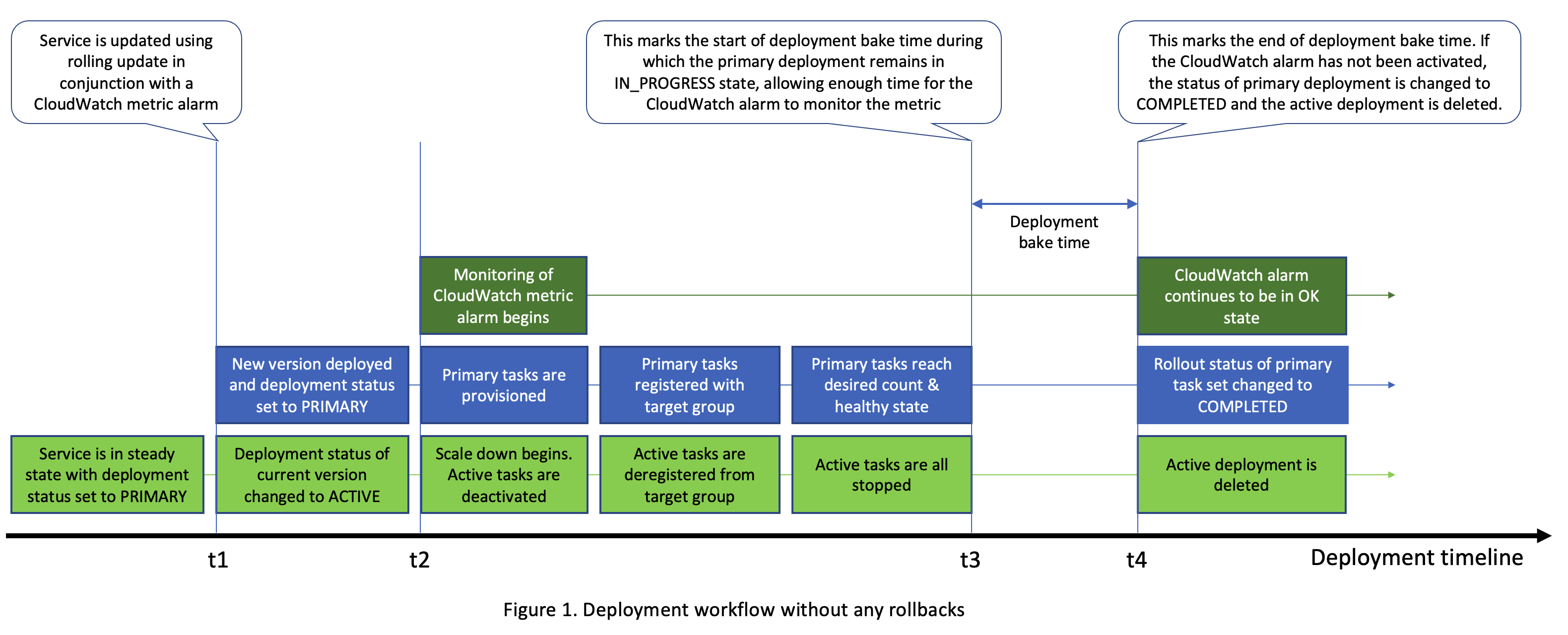
参照下图 1,在滚动更新期间,一旦更新服务的一个或多个任务(即这些任务现在构成
主
部署,而先前正在运行的任务构成
主动
部署)处于运行状态(t = t2),Amazon ECS 就会开始监控已配置的 Amazon CloudWatch 警报列表。如果在未配置任何警报的情况下完成滚动更新,则当主部署运行状况良好且已达到所需数量且活动部署已缩减为 0 时,部署过程被视为已完成。图 1 中的时间轴显示了这两个事件都发生在 t = t3,但在大多数用例中,它们可能会交错排列,具体取决于目标组取消注册延迟和运行状况检查设置(如果服务使用负载均衡器)等因素。如果您配置警报,则允许部署过程继续一段额外的持续时间,称为
烘焙时间
。在此期间,主部署保持在 IN_PROGRESS 状态。此时长的长度由 Amazon ECS 根据亚马逊 CloudWatch 警报的属性(例如其
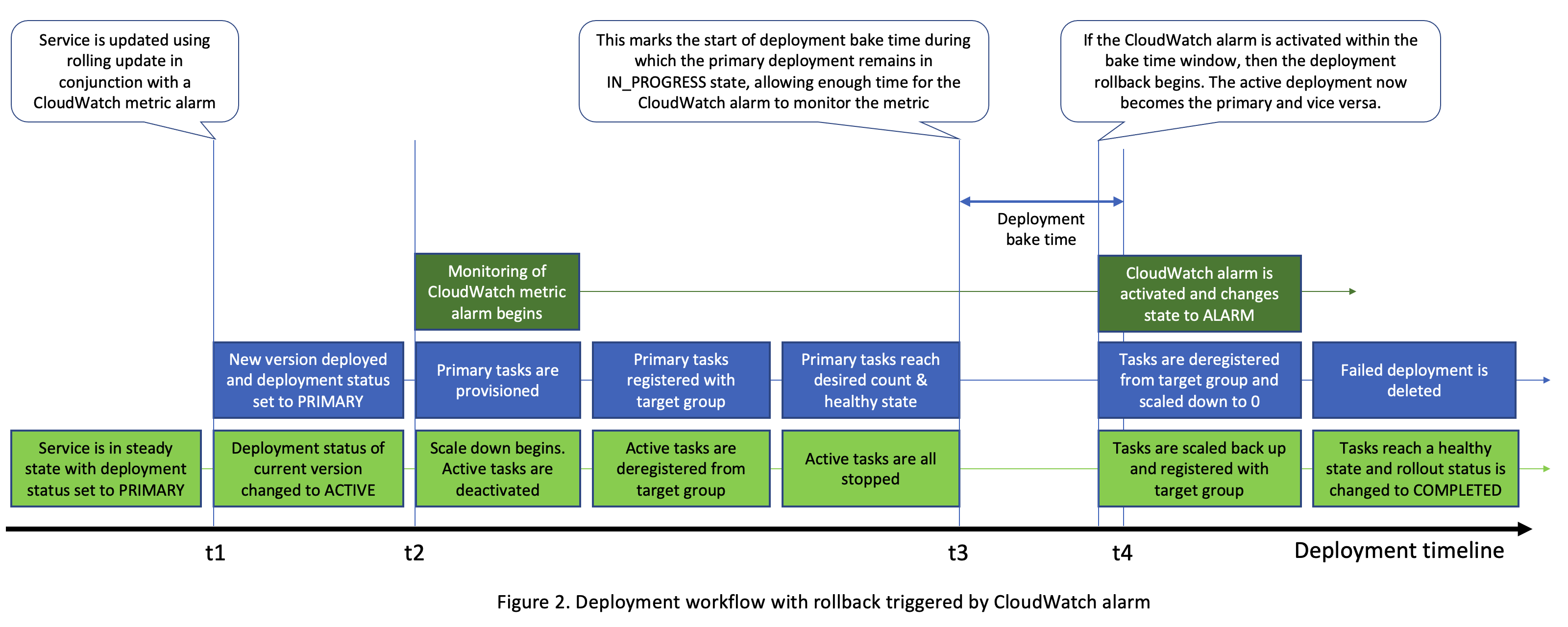
参考下图 2,如果在 t = t2 和 t = t4 之间的任何时候激活 Amazon CloudWatch 警报(即状态从 “正常” 更改为 “警报”),则 Amazon ECS 开始回滚。通过事件总线通知客户部署失败,当前部署的状态更改为失败。此外,以前的主动部署现在变成了主部署,并已向上扩展到所需的数量。失败的部署将缩小规模并最终删除。
滚动更新,警报正在运行
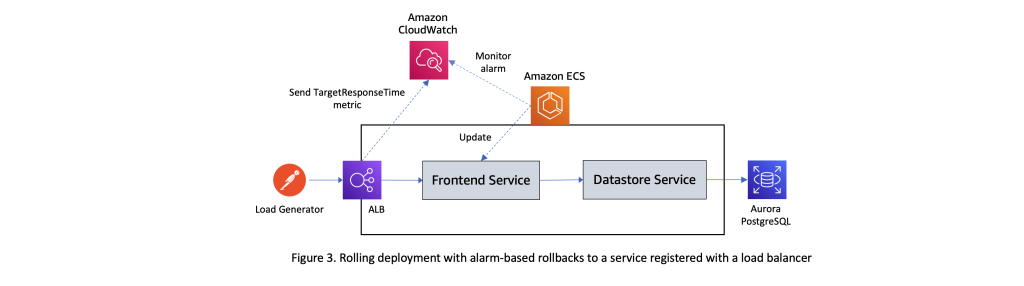
现在,让我们使用部署到亚马逊 ECS 集群的示例工作负载,测试滚动更新如何与 Amazon CloudWatch 警报配合使用。图 3 中的下图显示了本次测试所采用的设置。它包含一个前端服务,该服务公开了一组 REST API 并与数据存储服务进行交互,后者反过来会对 Aurora PostgreSQL 数据库的实例执行 CRUD 操作。前端服务的任务在连接到应用程序负载均衡器的目标组中注册。使用外部负载生成器向该工作负载发送稳定的请求流。Elastic Load Balancing 向亚马逊 CloudWatch 报告了多项指标,这些指标可用于验证系统是否按预期运行。在本次测试中,我们使用的是
targetResponseTim
e 指标,该指标衡量请求离开负载均衡器后直到收到目标响应所经过的时间(以秒为单位)。
基于该指标创建的 Amazon CloudWatch 指标警报的详细信息如下所示。警报配置为在 10 分钟间隔内至少 5 次违反
TargetResponseTim
e 指标突破 0.1 秒的阈值时激活。
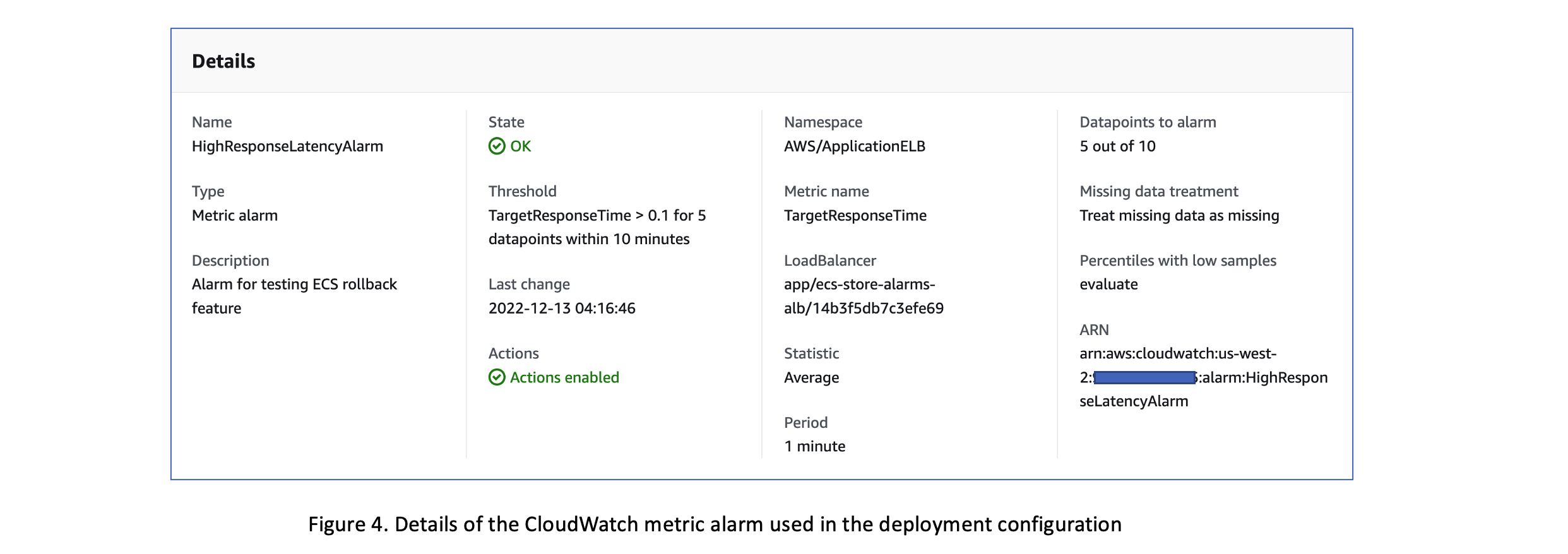
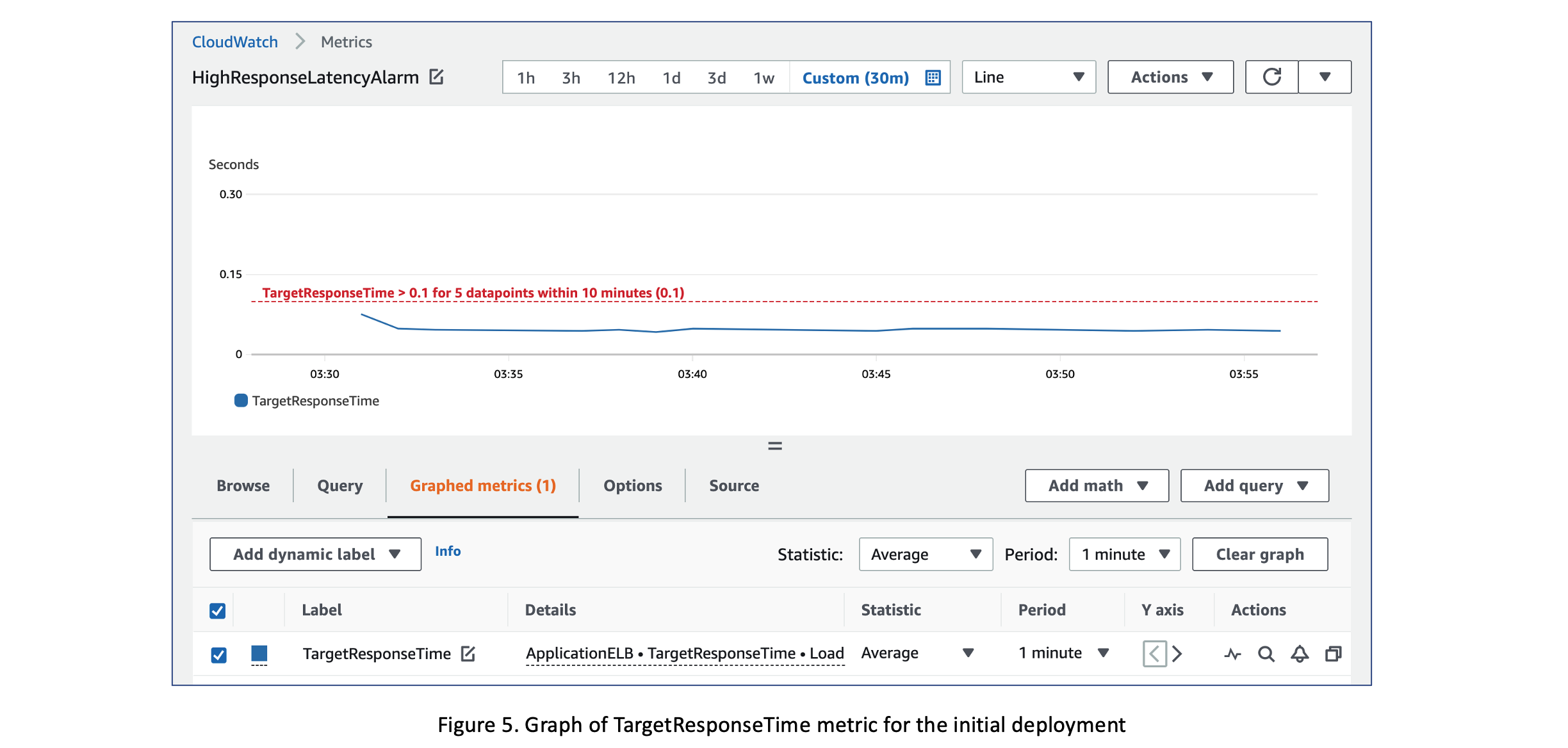
图 5 显示了
TargetResponseTime
指标的图表,该 指标在初始部署前端服务时平均约为 50 毫秒。
现在,随着前端服务的更新版本,滚动更新已启动。此修订版的应用代码已修改,因此该服务的响应时间超过了为 Amazon CloudWatch 指标警报配置的 0.1 秒阈值。下面的 JSON 数据显示了更新启动后某个时候主要部署和活跃部署的状态。此交叉点对应于图 2 中时间轴中的 t = t3,此时活动部署已缩减到 0,主部署已扩大到所需数量。在 JSON 数据中,任务定义 f
rontendalarmTask: 3
对应于服务的初始版本,而 fr
onten
dalarmTask: 4 是更新版本的任务定义。
[
{
"id": "ecs-svc/1330173481524238954",
"status": "PRIMARY",
"taskDefinition": "arn:aws:ecs:us-west-2:XXX:task-definition/FrontendAlarmTask:4",
"desiredCount": 2,
"pendingCount": 0,
"runningCount": 2,
"failedTasks": 0,
"createdAt": "2022-12-12T23:00:40.748000-05:00",
"updatedAt": "2022-12-12T23:01:32.930000-05:00",
"launchType": "EC2",
"networkConfiguration": {
},
"rolloutState": "IN_PROGRESS",
"rolloutStateReason": "ECS deployment ecs-svc/1330173481524238954 in progress."
},
{
"id": "ecs-svc/7260558072093326498",
"status": "ACTIVE",
"taskDefinition": "arn:aws:ecs:us-west-2:XXX:task-definition/FrontendAlarmTask:3",
"desiredCount": 0,
"pendingCount": 0,
"runningCount": 0,
"failedTasks": 0,
"createdAt": "2022-12-12T22:30:29.943000-05:00",
"updatedAt": "2022-12-12T23:02:20.611000-05:00",
"launchType": "EC2",
"networkConfiguration": {
},
"rolloutState": "COMPLETED",
"rolloutStateReason": "ECS deployment ecs-svc/7260558072093326498 completed."
}
]
图 6 显示了部署更新后
TargetResponseTime
指标的图表。它还指出了部署烘焙时间开始以及激活警报时启动回滚的大概时刻。
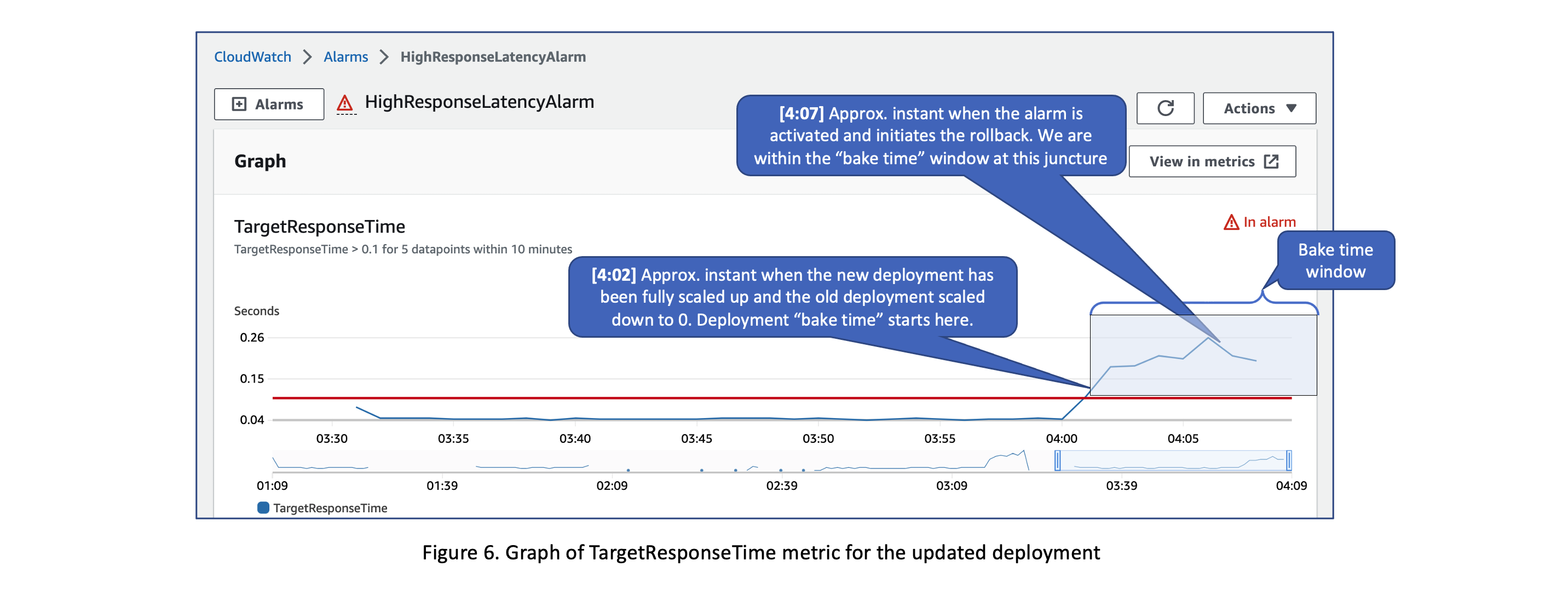
下面的 JSON 数据显示了启动回滚后立即执行的主要部署和活动部署的状态以及启动回滚的原因。
[
{
"id": "ecs-svc/7260558072093326498",
"status": "PRIMARY",
"taskDefinition": "arn:aws:ecs:us-west-2:XXX:task-definition/FrontendAlarmTask:3",
"desiredCount": 2,
"pendingCount": 0,
"runningCount": 2,
"failedTasks": 0,
"createdAt": "2022-12-12T22:30:29.943000-05:00",
"updatedAt": "2022-12-12T23:08:22.484000-05:00",
"launchType": "EC2",
"networkConfiguration": {
},
"rolloutState": "IN_PROGRESS",
"rolloutStateReason": "ECS deployment detected triggered alarm(s): rolling back to deploymentId ecs-svc/7260558072093326498."
},
{
"id": "ecs-svc/1330173481524238954",
"status": "ACTIVE",
"taskDefinition": "arn:aws:ecs:us-west-2:XXX:task-definition/FrontendAlarmTask:4",
"desiredCount": 0,
"pendingCount": 0,
"runningCount": 1,
"failedTasks": 0,
"createdAt": "2022-12-12T23:00:40.748000-05:00",
"updatedAt": "2022-12-12T23:08:22.433000-05:00",
"launchType": "EC2",
"networkConfiguration": {
},
"rolloutState": "FAILED",
"rolloutStateReason": "ECS deployment failed: alarm(s) detected."
}
]带有后端服务警报的滚动更新
对于未注册到负载均衡器目标组的后端服务(例如本示例场景中的数据存储服务),使用警报管理滚动更新的动态将非常相似。请注意,由于不会出现任何与取消目标组任务相关的延迟,因此在这些情况下,部署到达图 2 中 t = t3 对应的交汇点的速度可能会快得多。但是,由于部署烘焙时间仅从 t = t3 开始,因此如果您已在微服务中实施了可观测性最佳实践,则仍可以通过监控相应的 Amazon CloudWatch 警报来发现潜在的性能问题。
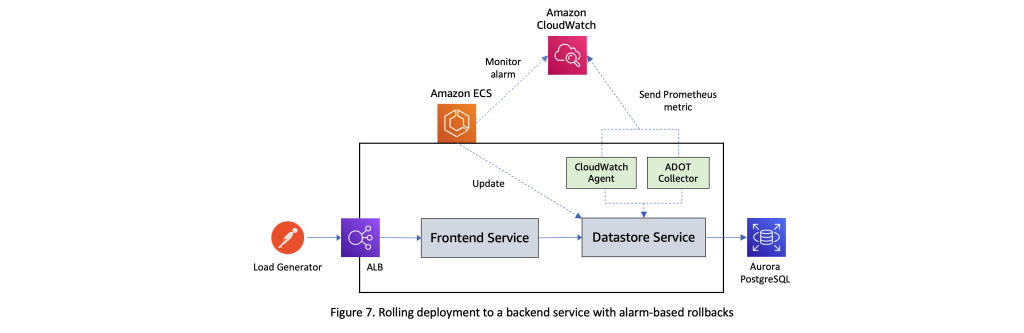
客户可以根据CloudWatch Container Ins
结论
该博客讨论了使用 CloudWatch 警报自动回滚 ECS 滚动部署的详细信息。此功能现已正式上线,可通过 亚马逊云科技 CLI、亚马逊云科技 软件开发工具包或 亚马逊云科技 CloudFormation 使用。我们非常重视买家在亚马逊的反馈,因此请告诉我们这项新功能如何为您服务。我们鼓励您向
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您发展海外业务和/或了解行业前沿技术选择推荐该服务。